一、实验目的:
1
、掌握
mlp
和
bp
神经网络流程,并实现分类任务
2
、掌握
k-means
算法流程,并实现聚类任务
二、实验任务
1.使用mlp实现水果分类:
实验描述:
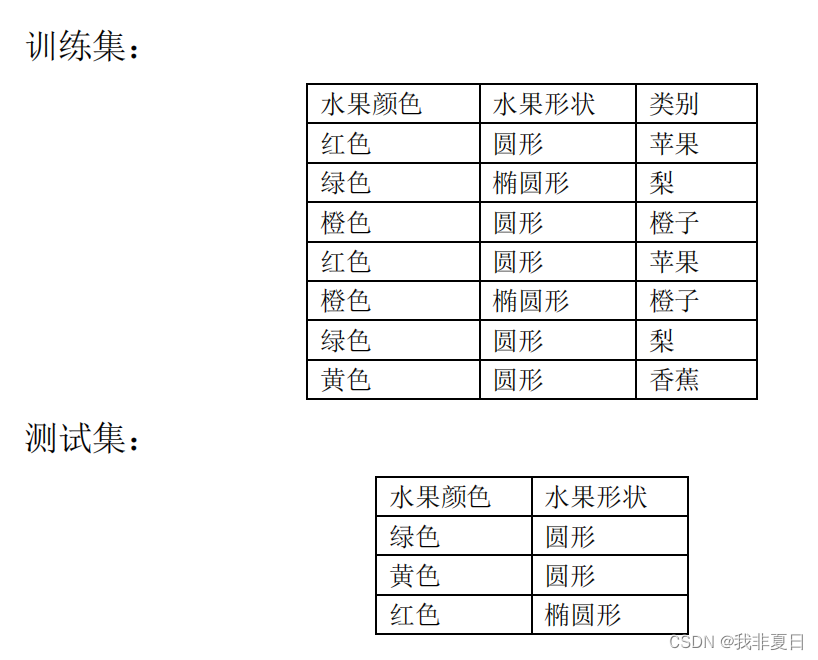
有一个关于水果的数据集,其中包含两个特征:水果的颜色和形状, 使用多层感知机(mlp
)对水果进行分类。数据集分为训练集和测试 集,使用训练集训练 mlp
神经网络模型,使用测试集评估模型的性能,预测给定水果的类别。
实验思路:
实验代码:
#mlp 实现水果分类
import pandas as pd
from sklearn.preprocessing import labelencoder, onehotencoder
from sklearn.compose import columntransformer
from sklearn.neural_network import mlpclassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据
train_data = pd.dataframe({
'水果颜色': ['红色', '绿色', '橙色', '红色', '橙色', '绿色', '黄色'],
'水果形状': ['圆形', '椭圆形', '圆形', '圆形', '椭圆形', '圆形', '圆形'],
'类别': ['苹果', '梨', '橙子', '苹果', '橙子', '梨', '香蕉']
})
test_data = pd.dataframe({
'水果颜色': ['绿色', '黄色', '红色'],
'水果形状': ['圆形', '圆形', '椭圆形']
})
# 数据预处理
label_encoder = labelencoder()
one_hot_encoder = onehotencoder(sparse=false)
# 定义特征和标签的列
feature_cols = ['水果颜色', '水果形状']
label_col = ['类别']
# 对特征和标签进行编码
ct = columntransformer(
[('one_hot_encoder', one_hot_encoder, feature_cols)],
remainder='passthrough'
)
x_train = ct.fit_transform(train_data[feature_cols])
y_train = label_encoder.fit_transform(train_data[label_col])
x_test = ct.transform(test_data[feature_cols])
# 构建mlp模型
mlp = mlpclassifier(hidden_layer_sizes=(10,), max_iter=1000)
# 训练模型
mlp.fit(x_train, y_train)
# 预测
y_pred = mlp.predict(x_test)
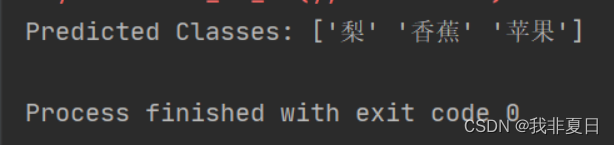
# 评估模型(但测试集没有真实的标签,所以我们这里只打印预测结果)
print("predicted classes:", label_encoder.inverse_transform(y_pred))
# 如果有真实的测试集标签,可以这样计算准确率
# y_test = label_encoder.transform(test_data['真实的类别列']) # 假设我们有一个真实的类别列
# accuracy = accuracy_score(y_test, y_pred)
# print("accuracy:", accuracy)实验结果:
2.使用bp神经网络实现特征分类:
实验描述:
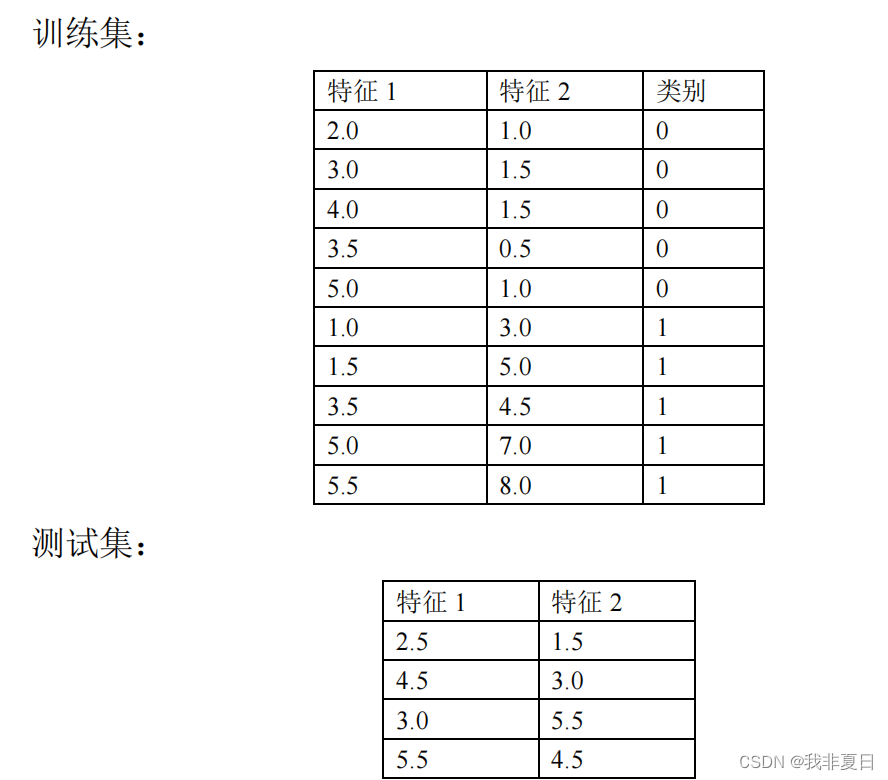
有一个包含两个特征的数据集,其中每个数据点属于两个类别之一, 使用 bp
神经网络对特征进行分类。数据集分为训练集和测试集,使
用训练集训练
bp
神经网络模型,使用测试集评估模型的性能,预测 给定特征的类别。
实验思路:
实验代码:
import numpy as np
from sklearn.neural_network import mlpclassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载和预处理数据
x_train = np.array([[2.0, 1.0], [3.0, 1.5], [4.0, 1.5], [3.5, 0.5], [5.0, 1.0],
[1.0, 3.0], [1.5, 5.0], [3.5, 4.5], [5.0, 7.0], [5.5, 8.0]])
y_train = np.array([0, 0, 0, 0, 0, 1, 1, 1, 1, 1])
x_test = np.array([[2.5, 1.5], [4.5, 3.0], [3.0, 5.5], [5.5, 4.5]])
# 定义bp神经网络模型
mlp = mlpclassifier(hidden_layer_sizes=(10,), max_iter=1000, random_state=1)
# 训练模型
mlp.fit(x_train, y_train)
# 预测测试集
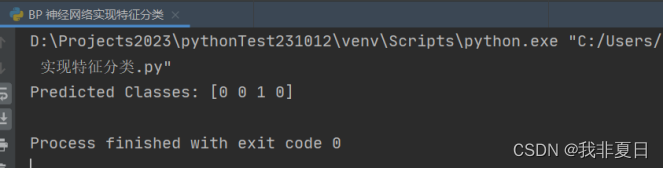
y_pred = mlp.predict(x_test)
# 评估模型性能(如果有真实的测试集标签)
# 这里我们假设真实的测试集标签是未知的,但如果有的话,你可以这样计算准确率:
# y_test_real = np.array([...]) # 这里填入真实的测试集标签
# accuracy = accuracy_score(y_test_real, y_pred)
# print("accuracy:", accuracy)
# 打印预测结果
print("predicted classes:", y_pred)实验结果:
3.编程实现k-means算法:
实验描述:
有一个包含身高和鞋码两个特征的数据表,使用
k-means
算法将数据 表中的个体聚类成 3 个簇。通过可视化展示聚类结果,观察个体如何 被聚类到不同的簇中。
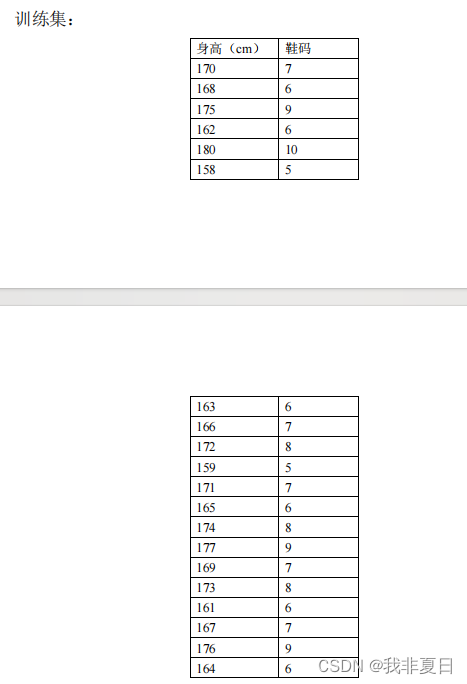
实验思路:
使用了 sklearn.cluster.kmeans 类来执行 k-means 聚类,并使用 standardscaler 对数据进行标准化处理。然后,绘制了散点图来可视化聚类结果,其中每个数据点都根据其聚类标签着色,聚类中心用黑色大圆点表示。
实验代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import kmeans
from sklearn.preprocessing import standardscaler
# 1. 准备数据集
data = {
'height': [170, 168, 175, 162, 180, 158, 163, 166, 172, 159, 171, 165, 174, 177, 169, 173, 161, 167, 176, 164],
'shoesize': [7, 6, 9, 6, 10, 5, 6, 7, 8, 5, 7, 6, 8, 9, 7, 8, 6, 7, 9, 6]
}
df = pd.dataframe(data)
# 2. 数据标准化(可选步骤,但通常有助于聚类)
scaler = standardscaler()
scaled_data = scaler.fit_transform(df)
# 3. 使用 sklearn 的 kmeans 类进行聚类
kmeans = kmeans(n_clusters=3, random_state=0)
kmeans.fit(scaled_data)
# 获取聚类标签和聚类中心
labels = kmeans.labels_
centroids = kmeans.cluster_centers_
# 将聚类标签添加到原始数据框
df['cluster'] = labels
# 4. 可视化聚类结果
plt.scatter(df['height'], df['shoesize'], c=df['cluster'], cmap='viridis', marker='o')
plt.scatter(centroids[:, 0], centroids[:, 1], c='black', s=200, alpha=0.5)
# 设置坐标轴范围
plt.xlim(150, 190) # 设置横坐标(身高)范围为150-190
plt.ylim(min(df['shoesize']) - 0.5, max(df['shoesize']) + 1.5) # 为鞋码增加一些缓冲
# 设置坐标轴刻度标签更细化
plt.xticks(np.arange(150, 190, 5)) # 横坐标(身高)每5cm一个刻度
plt.yticks(np.arange(min(df['shoesize']) - 0.5, max(df['shoesize']) + 1.5, 1)) # 纵坐标(鞋码)每1个单位一个刻度
plt.xlabel('height (cm)')
plt.ylabel('shoe size')
plt.title('k-means clustering of height and shoe size')
plt.grid(true) # 可选:添加网格线以使图表更清晰
plt.show()实验结果:
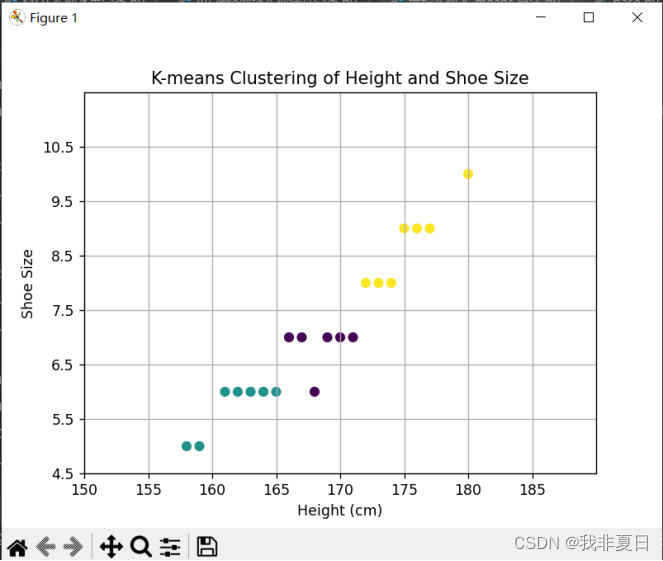
4.使用 sklearn 库中的 k-means 方法实现鸢尾花数据集聚类任务:
实验描述:
使用
sklearn
库中的
k-means
方法将鸢尾花数据集聚类成
3
个簇,并 通过可视化展示聚类结果。
实验思路:
实验代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import kmeans
from sklearn import datasets
from sklearn.decomposition import pca # 用于降维以便可视化
# 1. 加载鸢尾花数据集
iris = datasets.load_iris()
x = iris.data
y = iris.target
# 2. 使用 kmeans 进行聚类
kmeans = kmeans(n_clusters=3, random_state=0)
kmeans.fit(x)
# 3. 获取聚类标签
labels = kmeans.labels_
# 4. 由于有四个特征,我们使用 pca 将其降至二维以便可视化
pca = pca(n_components=2)
x_pca = pca.fit_transform(x)
# 5. 可视化聚类结果
plt.scatter(x_pca[labels == 0, 0], x_pca[labels == 0, 1], s=50, c='lightgreen', marker='s', label='cluster 1')
plt.scatter(x_pca[labels == 1, 0], x_pca[labels == 1, 1], s=50, c='orange', marker='o', label='cluster 2')
plt.scatter(x_pca[labels == 2, 0], x_pca[labels == 2, 1], s=50, c='lightblue', marker='v', label='cluster 3')
# 画出聚类中心
centers = pca.transform(kmeans.cluster_centers_)
plt.scatter(centers[:, 0], centers[:, 1], c='black', s=200, alpha=0.5, label='centroids')
plt.xlabel('pca feature 1')
plt.ylabel('pca feature 2')
plt.title('k-means clustering of iris dataset')
plt.legend()
plt.show()实验结果:
![常用数据聚类算法总结记录与代码实现[K-means/层次聚类/DBSACN/高斯混合模型(GMM)/密度峰值聚类/均值漂移聚类/谱聚类等]](https://images.3wcode.com/3wcode/20240804/s_0_202408042021086355.png)

发表评论