ASR-LLM-TTS 大模型对话实现案例;语音识别、大模型对话、声音生成
参考:https://blog.csdn.net/weixin_42357472/article/details/136305123(llm+tts)这里LLM用的是chatglm。
参考:https://blog.csdn.net/weixin_42357472/article/details/136305123(llm+tts)
https://blog.csdn.net/weixin_42357472/article/details/136411769 (asr+vad)
1、实时语音识别版本
代码:
##运行
python main.py
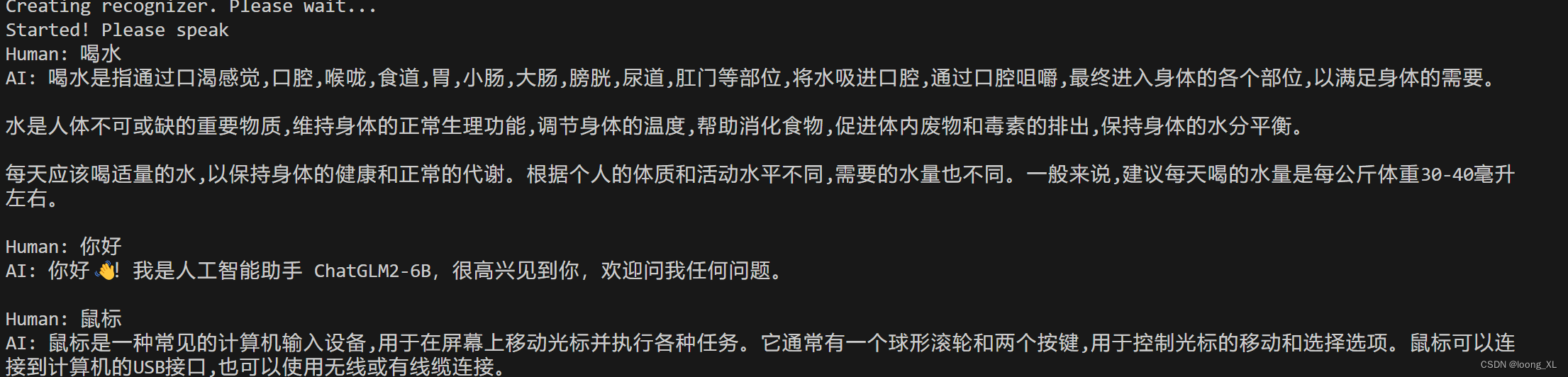
main.py
from multiprocessing import process, pipe
import requests
import json
from playsound import playsound
相关文章:
-
-
Unity热更,HybirdCLR热更,YooAsset热更,保姆级教程,从零开始…
-
-
-
关于VR Interaction Framework手势很简单,虽然官方提供了很多手势,但如果我们有新的手势,需要自己创建。好记性不如烂笔头!…
-
去年,Meta 推出了 AI 功能,允许广告主创建动态背景、增强图像并生成源自其原始内容的各种广告文本版本。这主要是侧重于通过测试图片和文本等创意元素来优化广告效果。在最新的更新中…
版权声明:本文内容由互联网用户贡献,该文观点仅代表作者本人。本站仅提供信息存储服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 2386932994@qq.com 举报,一经查实将立刻删除。


发表评论