neural architecture search with reinforcement learning
background
神经网络在诸多任务中表现较好,但是设计/调参过程复制。
本文提出一种使用rnn生成模型架构,并且使用强化学习来训练rnn,使其生成的模型在验证集上的准确率最大
论文工作
提出了neural architecture search,一种基于梯度的方法
神经网络的结构structure和连通性connectivity可以用可变长字符串来表示,因此
(1)希望使用循环神经网络rnn(controller)来生成这个网络结构
(2)在数据集上训练生成的子网络child network,获得其准确率
(3)将子网络的在数据集上的准确率作为奖励信号,计算梯度更新控制器rnn
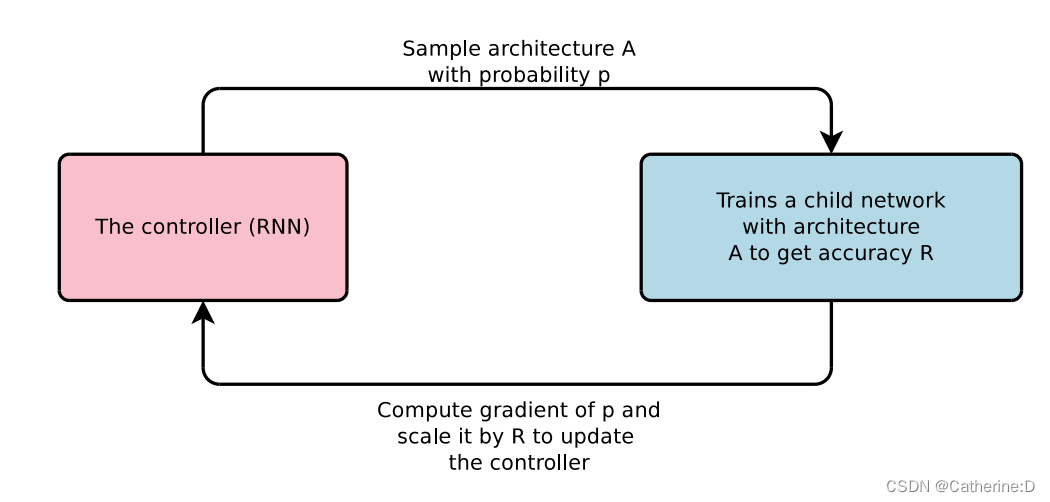
相关工作
本文的neural architecture search和程序合成program synthesis,归纳编程inductive programming有一定相似性
neural architecture search是自回归的,即每预测一个超参数,都以先前的预测为条件
其他相关工作详见论文
方法
1. rnn生成网络架构
提高controller的灵活性,使用rnn生成神经网络的超参数
这里预测的神经网络只有卷积层,用控制器生成超参作为a sequence of tokens
每一层包括:filter数量、filter的两个尺寸、stride的两个尺寸
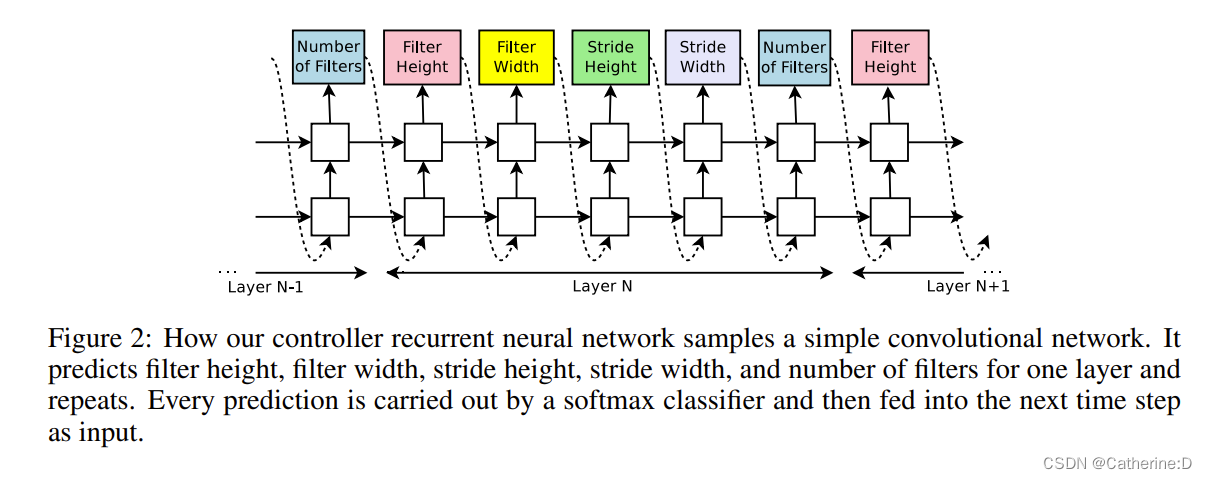
实验里,层数超过阈值就停止生成;随训练进行,作者增加这个阈值
rnn完成了一个模型结构的生成,就构建并训练具有该结构的神经网络,待其收敛时记录准确率
2. 强化训练
这里最好有强化学习的基础,特别是policy gradient,不太了解该内容的建议学习一下李宏毅老师的相关部分。
控制器生成的tokens作为一系列actions(a1:t)
子网络在hold out数据集上训练达到精度r,作为奖励信号
最大化期望奖励:(因变量是rnn的参数)
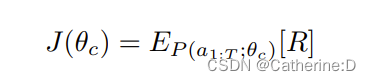
由于r不可微,所以使用policy gradient策略来更新rnn的参数,这里使用了williams的reinforce rule(1992)
具体策略可参考https://zhuanlan.zhihu.com/p/110881517
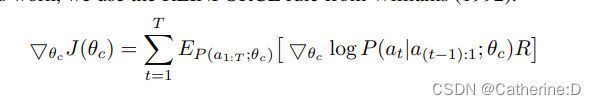
经验近似:
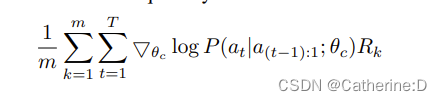
m是controller在一个batch里采样网不同结构的数量,t是超参数量,生成的第k个网络的精度为rk
上述的更新为无偏估计,但是方差高,未来减少方差,使用了基线函数:
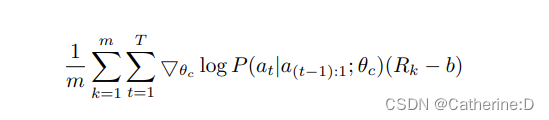
只要b不依赖于当前action,就仍是无偏估计。本文作者使用的是前k-1轮精度的指数移动平均
上述公式的推导:

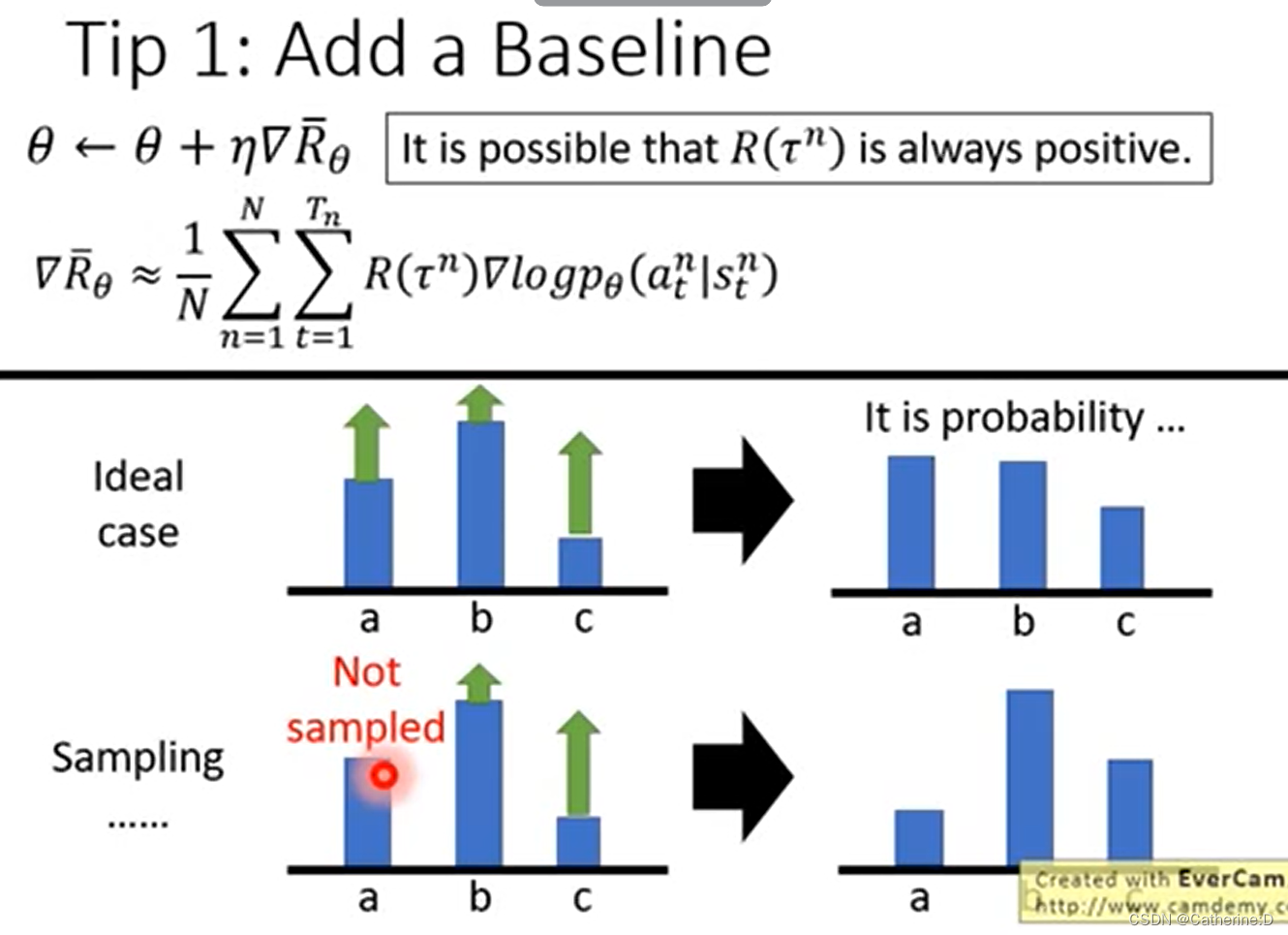
为什么要加baseline b,参考李宏毅老师的讲解,因为update时是一个sample的过程,如果所有的r都是正数,而有些选项没有被sample到(比如a),那么随着其他选项的概率更新(normalization之后概率之和为1)那么a被选中的概率就会减小,但这是我们不希望的,因为a只是“很不幸”的没有被选中而已
因此我们希望 reward r不要总是正数
所以baseline是为了解决:the probability of actions not sampled will decrease.
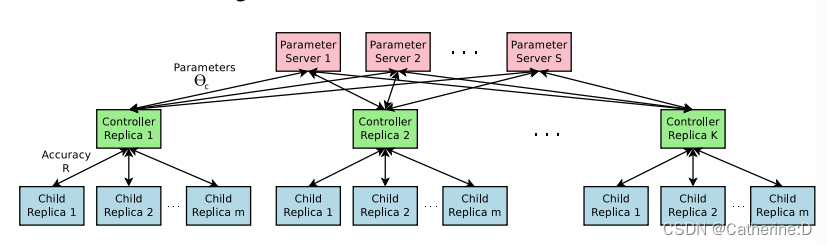
使用并行和异步更新加速训练(有钱真好)
每一次训练完子网络才更新controller的参数,使得时间较长,这里作者使用了分布式计算,异步更新
s个parameter server,存储k个控制器副本的共享参数(rnn),每个控制器副本对并行训练的m个子架构将进行采样。控制器将小批量数据的梯度发送给服务器,更新所有控制器副本的权重
3.使用skip connection和不同layer type增加模型复杂度
为了扩大搜索空间,增加skip connection(类比googlenet resnet)
为了能预测这种连接,使用set-selection type attention机制,在每一层都增加一个anchor point锚点,指示前n-1层的内容信息(是否需要connect sigmoid)每个sigmoid都是controller当前状态和前n-1层锚点的隐藏状态的函数。
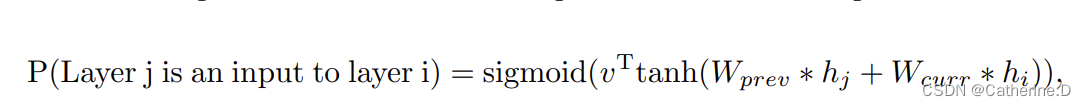
hj是第j层锚点的状态(0<j<n-1),wprev,wcurr,v是可训练参数。
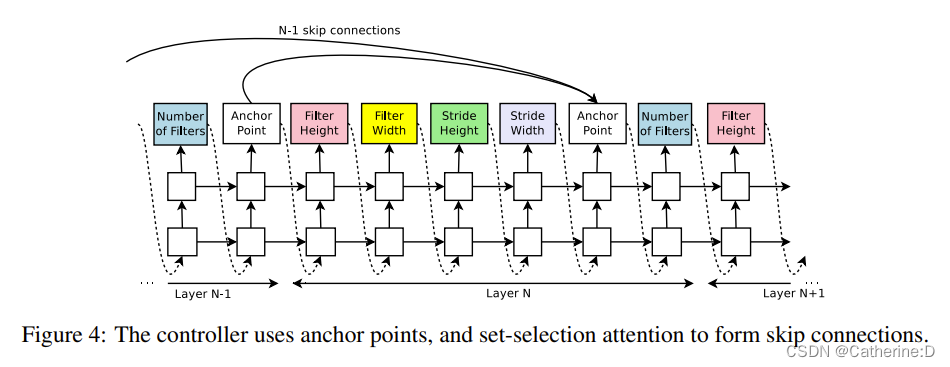
几种情况的处理:
(1)没有输入的层,把图像作为输入
(2) 在最后一层,把之前所有没有被connect的层的输出连接起来,将隐藏状态给分类器
(3)输入层大小不同,用0作为padding
4.generate recurrent cell architectures
rnn cell:输入xt,ht-1生成ht
控制器rnn需要用组合方法(加,乘等)以及激活函数来标记节点,合并输入,再将两个输出送给下一个节点。
实现上,按顺序索引树的节点,以便逐个访问每个节点需要的超参
参考lstm,加入ct,ct-1标记记忆状态
例子:叶子节点0 1,内部节点2
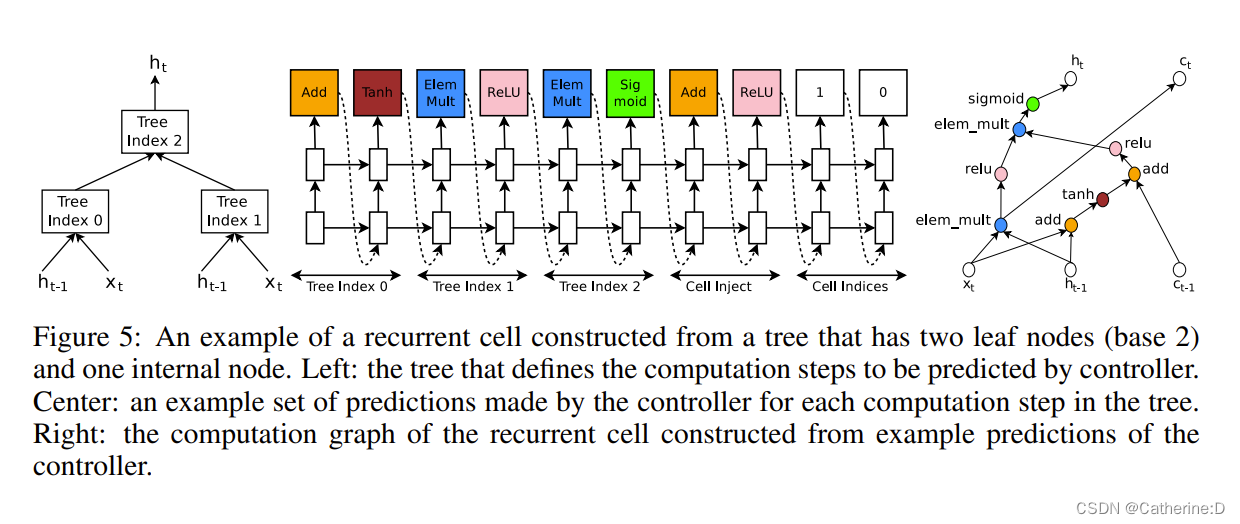
计算步骤

效果
cifar10上,test error = 3.65% ,超sota0.09%,训练速度1.05倍
penn treebank dataset,形成的新的cell性能优于lstm,test set perplexity = 62.4,超过sota3.6
转移到ptb的字符语言建模任务上,达到sota 1.214 perplexity
其他结果参考原文,不一一列举
发表评论