前言
在处理pdf文档时,有时需要精确地裁剪页面以适应特定需求,比如去除广告、背景信息或者仅仅是为了简化文档内容。
本文将指导如何使用免费.net控件通过c#实现裁剪pdf页面。
c# 裁剪pdf页面
free spire.pdf for .net这个库提供了一个非常简单的接口来实现裁剪pdf页面指定区域,具体操作如下:
- 通过
loadfromfile()方法加载pdf文档; - 获取指定pdf页面;
- 指定一个区域,然后通过
pdfpagebase.cropbox属性裁剪指定区域; - 通过
savetofile()方法保存裁剪后的pdf文档。
示例代码如下:
using system.drawing;
using spire.pdf;
namespace croppdfpage
{
class program
{
static void main(string[] args)
{
//加载pdf文档
pdfdocument pdf = new pdfdocument();
pdf.loadfromfile("示例.pdf");
//获取第二页
pdfpagebase page = pdf.pages[1];
//按指定区域裁剪pdf页面
page.cropbox = new rectanglef(270, 130, 400, 480);
//保存裁剪后的文档
pdf.savetofile("裁剪pdf.pdf");
pdf.close();
}
}
}
裁剪前后对比:

拓展:c#实现pdf按页分割文件,以及分页合并
效果
下面就是通过pdf插件进行按页进行文件分割输出
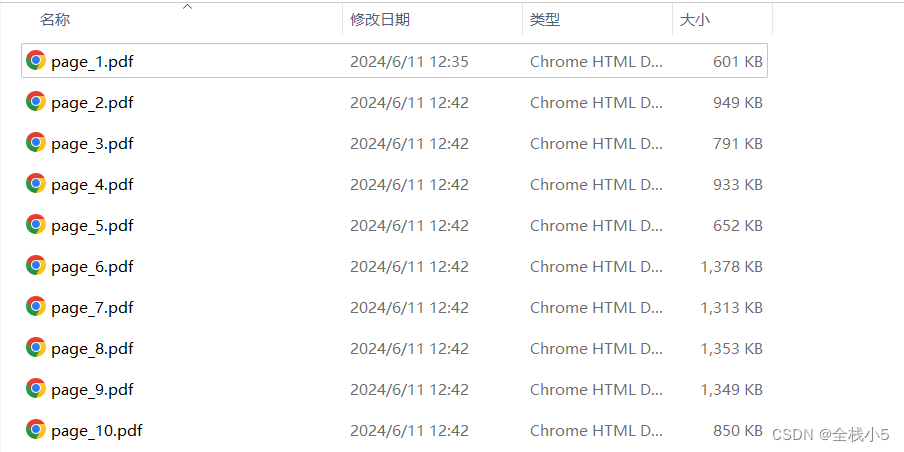
单页分割
插件命名空间
using itextsharp.text; using itextsharp.text.pdf;
目标分割pdf文件、创建输出文件所在的文件夹、itextsharp插件操作pdf分割
// 目标分割pdf文件
string inputfilepath = @"你自己的pdf文件物理路径.pdf";
// 创建输出文件所在文件夹
string outputfolder = "newfile";
string rootpath = system.io.directory.getcurrentdirectory();
string folderall = path.combine(rootpath, outputfolder);
if (!directory.exists(folderall))
{
directory.createdirectory(folderall);
}
// 操作pdf分割
using (pdfreader reader = new pdfreader(inputfilepath))
{
for (int i = 1; i <= reader.numberofpages; i++)
{
string newfilepath = path.combine(outputfolder, $"page_{i}.pdf");
using (document document = new document())
using (pdfcopy copy = new pdfcopy(document, new filestream(newfilepath, filemode.create)))
{
document.open();
copy.addpage(copy.getimportedpage(reader, i));
document.close();
}
}
}
console.writeline("pdf 分割完成!");
文件合并
// 目标合并pdf文件
string[] sourcefiles = new string[] {
@"你的pdf文件1.pdf",
@"你的pdf文件2.pdf"
};
// 创建输出文件所在文件夹
string outputfolder = "newfile";
string rootpath = system.io.directory.getcurrentdirectory();
string folderall = path.combine(rootpath, outputfolder);
if (!directory.exists(folderall))
{
directory.createdirectory(folderall);
}
using (document document = new document())
{
pdfcopy copy = new pdfcopy(document, new filestream($"{outputfolder}\\page_1_20_add_21_40.pdf", filemode.create));
document.open();
foreach (string file in sourcefiles)
{
using (pdfreader reader = new pdfreader(file))
{
for (int i = 1; i <= reader.numberofpages; i++)
{
copy.addpage(copy.getimportedpage(reader, i));
}
}
}
document.close();
copy.close();
}
多页分割
根据分页范围进行分割文件,比如:1-10页分割一个文件,即10页分割一个文件
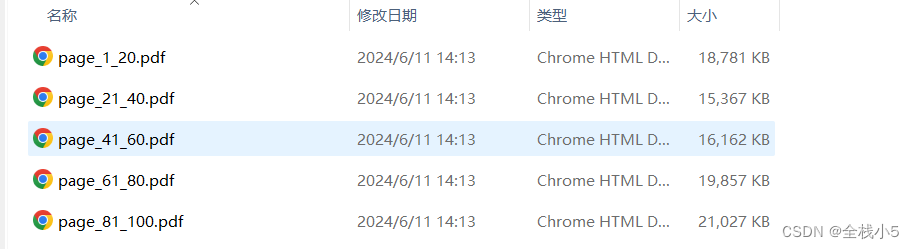
// 目标分割pdf文件
string inputfilepath = @"你自己的pdf文件物理路径.pdf";
// 创建输出文件所在文件夹
string outputfolder = "newfile";
string rootpath = system.io.directory.getcurrentdirectory();
string folderall = path.combine(rootpath, outputfolder);
if (!directory.exists(folderall))
{
directory.createdirectory(folderall);
}
// 操作pdf分割
using (pdfreader reader = new pdfreader(inputfilepath))
{
int startpage = 1;
int pagesize = 0;
int totalpage = 0;
int unitsize = 20;
int remainder = 0;
totalpage = reader.numberofpages;
pagesize = totalpage / unitsize;
remainder = totalpage % unitsize;
// 足够20的分割文件
int currentindex = 0;
for (int index = 0; index < pagesize; index++)
{
currentindex = (index + 1);
using (document document = new document())
{
int sv = (startpage + index * unitsize);
int ev = ((index + 1) * unitsize);
string newfilepath = path.combine(outputfolder, $"page_{sv}_{ev}.pdf");
pdfcopy copy = new pdfcopy(document, new filestream(newfilepath, filemode.create));
document.open();
for (int i = sv; i <= ev; i++)
{
copy.addpage(copy.getimportedpage(reader, i));
}
document.close();
copy.close();
}
}
// 不足20页的文件
using (document document = new document())
{
int sv = (startpage + pagesize * unitsize);
int ev = (pagesize * unitsize + remainder);
string newfilepath = path.combine(outputfolder, $"page_size_{sv}_{ev}.pdf");
pdfcopy copy = new pdfcopy(document, new filestream(newfilepath, filemode.create));
document.open();
for (int i = sv; i <= ev; i++)
{
copy.addpage(copy.getimportedpage(reader, i));
}
document.close();
copy.close();
}
}
}
插件说明
itextsharp 是一个开源的 pdf 处理库,用于在 c# 程序中创建、编辑和处理 pdf 文件。它提供了丰富的功能和 api,使开发者能够进行各种 pdf 文件操作,包括创建 pdf、添加文本、插入图片、设置页面布局等功能。itextsharp 库基于 itext 库的 c# 版本,是在 c# 平台上操作 pdf 文件的常用工具之一。
以下是 itextsharp 的一些基本功能:
1、创建 pdf 文件
使用 itextsharp 可以在 c# 中轻松地创建新的 pdf 文件,可以通过代码指定文档结构、页面布局、文本样式等。
2、编辑 pdf 文件内容
可以向已有的 pdf 文件中添加文本、图片、表格等内容,也可以修改现有内容,实现文档内容的动态更新。
3、处理 pdf 文件
itextsharp 提供了丰富的 api,可以处理 pdf 文件中的文本、表格、图形等元素,实现对 pdf 内容的精确控制和调整。
4、设置页面属性
可以通过 itextsharp 设置页面尺寸、方向、边距等属性,定制化生成的 pdf 文档格式。
5、添加水印和加密
可以在 pdf 文件中添加水印、数字签名,也可以通过 itextsharp 对 pdf 文件进行加密保护,确保 pdf 文件的安全性。
6、pdf 文件合并和拆分
itextsharp 提供了合并多个 pdf 文件和拆分单个 pdf 文件的功能,方便进行文档的整合和拆分操作。
到此这篇关于通过c#实现裁剪pdf页面功能的文章就介绍到这了,更多相关c#裁剪pdf页面内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论