引言
在设计和出版行业中,字体的选择和使用对最终作品的质量有着重要影响。然而,有时我们可能会遇到包含未知字体的pdf文件,这使得我们无法准确地复制或修改文档。获取pdf中的字体信息可以解决这个问题,让我们能够更好地处理这些文件。无论是用于重新设计、文档翻译还是个人学习,了解如何获取pdf中的字体信息都是一项非常有用的技能。本文将介绍如何通过c#获取pdf中指定文本或所有文本的字体信息。
获取字体的操作需要用到第三方库 spire.pdf for .net,我们可以通过以下链接下载产品包后手动添加引用,或者直接通过nuget安装。
点击下载 spire.pdf for.net
c# 获取pdf中指定文本的字体信息
通过使用spire.pdf for .net提供的 pdftextfragment 类下的各属性,我们可以获取字体名称、大小、样式和颜色。主要实现步骤如下
- 加载 pdf 文件,然后获取指定页面。
- 通过
pdftextfinder.find()方法查找指定文本,并返回一个pdftextfragment对象。 - 创建一个
stringbuilder实例来存储信息。 - 遍历所有查找到的文本
- 通过
pdftextfragment.text属性获取找到的文本内容。 - 通过
pdftextfragment.textstates[0].fontname属性获取找到的文本的字体名称。 - 通过
pdftextfragment.textstates[0].fontsize属性获取找到的文本的字体大小。 - 通过
pdftextfragment.textstates[0].fontfamily属性获取找到的文本的字体类型。 - 通过
pdftextfragment.textstates[0].isbold和pdftextfragment.textstates[0].issimulatebold属性指示字体是否加粗或模拟加粗(字体样式设置为填充和描边)。 - 通过
pdftextfragment.textstates[0].isitalic属性指示字体是否为斜体. - 使用
pdftextfragment.textstates[0].foregroundcolor属性获取找到的文本的字体颜色。 - 将获取到的字体信息添加到
stringbuilder实例中,然后写入 txt 文件。
c#代码:
using spire.pdf;
using spire.pdf.texts;
using system.collections.generic;
using system.drawing;
using system.io;
using system.text;
namespace gettextfont
{
class program
{
static void main(string[] args)
{
// 加载pdf文件
pdfdocument pdf = new pdfdocument();
pdf.loadfromfile("e:\\pythonpdf\\南极.pdf");
// 获取第一页
pdfpagebase page = pdf.pages[0];
// 创建pdftextfinder实例
pdftextfinder finds = new pdftextfinder(page);
// 查找页面上指定文本
finds.options.parameter = textfindparameter.none;
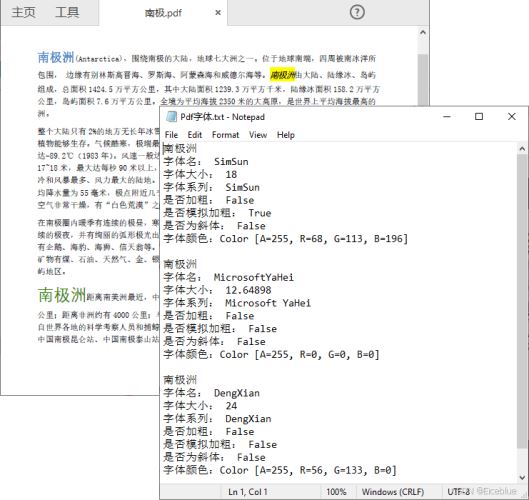
list<pdftextfragment> result = finds.find("南极洲");
// 创建stringbuilder实例
stringbuilder str = new stringbuilder();
// 遍历所有查找到的文本
foreach (pdftextfragment find in result)
{
// 获取文本
string text = find.text;
// 获取字体名
string fontname = find.textstates[0].fontname;
// 获取字体大小
float fontsize = find.textstates[0].fontsize;
// 获取字体类型
string fontfamily = find.textstates[0].fontfamily;
// 判断是否加粗或模拟加粗
bool isbold = find.textstates[0].isbold;
bool issimulatebold = find.textstates[0].issimulatebold;
// 判断是否为斜体
bool isitalic = find.textstates[0].isitalic;
// 获取字体颜色
color color = find.textstates[0].foregroundcolor;
// 将获取到的信息添加到stringbuilder实例中
str.appendline(text);
str.appendline("字体名: " + fontname);
str.appendline("字体大小: " + fontsize);
str.appendline("字体系列: " + fontfamily);
str.appendline("是否加粗: " + isbold);
str.appendline("是否模拟加粗: " + issimulatebold);
str.appendline("是否为斜体: " + isitalic);
str.appendline("字体颜色:" + color);
str.appendline(" ");
}
// 写入一个txt文件
file.writealltext("pdf字体.txt", str.tostring());
}
}
}
c# 获取pdf文档中用到的所有字体信息
pdfusedfont 类表示pdf文档中使用到的字体,它提供了不同的属性来帮助我们获取字体名称、大小、类型和样式等。主要实现步骤如下:
- 加载 pdf 文件。
- 通过
pdfdocument.usedfonts属性获取 pdf 文件中使用的所有字体。 - 创建一个
stringbuilder实例来存储信息。 - 遍历所有使用到的字体。
- 通过
pdfusedfont.name属性获取字体名称。 - 通过
pdfusedfont.size属性获取字体大小。 - 通过
pdfusedfont.type属性获取字体类型。 - 通过
pdfusedfont.style属性获取字体样式。 - 将获取到的字体信息添加到
stringbuilder实例中,然后写入 txt 文件。
c#代码:
using spire.pdf;
using spire.pdf.graphics.fonts;
using spire.pdf.graphics;
using system.io;
using system.text;
namespace gettextfont
{
class program
{
static void main(string[] args)
{
// 加载pdf文件
pdfdocument pdf = new pdfdocument();
pdf.loadfromfile("e:\\pythonpdf\\南极.pdf");
// 获取pdf文件中使用到的字体
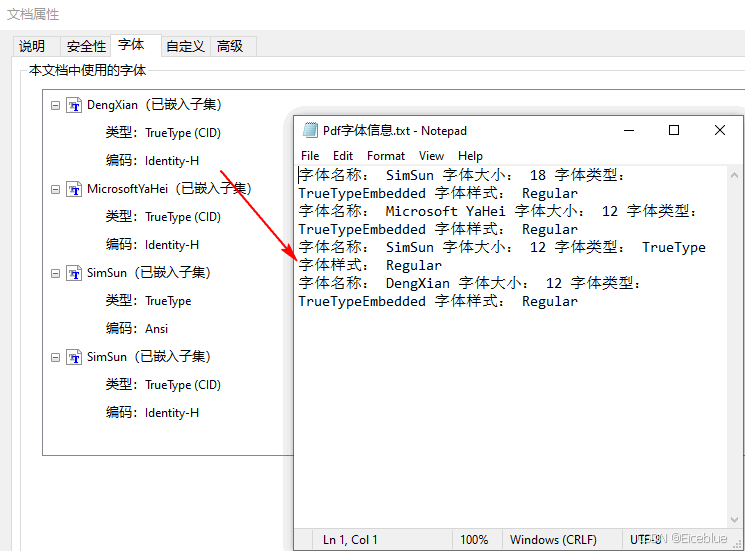
pdfusedfont[] fonts = pdf.usedfonts;
// 创建stringbuilder实例
stringbuilder str = new stringbuilder();
// 遍历所有使用到的字体
foreach (pdfusedfont font in fonts)
{
// 获取字体名
string name = font.name;
// 获取字体大小
float size = font.size;
// 获取字体类型
pdffonttype type = font.type;
// 获取字体样式
pdffontstyle style = font.style;
// 将获取到的信息添加到stringbuilder实例中
str.appendline("字体名称: " + name + " 字体大小: " + size + " 字体类型: " + type + " 字体样式: " + style);
}
// 写入一个txt文件
file.writealltext("pdf字体信息.txt", str.tostring());
}
}
}
到此这篇关于通过c#获取pdf中指定文本或所有文本的字体信息的文章就介绍到这了,更多相关c#获取pdf文本信息内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论