知识点
环境配置
-
torchtext :是一个用于自然语言处理(nlp)任务的库,它提供了丰富的功能,包括数据预处理、词汇构建、序列化和批处理等,特别适合于文本分类、情感分析、机器翻译等任务
-
jieba:是一个中文分词库,用于将中文文本切分成有意义的词语
-
sacrebleu:用于评估机器翻译质量的工具,主要通过计算bleu(bilingual evaluation understudy)得分来衡量生成文本与参考译文之间的相似度
-
spacy:是一个强大的自然语言处理库,支持70+语言的分词与训练。这里用于对英文进行分词
!pip install torchtext !pip install jieba !pip install sacrebleu
数据预处理
机器翻译任务的预处理是确保模型能够有效学习源语言到目标语言映射的关键步骤。预处理阶段通常包括多个步骤,旨在清理、标准化和转换数据,使之适合模型训练。以下是机器翻译任务预处理中常见的几个处理步骤:
- 清洗和规范化数据
- 去除无关信息:删除html标签、特殊字符、非文本内容等,确保文本的纯净性(本赛题的训练集中出现了非常多的脏数据,如“joey. (掌声) (掌声) 乔伊”、“thank you. (马嘶声) 谢谢你们”等这种声音词)
- 统一格式:转换所有文本为小写,确保一致性;标准化日期、数字等格式。
- 分句和分段:将长文本分割成句子或段落,便于处理和训练。
- 分词
- 分词:将句子分解成单词或词素(构成单词的基本组成部分,一个词素可以是一个完整的单词,也可以是单词的一部分,但每一个词素都至少携带一部分语义或语法信息),这是nlp中最基本的步骤之一。我们这里使用了使用
jieba对中文进行分词,使用spacy对英文进行分词。
- 分词:将句子分解成单词或词素(构成单词的基本组成部分,一个词素可以是一个完整的单词,也可以是单词的一部分,但每一个词素都至少携带一部分语义或语法信息),这是nlp中最基本的步骤之一。我们这里使用了使用
- 构建词汇表和词向量
- 词汇表构建:从训练数据中收集所有出现过的词汇,构建词汇表,并为每个词分配一个唯一的索引。
- 词向量:使用预训练的词向量或自己训练词向量,将词汇表中的词映射到高维空间中的向量,以捕捉语义信息(当前大模型领域训练的 embedding 模型就是用来完成此任务的)。
- 序列截断和填充
- 序列截断:限制输入序列的长度,过长的序列可能增加计算成本,同时也可能包含冗余信息。
- 序列填充:将所有序列填充至相同的长度,便于批量处理。通常使用
<pad>标记填充。
- 添加特殊标记
- 序列开始和结束标记:在序列两端添加
<sos>(sequence start)和<eos>(sequence end)标记,帮助模型识别序列的起始和结束。 - 未知词标记:为不在词汇表中的词添加
<unk>(unknown)标记,使模型能够处理未见过的词汇。
- 序列开始和结束标记:在序列两端添加
- 数据增强
- 随机替换或删除词:在训练数据中随机替换或删除一些词,增强模型的鲁棒性。
- 同义词替换:使用同义词替换原文中的词,增加训练数据的多样性。
- 数据分割
- 划分数据集:将数据划分为训练集、验证集和测试集,分别用于模型训练、参数调整和最终性能评估(该赛题中已划分好,不需要自己进行划分)
模型训练
-
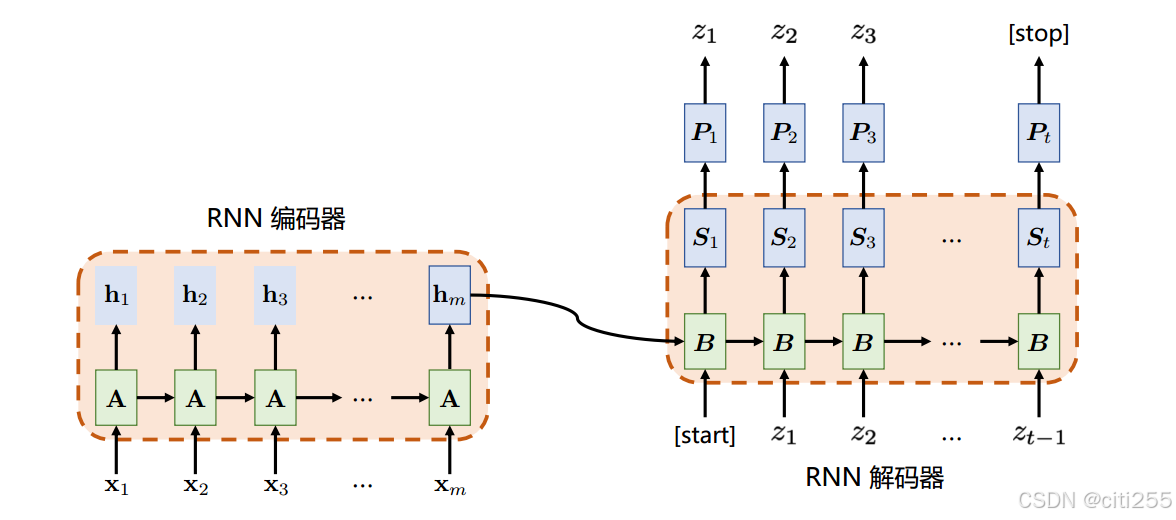
编码器-解码器模型(encoder-decoder paradigm)
又称seq2se模型。其基本思想是将源语言编码为类似信息传输中的数字信号,然后利用解码器对其进行转换,生成目标语言。
在当今主流的神经机器翻译系统中,编码器由词嵌入层和中间网络层组成。
-
词嵌入层(embedding)会将每个单词映射到多维实数表示空间;
-
中间层会对词嵌入向量进行更深层的抽象,得到输入单词序列的中间表示如:循环神经网络、卷积神经网络、自注意力机制等。
解码器则额外包含一个输出层,一个编码解码注意力子层。
-
-
常用模型
为了解决不定长输入的问题,出现了rnn、lstm、transformer等神经网络模型。
-
rnn(循环神经网络)
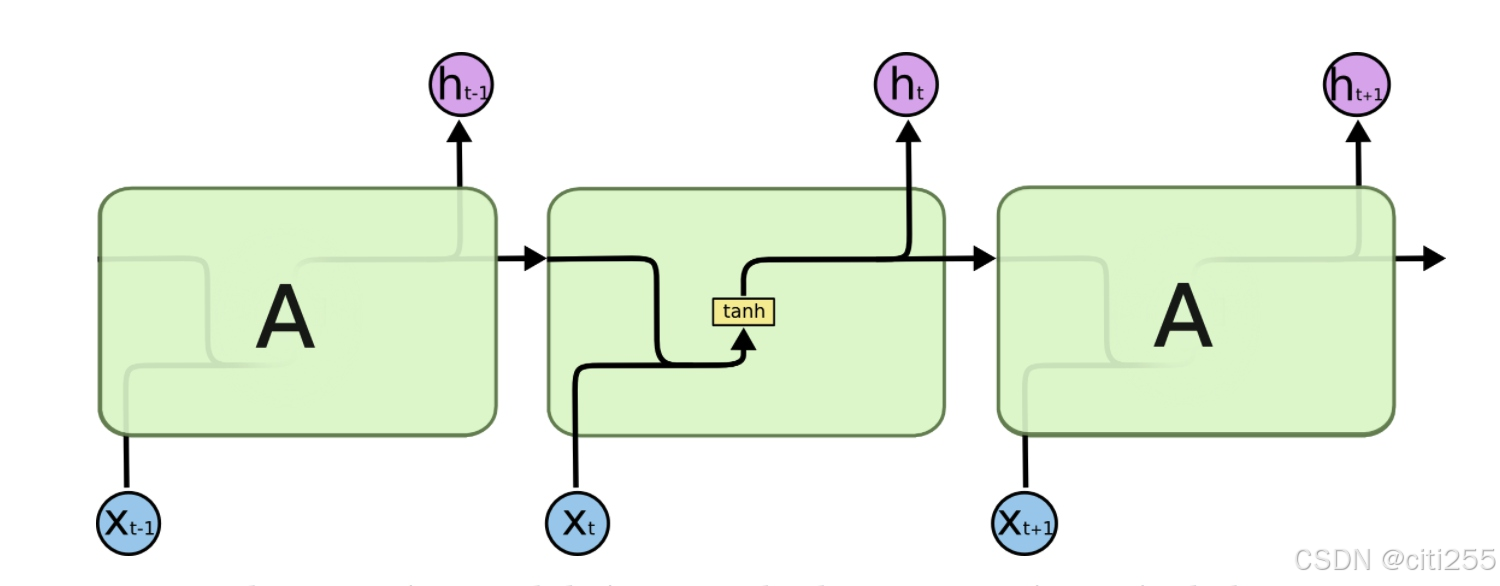
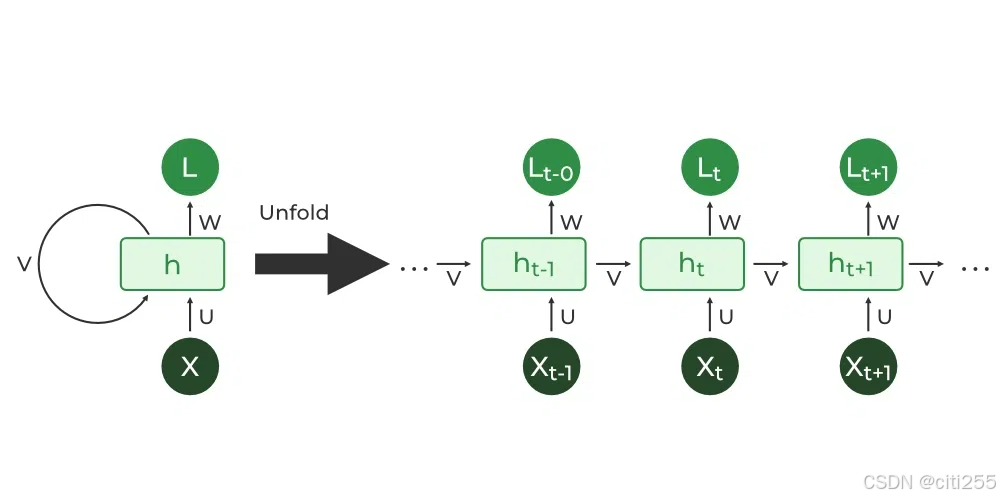
基于rnn的seq2seq模型:
模型参数始终不变,将源序列经过嵌入后逐步输入编码器,每次输入更新隐藏层状态。编码器在最后时刻的隐藏状态包含了所有输入的信息,解码器据此进行解码。
解码器首个输入通常为标记
<sos>或<bos>,之后则根据是否采用教师强制策略,选择以上一时间步的真实输出作为输入,或以目标序列的对应嵌入作为输入。由于将信息压缩在一个隐藏状态内,这种模型在在处理长序列时效果不佳。
此外,随着序列长度增加,容易出现梯度消失/爆炸的问题。
-
注意力机制
保存编码器输出的向量序列 h 1 , h 2 , h 3 , . . . , h m h_{1},h_{2},h_{3},...,h_{m} h1,h2,h3,...,hm,在解码时,依据解码端翻译的需要,自适应地从这个向量序列中查找对应的信息。
在后面的baseline中,具体方法主要是依据解码器当前时间步的隐藏状态,对编码器输出序列计算权重,计算加权和后输入gru层。
该机制有助于解决rnn由于将信息压缩在一个隐藏状态内而丢失长序列信息的问题。带注意力机制的rnn seq2seq模型图解如下:
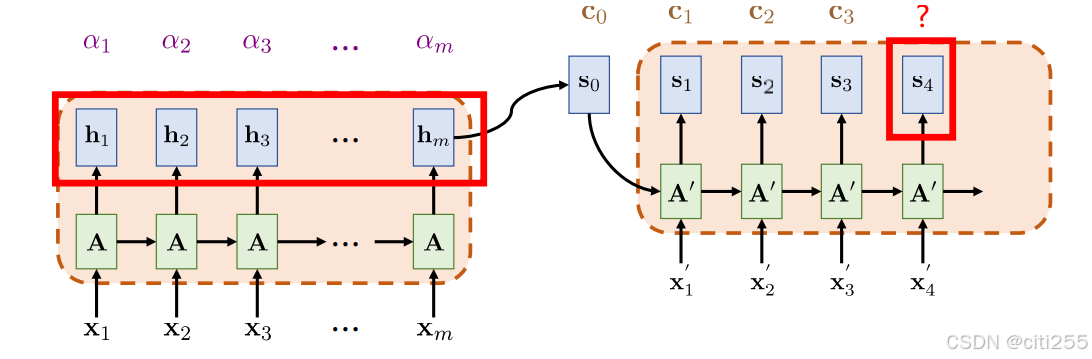
其中, c 1 , c 2 , . . . c n c_1,c_2,...c_n c1,c2,...cn 中包括了上下文信息。
-
gru
解决情况:早期观测值对预测所有未来观测值具有非常重要的意义;一些词元没有相关的观测值,需要跳过;序列的各个部分之间存在逻辑中断。
gru是lstm的简化版本,包括一个重置门和一个更新门。其中,重置门允许我们控制“可能还想记住”的过去状态的数量; 更新门将允许我们控制新状态中有多少个是旧状态的副本。重置门有助于捕获序列中的短期依赖关系;更新门有助于捕获序列中的长期依赖关系。
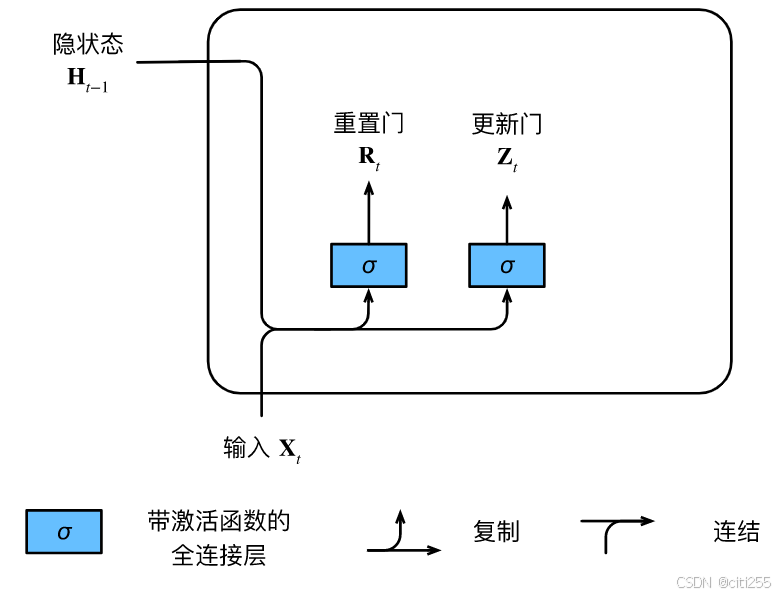
具体计算流程如下:
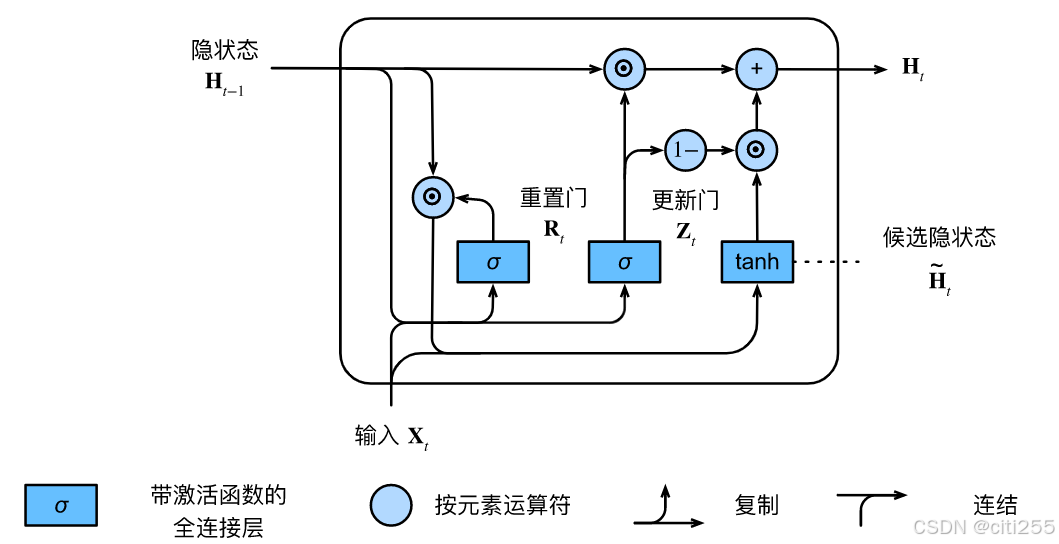
基于gru带注意力机制的seq2seq模型与rnn带注意力机制的非常相似,只是对rnn输入和隐藏状态的处理更简单。
-
lstm(长短期记忆网络)
包括长期记忆(细胞记忆)和短期记忆(隐藏状态)。长期记忆没有经过权重或偏差的直接修改,因此在流动中不会出现梯度爆炸或消失。 短期记忆则直接受权重影响。
-
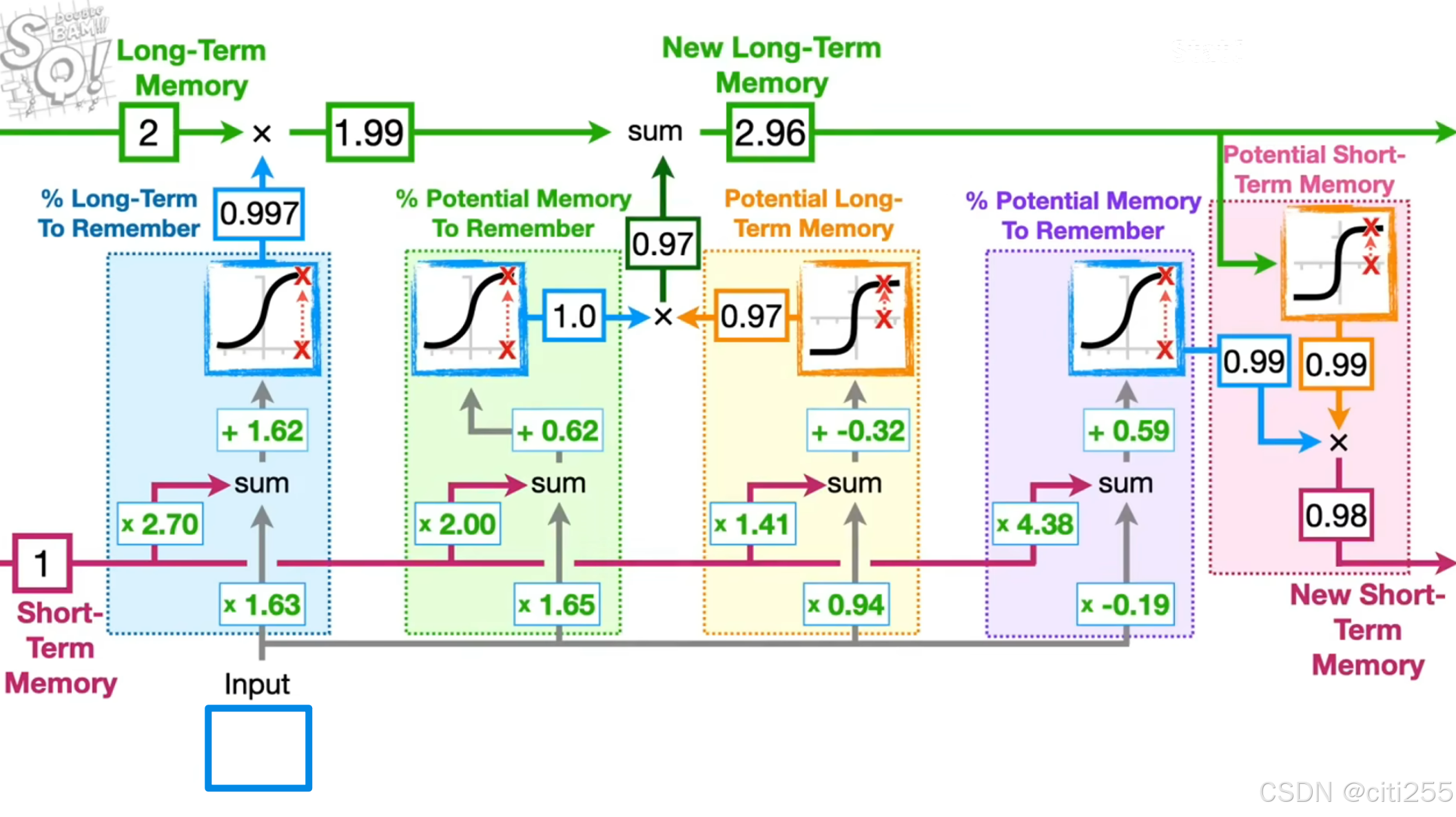
长短期记忆网络中的遗忘门确定了记住长期记忆的百分比;输入门确定我们应该如何更新长期记忆;输出门更新短期记忆。
-
transformer
将在后续的task03中进行学习。
翻译质量评价
使用bleu。
baseline解读
数据预处理
- 读取数据
- 预处理(分词、小写转换、忽略空数据)
- 构建词汇表(包括’', ‘’, ‘’, ''等必要的标记),填充数据并分批次构建张量
- 定义数据集并提供相应方法
- 辅助函数
# 定义tokenizer
en_tokenizer = get_tokenizer('spacy', language='en_core_web_trf')
zh_tokenizer = lambda x: list(jieba.cut(x)) # 使用jieba分词
# 读取数据函数
def read_data(file_path: str) -> list[str]:
with open(file_path, 'r', encoding='utf-8') as f:
return [line.strip() for line in f]
# 数据预处理函数
def preprocess_data(en_data: list[str], zh_data: list[str]) -> list[tuple[list[str], list[str]]]:
processed_data = []
for en, zh in zip(en_data, zh_data):
en_tokens = en_tokenizer(en.lower())[:max_length]
zh_tokens = zh_tokenizer(zh)[:max_length]
if en_tokens and zh_tokens: # 确保两个序列都不为空
processed_data.append((en_tokens, zh_tokens))
return processed_data
# 构建词汇表
def build_vocab(data: list[tuple[list[str], list[str]]]):
en_vocab = build_vocab_from_iterator(
(en for en, _ in data),
specials=['<unk>', '<pad>', '<bos>', '<eos>']
)
zh_vocab = build_vocab_from_iterator(
(zh for _, zh in data),
specials=['<unk>', '<pad>', '<bos>', '<eos>']
)
en_vocab.set_default_index(en_vocab['<unk>'])
zh_vocab.set_default_index(zh_vocab['<unk>'])
return en_vocab, zh_vocab
# 定义数据集
class translationdataset(dataset):
def __init__(self, data: list[tuple[list[str], list[str]]], en_vocab, zh_vocab):
self.data = data
self.en_vocab = en_vocab
self.zh_vocab = zh_vocab
def __len__(self):
return len(self.data)
def __getitem__(self, idx): # 根据索引获取数据项,加上'<bos>''<eos>'标记并返回数据项的索引序列
en, zh = self.data[idx]
en_indices = [self.en_vocab['<bos>']] + [self.en_vocab[token] for token in en] + [self.en_vocab['<eos>']]
zh_indices = [self.zh_vocab['<bos>']] + [self.zh_vocab[token] for token in zh] + [self.zh_vocab['<eos>']]
return en_indices, zh_indices
# 辅助函数,用于将一个批次的数据分割成中文和英文批次张量
def collate_fn(batch):
en_batch, zh_batch = [], []
for en_item, zh_item in batch:
if en_item and zh_item: # 确保两个序列都不为空
en_batch.append(torch.tensor(en_item))
zh_batch.append(torch.tensor(zh_item))
if not en_batch or not zh_batch: # 如果整个批次为空,返回空张量
return torch.tensor([]), torch.tensor([])
en_batch = nn.utils.rnn.pad_sequence(en_batch, batch_first=true, padding_value=en_vocab['<pad>'])
zh_batch = nn.utils.rnn.pad_sequence(zh_batch, batch_first=true, padding_value=zh_vocab['<pad>'])
return en_batch, zh_batch
模型构建
这段代码也就是机器翻译核心部分。
baseline采用基于注意力机制的seq2seq模型,包括encoder、decoder两部分。
- encoder类具有前向传播方法,输入索引序列
src被嵌入,并经过gru网络,更新隐藏状态hidden,得到输出outputs。
class encoder(nn.module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.embedding(input_dim, emb_dim)
self.gru = nn.gru(emb_dim, hid_dim, n_layers, dropout=dropout, batch_first=true)
# 多个gru层有助于学习更复杂更抽象的序列特征
self.dropout = nn.dropout(dropout) #随机地将一部分输入单元置为0,防止过拟合
def forward(self, src):
# src = [batch size, src len]
# 将输入词索引转换为词向量,并应用 dropout
embedded = self.dropout(self.embedding(src))
# embedded = [batch size, src len, emb dim]
#通过gru网络
outputs, hidden = self.gru(embedded)
# outputs = [batch size, src len, hid dim * n directions]
# hidden = [n layers * n directions, batch size, hid dim]
# 对于单向 gru,n directions 为 1
return outputs, hidden
- 在decoder类的前向传播方法中,encoder的输出
encoder_outputs、前一时间步的隐藏状态hidden和当前时间步的输入input经过注意力机制处理,输入gru网络,最后通过全连接层得到prediction。
class decoder(nn.module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout, attention):
super().__init__()
self.output_dim = output_dim
self.hid_dim = hid_dim
self.n_layers = n_layers
self.attention = attention
self.embedding = nn.embedding(output_dim, emb_dim)
self.gru = nn.gru(hid_dim + emb_dim, hid_dim, n_layers, dropout=dropout, batch_first=true)
self.fc_out = nn.linear(hid_dim * 2 + emb_dim, output_dim) # 全连接层
self.dropout = nn.dropout(dropout)
def forward(self, input, hidden, encoder_outputs):
# input = [batch size, 1]
# hidden = [n layers, batch size, hid dim]
# encoder_outputs = [batch size, src len, hid dim]
input = input.unsqueeze(1)
embedded = self.dropout(self.embedding(input))
# embedded = [batch size, 1, emb dim]
a = self.attention(hidden[-1:], encoder_outputs)
# a = [batch size, src len]
# a 为当前时间步对 encoder_outputs 每个时间步输出的注意力权重分布
a = a.unsqueeze(1)
# a = [batch size, 1, src len]
# bmm 进行矩阵乘法,得到 weighted(注意力加权后的 encoder_outputs)
weighted = torch.bmm(a, encoder_outputs)
# weighted = [batch size, 1, hid dim]
# 连接嵌入的词向量 embedded 和加权的编码器输出 weighted ,输入 gru 网络
# 得到输出 output 和新的隐藏状态 hidden
rnn_input = torch.cat((embedded, weighted), dim=2)
# rnn_input = [batch size, 1, emb dim + hid dim]
output, hidden = self.gru(rnn_input, hidden)
# output = [batch size, 1, hid dim]
# hidden = [n layers, batch size, hid dim]
embedded = embedded.squeeze(1)
output = output.squeeze(1)
weighted = weighted.squeeze(1)
# 将 gru 输出、加权的编码器输出和嵌入的词向量拼接起来,经过全连接层生成最终的预测
prediction = self.fc_out(torch.cat((output, weighted, embedded), dim=1))
# prediction = [batch size, output dim]
return prediction, hidden
- 整个seq2seq模型为:
class seq2seq(nn.module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device # 设备信息(如 cuda 或 cpu),用于将张量移动到指定设备
def forward(self, src, trg, teacher_forcing_ratio=0.5):
# src = [batch size, src len]
# trg = [batch size, trg len]
batch_size = src.shape[0]
trg_len = trg.shape[1]
trg_vocab_size = self.decoder.output_dim
outputs = torch.zeros(batch_size, trg_len, trg_vocab_size).to(self.device)
encoder_outputs, hidden = self.encoder(src)
input = trg[:, 0] # 将解码器的初始输入设置为`<bos>`
# 逐时间步解码
for t in range(1, trg_len):
output, hidden = self.decoder(input, hidden, encoder_outputs)
outputs[:, t] = output
teacher_force = random.random() < teacher_forcing_ratio
# teacher_force:在训练模式中,随机决定是否采用教师强制(下一时间步输入是否使用真实序列)
top1 = output.argmax(1) # 在当前时间步的输出中选择概率最高的词
input = trg[:, t] if teacher_force else top1
return outputs
- 其中注意力机制的实现函数如下,它根据 hidden 和 encoder_outputs,获取在 encoder_outputs 上的注意力权重分布:
class attention(nn.module):
def __init__(self, hid_dim):
super().__init__()
self.attn = nn.linear(hid_dim * 2, hid_dim)
self.v = nn.linear(hid_dim, 1, bias=false)
def forward(self, hidden, encoder_outputs):
# hidden = [1, batch size, hid dim]
# encoder_outputs = [batch size, src len, hid dim]
batch_size = encoder_outputs.shape[0]
src_len = encoder_outputs.shape[1]
hidden = hidden.repeat(src_len, 1, 1).transpose(0, 1)
# hidden = [batch size, src len, hid dim]
# 将隐藏状态复制 batch 份以匹配每一批 encoder_outputs
energy = torch.tanh(self.attn(torch.cat((hidden, encoder_outputs ), dim=2)))
# energy = [batch size, src len, hid dim]
attention = self.v(energy).squeeze(2)
# attention = [batch size, src len]
return f.softmax(attention, dim=1) # 归一化后返回
训练函数使用seq2seq模型在数据上进行n_epochs轮训练,使用optimizer作为优化器。
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
#print(f"training batch {i}")
src, trg = batch
#print(f"source shape before: {src.shape}, target shape before: {trg.shape}")
if src.numel() == 0 or trg.numel() == 0:
#print("empty batch detected, skipping...")
continue # 跳过空的批次
src, trg = src.to(device), trg.to(device)
optimizer.zero_grad()
output = model(src, trg)
output_dim = output.shape[-1]
output = output[:, 1:].contiguous().view(-1, output_dim)
trg = trg[:, 1:].contiguous().view(-1)
loss = criterion(output, trg)
loss.backward()
clip_grad_norm_(model.parameters(), clip) # 梯度裁剪,防止梯度爆炸
optimizer.step()
epoch_loss += loss.item()
print(f"average loss for this epoch: {epoch_loss / len(iterator)}")
return epoch_loss / len(iterator)
- 为整个模型提供初始化函数:
# 初始化模型
def initialize_model(input_dim, output_dim, emb_dim, hid_dim, n_layers, dropout, device):
attn = attention(hid_dim)
enc = encoder(input_dim, emb_dim, hid_dim, n_layers, dropout)
dec = decoder(output_dim, emb_dim, hid_dim, n_layers, dropout, attn)
model = seq2seq(enc, dec, device).to(device)
return model
训练
-
定义优化器
-
定义辅助函数用于计算每轮训练的运行时间
# 定义优化器
def initialize_optimizer(model, learning_rate=0.001):
return optim.adam(model.parameters(), lr=learning_rate)
# 运行时间
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
- 训练函数
def train(model, iterator, optimizer, criterion, clip):
model.train() # 设置模型为训练模式,这会启用 dropout 和 batch normalization
epoch_loss = 0 # 计算每轮训练损失
# 遍历数据集中的每个批次
for i, batch in enumerate(iterator):
# 提取源序列 src 和目标序列 trg
#print(f"training batch {i}")
src, trg = batch
#print(f"source shape before: {src.shape}, target shape before: {trg.shape}")
if src.numel() == 0 or trg.numel() == 0: # 跳过空的批次
#print("empty batch detected, skipping...")
continue
# 将数据移动到指定的设备(如 cuda 或 gpu)
src, trg = src.to(device), trg.to(device)
optimizer.zero_grad() # pytorch 默认会累积梯度,因此需要清除之前批次的梯度
output = model(src, trg) # 前向传播
# 比较trg和output,计算损失
output_dim = output.shape[-1]
output = output[:, 1:].contiguous().view(-1, output_dim)
trg = trg[:, 1:].contiguous().view(-1)
loss = criterion(output, trg)
loss.backward() # 反向传播
clip_grad_norm_(model.parameters(), clip) # 梯度裁剪
optimizer.step()
epoch_loss += loss.item()
print(f"average loss for this epoch: {epoch_loss / len(iterator)}")
return epoch_loss / len(iterator)
- 在验证或测试集上评估训练结果
def evaluate(model, iterator, criterion):
model.eval() # 将模型设置为评估模式
epoch_loss = 0
with torch.no_grad():
for i, batch in enumerate(iterator):
#print(f"evaluating batch {i}")
src, trg = batch
if src.numel() == 0 or trg.numel() == 0:
continue # 跳过空批次
src, trg = src.to(device), trg.to(device)
output = model(src, trg, 0) # 关闭 teacher forcing
output_dim = output.shape[-1]
output = output[:, 1:].contiguous().view(-1, output_dim)
trg = trg[:, 1:].contiguous().view(-1)
loss = criterion(output, trg)
epoch_loss += loss.item()
return epoch_loss / len(iterator)
- 主训练循环,默认训练轮数为10
def train_model(model, train_iterator, valid_iterator, optimizer, criterion, n_epochs=10, clip=1):
best_valid_loss = float('inf')
for epoch in range(n_epochs):
start_time = time.time()
print(f"starting epoch {epoch + 1}")
train_loss = train(model, train_iterator, optimizer, criterion, clip)
valid_loss = evaluate(model, valid_iterator, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), '../model/best-model_test.pt')
print(f'epoch: {epoch+1:02} | time: {epoch_mins}m {epoch_secs}s')
print(f'\ttrain loss: {train_loss:.3f} | train ppl: {math.exp(train_loss):7.3f}')
print(f'\t val. loss: {valid_loss:.3f} | val. ppl: {math.exp(valid_loss):7.3f}')
- 定义常量
# 定义常量
max_length = 1000 # 最大句子长度
batch_size = 32
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
n = 100 # 采样训练集的数量
train_path = '../dataset/train.txt'
dev_en_path = '../dataset/dev_en.txt'
dev_zh_path = '../dataset/dev_zh.txt'
test_en_path = '../dataset/test_en.txt'
train_loader, dev_loader, test_loader, en_vocab, zh_vocab = load_data(
train_path, dev_en_path, dev_zh_path, test_en_path
)
print(f"英语词汇表大小: {len(en_vocab)}")
print(f"中文词汇表大小: {len(zh_vocab)}")
print(f"训练集大小: {len(train_loader.dataset)}")
print(f"开发集大小: {len(dev_loader.dataset)}")
print(f"测试集大小: {len(test_loader.dataset)}")
- 主函数
if __name__ == '__main__':
n_epochs = 10 #训练轮数
clip=1
# 模型参数
input_dim = len(en_vocab)
output_dim = len(zh_vocab)
emb_dim = 128
hid_dim = 256
n_layers = 1
dropout = 0.5
# 初始化模型
model = initialize_model(input_dim, output_dim, emb_dim, hid_dim, n_layers, dropout, device)
print(f'the model has {sum(p.numel() for p in model.parameters() if p.requires_grad):,} trainable parameters')
# 定义损失函数
criterion = nn.crossentropyloss(ignore_index=zh_vocab['<pad>'])
# 初始化优化器
optimizer = initialize_optimizer(model)
# 训练模型
train_model(model, train_loader, dev_loader, optimizer, criterion, n_epochs, clip)
在开发集上进行评价
- 翻译函数
def translate_sentence(sentence, src_vocab, trg_vocab, model, device, max_length=50):
model.eval()
#print(sentence) # 打印sentence的内容
if isinstance(sentence, str):
#tokens = [token.lower() for token in en_tokenizer(sentence)]
tokens = [token for token in en_tokenizer(sentence)]
else:
#tokens = [token.lower() for token in sentence]
tokens = [str(token) for token in sentence]
tokens = ['<bos>'] + tokens + ['<eos>']
src_indexes = [src_vocab[token] for token in tokens]
src_tensor = torch.longtensor(src_indexes).unsqueeze(0).to(device)
with torch.no_grad():
encoder_outputs, hidden = model.encoder(src_tensor)
trg_indexes = [trg_vocab['<bos>']]
for i in range(max_length):
trg_tensor = torch.longtensor([trg_indexes[-1]]).to(device)
with torch.no_grad():
output, hidden = model.decoder(trg_tensor, hidden, encoder_outputs)
pred_token = output.argmax(1).item()
trg_indexes.append(pred_token)
if pred_token == trg_vocab['<eos>']:
break
trg_tokens = [trg_vocab.get_itos()[i] for i in trg_indexes]
return trg_tokens[1:-1] # 移除 <bos> 和 <eos>
- 计算bleu分数的函数
def calculate_bleu(dev_loader, src_vocab, trg_vocab, model, device):
translated_sentences = []
references = []
for src, trg in dev_loader:
src = src.to(device)
translation = translate_sentence(src, src_vocab, trg_vocab, model, device)
# 将翻译结果转换为字符串
translated_sentences.append(' '.join(translation))
# 将每个参考翻译转换为字符串,并添加到references列表中
for t in trg:
ref_str = ' '.join([trg_vocab.get_itos()[idx] for idx in t.tolist() if idx not in [trg_vocab['<bos>'], trg_vocab['<eos>'], trg_vocab['<pad>']]])
references.append(ref_str)
print("translated_sentences",translated_sentences[:2])
print("references:",references[6:8])
# 使用`sacrebleu`计算bleu分数
# 注意:sacrebleu要求references是一个列表的列表,其中每个子列表包含一个或多个参考翻译
bleu = sacrebleu.corpus_bleu(translated_sentences, [references])
# 打印bleu分数
return bleu.score
- 在开发集上进行评价
# 加载最佳模型
model.load_state_dict(torch.load('../model/best-model_test.pt'))
# 计算bleu分数
bleu_score = calculate_bleu(dev_loader, en_vocab, zh_vocab, model, device)
print(f'bleu score = {bleu_score*100:.2f}')
对测试集进行翻译
# 加载最佳模型
model.load_state_dict(torch.load('../model/best-model_test.pt'))
with open('../results/submit_test.txt', 'w') as f:
translated_sentences = []
for batch in test_loader: # 遍历所有数据
src, _ = batch
src = src.to(device)
translated = translate_sentence(src[0], en_vocab, zh_vocab, model, device) #翻译结果
results = "".join(translated)
f.write(results + '\n') # 将结果写入文件
参数调整
可调整的参数有:
n:采样训练集的数量max_length:选择截取的最大句子长度batch_size:批次大小(每批次样本数)n_epochs:训练轮数
默认参数训练结果如下:
the model has 64,684,073 trainable parameters
starting epoch 1
average loss for this epoch: 11.154994328816732
epoch: 01 | time: 0m 9s
train loss: 11.155 | train ppl: 69912.122
val. loss: 10.826 | val. ppl: 50305.185
starting epoch 2
average loss for this epoch: 10.010788917541504
epoch: 02 | time: 0m 9s
train loss: 10.011 | train ppl: 22265.394
val. loss: 9.265 | val. ppl: 10566.786
starting epoch 3
average loss for this epoch: 7.507755279541016
epoch: 03 | time: 0m 9s
train loss: 7.508 | train ppl: 1822.119
val. loss: 8.154 | val. ppl: 3477.248
starting epoch 4
average loss for this epoch: 5.75741179784139
epoch: 04 | time: 0m 9s
train loss: 5.757 | train ppl: 316.528
val. loss: 8.582 | val. ppl: 5336.530
starting epoch 5
average loss for this epoch: 5.361410140991211
epoch: 05 | time: 0m 9s
train loss: 5.361 | train ppl: 213.025
val. loss: 9.144 | val. ppl: 9358.471
starting epoch 6
average loss for this epoch: 5.312565326690674
epoch: 06 | time: 0m 9s
train loss: 5.313 | train ppl: 202.870
val. loss: 9.604 | val. ppl: 14828.058
starting epoch 7
average loss for this epoch: 5.258942127227783
epoch: 07 | time: 0m 9s
train loss: 5.259 | train ppl: 192.278
val. loss: 9.948 | val. ppl: 20920.005
starting epoch 8
average loss for this epoch: 5.155441125233968
epoch: 08 | time: 0m 9s
train loss: 5.155 | train ppl: 173.372
val. loss: 10.125 | val. ppl: 24954.654
starting epoch 9
average loss for this epoch: 5.203134854634603
epoch: 09 | time: 0m 9s
train loss: 5.203 | train ppl: 181.841
val. loss: 10.220 | val. ppl: 27455.315
starting epoch 10
average loss for this epoch: 5.101626078287761
epoch: 10 | time: 0m 9s
train loss: 5.102 | train ppl: 164.289
val. loss: 10.365 | val. ppl: 31724.934
translated_sentences ['蚌类 那团 千万别 一万五千个 回声 夜线 data 三天 花粉 犯人 第二轮 银色 同名 事发 玛利亚 benjamin 还装 站岗 赝造 苦海 产下 平常 好了吧 辛 裘 丽斯 titan 独特 工程技术 环境污染 南极洲 九霄云外 戈尔 拼命 对作 木兰 国内外 心肌梗塞 十一个 思维习惯 残废 平安 shokran 他画 额眶部 目 倾覆 其极 杜莎', '蚌类 那团 千万别 一万五千个 回声 夜线 data 三天 花粉 犯人 第二轮 银色 同名 事发 玛利亚 benjamin 还装 站岗 赝造 苦海 产下 平常 好了吧 辛 裘 丽斯 titan 独特 工程技术 环境污染 南极洲 九霄云外 戈尔 拼命 对作 木兰 国内外 心肌梗塞 十一个 思维习惯 残废 平安 shokran 他画 额眶部 目 倾覆 其极 杜莎']
references: ['只是 你们 无法 见到 这位 天才 设计者', '在 印度 , 那里 有 一对 夫妻 经营 的 流动 图书馆']
bleu score = 2.40
根据训练中和在开发集上的损失,调整参数 max_length = 100 n = 10000 n_epochs = 3 ,训练结果如下:
英语词汇表大小: 44850
中文词汇表大小: 75172
训练集大小: 10000
开发集大小: 1000
测试集大小: 1000
the model has 64,469,156 trainable parameters
starting epoch 1
average loss for this epoch: 6.833627208685264
epoch: 01 | time: 3m 4s
train loss: 6.834 | train ppl: 928.553
val. loss: 6.993 | val. ppl: 1088.676
starting epoch 2
average loss for this epoch: 6.154211776378827
epoch: 02 | time: 3m 6s
train loss: 6.154 | train ppl: 470.696
val. loss: 6.970 | val. ppl: 1064.049
starting epoch 3
average loss for this epoch: 5.7989484667778015
epoch: 03 | time: 3m 6s
train loss: 5.799 | train ppl: 329.952
val. loss: 7.008 | val. ppl: 1105.416
translated_sentences ['他们 的 的 , 他们 的 他们 的 他们 的', '他们 的 的 , 他们 的 他们 的 他们 的']
references: ['只是 你们 无法 见到 这位 天才 设计者', '在 印度 , 那里 有 一对 夫妻 经营 的 流动 图书馆']
bleu score = 21.07
the model has 64,469,156 trainable parameters
starting epoch 1
average loss for this epoch: 6.833627208685264
epoch: 01 | time: 3m 4s
train loss: 6.834 | train ppl: 928.553
val. loss: 6.993 | val. ppl: 1088.676
starting epoch 2
average loss for this epoch: 6.154211776378827
epoch: 02 | time: 3m 6s
train loss: 6.154 | train ppl: 470.696
val. loss: 6.970 | val. ppl: 1064.049
starting epoch 3
average loss for this epoch: 5.7989484667778015
epoch: 03 | time: 3m 6s
train loss: 5.799 | train ppl: 329.952
val. loss: 7.008 | val. ppl: 1105.416
translated_sentences ['他们 的 的 , 他们 的 他们 的 他们 的', '他们 的 的 , 他们 的 他们 的 他们 的']
references: ['只是 你们 无法 见到 这位 天才 设计者', '在 印度 , 那里 有 一对 夫妻 经营 的 流动 图书馆']
bleu score = 21.07
虽然损失更小了,在开发集上的分数也有所提高,但翻译质量并没有改善,提交翻译结果后分数甚至更低了。



发表评论