目录
前言
ce模块通常只注意了通道特征,但在视觉任务中,空间任务通常更为重要,是不可忽略的,因此cbam将通道注意力机制与空间注意力机制进行串联,充分关注特征信息。
什么是空间特征?在深度学习中,空间特征是指描述输入数据在空间维度上的特征信息。对于图像数据而言,空间特征可以涵盖多种信息,包括边缘、角点、纹理、颜色等。这些特征信息可以帮助模型理解图像中不同区域的内容和结构,从而实现诸如目标检测、图像分割、图像分类等任务。在深度学习模型中,通常通过卷积神经网络(cnn)等结构来提取和学习空间特征,这些特征对于模型的表现和性能具有重要的影响。
什么是空间注意力机制?空间注意力机制是一种注意力机制,用于在深度学习模型中对输入数据的不同空间位置进行加权,以便模型能够更加关注重要的空间位置,从而提高模型的性能和泛化能力。空间注意力机制通常应用在图像处理或自然语言处理等任务中,能够有效地捕捉输入数据在空间维度上的相关性。
在空间注意力机制中,模型会学习到针对输入数据中不同空间位置的权重,以确定哪些位置对于任务是最重要的。这些权重可以根据输入数据的内容和上下文来自适应地调整,从而实现对不同空间位置的加权组合。通过引入空间注意力机制,模型可以更好地捕捉数据的局部特征和全局结构,从而提高模型的性能和泛化能力。
|
| 通道注意力机制 | 空间注意力机制 |
| 关注对象 | 关注于不同特征通道的重要性 | 关注于输入数据中不同位置的重要性 |
| 操作对象 | 输入数据的通道维度 | 输入数据的空间维度 |
| 应用范围 | 处理具有多个特征通道的数据 | 处理具有空间结构的数据 |
一、cbam结构
cbam 是由channel attention moduel和spatial attention module构成,结构如图1所示。channel attention moduel,结构如图2所示。对输入的特征图分别同时进行最大池化和平均池化,通过对输入形状为(b,c,h,w)的特征图进行最大池化或平均池化操作,将每个通道(c)在空间维度上的信息进行压缩,最终得到形状为(b,c,1,1)的输出,在这个过程中,对于每个通道而言,它的空间信息被最大池化或者平均池化操作压缩为一个单独的值,从而实现了对全局空间信息的压缩和提取。这一步旨在将特征图上的信息集中在通道上,从而更好的在通道上捕捉到输入的特征图的特征信息,利用这两个特征可以大大提高网络的表示能力。共享网络由两个卷积和一个relu激活函数构成,先降维再升维,这一步旨在减少参数开销,其中mlp中的权重是共享的,所用的输入都用相同的w0和w1权重矩阵进行计算处理,将共享网络应用于每个特征描述子后,使用元素求和(+)来合并输出特征向量,再将输出的特征向量通过sigmoid函数生成权重向量,确保它们的总和为1。spatial attention module,结构如图3所示。对输入的特征图沿通道轴应用平均池化和最大池化,通过平均池化和最大池化操作,可以将输入张量的通道维度(c)压缩为1,从而将全局通道信息整合为一个单一的通道特征图,形状为(b,1,h,w)。在这个过程中,对于每个样本(b),模型会对该样本在通道上的特征进行平均池化,从而实现对全局通道信息的压缩合并。这种操作有助于减少参数数量、减小计算复杂度,同时保留重要的通道特征信息。将获得的两个矩阵在通道上拼接起来(torch.cat),并通过一个卷积层,将通道数再次变成1,使获得的特征信息全部分布在一个通道上,再将通过卷积层的输出通过sigmoid函数生成权重向量。cbam则是将在channel attention module得到的通道注意力权重乘以输入的原始特征图。这一步用于调整每个通道的特征值,强调重要通道的信息,抑制不重要通道的信息。再将之前在spatial attention module得到的空间注意力权重乘以通过通道注意力机制得到的特征图,最终即得到最终输出结果。(通道和空间注意力机制可以并行或者顺序放置,发现顺序排列比平行排列产生更好结果,我们实验结果表明,通道优先顺序略优于空间优先顺序)
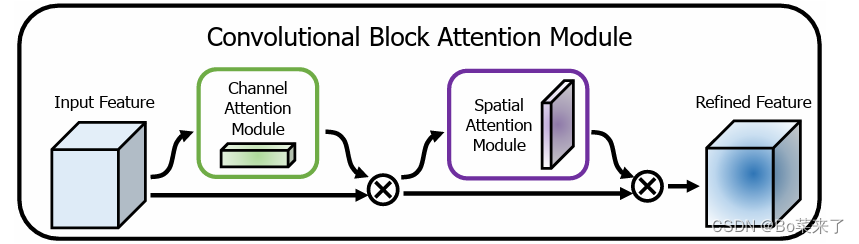
图1 cbam结构
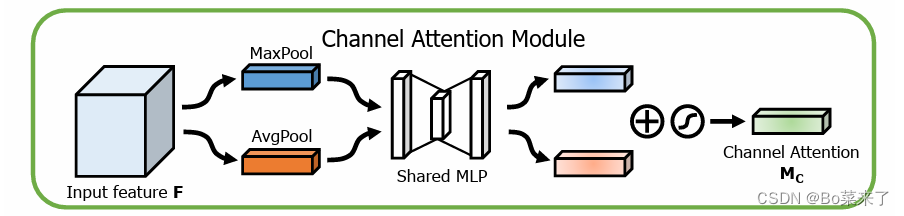
图2 通道注意力机制
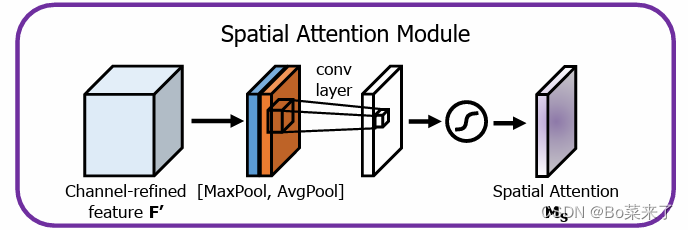
图3 空间注意力机制
精读:cbam(convolutional block attention module)是一个集成在卷积神经网络中的注意力模块,目的是增强模型的特征表达能力,通过强调重要的特征并抑制不重要的特征。cbam 通过两个主要部分工作:channel attention module 和 spatial attention module。下面详细解释这两部分的工作原理及其互动方式。
channel attention module (cam)的核心目的是强调那些对当前任务更重要的特征通道。它通过以下步骤实现:
1.特征压缩:对输入的特征图x,形状为(b,c,h,w),进行最大池化和平均池化。这两种池化操作都在空间维度h×w 上进行,输出的结果是两个形状为(b,c,1,1)的特征图,即每个通道压缩成一个单独的值,分别代表了该通道的最大值和平均值。通过以下步骤实现:
2.维度转换:通过一个小型神经网络(通常是两层mlp),首先将通道数降维以减少参数量,然后再升维恢复到原始通道数。这个小网络包括两个全连接层和一个relu激活函数。
3.特征融合与激活:将最大池化和平均池化得到的两个特征图通过共享的mlp处理后,结果相加并通过sigmoid函数,得到每个通道的权重系数。
spatial attention module (sam) 的目的是在空间上强调更为关键的区域。它的步骤包括:
1.通道压缩:将处理后的特征图x 进行最大池化和平均池化,但这次是沿着通道轴 c,从而压缩所有通道信息到一个单通道图像中。操作结果是两个形状为(b,1,h,w)的特征图。
2. 特征拼接与卷积:将上述两个特征图在通道维度上拼接,然后通过一个卷积层将通道数变为1,最终通过sigmoid函数得到每个空间位置的权重系数。
整合与顺序
1.特征图权重调整:首先,通过channel attention module得到的通道权重乘以原始的特征图x,调整每个通道的重要性。然后,将这个调整后的特征图输入到spatial attention module,进一步调整每个位置的重要性。
2. 顺序优化:实验显示,首先应用channel attention(通道注意力)后再应用spatial attention(空间注意力)通常效果更好。这是因为,一旦我们确定了最重要的特征通道,再去调整这些通道中各个位置的重要性,能够更精确地强化有用的信息,抑制不必要的信息。
二、cbam计算流程
如图 1所示,给定一个输入![]() ,
,![]() 为cbam通过 channel attention moduel获得,在channel attention moduel中,先通过全局平均池化和全局最大池化分别获得
为cbam通过 channel attention moduel获得,在channel attention moduel中,先通过全局平均池化和全局最大池化分别获得![]() 和
和![]() ,其中
,其中![]() 为sigmoid函数,mlp结构为conv-relu-conv,
为sigmoid函数,mlp结构为conv-relu-conv,![]() ,
,![]() ,
,![]() ,
,![]() 为mlp的权重。
为mlp的权重。
![]()
![]()
![]()
![]()
![]() 为cbam通过spatial attention module获得,在spatial attention module中,先通过全局平均池化和全局最大池化分别获得
为cbam通过spatial attention module获得,在spatial attention module中,先通过全局平均池化和全局最大池化分别获得![]() 和
和![]() ,其中
,其中![]() 为sigmoid函数,
为sigmoid函数,![]() 表示滤波器为7*7的卷积运算。
表示滤波器为7*7的卷积运算。
![]()
![]()
![]()
将f通过channel attention moduel得到的通道注意力权重![]() 乘以输入的原始特征图f,以获得
乘以输入的原始特征图f,以获得![]() ,再将
,再将![]() 通过spatial attention module得到的空间注意力权重
通过spatial attention module得到的空间注意力权重![]() 乘以通过通道注意力机制得到的特征图
乘以通过通道注意力机制得到的特征图![]() ,其中
,其中![]() 为元素乘法,
为元素乘法,![]() 为最终输出
为最终输出
![]()
![]()
三、cbam参数
利用thop库的profile函数计算flops和param。input:(512,7,7)。
| module | flops | param |
| cbam | 95938.0 | 32866.0 |
四、代码详解
import torch
from torch import nn
from torch.nn import init
class channelattention(nn.module):
def __init__(self, in_planes, ratio=16):
super(channelattention, self).__init__()
self.avg_pool = nn.adaptiveavgpool2d(1)
self.max_pool = nn.adaptivemaxpool2d(1)
self.mlp=nn.sequential(
nn.conv2d(in_planes, in_planes // ratio, 1, bias=false),
nn.relu(),
nn.conv2d(in_planes // ratio, in_planes, 1, bias=false)
)
self.sigmoid = nn.sigmoid()
def forward(self, x):
avg_out = self.mlp(self.avg_pool(x)) # 通过平均池化压缩全局空间信息: (b,c,h,w)--> (b,c,1,1) ,然后通过mlp降维升维:(b,c,1,1)
max_out = self.mlp(self.max_pool(x)) # 通过最大池化压缩全局空间信息: (b,c,h,w)--> (b,c,1,1) ,然后通过mlp降维升维:(b,c,1,1)
out = avg_out + max_out
return self.sigmoid(out)
class spatialattention(nn.module):
def __init__(self, kernel_size=7):
super(spatialattention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.conv2d(2, 1, kernel_size, padding=padding, bias=false)
self.sigmoid = nn.sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=true) # 通过平均池化压缩全局通道信息:(b,c,h,w)-->(b,1,h,w)
max_out, _ = torch.max(x, dim=1, keepdim=true) # 通过最大池化压缩全局通道信息:(b,c,h,w)-->(b,1,h,w)
x = torch.cat([avg_out, max_out], dim=1) # 在通道上拼接两个矩阵:(b,2,h,w)
x = self.conv1(x) # 通过卷积层得到注意力权重:(b,2,h,w)-->(b,1,h,w)
return self.sigmoid(x)
class cbam(nn.module):
def __init__(self, in_planes, ratio=16, kernel_size=7):
super(cbam, self).__init__()
self.ca = channelattention(in_planes, ratio)
self.sa = spatialattention(kernel_size)
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not none:
init.constant_(m.bias, 0)
elif isinstance(m, nn.batchnorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.linear):
init.normal_(m.weight, std=0.001)
if m.bias is not none:
init.constant_(m.bias, 0)
def forward(self, x):
out = x * self.ca(x) # 通过通道注意力机制得到的特征图,x:(b,c,h,w),ca(x):(b,c,1,1),out:(b,c,h,w)
result = out * self.sa(out) # 通过空间注意力机制得到的特征图,out:(b,c,h,w),sa(out):(b,1,h,w),result:(b,c,h,w)
return result
if __name__ == '__main__':
from torchsummary import summary
from thop import profile
model = cbam(in_planes=512)
# summary(model, (512, 7, 7), device='cpu', batch_size=1)
flops, params = profile(model, inputs=(torch.randn(1, 512, 7, 7),))
print(f"flops: {flops}, params: {params}")


![常用数据聚类算法总结记录与代码实现[K-means/层次聚类/DBSACN/高斯混合模型(GMM)/密度峰值聚类/均值漂移聚类/谱聚类等]](https://images.3wcode.com/3wcode/20240804/s_0_202408042021086355.png)
发表评论