docker部署sqlserver过程记录
2024-08-02 23:49 | 分类:数据库 | 评论:0 次 | 浏览: 79
文章目录系列文章目录前言一、pandas是什么?二、使用步骤1.引入库2.读入数据总结前言最近接触到了NL2SQL,有个相对比较适合自己的开...
【Docker】PostgreSQL 容器化部署
2024-08-02 23:36 | 分类:数据库 | 评论:0 次 | 浏览: 84
PostgreSQL标准软件基于Bitnami PostgreSQL 构建。当前版本为16.1.0。

记录使用FlinkSql进行实时工作流开发
2024-08-02 23:29 | 分类:数据库 | 评论:0 次 | 浏览: 87
Apache Flink是一个开源框架,用于处理无边界(无尽)和有边界(有限)数据流。它提供了低延迟、高吞吐量和状态一致性,使开发者能够构建...
![[极客大挑战 2019]HardSQL1](https://images.3wcode.com/3wcode/20240802/s_0_202408022318138021.png)
[极客大挑战 2019]HardSQL1
2024-08-02 23:18 | 分类:数据库 | 评论:0 次 | 浏览: 75
flag出来了,但是只有一半,使用right和left。拿到题目,好多类似的,这次估计更难,sql注入漏洞。
服务器部署环境(docker安装Mysql + Redis + MongoDB)
2024-08-02 23:15 | 分类:数据库 | 评论:0 次 | 浏览: 99
#Linux docker 部署mysql、redis、mongoDB
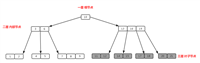
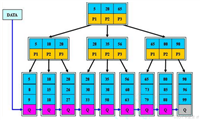
B树、B+树详解
2024-08-02 23:05 | 分类:数据库 | 评论:0 次 | 浏览: 101
首先,为什么要总结B树、B+树的知识呢?最近在学习数据库索引调优相关知识,数据库系统普遍采用B-/+Tree作为索引结构(例如mysql的I...
Mysql的B树和B+树分别能存储多大的数据量
2024-08-02 23:05 | 分类:数据库 | 评论:0 次 | 浏览: 101
B-Tree: 4000 条, 千级B+Tree: 2000w条,千万级一般是3层,即Mysql通过3次IO操作就可以找到数据。
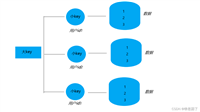
redisTemplate中String,Hash,List,Set,zSet的方法及部分方法的使用
2024-08-02 22:52 | 分类:数据库 | 评论:0 次 | 浏览: 171
redisTemplate中String,Hash,List,Set,zSet的方法及部分方法的使用
RedisTemplate.opsForHash()用法简介并举例
2024-08-02 22:50 | 分类:数据库 | 评论:0 次 | 浏览: 187
请注意,示例中的"myhash"是哈希的键名,“field1”、"field2"等是要设置或获取的字...
(一)Kafka 安全之使用 SASL 进行身份验证 —— JAAS 配置、SASL 配置
2024-08-02 22:28 | 分类:数据库 | 评论:0 次 | 浏览: 115
SASL 是用来认证 C/S 模式也就是服务器与客户端的一种认证机制,全称 Simple Authentication and Securi...
FlinkCDC全量及增量采集SqlServer数据
2024-08-02 22:21 | 分类:数据库 | 评论:0 次 | 浏览: 80
本文详细介绍Flink-CDC如何全量及增量采集Sqlserver数据源.
Flink Sql:四种Join方式详解(基于flink1.15官方文档)
2024-08-02 22:21 | 分类:数据库 | 评论:0 次 | 浏览: 77
Regular Joins(常规连接 ),Interval Joins(间隔连接),Temporal Joins(时态连接),lookup ...
Flink 客户端操作命令及可视化工具
2024-08-02 22:20 | 分类:数据库 | 评论:0 次 | 浏览: 91
Flink提供了丰富的客户端操作来提交任务和与任务进行交互。下面主要从Flink命令行、SQL Client和Web五个方面进行整理。在Fl...
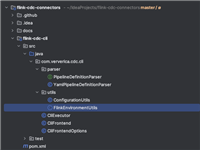
flinkcdc 3.0 源码学习之客户端flink-cdc-cli模块
2024-08-02 22:18 | 分类:数据库 | 评论:0 次 | 浏览: 96
flinkcdc 3.0 源码学习之客户端flink-cdc-cli模块

Flink的sink实战之四:自定义
2024-08-02 22:18 | 分类:数据库 | 评论:0 次 | 浏览: 99
我们总是喜欢瞻仰大厂的大神们,但实际上大神也不过凡人,与菜鸟程序员相比,也就多花了几分心思,如果你再不努力,差距也只会越来越大。面试题多多少...

Doris实战——结合Flink构建极速易用的实时数仓
2024-08-02 22:18 | 分类:数据库 | 评论:0 次 | 浏览: 132
Doris实战——结合Flink构建极速易用的实时数仓

re:Invent 2023 | 使用与 Flink CDC 的实时同步,打破数据孤岛
2024-08-02 22:18 | 分类:数据库 | 评论:0 次 | 浏览: 120
这段视频探讨了如何利用Apache Flink的变更数据捕获(CDC)功能来解决数据孤岛问题并实现实时数据同步。演讲者首先概述了传统数据集成...
数据仓库之SparkSQL
2024-08-02 22:16 | 分类:数据库 | 评论:0 次 | 浏览: 82
Apache Spark SQL是Spark中的一个组件,专门用于结构化数据处理。它提供了通过SQL和DataFrame API来执行结构化...
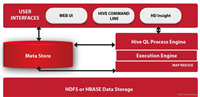
深入理解 Hadoop 上的 Hive 查询执行流程
2024-08-02 22:10 | 分类:数据库 | 评论:0 次 | 浏览: 79
在 Hadoop 生态系统中,Hive 是一个重要的分支,它构建在 Hadoop 之上,提供了一个开源的数据仓库系统。它的主要功能是查询和分...
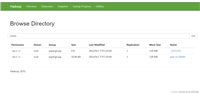
在CentOS7下利用sqoop组件把mysql数据传入hdfs中
2024-08-02 22:04 | 分类:数据库 | 评论:0 次 | 浏览: 99
主页,在后面找到Browse Directory就可以看到hdfs对应的数据库下的目录文件,同时也可以下载.import从mysql的web...
Hbase 面试题(十)
2024-08-02 22:00 | 分类:数据库 | 评论:0 次 | 浏览: 78
1. 阐述Hbase集群中HRegionServer作用 ?2. 简述Hbase phoenix开源SQL引擎 ?3. 阐述Hbase的高可...
伪分布式hadoop上安装hive
2024-08-02 21:59 | 分类:数据库 | 评论:0 次 | 浏览: 92
安装伪分布式hadoop容器,在容器内安装hive,安装mysql容器并允许远程访问数据库,修改hive-site.xml中与mysql连接...
面试专区|【70道Hive高频题整理(附答案背诵版)】
2024-08-02 21:57 | 分类:数据库 | 评论:0 次 | 浏览: 86
Hive是一个基于Hadoop的数据仓库工具,它可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为...

大数据最全大数据StarRocks(一) StarRocks概述(1),2024年最新成功入职字节跳动
2024-08-02 21:50 | 分类:数据库 | 评论:0 次 | 浏览: 94
StarRocks集群由FE和BE构成, 可以使用MySQL客户端访问StarRocks集群。

大数据-Hadoop-基础篇-第十章-Spark
2024-08-02 21:50 | 分类:数据库 | 评论:0 次 | 浏览: 81
Spark是一种通用的大数据计算框架,是基于RDD(弹性分布式数据集)的一种计算模型。那到底是什么呢?可能很多人还不是太理解,通俗讲就是可以...

大数据入门之如何利用Phoenix访问Hbase
2024-08-02 21:50 | 分类:数据库 | 评论:0 次 | 浏览: 76
HBase和Phoenix可谓是一对黄金搭档。HBase以其高效的列式存储和强大的数据扩展能力,成为大数据存储领域的佼佼者;而Phoenix...
redis的使用场景
2024-08-02 21:40 | 分类:数据库 | 评论:0 次 | 浏览: 178
为了把一些经常访问的数据,放入缓存中以减少对数据库的访问频率。从而减少数据库的压力,提高程序的性能。(内存中存储)