关键字: [amazon web services re:invent 2023, apache flink, real time data synchronization, break down data silos, apache flink cdc, streaming etl, transactional data lake]
本文字数: 1400, 阅读完需: 7 分钟
视频
如视频不能正常播放,请前往bilibili观看本视频。>> https://www.bilibili.com/video/bv1y64y1p7qe
导读
拥有多个数据孤岛会导致数据在整个组织中处于不同的来源,从而难以执行分析和实现数据访问的民主化。为了能够将所有数据集中到一个地方,您可能需要设置不同的数据流、批处理作业或额外的 cdc 组件,这可能会增加架构的复杂性。在本论坛中,您将了解如何通过在亚马逊云科技上使用 flink cdc 来简化跨事务 db 的实时同步和摄取,并最终打破数据孤岛。
演讲精华
以下是小编为您整理的本次演讲的精华,共1100字,阅读时间大约是6分钟。如果您想进一步了解演讲内容或者观看演讲全文,请观看演讲完整视频或者下面的演讲原文。
数据孤岛问题对寻求商业洞察的公司来说是一个严重挑战。根据在委内瑞拉出生并居住在西班牙的四年来一直专注于亚马逊云科技的流媒体解决方案架构师francisco murillo的解释,许多组织的关键信息分散在不同的数据孤岛中,如交易数据库和数据仓库等。过去,他们依赖于每日etl批量作业将这些孤岛中的数据提取并加载到中央数据仓库进行分析。然而,这种方法存在高延迟的问题,因为利益相关者必须在完成批量作业(通常需24小时)后才能获得新见解。此外,这些批量作业在处理大量数据方面的并行处理限制也使得处理时间更长。
以现实生活中的一例为例,在欺诈检测场景中,如果公司早晨收到了有关某事件的可疑警报,等到每日批量作业完成后,可能已经太晚了,无法采取任何行动。企业需要在第一时间做出响应并进行实时分析。由于这些挑战,企业在遵守服务等级协议(sla)以及快速响应业务需求方面的灵活性受到限制。
随着数据量每年呈指数级增长,企业领导者需要更快地获取见解来指导决策。流数据技术有望解决数据集成和数据分析方面的这些挑战。据murillo所说,诸如apache kafka、amazon kinesis和amazon msk等流解决方案与传统批量处理方式截然不同。它们持续运行,处理源源不断的数据,而非安排批次处理。这使得实时分析和即时见解能在毫秒或秒级别内获得,而无需等待数小时或数天。流数据技术仅处理已更改的数据,从而避免重复工作并提高架构的成本效率。例如,它只传输增量插入、更新和删除,而不是移动整个表或数据库。这些技术还可以水平扩展,即使数据量增加,仍能实现高吞吐量和高响应速度。客户只需启动更多资源即可处理额外的流量。
关键的数据流集成能力在于变化数据捕获(cdc)技术。cdc技术能够从源系统中获取数据变化,包括旧数据值、新数据值、元数据和更改类型(插入、更新或删除)等详细信息。为了实现这一功能,需要利用像kafka这样的流存储层来收集更改事件。接下来,可以使用apache flink等流分析框架处理这些cdc事件,以执行加工、聚合等操作。此外,输出数据还可以实时同步到其他系统,从而替代传统的每日批量处理方式。
然而,正如murillo所提到的那样,构建具有一致性和容错保证的自定义分布式流应用程序是一项具有挑战性的任务。apache flink被设计为专门针对大规模流处理需求。它提供了诸如精确一次事件处理和故障期间的一致状态等关键保障。用户可以通过sql、java、scala或python编写flink应用程序,并提供从低级到简单声明式sql的api选项。该框架在后台处理分布、扩展和容错等方面的复杂性。
flink拥有一个活跃的开源社区,有超过300名来自亚马逊云科技的贡献者提交了2200多个拉取请求并进行了300多次代码审查。由于亚马逊云科技客户对于为何亚马逊没有提供针对flink的完全托管服务的疑问,因此亚马逊推出了amazon kinesis analytics(现名为amazon managed streaming for apache flink),以便在使用flink工作负载时无需管理基础设施。
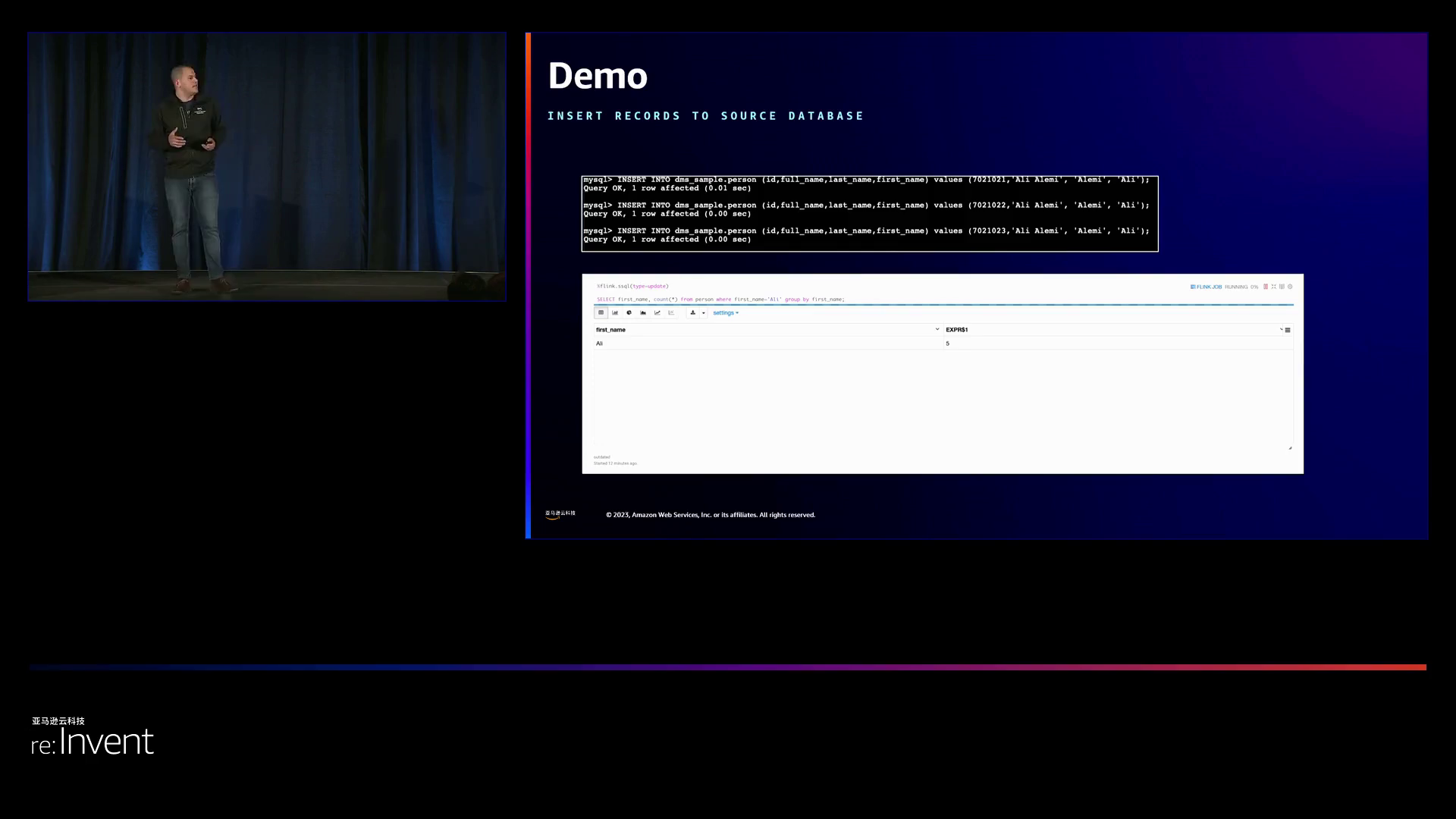
flink的一个显著优势是其针对mysql、mongodb和oracle等数据库的cdc连接器。这避免了将数据库更改流式传输到kafka的单独cdc工具的需求。flink的连接器可以直接与数据库事务日志集成,以捕捉发生的插入、更新和删除操作。这些记录将被流式传输到flink进行处理。
这些都是通过flink的动态表功能实现的,它们会跟踪对数据库的更改,以提供一个一致的视图。当在源数据库中插入或更新记录时,flink会消费更改事件并更新动态表。在删除记录时,将从动态表中删除相应记录。这使得对更改流的连续查询成为可能。
flink通过实时更新用户点击量来维护网站内容。每当有新的点击事件发生,总数就会增加;若点击被取消,总数则会减少。应用程序始终保持准确的实时视图。
关键在于确定cdc数据的流向和处理衍生见解的流式处理。其他需要准确反映数据库更改的系统需要一个能够处理插入、更新和删除流的"upsert"接收器。基于amazons3的事务性数据湖如delta lake和apache hudi提供了upsert功能,以及压缩、快照隔离和模式强制执行等功能。
通过使用flink的hudi和iceberg连接器,可以将cdc数据流式传输到数据湖,并通过athena进行查询。这种架构降低了分析的延迟,提供了跨孤岛的一致视图,并通过消除步骤简化了流式etl管道。数据湖成为了真实来源。
murillo展示了一个参考架构,该架构使用flink的mysql数据库cdc连接器、flink sql的变更流处理以及在s3中存储的hudi表。这里的客户故事是直接cdc集成和实时同步,而无需单独的kafka集群。flink的动态表提供对变更事件的流处理和连续查询。hudi实现在数据湖上的upsert和压缩。athena查询提供快速的交互式访问,同时具有一致的视图。
对于必须将cdc数据提供给多个应用程序的情况,msk connect提供了针对包括mysql和postgresql在内的数据库的kafka连接器。数据库更改可以实时流传输到msk集群。然后,flink应用程序可以利用动态表处理这些主题。输出可以被流传输到s3或回流到msk供其他消费者使用。可以使用lambda函数或运行flink作业的emr集群添加额外的处理。
关键是结合亚马逊云科技的流处理管理服务以简化和自动缩放。客户可以专注于流处理逻辑,而不是基础设施或运营。亚马逊云科技服务处理无差别的繁重工作。
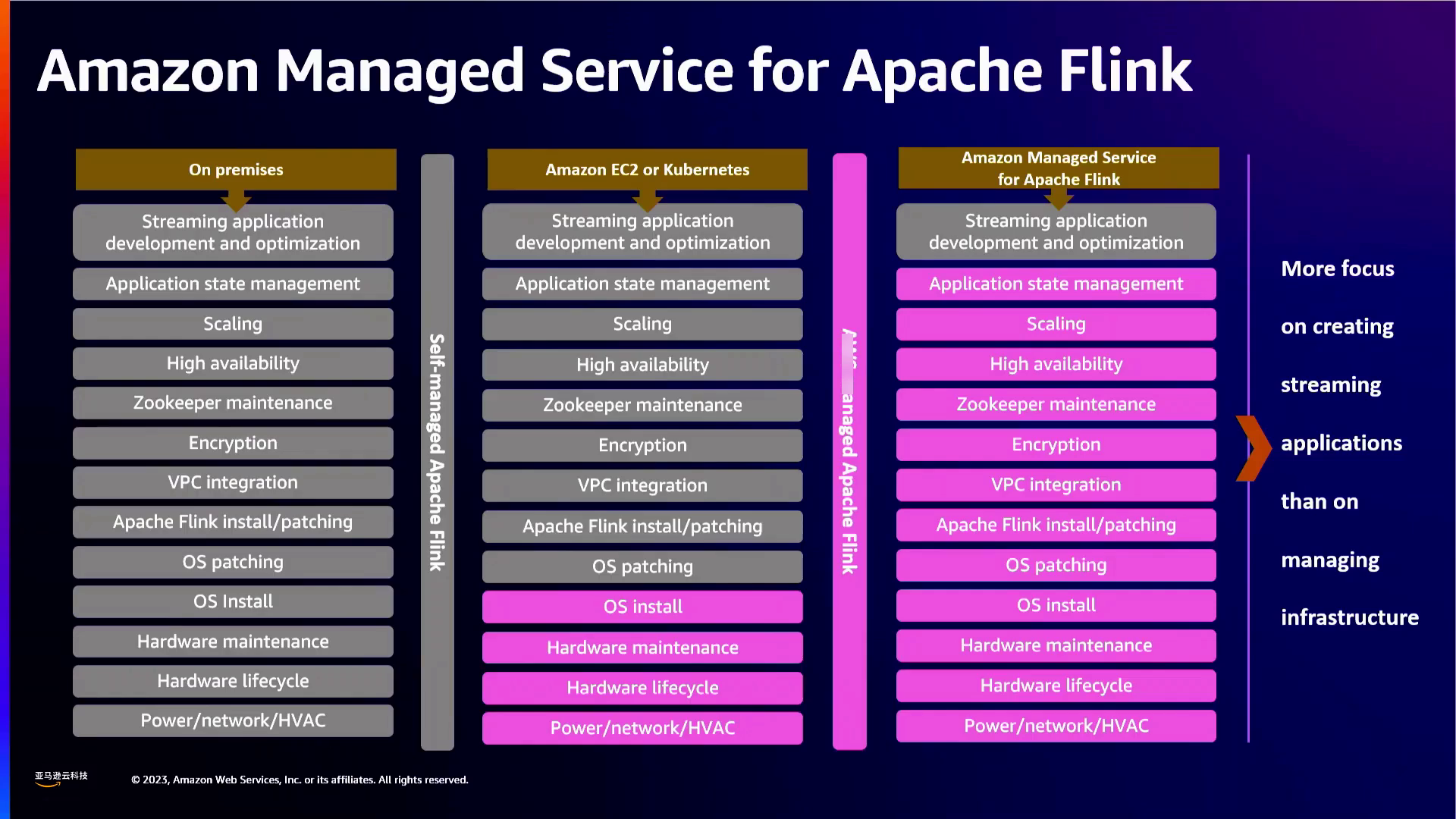
总的来说,apache flink的集成cdc连接器与hudi等交易数据湖相结合,使得跨孤岛的实时数据集成成为可能,同时也降低了复杂性。通过将数据库更改流式传输到flink应用程序中,实现了对持续分析的支持。亚马逊云科技的托管服务,如msk、flink和athena,简化了部署架构。随着组织寻求更快地获取关于不断增长的数据量的见解,这是一种打破数据孤岛的现代解决方案。
下面是一些演讲现场的精彩瞬间:
实时跨区域数据流动和处理有助于获取深入洞察。

领导者表示,apache flink可以轻松扩展处理器以满足不断增加的数据处理需求,同时具有与各种亚马逊云科技数据源(如kinesis和rds)集成的流处理能力。

近日,领导者推出了amazon managed service for apache flink,被视为实现实时数据转换和分析的最简单方法。

领导者强调,客户需要一个能够在s3数据上执行更新、合并和删除操作的服务,以便实现实时同步并解决小文件问题。
领导者表示,hudi作为最受欢迎的开源表格式,与亚马逊云科技dms集成良好,并能指定主键以及用于变更数据捕获的列。

建议与会者先在re:invent参加活动,参观完现代应用和开源专区后再回答观众提问。
总结
这段视频探讨了如何利用apache flink的变更数据捕获(cdc)功能来解决数据孤岛问题并实现实时数据同步。演讲者首先概述了传统数据集成方法所面临的挑战,即采用每日批处理etl作业的方式。这种方法存在较高的延迟和有限的并行性问题。随后,他解释了一种更优的解决方案,即通过使用cdc技术捕捉数据更改,并仅递增地处理已更新的记录。
apache flink被描述为一个构建可扩展的有状态的流处理应用程序的理想框架。其cdc连接器允许直接从mysql和mongodb等数据库中提取更改事件。此外,flink的动态表提供了统一的流和批量处理模型,实现了对实时数据的持续查询。
在处理cdc流并将其写入目的地(例如数据湖)时,需要使用upsert语义来保持数据的一致性。这种支持upserts以及针对s3等对象存储的压缩的分布式数据湖格式包括apache hudi。flink还提供了用于将数据写入hudi表的连接器。
演讲者展示了一个参考架构,该架构使用了amazon[amazon rds](https://aws.amazon.com/rds/features/#easy_to_manage?&trk=fcbfde70-6c6d-4967-931b-1a4a4990c211&sc_channel=el " rds")、msk connect、flink和hudi ons3。数据库更改通过debezium流式传输到kafka,然后在flink studio笔记本中消费这些更改,并通过sql进行聚合,最终将这些数据插入到hudi表中。这样一来,数据湖就可以使用athena进行查询。
总的来说,flink的cdc连接器简化了实时数据提取的过程。当与事务性数据湖结合使用时,这可以构建实时数据管道,从而打破数据孤岛并实现系统同步。
演讲原文
想了解更多精彩完整内容吗?立即访问re:invent 官网中文网站!
2023亚马逊云科技re:invent全球大会 - 官方网站
点击此处,一键查看 re:invent 2023 所有热门发布
即刻注册亚马逊云科技账户,开启云端之旅!
【免费】亚马逊云科技中国区“40 余种核心云服务产品免费试用”
亚马逊云科技是谁?
亚马逊云科技(amazon web services)是全球云计算的开创者和引领者,自 2006 年以来一直以不断创新、技术领先、服务丰富、应用广泛而享誉业界。亚马逊云科技可以支持几乎云上任意工作负载。亚马逊云科技目前提供超过 200 项全功能的服务,涵盖计算、存储、网络、数据库、数据分析、机器人、机器学习与人工智能、物联网、移动、安全、混合云、虚拟现实与增强现实、媒体,以及应用开发、部署与管理等方面;基础设施遍及 31 个地理区域的 99 个可用区,并计划新建 4 个区域和 12 个可用区。全球数百万客户,从初创公司、中小企业,到大型企业和政府机构都信赖亚马逊云科技,通过亚马逊云科技的服务强化其基础设施,提高敏捷性,降低成本,加快创新,提升竞争力,实现业务成长和成功。

发表评论