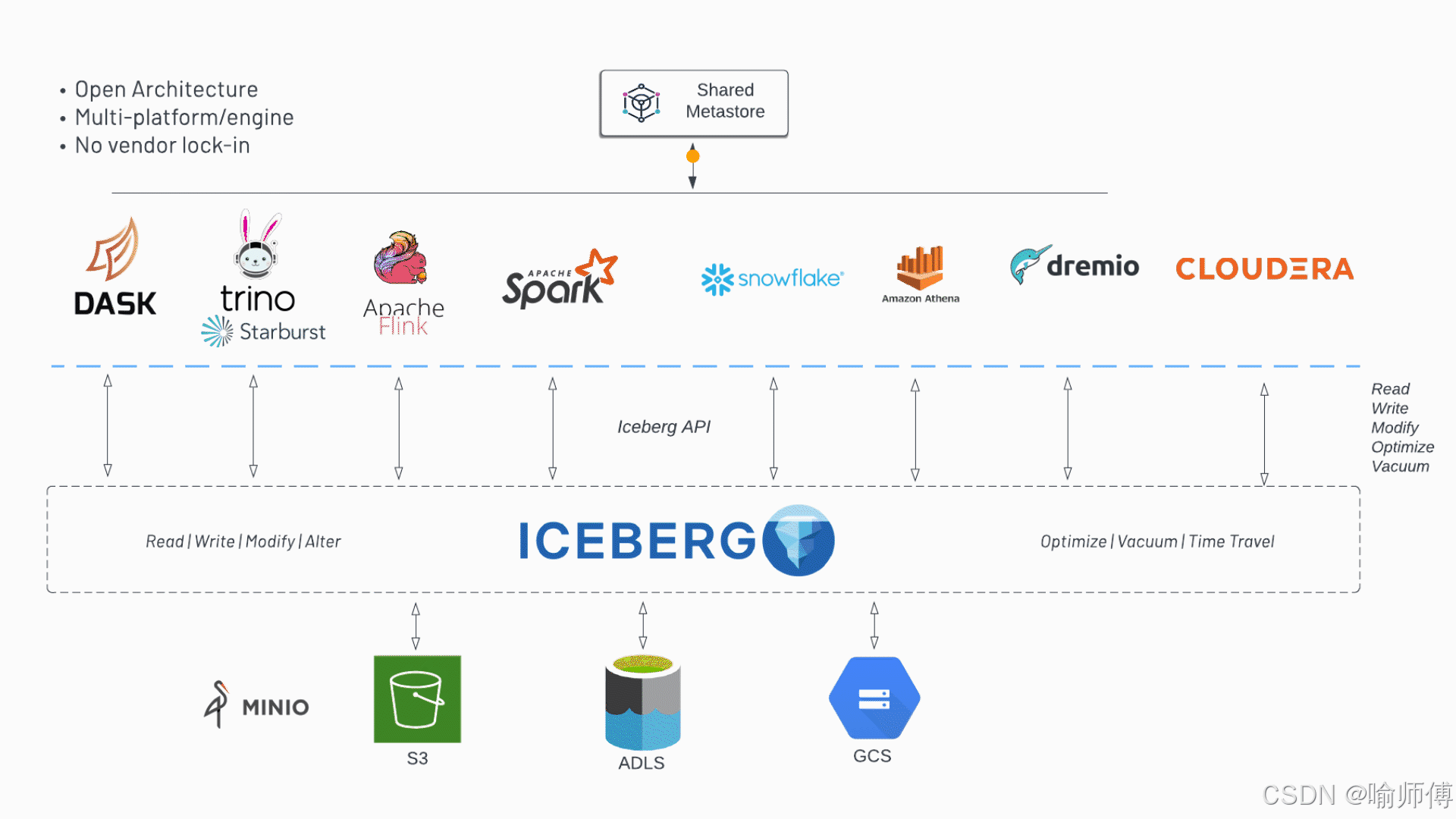
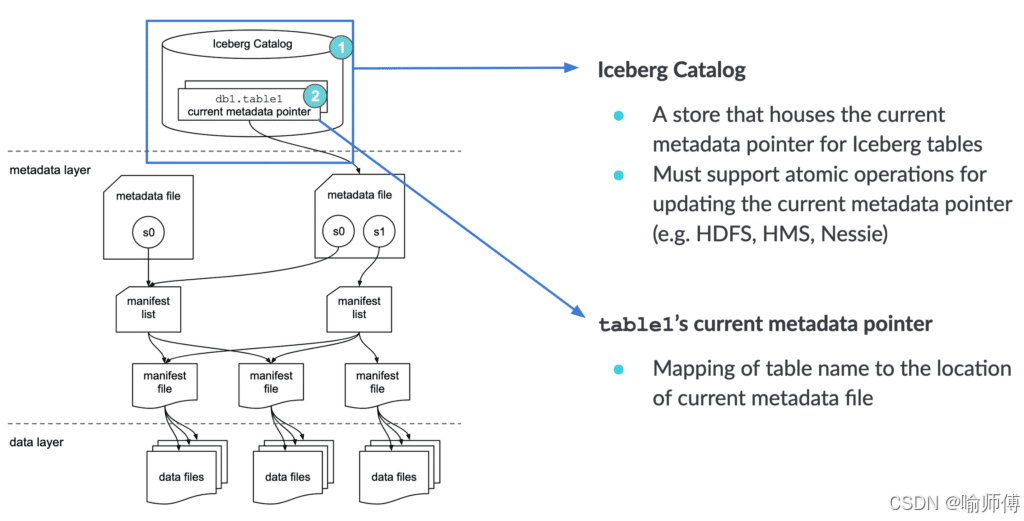
apache iceberg 底层数据存储

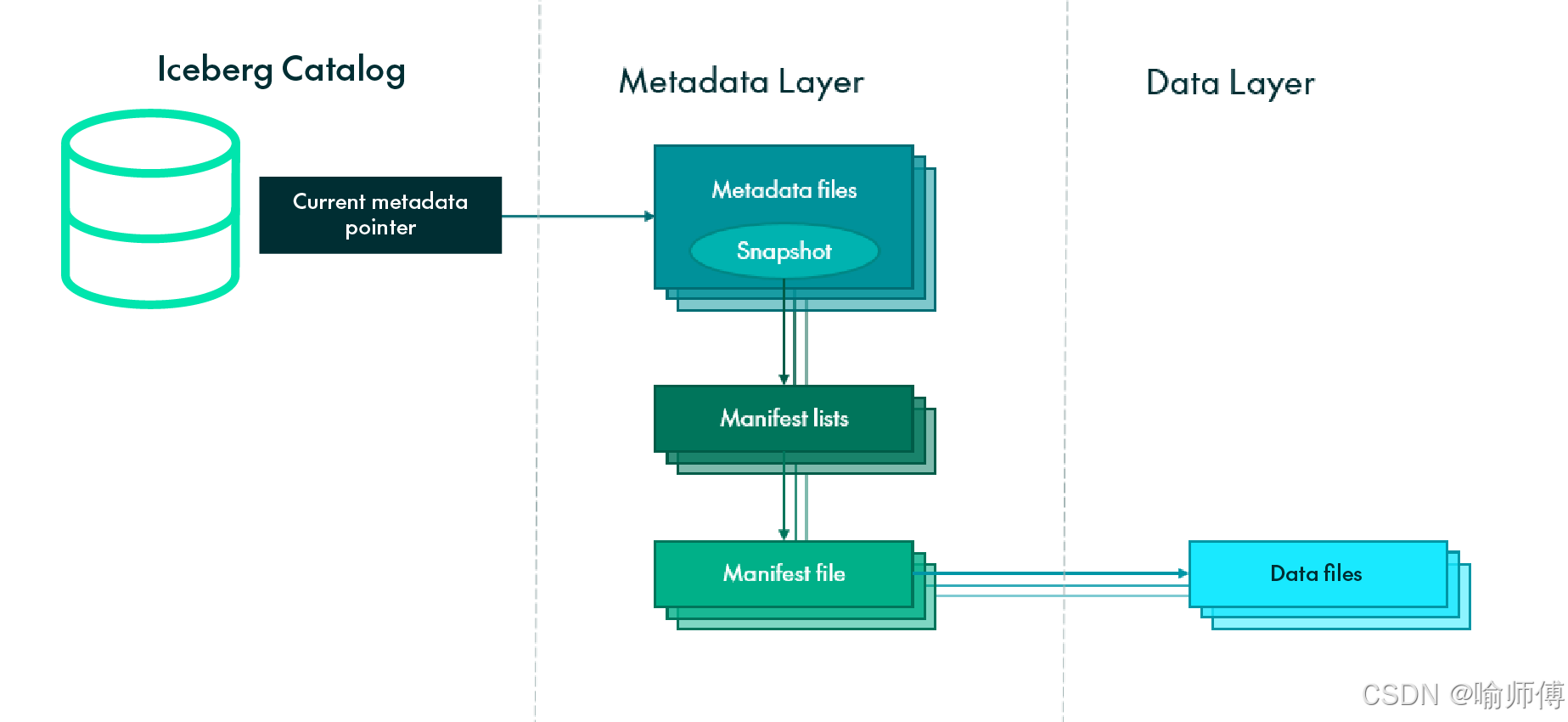
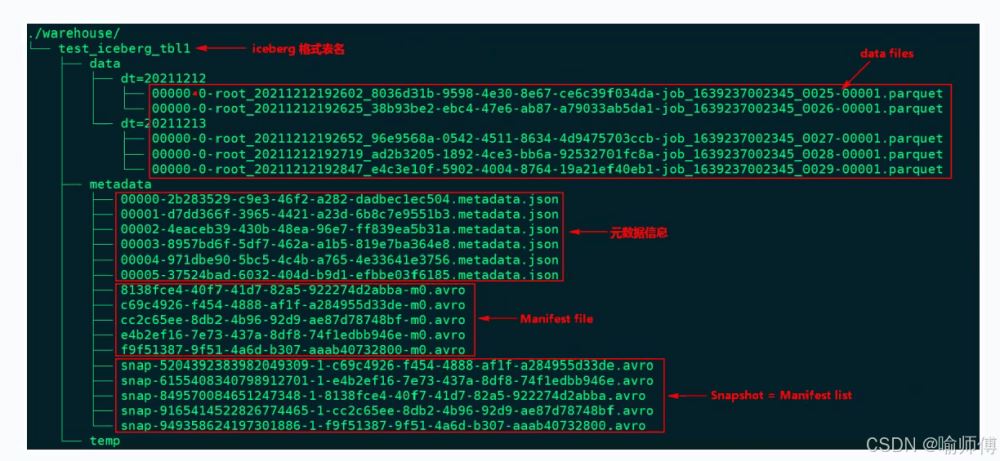
iceberg 数据组织图(hdfs): 5个snapshot对应5个manifest list清单列表。
1.查询最新快照数据
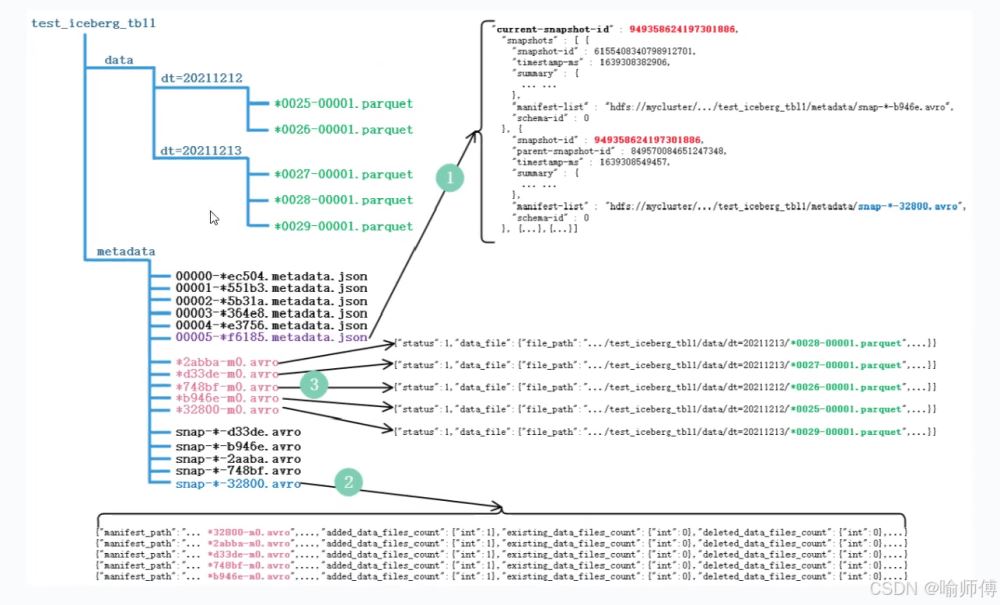
获取最新元数据
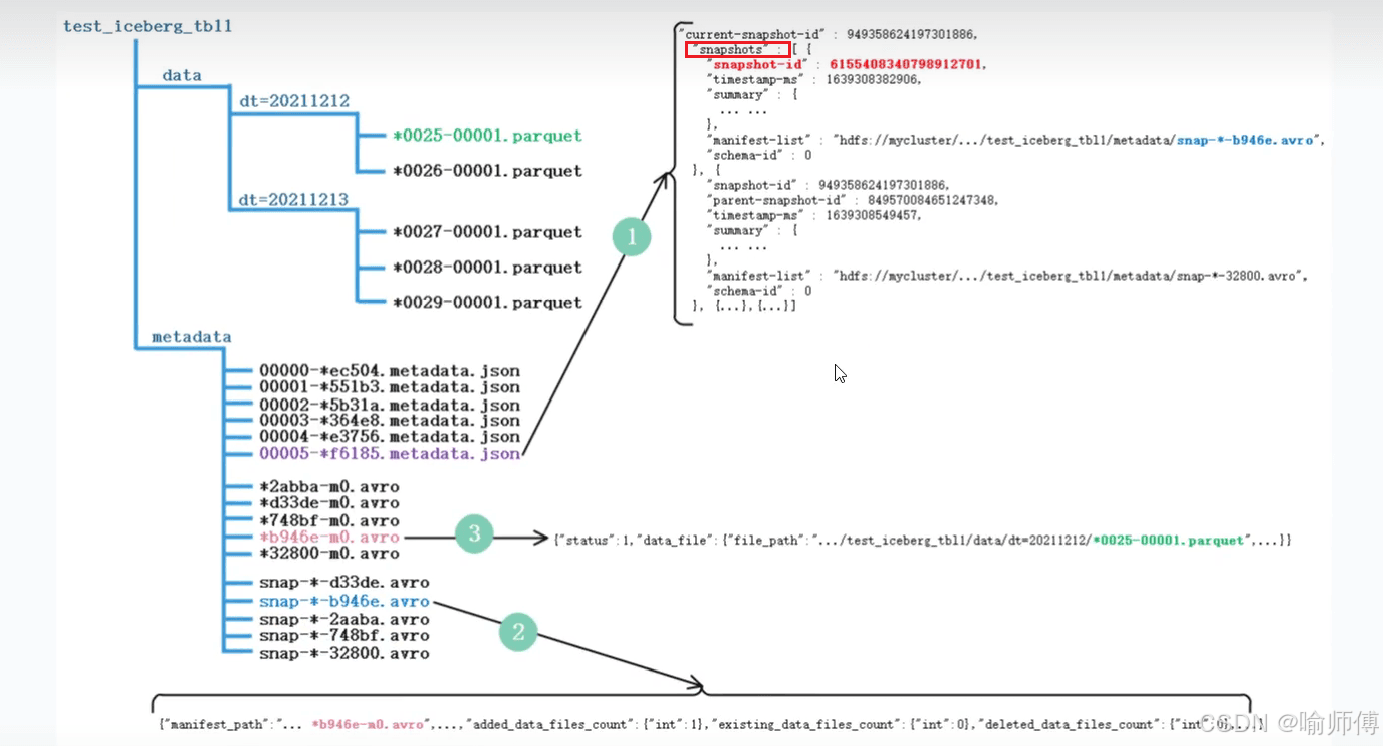
获取 iceberg 表的最新元数据文件,eg:00000-ec504.metadata.json。
解析元数据
从元数据文件中提取以下信息:
- 当前表的快照 id:
949358624197301886 - 所有快照信息:在 json 中的
snapshots数组。
获取快照文件信息
根据快照 id,找到对应的 avro 文件信息,eg:snap--32800.avro。
在该快照文件中,提取 manifest file清单文件信息:
*32800-m0.avro*2abba-m0.avro*d33de-m0.avro*748bf-m0.avro*b946e-m0.avro
读取最新数据
读取以上 manifest file清单文件中描述的 parquet 数据文件(data files)。
分析 snap 文件
在 snap--32800.avro 文件中,可以找到以下属性:
deleted data files countadded data files countexisting data files count
判断数据文件状态
iceberg 根据 deleted data files count 判断是否存在被删除的数据:
如果该值大于 0,表示对应的 manifest 文件中有已删除的数据。读取数据时,无需读取这些被删除的文件。
manifest 清单文件分析
根据 manifest 清单文件,找到对应的 parquet 文件存储位置。
每个 manifest 文件中有 status 属性:
1:代表对应的 parquet 文件为新增文件,需要读取。
2:代表 parquet 文件被删除。
2.查询指定快照(历史快照)数据
apache iceberg 支持查询历史上任何时刻的快照。
要查询特定快照,需要指定 snapshot-id 属性,可以通过 spark 或 flink 实现。
在 spark 中查询指定快照的数据:
spark.read
.option("snapshot-id", 6155488348798912701l)
.format("iceberg")
.load("path")查询某个快照数据的原理:
指定快照 id
在读取数据时,通过 snapshot-id 指定要查询的快照。
查找快照信息
iceberg 会根据指定的快照 id 检索相关的元数据(如下metadata里面的snapshots数组),包括快照中包含的数据文件和 manifest 文件。
3.根据时间戳查询某个快照数据
apache iceberg 支持通过 as-of-timestamp 参数读取特定时间戳的快照数据,通常也是通过 spark 或 flink 实现。
在 spark 中根据时间戳查询数据:
spark.read
.option("as-of-timestamp", "时间戳")
.format("iceberg")
.load("path")指定时间戳
使用 as-of-timestamp 指定要查询的时间点。
查找快照信息
iceberg 将查找与时间戳对应的快照,利用 *.metadata.json 文件中的信息。
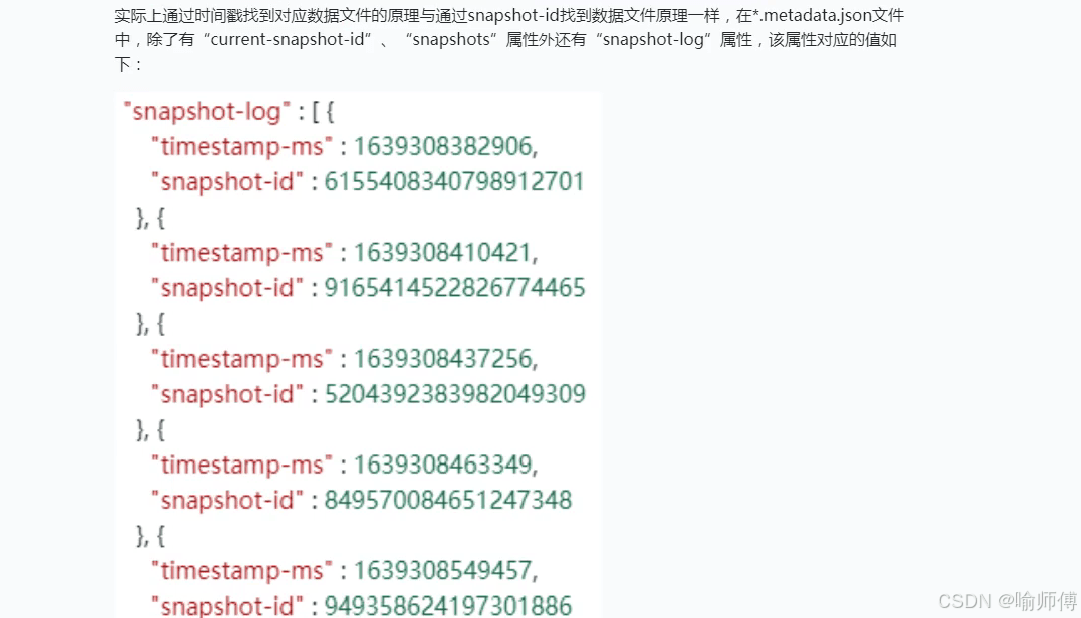
属性解析
在元数据文件中,除了 current-snapshot-id 和 snapshots 属性外,还有一个 snapshot-log 属性,该属性记录了快照的历史信息。
到此这篇关于apache iceberg - 底层数据查询原理的文章就介绍到这了,更多相关apache iceberg原理内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!


发表评论