ahu-aischool-nlp-final复习指南
by 晖汪汪 仅供参考
题型参考(猜测)
- 选择题( 12 × 2 = 24 分 12 \times 2 = 24分 12×2=24分)
- 填空( 8 × 2 = 16 分 8 \times 2 = 16分 8×2=16分)
- 解答( 3 × 10 = 30 分 3 \times 10 = 30分 3×10=30分)
- 设计( 2 × 15 = 30 分 2 \times 15 = 30分 2×15=30分)
1 transformer(分值>60分)
-
transformer的核心组件是什么?
self-attention:自注意力机制- google的研究人员在《attention is all you need》一文中首次引入了
self attention机制,并发明了transformer。 transformer后来成为gpt和bert的基石。
-
为什么transformer如此出众?
-
并行计算: 与rnn不同,transformer可以并行处理整个输入序列,从而提高计算效率。
-
自注意力机制能够捕捉全局依赖关系,适用于长序列数据,虽然lstm和gru说是有更长时的记忆能力,但是还是远远不及自注意力机制(可以说自注意力机制只受限于计算资源)。
-
位置编码: transformer引入了位置编码来保留序列信息,解决了模型本身不含位置信息的问题。
-
transformer小总结:
-
transformer 与 rnn 不同,可以比较好地并行训练;
-
transformer 本身是不能利用单词的顺序信息的,因此需要在输入中添加位置 embedding(位置编码), 否则 transformer 就是一个词袋模型;
-
transformer 的重点是
self-attention结构,其中用到的 q 、 k 、 v q、k、v q、k、v矩阵通过输入进行线性变换得到; -
transformer 中
multi-head attention中有多个self-attention,可以捕获单词之间多种维度上的相关系数attention分数。 -
其损失函数是交叉熵损失(cross-entropy loss),公式如下:
l = − 1 n ∑ i = 1 n log p ( w i ∣ w 1 , w 2 , … , w i − 1 ) \mathcal{l} = -\frac{1}{n} \sum_{i=1}^{n} \log p(w_i | w_1, w_2, \ldots, w_{i-1}) l=−n1i=1∑nlogp(wi∣w1,w2,…,wi−1)
n n n是序列的长度, w i w_i wi 是第 i i i个词, p ( w i ∣ w 1 , w 2 , … , w i − 1 ) p(w_i | w_1, w_2, \ldots, w_{i-1}) p(wi∣w1,w2,…,wi−1)是模型预测的第 i i i 个词的概率。下图是《attention is all you need》中提出的
transformer网络结构。
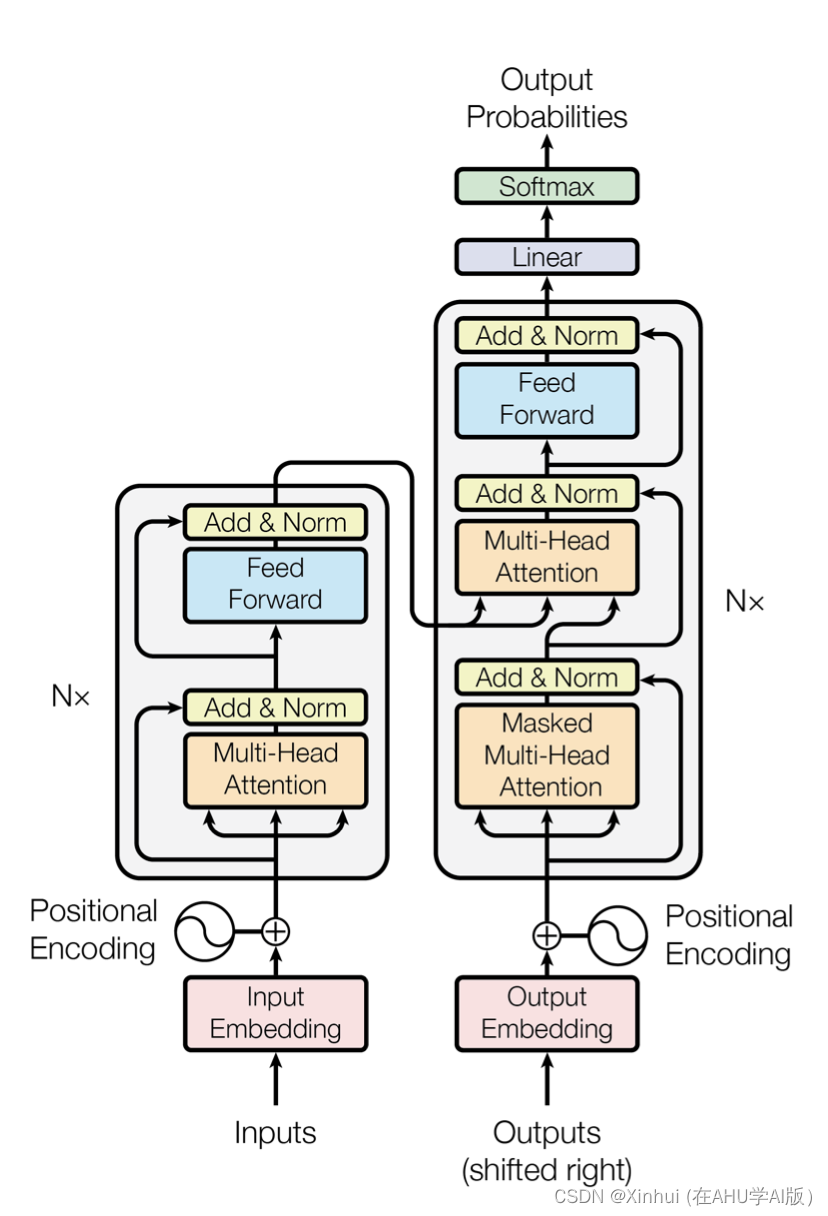 - 自注意力机制是如何演算的?(应该会考一个解答题) - 这里的注意力机制应该主要指缩放点积注意力。 - 点积操作要求查询和键*具有相同的长度
d
d
d,基于个
n
n
n个
- 自注意力机制是如何演算的?(应该会考一个解答题) - 这里的注意力机制应该主要指缩放点积注意力。 - 点积操作要求查询和键*具有相同的长度
d
d
d,基于个
n
n
n个查询和 m m m个键-值对计算注意力( n 个 q , m 个 k − v n个q,m个k-v n个q,m个k−v) 其中查询和键的长度为 d d d,值的长度为 v v v。 查询 q ∈ r n × d \mathbf{q} \in \mathbb{r}^{n \times d} q∈rn×d、 键 k ∈ r m × d \mathbf{k}\in \mathbb{r}^{m\times d} k∈rm×d和值 v ∈ r m × v \mathbf{v} \in \mathbb{r}^{m\times v} v∈rm×v的缩放点积注意力为:
attention ( q , k , v ) = s o f t m a x ( q k t d ) v ∈ r n × v \text{attention}(q, k, v) =softmax(\frac{\mathbf{q}\mathbf{k}^{t}}{\sqrt{d}})\mathbf{v} \in \mathbb{r}^{n \times v} attention(q,k,v)=softmax(dqkt)v∈rn×v
-
-
其中,
s
o
f
t
m
a
x
softmax
softmax的运算如下。假设输入向量
z
=
[
z
1
,
z
2
,
…
,
z
k
]
\mathbf{z} = [z_1, z_2, \ldots, z_k]
z=[z1,z2,…,zk](个人估计是不用算出
s
o
l
f
m
a
x
solfmax
solfmax的,因为没说让带计算器):
s
o
f
t
m
a
x
(
z
i
)
=
e
z
i
∑
j
=
1
k
e
z
j
softmax(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{k} e^{z_j}}
softmax(zi)=∑j=1kezjezi
-
transformer的残差连接是用来做什么的?
- 残差连接: 在每个子层(子网络)之间引入残差连接(residual connection),可以缓解
梯度消失问题,并且加速模型的训练。 - 同时可以应用**
relu**解决梯度爆炸问题。 - 进行残差连接后,层归一化残差连接的输出,解决梯度消失/爆炸并提升数值稳定性。
- 简而言之:残差连接、
relu、层归一化(add&norm)。
- 残差连接: 在每个子层(子网络)之间引入残差连接(residual connection),可以缓解
-
transformer的重要组件 f n n 前馈神经网络 fnn前馈神经网络 fnn前馈神经网络的作用是什么?
-
每个transformer层包括一个位置独立的前馈神经网络(fnn),用于进一步处理和转换自注意力机制输出的特征。
-
具体地说,因为
attention没有非线性的特性,**前馈神经网络(fnn)**中的激活函数可以给模型提供非线性的性质,使得模型可以拟合和学习复杂的函数关系。
-
-
输入为 n n n,那么transformer的复杂度如何计算?(可能会考一个解答题)
-
transformer的复杂度决定于:
-
自注意力机制(self-attention mechanism)
计算注意力权重和应用这些权重进行加权求和。
- 查询矩阵 q q q,键矩阵 k k k,和值矩阵 v v v的线性变换
q = x w q , k = x w k , v = x w v q = xw_q, \quad k = xw_k, \quad v = xw_v q=xwq,k=xwk,v=xwv
x x x是输入矩阵, w q , w k , w v w_q,w_k,w_v wq,wk,wv是权重矩阵。复杂度是 o ( n ⋅ d 2 ) o(n \cdot d^2) o(n⋅d2),其中 d d d是输入向量的维度。
-
计算查询矩阵 q q q和键矩阵 k k k的点积,并应用$ softmax$
attention ( q , k , v ) = softmax ( q k t d k ) v \text{attention}(q, k, v) = \text{softmax}\left(\frac{qk^t}{\sqrt{d_k}}\right) v attention(q,k,v)=softmax(dkqkt)v
复杂度是 o ( n 2 ⋅ d ) o(n^2 \cdot d) o(n2⋅d),其中 d k d_k dk是键向量的维度,通常与 d d d相同。 -
将注意力权重与值矩阵相乘
复杂度是 o ( n 2 ⋅ d ) o(n^2 \cdot d) o(n2⋅d)。
则总复杂度为 o ( n ⋅ d 2 + n 2 ⋅ d ) o(n \cdot d^2 + n^2 \cdot d) o(n⋅d2+n2⋅d)
-
前馈神经网络(fnn)
来自于两层全连接层的计算:
layer 1relu ( x w 1 + b 1 ) \text{relu}(xw_1 + b_1) relu(xw1+b1)
复杂度 o ( n ⋅ d ⋅ d f f ) o(n \cdot d \cdot d_{ff}) o(n⋅d⋅dff),其中 d f f d_{ff} dff是前馈神经网络的隐藏层维度,通常大于 d d d。
layer 2( x w 1 + b 1 ) w 2 + b 2 (xw_1 + b_1)w_2 + b_2 (xw1+b1)w2+b2
复杂度 o ( n ⋅ d ⋅ d f f ) o(n \cdot d \cdot d_{ff}) o(n⋅d⋅dff)
totalo ( n ⋅ d ⋅ d f f ) o(n \cdot d \cdot d_{ff}) o(n⋅d⋅dff)
-
transformer模型的总体复杂度
o ( n ⋅ d 2 + n 2 ⋅ d + n ⋅ d ⋅ d f f ) o(n \cdot d^2 + n^2 \cdot d + n \cdot d \cdot d_{ff}) o(n⋅d2+n2⋅d+n⋅d⋅dff)
通常, d f f d_{ff} dff比 d d d大一些,例如 d f f = 4 d d_{ff} = 4d dff=4d。因此,总复杂度可以简化为:
o ( n ⋅ d 2 + n 2 ⋅ d ) o(n \cdot d^2 + n^2 \cdot d) o(n⋅d2+n2⋅d)
对于较长的输入序列,复杂度主要由自注意力机制决定:
o ( n 2 ⋅ d ) o(n^2 \cdot d) o(n2⋅d)
-
-
看不懂上面没关系——个人猜测,考试考以下两种简单的情况:
-
假如输入 n = 1 n = 1 n=1个词到transformer中,每个词到
embedding为 d d d维,则上面的复杂度可以简化为:o ( d 2 ) + o ( d ) + o ( d × d f f ) o(d^2) + o(d) + o(d \times d_{ff}) o(d2)+o(d)+o(d×dff)
即 o ( d 2 ) o(d^2) o(d2)
-
假如输入 n n n个词到transformer中,每个词到
embedding为 d d d维,则上面的复杂度可以简化为:o ( n ⋅ d 2 + n 2 ⋅ d + n ⋅ d ⋅ d f f ) o(n \cdot d^2 + n^2 \cdot d + n \cdot d \cdot d_{ff}) o(n⋅d2+n2⋅d+n⋅d⋅dff)
即 o ( n ⋅ d 2 + n 2 ⋅ d ) o(n \cdot d^2 + n^2 \cdot d) o(n⋅d2+n2⋅d)
-
-
-
transformer中什么机制让解码器关注到编码器?**
- 在**
encoder- decoder attention layers**层中使用编码器传过来的 k 和 v k和v k和v,这有助于解码器将注意力集中在输入序列中的适当位置。 - 即交叉注意力(
cross-attention),也可以叫编解机制: 解码器在计算注意力时,不仅关注解码器自身的输入,还会结合编码器的输出。
- 在**
2 自注意力机制
-
多重注意力机制是用来做什么的?
- 多头注意力(multi-head attention)将注意力机制拆分为多个头(heads),每个头独立计算注意力,然后将结果拼接起来。这样可以捕捉不同的特征和关系,提高模型的表达能力。
- 即捕获不同子空间内的表征。
-
mask - attention是用来做什么的?
- **掩码注意力(mask-attention)**在解码器中使用,以确保模型只关注到当前时间步之前的信息,防止未来信息泄露,屏蔽来自未来的信息的影响
- 传统的传统encoder-decoder流程训练阶段与测试阶段的decoder输入形式不一致,训练阶段使用了上下文的信息 ,而测试阶段只使用了上文信息。掩码注意力(mask-attention)训练时模拟测试阶段 ,只使用上文信息预测某个单词时 ,将其下文遮住(mask)。
3 bert和gpt
-
bert和gpt有什么相同点和不同点?-
相同点:-
transformer架构:
bert和gpt都基于transformer架构,具体来说:bert使用的是transformer的**编码器(encoder)**部分;gpt使用的是transformer的**解码器(decoder)**部分。
-
预训练和微调:两者都采用了预训练和微调的策略。模型首先在大量无标注的文本数据上进行预训练,然后在特定任务上进行微调。
-
自注意力机制:两者都使用了自注意力机制(self-attention),这使得它们能够捕捉句子中不同词之间的关系。
-
输入形式:
- 都使用**词嵌入(word embeddings)**将输入的词表示为向量;
- 都使用**位置编码(position embeddings)**来表示输入词在序列中的位置;
- 都使用子词(subword)级别的表示,例如
bert使用wordpiece,gpt使用byte pair encoding(bpe)。这种方法有助于处理**未登录词(oov)**和稀有词。
-
-
不同点(更重要):-
架构有差异:
bert:使用的是transformer的编码器部分,侧重于理解句子上下文。bert是双向的**(bidirectional)**,它在预训练时同时考虑了词汇的左侧和右侧上下文。gpt:使用的是transformer的解码器部分,主要用于生成任务。gpt是单向的**(unidirectional)**,即在预训练时只考虑了词汇的左侧上下文。
-
预训练目标不同(训练方式):
bert:采用了**掩蔽语言模型(masked language model, mlm)和下一句预测(next sentence prediction, nsp)**作为预训练目标。mlm通过随机掩蔽句子中的一些词汇并要求模型预测这些词汇来进行训练,nsp通过让模型判断两个句子是否是连续的来进行训练。gpt:采用了自回归语言模型(auto-regressive language model),通过预测当前词汇的下一个词来进行训练。
-
输入形式:
-
特殊标识符:
**
bert**使用特殊的cls( [ c l s ] ) ([cls]) ([cls])标识符作为句子开始的标识,用于分类任务的输出。使用sep( [ s e p ] ) ([sep]) ([sep])标识符分隔不同的句子。**
gpt**使用一个特殊的起始标识符(如 < ∣ e n d o f t e x t ∣ > <|endoftext|> <∣endoftext∣>)来标记文本的开始或结束,但在一般的句子生成中,标记符的使用较少。 -
输入格式:
bert:输入通常包括一个句子或两个句子(如句子对分类任务)。对于单句输入,格式为: [ c l s ] s e n t e n c e [ s e p ] [cls] sentence [sep] [cls]sentence[sep]。对于句子对输入,格式为: [ c l s ] s e n t e n c e a [ s e p ] s e n t e n c e b [ s e p ] [cls] sentence a [sep] sentence b [sep] [cls]sentencea[sep]sentenceb[sep]。gpt:输入通常是一个连续的文本序列,没有明确的句子分隔符。生成任务中的输入格式为:
prompt(提示词)加上模型生成的文本。 -
预处理方式
bert需要将输入文本分成固定长度的片段(chunks),并在预训练和微调阶段进行掩蔽处理(masked token)。gpt输入文本可以是任意长度的序列,不需要固定长度的分段。在预训练阶段,它通过自回归模型预测下一个词,不进行掩蔽处理。
-
-
应用场景不同:
-
bert:更适合于理解任务,如文本分类、问答系统、命名实体识别等,因为其双向编码器能够更好地理解句子整体结构。
gpt:更适合于生成任务,如文本生成、对话生成等,因为其自回归解码器能够连续生成文本。
-
-
-
-
bert和 gpt分别是如何搭建的?
-
bert(bidirectional encoder representations from transformers)主要由transformer的编码器部分构成。
-
输入表示:
-
token embeddings:将输入的词转换为词嵌入向量。
-
segment embeddings:如果输入包含两个句子,则添加段嵌入来区分不同的句子。segment a和segment b的嵌入向量不同。
-
position embeddings:添加位置嵌入来表示输入词在序列中的位置。也就是位置编码。
t o t a l _ e m b e d d i n g = t o k e n _ e m b e d d i n g + s e g m e n t _ e m b e d d i n g + p o s i t i o n _ e m b e d d i n g total\_embedding =token\_embedding + segment\_embedding + position\_embedding total_embedding=token_embedding+segment_embedding+position_embedding
-
-
编码器堆栈:
- 多层堆叠的transformer编码器:bert使用多层堆叠的transformer编码器,每一层都包含多头自注意力机制和前馈神经网络。
- 多头自注意力机制:通过多个注意力头来捕捉输入序列中不同位置之间的依赖关系。
- 前馈神经网络:每个注意力头之后跟随一个前馈神经网络,以进一步处理和转换信息。
-
预训练任务:
- 掩蔽语言模型(masked language model, mlm):在预训练过程中,随机掩蔽输入序列中的一些词,模型需要预测这些被掩蔽的词。
- 下一句预测(next sentence prediction, nsp):模型输入两个句子,需要预测第二个句子是否是第一个句子的后续句。
-
-
gpt(generative pre-trained transformer)主要由transformer的解码器部分构成。其搭建方式如下
-
输入表示:
-
token embeddings:将输入的词转换为词嵌入向量。
-
position embeddings:添加位置嵌入来表示输入词在序列中的位置。
t o t a l _ e m b e d d i n g s = t o k e n _ e m b e d d i n g s + p o s i t i o n _ e m b e d d i n g s total\_embeddings =token\_embeddings + position\_embeddings total_embeddings=token_embeddings+position_embeddings
-
-
解码器堆栈:
- 多层堆叠的transformer解码器:gpt使用多层堆叠的transformer解码器,每一层都包含多头自注意力机制、前馈神经网络和掩蔽(masked)机制。
- 多头自注意力机制:通过多个注意力头来捕捉输入序列中不同位置之间的依赖关系。与bert不同的是,gpt的自注意力机制是掩蔽的,即当前词只能看到它之前的词,不能看到它之后的词。
- 前馈神经网络:每个注意力头之后跟随一个前馈神经网络,以进一步处理和转换信息。
-
预训练任务:
- 自回归语言模型(auto-regressive language model):模型通过预测当前词的下一个词来进行预训练。输入序列中的每个词都只能依赖于它之前的词。
-
-
-
位置编码(position encoding)是用来做什么的?
- 将位置编码添加到embbeding中,有助于模型确定每 个单词的位置或不同单词之间的距离。
- 投射到 q 、 k 、 v q、k、v q、k、v中,在计 算点积注意力时提供有意义的距离信息(表征相对位置)。
4 模型设计(设计题)
-
如何设计一个文本分类系统?(如姓氏分类)
1.数据收集与准备
①训练语料的选择:收集包含国籍姓氏的文本数据,训练数据应该以表格形式组织,每行代表一个数据(即姓氏),至少两列,一列是姓氏本身,另一列对应国籍标签。
surname nationality 1 guo chinese 2 kore english ②预处理文本数据:例如去除特殊字符、处理缺失值等
2.特征提取
向量化:将姓氏转化为数值向量,通常包括:
①one-hot embedding
②word embedding:使用预训练的词嵌入模型(如
word2vec)来获取姓氏的向量表示3.模型选择
选择前馈神经网络:mlp或cnn模型。
3.模型训练
训练/验证/测试拆分:将数据集分为训练集、验证集和测试集,常见的比例是70%训练,15%验证,15%测试
模型输入:姓氏文本的嵌入表示以及对应的国籍标签 。
模型输出:损失值及梯度信息。
训练目标:通过最小化
交叉熵损失函数来训练模型。优化算法:采用
adam、sgd等优化算法进行梯度下降,更新模型参数。正则化:应用
dropout、权重衰减等技术防止过拟合4.模型预测
给定一个姓氏,预测出概率最高的一个国籍或最高的几个国籍。
4.模型评估与优化
评估指标:使用
准确率、精确率、召回率和 f 1 − s c o r e f_1-score f1−score等指标来评估模型性能超参数调整:学习率、批次大小、迭代次数等超参数的调优
-
如何设计一个机器翻译系统(如从英文到中文)?
1.数据收集与准备
①训练语料的选择:收集大规模中英文平行语料,语料的格式例如:
中文句子
1
e
n
g
l
i
s
h
_
s
e
n
t
e
n
c
e
_
1
中文句子
2
e
n
g
l
i
s
h
_
s
e
n
t
e
n
c
e
_
2
中文句子1 \quad english\_sentence\_1 \\ 中文句子2 \quad english\_sentence\_2
中文句子1english_sentence_1中文句子2english_sentence_2
②预处理文本数据:对中英文文本进行预处理,包括分词、去除停用词、标点符号等,将文本转化为词语的列表
③为中文和英文分别建立词汇表,将单词映射为唯一的索引,以便后续转换为数值表示,可以进行词嵌入。
2.模型选择
选择神经网络模型、采用seq2seq模型,可以选择带有注意力机制的transformer模型。
3.模型训练
模型输入:位置编码与中文句子的嵌入向量相加,形成最终的输入序列
模型输出:英文句子的嵌入表示
训练目标:通过最小化翻译偏差(如bleu)或交叉熵损失函数来训练模型
优化算法:采用adam、sgd等优化算法进行梯度下降,更新模型参数
正则化:应用dropout、权重衰减等技术防止过拟合
4.模型评估与优化
评估指标:使用bleu分数(bilingual evaluastion understudy)来衡量翻译结果的质量和准确性
超参数调整:学习率、批量大小、层数、注意力头数等超参数的调优
5.模型推理
输入中文句子,模型返回英文翻译结果
6.存储推理模型



发表评论