概述
flink-cdc-cli 模块目录结构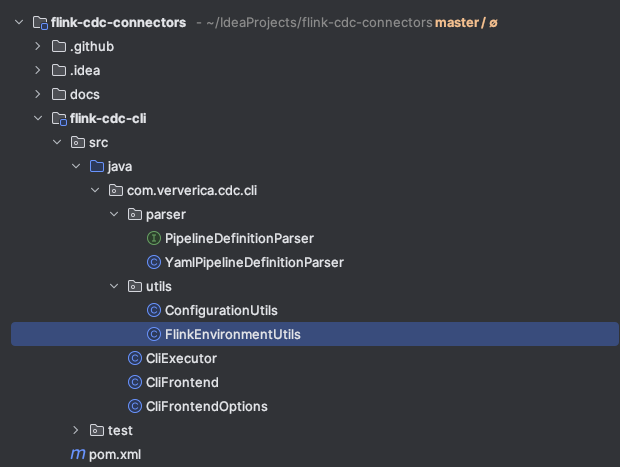
可以看到一共有6个类,1个接口,其中在上一篇文章探索flink-cdc.sh脚本的时候我们知道入口类是clifrontend,所以接下来会从这个类来一步一步探索这一模块.
入口类 clifrontend
main方法
public static void main(string[] args) throws exception {
options clioptions = clifrontendoptions.initializeoptions();
commandlineparser parser = new defaultparser();
commandline commandline = parser.parse(clioptions, args);
// help message
if (args.length == 0 || commandline.hasoption(clifrontendoptions.help)) {
helpformatter formatter = new helpformatter();
formatter.setleftpadding(4);
formatter.setwidth(80);
formatter.printhelp(" ", clioptions);
return;
}
// create executor and execute the pipeline
pipelineexecution.executioninfo result = createexecutor(commandline).run();
// print execution result
printexecutioninfo(result);
}
这里首先是初始化了一下选项,这里用到了apache commons cli 这个工具类,可以很方便的处理命令行参数
大概的步骤有3步
1.定义阶段 : 定义要解析的命令选项,对应的每个选项就是一个option类,options类是option类的一个集合
2.解析阶段 : 通过commandlineparser的parser方法将main方法的args参数解析,获得一个commandline对象
3.查询阶段 : 就是具体使用解析后的结果,可以通过hasoption来判断是否有该选项,getoptionvalue来获取选项对应的值
具体可以参考我的另外一系列文章,有详细介绍这个工具的用法
超强命令行解析工具 apache commons cli
超强命令行解析工具 apache commons cli 各个模块阅读
解析了入参后就判断入参args是否是空或者是否包含-h或者–help这个选项,如果是的话就打印一下帮助信息
接着通过commandline对象创建执行器并且执行任务
最后在打印一下结果信息
这个类中最核心的一行就是创建执行器并且执行任务
// create executor and execute the pipeline
pipelineexecution.executioninfo result = createexecutor(commandline).run();
static cliexecutor createexecutor(commandline commandline) throws exception {
// the pipeline definition file would remain unparsed
list<string> unparsedargs = commandline.getarglist();
if (unparsedargs.isempty()) {
throw new illegalargumentexception(
"missing pipeline definition file path in arguments. ");
}
// take the first unparsed argument as the pipeline definition file
path pipelinedefpath = paths.get(unparsedargs.get(0));
if (!files.exists(pipelinedefpath)) {
throw new filenotfoundexception(
string.format("cannot find pipeline definition file \"%s\"", pipelinedefpath));
}
// global pipeline configuration
configuration globalpipelineconfig = getglobalconfig(commandline);
// load flink environment
path flinkhome = getflinkhome(commandline);
configuration flinkconfig = flinkenvironmentutils.loadflinkconfiguration(flinkhome);
// additional jars
list<path> additionaljars =
arrays.stream(
optional.ofnullable(
commandline.getoptionvalues(clifrontendoptions.jar))
.orelse(new string[0]))
.map(paths::get)
.collect(collectors.tolist());
// build executor
return new cliexecutor(
pipelinedefpath,
flinkconfig,
globalpipelineconfig,
commandline.hasoption(clifrontendoptions.use_mini_cluster),
additionaljars);
}
可以看到最后是构建了一个cliexecutor类,并执行了它的run方法.
选项类 clifrontendoptions
这个类主要是用来定义命令行选项的,使用的是apache commons cli这个类库,代码比较简单
这里主要细看一下各个选项都有什么作用
package org.apache.flink.cdc.cli;
import org.apache.commons.cli.option;
import org.apache.commons.cli.options;
/** command line argument options for {@link clifrontend}. */
public class clifrontendoptions {
public static final option flink_home =
option.builder()
.longopt("flink-home")
.hasarg()
.desc("path of flink home directory")
.build();
public static final option help =
option.builder("h").longopt("help").desc("display help message").build();
public static final option global_config =
option.builder()
.longopt("global-config")
.hasarg()
.desc("path of the global configuration file for flink cdc pipelines")
.build();
public static final option jar =
option.builder()
.longopt("jar")
.hasargs()
.desc("jars to be submitted together with the pipeline")
.build();
public static final option use_mini_cluster =
option.builder()
.longopt("use-mini-cluster")
.hasarg(false)
.desc("use flink minicluster to run the pipeline")
.build();
public static options initializeoptions() {
return new options()
.addoption(help)
.addoption(jar)
.addoption(flink_home)
.addoption(global_config)
.addoption(use_mini_cluster);
}
}
–flink-home
–global-config
–jar
–use-mini-cluster
-h 或者 --help
执行类 cliexecutor
package com.ververica.cdc.cli;
import com.ververica.cdc.cli.parser.pipelinedefinitionparser;
import com.ververica.cdc.cli.parser.yamlpipelinedefinitionparser;
import com.ververica.cdc.cli.utils.flinkenvironmentutils;
import com.ververica.cdc.common.annotation.visiblefortesting;
import com.ververica.cdc.common.configuration.configuration;
import com.ververica.cdc.composer.pipelinecomposer;
import com.ververica.cdc.composer.pipelineexecution;
import com.ververica.cdc.composer.definition.pipelinedef;
import java.nio.file.path;
import java.util.list;
/** executor for doing the composing and submitting logic for {@link clifrontend}. */
public class cliexecutor {
private final path pipelinedefpath;
private final configuration flinkconfig;
private final configuration globalpipelineconfig;
private final boolean useminicluster;
private final list<path> additionaljars;
private pipelinecomposer composer = null;
public cliexecutor(
path pipelinedefpath,
configuration flinkconfig,
configuration globalpipelineconfig,
boolean useminicluster,
list<path> additionaljars) {
this.pipelinedefpath = pipelinedefpath;
this.flinkconfig = flinkconfig;
this.globalpipelineconfig = globalpipelineconfig;
this.useminicluster = useminicluster;
this.additionaljars = additionaljars;
}
public pipelineexecution.executioninfo run() throws exception {
// parse pipeline definition file
pipelinedefinitionparser pipelinedefinitionparser = new yamlpipelinedefinitionparser();
pipelinedef pipelinedef =
pipelinedefinitionparser.parse(pipelinedefpath, globalpipelineconfig);
// create composer
pipelinecomposer composer = getcomposer(flinkconfig);
// compose pipeline
pipelineexecution execution = composer.compose(pipelinedef);
// execute the pipeline
return execution.execute();
}
private pipelinecomposer getcomposer(configuration flinkconfig) {
if (composer == null) {
return flinkenvironmentutils.createcomposer(
useminicluster, flinkconfig, additionaljars);
}
return composer;
}
@visiblefortesting
void setcomposer(pipelinecomposer composer) {
this.composer = composer;
}
@visiblefortesting
public configuration getflinkconfig() {
return flinkconfig;
}
@visiblefortesting
public configuration getglobalpipelineconfig() {
return globalpipelineconfig;
}
@visiblefortesting
public list<path> getadditionaljars() {
return additionaljars;
}
}
这个类的核心就是run 方法
首先是构建了一个yaml解析器用于解析yaml配置文件
然后调用parser 方法 获得一个pipelinedef类,这相当与将yaml配置文件转换成了一个配置实体bean,方便之后操作
接下来获取到pipelinecomposer对象,然后调用compose 方法传入刚刚的配置实体beanpiplinedef对象,就获得了一个piplineexecution对象
最后调用execute方法启动任务(这个方法底层就是调用了flink 的 streamexecutionenvironment.executeasync方法)
配置文件解析类 yamlpipelinedefinitionparser
看这个类之前先看一下官网给的任务构建的demo yaml
################################################################################
# description: sync mysql all tables to doris
################################################################################
source:
type: mysql
hostname: localhost
port: 3306
username: root
password: 12345678
tables: doris_sync.\.*
server-id: 5400-5404
server-time-zone: asia/shanghai
sink:
type: doris
fenodes: 127.0.0.1:8031
username: root
password: ""
table.create.properties.light_schema_change: true
table.create.properties.replication_num: 1
route:
- source-table: doris_sync.a_\.*
sink-table: ods.ods_a
- source-table: doris_sync.abc
sink-table: ods.ods_abc
- source-table: doris_sync.table_\.*
sink-table: ods.ods_table
pipeline:
name: sync mysql database to doris
parallelism: 2
这个类的主要目标就是要将这个yaml文件解析成一个实体类pipelinedef方便之后的操作
代码解释就直接写到注释中了
package com.ververica.cdc.cli.parser;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.core.type.typereference;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.jsonnode;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.objectmapper;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.dataformat.yaml.yamlfactory;
import com.ververica.cdc.common.configuration.configuration;
import com.ververica.cdc.composer.definition.pipelinedef;
import com.ververica.cdc.composer.definition.routedef;
import com.ververica.cdc.composer.definition.sinkdef;
import com.ververica.cdc.composer.definition.sourcedef;
import java.nio.file.path;
import java.util.arraylist;
import java.util.list;
import java.util.map;
import java.util.optional;
import static com.ververica.cdc.common.utils.preconditions.checknotnull;
/** parser for converting yaml formatted pipeline definition to {@link pipelinedef}. */
public class yamlpipelinedefinitionparser implements pipelinedefinitionparser {
// parent node keys
private static final string source_key = "source";
private static final string sink_key = "sink";
private static final string route_key = "route";
private static final string pipeline_key = "pipeline";
// source / sink keys
private static final string type_key = "type";
private static final string name_key = "name";
// route keys
private static final string route_source_table_key = "source-table";
private static final string route_sink_table_key = "sink-table";
private static final string route_description_key = "description";
// 这个是 解析的核心工具方法,可以获取yaml文件中的值,或者将其中的值转换成java实体类
private final objectmapper mapper = new objectmapper(new yamlfactory());
/** parse the specified pipeline definition file. */
@override
public pipelinedef parse(path pipelinedefpath, configuration globalpipelineconfig)
throws exception {
// 首先将 pipelinedefpath (就是传入的mysql-to-doris.yaml文件) 通过readtree 转换成 一个jsonnode 对象,方便之后解析
jsonnode root = mapper.readtree(pipelinedefpath.tofile());
// source is required
sourcedef sourcedef =
tosourcedef(
checknotnull(
root.get(source_key), // 获取 source 这个json对象
"missing required field \"%s\" in pipeline definition",
source_key));
// 这个和source 同理,不解释了
// sink is required
sinkdef sinkdef =
tosinkdef(
checknotnull(
root.get(sink_key), // 获取 sink json对象
"missing required field \"%s\" in pipeline definition",
sink_key));
// 这里是路由配置,是个数组,而且是个可选项,所以这里优雅的使用了optional对root.get(route_key) 做了一层包装
// 然后调用ifpresent方法来判断,如果参数存在的时候才会执行的逻辑,就是遍历数组然后加到 routedefs 中
// routes are optional
list<routedef> routedefs = new arraylist<>();
optional.ofnullable(root.get(route_key))
.ifpresent(node -> node.foreach(route -> routedefs.add(toroutedef(route))));
// pipeline configs are optional
// pipeline 参数,是可选项,这个如果不指定,配置就是用的flink-cdc中的配置
configuration userpipelineconfig = topipelineconfig(root.get(pipeline_key));
// merge user config into global config
// 合并用户配置和全局配置
// 这里可以看到是先addall 全局配置,后addall 用户配置,这的addall实际上就是hashmap的putall,新值会把旧值覆盖,所以用户的配置优先级大于全局配置
configuration pipelineconfig = new configuration();
pipelineconfig.addall(globalpipelineconfig);
pipelineconfig.addall(userpipelineconfig);
// 返回 任务的实体类
return new pipelinedef(sourcedef, sinkdef, routedefs, null, pipelineconfig);
}
private sourcedef tosourcedef(jsonnode sourcenode) {
// 将sourcenode 转换成一个 map类型
map<string, string> sourcemap =
mapper.convertvalue(sourcenode, new typereference<map<string, string>>() {});
// "type" field is required
string type =
checknotnull(
sourcemap.remove(type_key), // 将type 字段移除取出
"missing required field \"%s\" in source configuration",
type_key);
// "name" field is optional
string name = sourcemap.remove(name_key); // 将 name 字段移除取出
// 构建sourcedef对象
return new sourcedef(type, name, configuration.frommap(sourcemap));
}
private sinkdef tosinkdef(jsonnode sinknode) {
map<string, string> sinkmap =
mapper.convertvalue(sinknode, new typereference<map<string, string>>() {});
// "type" field is required
string type =
checknotnull(
sinkmap.remove(type_key),
"missing required field \"%s\" in sink configuration",
type_key);
// "name" field is optional
string name = sinkmap.remove(name_key);
return new sinkdef(type, name, configuration.frommap(sinkmap));
}
private routedef toroutedef(jsonnode routenode) {
string sourcetable =
checknotnull(
routenode.get(route_source_table_key),
"missing required field \"%s\" in route configuration",
route_source_table_key)
.astext(); // 从jsonnode 获取string类型的值
string sinktable =
checknotnull(
routenode.get(route_sink_table_key),
"missing required field \"%s\" in route configuration",
route_sink_table_key)
.astext();
string description =
optional.ofnullable(routenode.get(route_description_key))
.map(jsonnode::astext)
.orelse(null);
return new routedef(sourcetable, sinktable, description);
}
private configuration topipelineconfig(jsonnode pipelineconfignode) {
if (pipelineconfignode == null || pipelineconfignode.isnull()) {
return new configuration();
}
map<string, string> pipelineconfigmap =
mapper.convertvalue(
pipelineconfignode, new typereference<map<string, string>>() {});
return configuration.frommap(pipelineconfigmap);
}
}
配置信息工具类 configurationutils
package com.ververica.cdc.cli.utils;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.core.type.typereference;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.objectmapper;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.dataformat.yaml.yamlfactory;
import com.ververica.cdc.common.configuration.configuration;
import java.io.filenotfoundexception;
import java.nio.file.files;
import java.nio.file.path;
import java.util.map;
/** utilities for handling {@link configuration}. */
public class configurationutils {
public static configuration loadmapformattedconfig(path configpath) throws exception {
if (!files.exists(configpath)) {
throw new filenotfoundexception(
string.format("cannot find configuration file at \"%s\"", configpath));
}
objectmapper mapper = new objectmapper(new yamlfactory());
try {
map<string, string> configmap =
mapper.readvalue(
configpath.tofile(), new typereference<map<string, string>>() {});
return configuration.frommap(configmap);
} catch (exception e) {
throw new illegalstateexception(
string.format(
"failed to load config file \"%s\" to key-value pairs", configpath),
e);
}
}
}
这个类就一个方法,主要的作用就是将一个配置文件转换成 configuration对象
来看一下具体的实现细节吧
首先是 files.exists 判断了一下文件是否存在,不存在就直接抛异常
objectmapper mapper = new objectmapper(new yamlfactory());
这行代码主要是用了jackson库中的两个核心类,objectmapper和yamlfactory
objectmapper 是 jackson 库中用于序列化(将对象转换为字节流或其他格式)和反序列化(将字节流或其他格式转换为对象)的核心类。它提供了各种方法来处理 json、yaml 等格式的数据。
yamlfactory 是 jackson 库中专门用于处理 yaml 格式的工厂类。在这里,我们通过 new yamlfactory() 创建了一个 yaml 格式的工厂实例,用于处理 yaml 数据。
new objectmapper(new yamlfactory()):这部分代码创建了一个 objectmapper 实例,并使用指定的 yamlfactory 来配置它,这样 objectmapper 就能够处理 yaml 格式的数据了。
map<string, string> configmap =
mapper.readvalue(
configpath.tofile(), new typereference<map<string, string>>() {});
这行的意思就是传入yaml配置文件,容纳后将其转换成一个map类型,kv都是string
因为这个类的主要用途是解析global-conf的,也就是conf目录下的flink-cdc.yaml,这个文件仅只有kv类型的,所以要转换成map
flink-cdc.yaml
# parallelism of the pipeline
parallelism: 4
# behavior for handling schema change events from source
schema.change.behavior: evolve
这里再简单看一下mapper的readvalue方法
jackson objectmapper的readvalue方法主要用途就是将配置文件转换成java实体,主要可以三个重载
public <t> t readvalue(file src, class<t> valuetype); // 将配置转换成一个实体类
public <t> t readvalue(file src, typereference<t> valuetyperef); // 针对一些map,list,数组类型可以用这个
public <t> t readvalue(file src, javatype valuetype); // 这个一般不常用
最后这行就是将一个map转换成configuration对象
return configuration.frommap(configmap);
这里的configuration就是将hashmap做了一个封装,方便操作
flink环境工具类 flinkenvironmentutils
package com.ververica.cdc.cli.utils;
import com.ververica.cdc.common.configuration.configuration;
import com.ververica.cdc.composer.flink.flinkpipelinecomposer;
import java.nio.file.path;
import java.util.list;
/** utilities for handling flink configuration and environment. */
public class flinkenvironmentutils {
private static final string flink_conf_dir = "conf";
private static final string flink_conf_filename = "flink-conf.yaml";
public static configuration loadflinkconfiguration(path flinkhome) throws exception {
path flinkconfpath = flinkhome.resolve(flink_conf_dir).resolve(flink_conf_filename);
return configurationutils.loadmapformattedconfig(flinkconfpath);
}
public static flinkpipelinecomposer createcomposer(
boolean useminicluster, configuration flinkconfig, list<path> additionaljars) {
if (useminicluster) {
return flinkpipelinecomposer.ofminicluster();
}
return flinkpipelinecomposer.ofremotecluster(
org.apache.flink.configuration.configuration.frommap(flinkconfig.tomap()),
additionaljars);
}
}
public static configuration loadflinkconfiguration(path flinkhome) throws exception {
path flinkconfpath = flinkhome.resolve(flink_conf_dir).resolve(flink_conf_filename);
return configurationutils.loadmapformattedconfig(flinkconfpath);
}
这个方法的主要目的就是通过找到flink_home/conf/flink-conf.yaml文件,然后将这个文件转换成一个configuration对象,转换的方法在上一节中介绍过了
这里还用到了path 的 resolve 方法,就是用于拼接两个path然后形成一个新path的方法
public static flinkpipelinecomposer createcomposer(
boolean useminicluster, configuration flinkconfig, list<path> additionaljars) {
if (useminicluster) {
return flinkpipelinecomposer.ofminicluster();
}
return flinkpipelinecomposer.ofremotecluster(
org.apache.flink.configuration.configuration.frommap(flinkconfig.tomap()),
additionaljars);
}
这个是通过一些参数来初始化composer,composer就是将用户的任务翻译成一个pipeline作业的核心类
这里首先是判断了一下是否使用minicluster,如果是的话就用minicluster ,这个可以在启动的时候用–use-mini-cluster 来指定,具体在上文中介绍过.
如果不是那么就用remotecluster,这里就不多介绍了,之后的文章会介绍
总结
上面几个类写的比较多,这里做一个总结,简单的来总结一下这个模块
flink-cdc-cli 模块的主要作用
1.解析任务配置yaml文件,转换成一个pipelinedef任务实体类
2.通过flink_home获取flink的相关配置信息,然后构建出一个pipelinecomposer 对象
3.调用composer的comoose方法,传入任务实体类获取pipelineexecution任务执行对象,然后启动任务
再简单的概述一下 : 解析配置文件生成任务实体类,然后启动任务
通过阅读这模块的源码的收获 :
1.学习使用了apache commons cli 工具,之后如果自己写命令行工具的话也可以用这个
2.学习了 jackson 解析yaml文件
3.加深了对optional类判断null值的印象,之后对于null值判断有个一个更优雅的写法
4.对flink-cdc-cli模块有了个全面的认识,但是具体还有些细节需要需要深入到其他模块再去了解
总之阅读大佬们写的代码真是收获很大~
参考
[mini-cluster介绍] : https://www.cnblogs.com/wangwei0721/p/14052016.html
[jackson objectmapper#readvalue 使用] : https://www.cnblogs.com/del88/p/13098678.html
发表评论