目录
聚类分析是什么
一、 定义和数据类型
聚类应用
- 市场营销: 帮助营销人员帮他们发现顾客中独特的群组,然后利用他们的知识发展目标营销项目
- 土地利用: 在土地观测数据库中发现相似的区域
- 保险: 识别平均索赔额度较高的机动车辆保险客户群组
- 城市规划: 通过房屋的类型、价值、地理位置识别相近的住房
- 地震研究: 沿着大陆断层聚类地震的震中
聚类分析方法的性能指标
- 可扩展性
- 自适应性
- 鲁棒性
- 可解释性
聚类分析中常用数据结构有数据矩阵和相异度矩阵
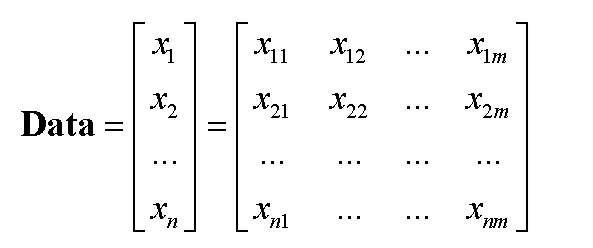
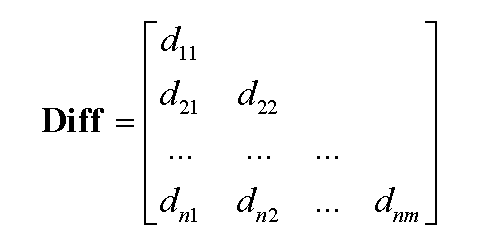
聚类分析方法分类
基于划分、基于分层、基于密度、基于网络、基于模型
二、k-means聚类算法
划分聚类方法对数据集进行聚类时包含三个要点
选定某种距离作为数据样本间的相似性度量
选择评价聚类性能的准则函数
选择某个初始分类,之后用迭代的方法得到聚类结果,使得评价聚类的准则函数取得最优值
标准测试函数:
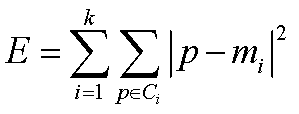
均值:
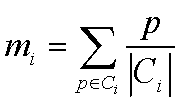
k-means算法流程:
输入:包含n个对象的数据集聚类个数k,最小误差e
输出:满足方差最小标准的k个聚类
①从n个数据对象中随机选出k个对象作为初始聚类的中心
②将每个类簇中的平均值作为度量基准,重新分配数据库中的
数据对象
③计算每个类簇的平均值,更新平均值
④循环(2)(3),直到每个类簇不在发生变化或者平均误差小于e
k-means聚类算法的特点
三、k-medoids算法
基本思想
k-medoids算法是一种聚类算法,与k-means算法相似,但它选择的中心点是簇中实际的数据点,而不是像k-means那样选择簇中心点的均值。
其基本思想是,给定一个数据集和聚类数k,随机选择k个点作为初始中心点,然后迭代以下两个步骤直到收敛:
1. 对于每个数据点,计算其与各中心点的距离,并将其划分到距离最近的簇中。
2. 对于每个簇,选择一个代表点(即中心点)来替换原来的中心点,使得代表点到簇中其他点的距离之和最小。
这个过程是一种优化过程,每次迭代会使得簇内的样本距离代表点更近,而簇间的距离更远,最终达到收敛。
与k-means算法不同,k-medoids算法不是适用于高维数据集,因为在高维空间中,欧几里得距离的性质会失效,需要使用更加复杂的距离度量方式。
k-medoids算法特点
四、送书活动

详情了解:《python从入门到精通(微课精编版)(软件开发视频大讲堂)》(前沿科技)【摘要 书评 试读】- 京东图书




发表评论