在“downloads”文件夹中空白处右键,选择“在终端打开”,输入命令,解压eclipse到/opt目录下:
sudo tar -zxvf eclipse-committers-2023-12-r-linux-gtk-x86_64.tar.gz -c /opt
在linux系统中设置eclipse快捷方式
sudo vim /usr/share/applications/eclipse.desktop
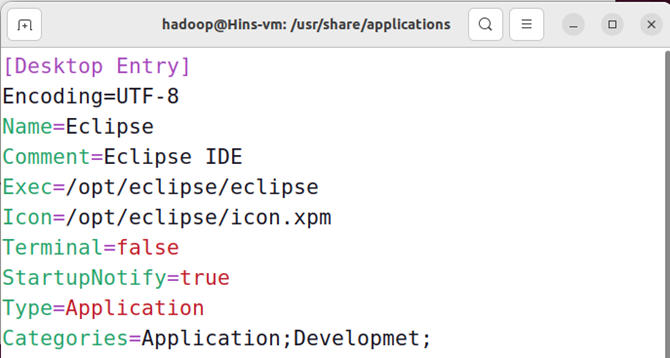
向eclipse.desktop中添加以下内容:
[desktop entry]
encoding=utf-8
name=eclipse
comment=eclipse ide
exec=/opt/eclipse/eclipse
icon=/opt/eclipse/icon.xpm
terminal=false
startupnotify=true
type=application
categories=application;developmet;
给eclipse.desktop赋权
cd /usr/share/applications
sudo chmod u+x eclipse.desktop
找到/usr/share/applications/eclipse.desktop,鼠标右键选择复制,到桌面粘贴即可。
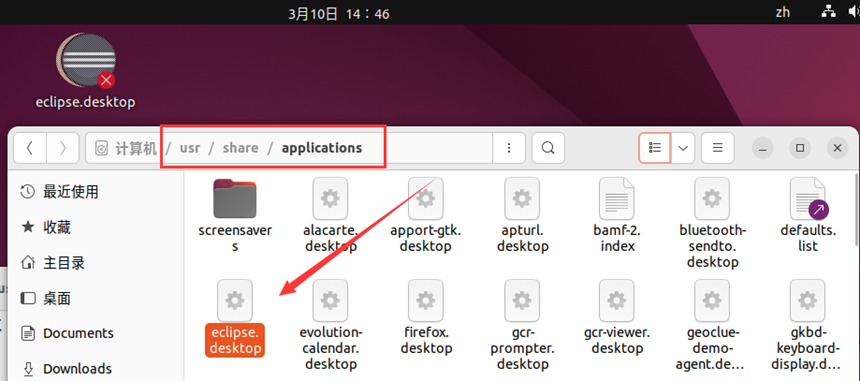
注:高版本ubuntu会有权限检查,如报错需要右键图标,选择“允许运行”
之后双击快捷方式打开即可。
🕘 4.2 在eclipse中创建项目
启动eclipse。当eclipse启动以后,会弹出如下图所示界面,提示设置工作空间(workspace)。
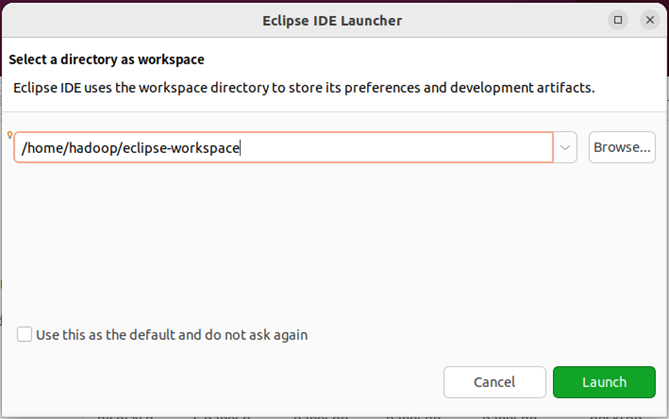
可以直接采用默认的设置“/home/hadoop/workspace”,点击“ok”按钮。可以看出,由于当前是采用hadoop用户登录了linux系统,因此,默认的工作空间目录位于hadoop用户目录“/home/hadoop”下。
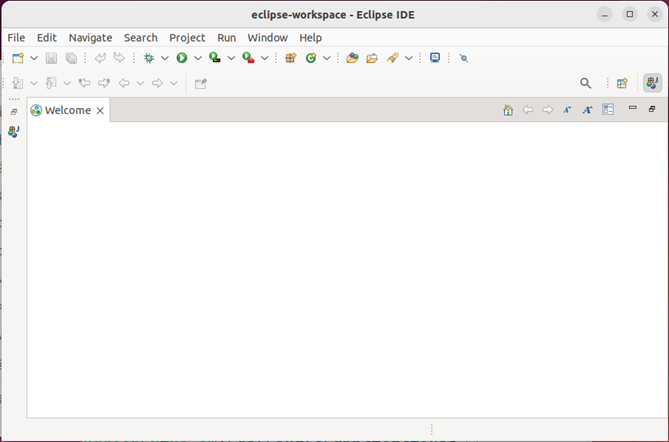
eclipse启动以后,会呈现如下图所示的界面。
关闭welcome界面后,选择“file–>new–>java project”菜单,开始创建一个java工程,会弹出如下图所示界面。
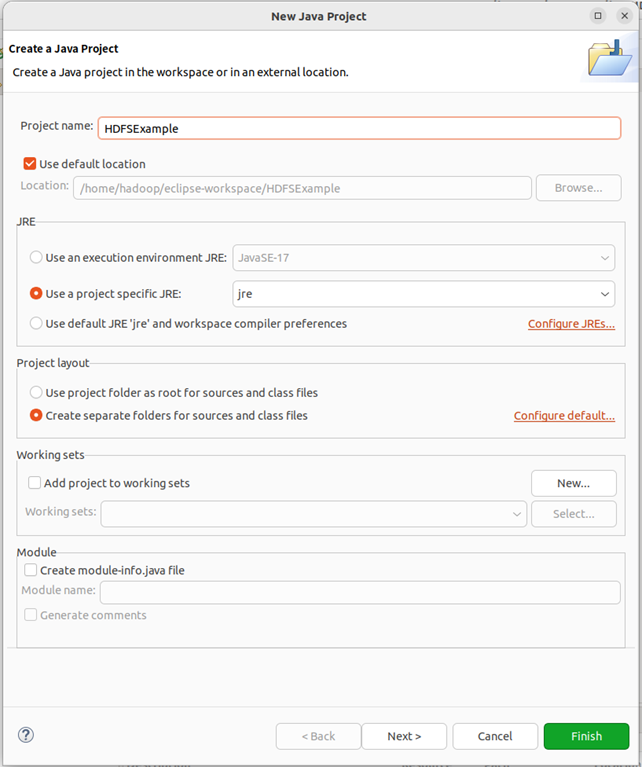
在“project name”后面输入工程名称“hdfsexample”,选中“use default location”,让这个java工程的所有文件都保存到“/home/hadoop/workspace/hdfsexample”目录下。在“jre”这个选项卡中,可以选择当前的linux系统中已经安装好的jdk,比如jdk1.8.0_371。然后,点击界面底部的“next>”按钮,进入下一步的设置。
🕘 4.3 为项目添加需要用到的jar包
进入下一步的设置以后,会弹出如下图所示界面。
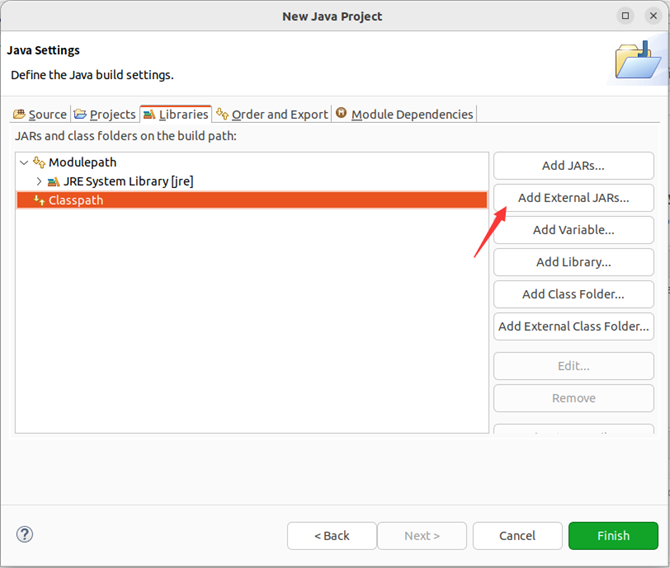
需要在这个界面中加载该java工程所需要用到的jar包,这些jar包中包含了可以访问hdfs的java api。这些jar包都位于linux系统的hadoop安装目录下,对于本文而言,就是在“/usr/local/hadoop/share/hadoop”目录下。点击界面中的“libraries”选项卡,然后,点击界面右侧的“add external jars…”按钮,会弹出如下图所示界面。
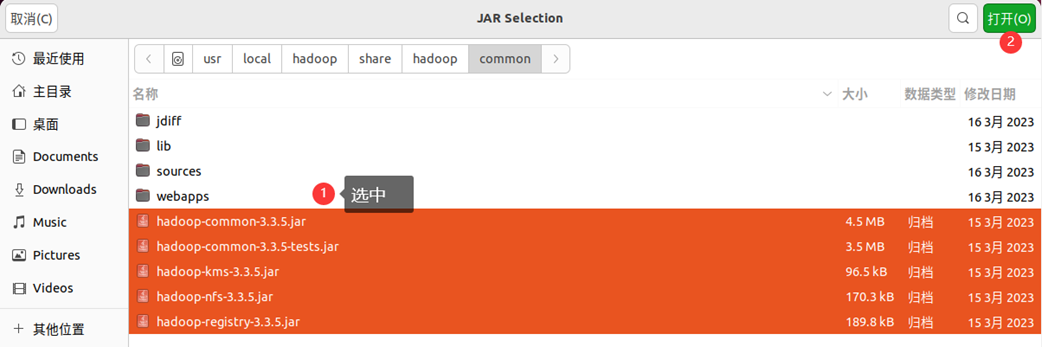
为了编写一个能够与hdfs交互的java应用程序,一般需要向java工程中添加以下jar包:
(1)“/usr/local/hadoop/share/hadoop/common”目录下的所有jar包,包括hadoop-common-3.3.5.jar、hadoop-common-3.3.5-tests.jar、haoop-nfs-3.3.5.jar、haoop-kms-3.3.5.jar和hadoop-registry-3.3.5.jar,注意,不包括目录jdiff、lib、sources和webapps;
(2)“/usr/local/hadoop/share/hadoop/common/lib”目录下的所有jar包;
(3)“/usr/local/hadoop/share/hadoop/hdfs”目录下的所有jar包,注意,不包括目录jdiff、lib、sources和webapps;
(4)“/usr/local/hadoop/share/hadoop/hdfs/lib”目录下的所有jar包。
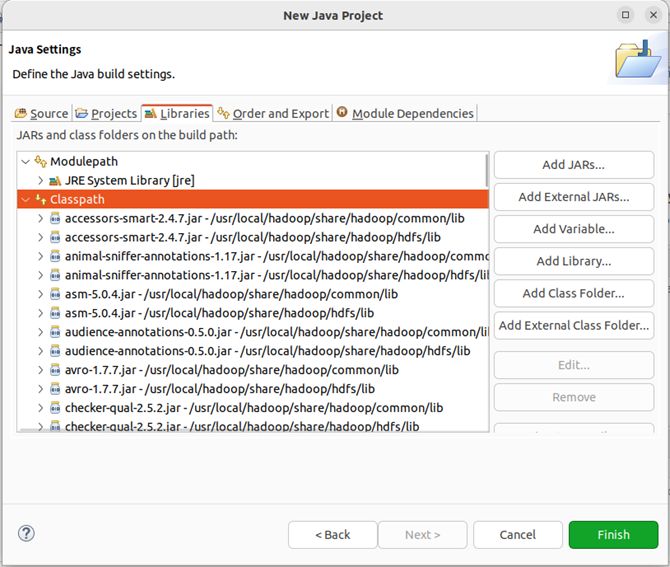
全部添加完毕以后,就可以点击界面右下角的“finish”按钮,完成java工程hdfsexample的创建。
🕘 4.4 编写java应用程序
下面编写一个java应用程序。
请在eclipse工作界面左侧的“package explorer”面板中(如下图所示),找到刚才创建好的工程名称“hdfsexample”,然后在该工程名称上点击鼠标右键,在弹出的菜单中选择“new–>class”菜单。
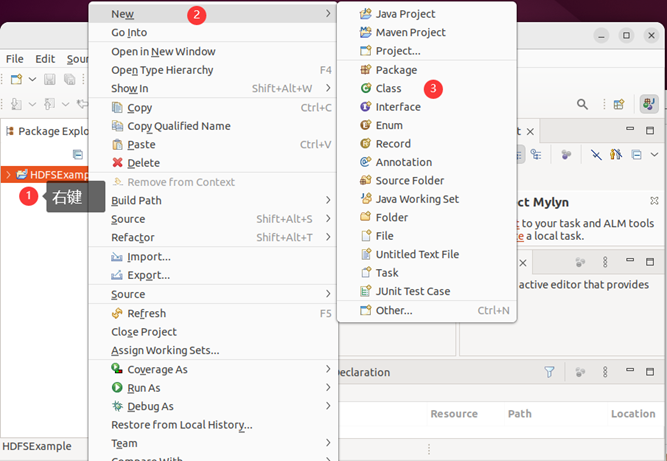
选择“new–>class”菜单以后会出现如下图所示界面。
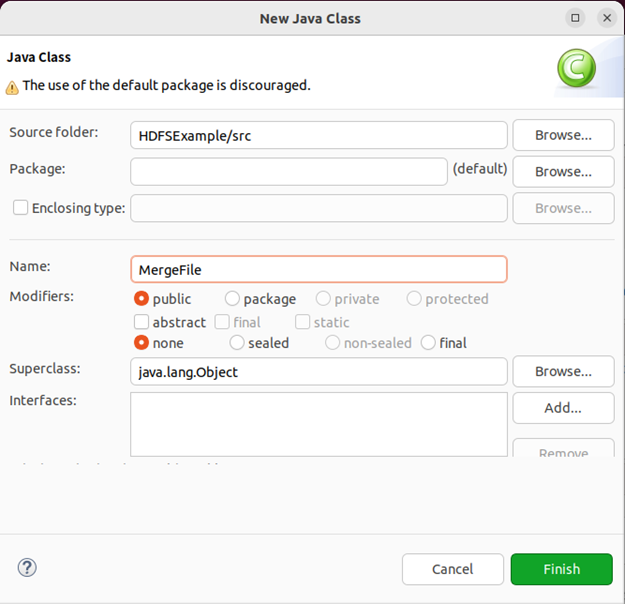
在该界面中,只需要在“name”后面输入新建的java类文件的名称,这里采用名称“mergefile”,其他都可以采用默认设置,然后,点击界面右下角“finish”按钮,eclipse就自动创建了一个名为“mergefile.java”的源代码文件,请在该文件中输入以下代码:
import java.io.ioexception;
import java.io.printstream;
import java.net.uri;
import org.apache.hadoop.conf.configuration;
import org.apache.hadoop.fs.\*;
/\*\*
\* 过滤掉文件名满足特定条件的文件
\*/
class mypathfilter implements pathfilter {
string reg = null;
mypathfilter(string reg) {
this.reg = reg;
}
public boolean accept(path path) {
if (!(path.tostring().matches(reg)))
return true;
return false;
}
}
/\*\*\*
\* 利用fsdataoutputstream和fsdatainputstream合并hdfs中的文件
\*/
public class mergefile {
path inputpath = null; //待合并的文件所在的目录的路径
path outputpath = null; //输出文件的路径
public mergefile(string input, string output) {
this.inputpath = new path(input);
this.outputpath = new path(output);
}
public void domerge() throws ioexception {
configuration conf = new configuration();
conf.set("fs.defaultfs","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.distributedfilesystem");
filesystem fssource = filesystem.get(uri.create(inputpath.tostring()), conf);
filesystem fsdst = filesystem.get(uri.create(outputpath.tostring()), conf);
//下面过滤掉输入目录中后缀为.abc的文件
filestatus[] sourcestatus = fssource.liststatus(inputpath,
new mypathfilter(".\*\\.abc"));
fsdataoutputstream fsdos = fsdst.create(outputpath);
printstream ps = new printstream(system.out);
//下面分别读取过滤之后的每个文件的内容,并输出到同一个文件中
for (filestatus sta : sourcestatus) {
//下面打印后缀不为.abc的文件的路径、文件大小
system.out.print("路径:" + sta.getpath() + " 文件大小:" + sta.getlen()
+ " 权限:" + sta.getpermission() + " 内容:");
fsdatainputstream fsdis = fssource.open(sta.getpath());
byte[] data = new byte[1024];
int read = -1;
while ((read = fsdis.read(data)) > 0) {
ps.write(data, 0, read);
fsdos.write(data, 0, read);
}
fsdis.close();
}
ps.close();
fsdos.close();
}
public static void main(string[] args) throws ioexception {
mergefile merge = new mergefile(
"hdfs://localhost:9000/user/hadoop/",
"hdfs://localhost:9000/user/hadoop/merge.txt");
merge.domerge();
}
}
🕘 4.5 编译运行程序
在开始编译运行程序之前,请一定确保hadoop已经启动运行,如果还没有启动,需要打开一个linux终端,输入以下命令启动hadoop,并检查是否都正常启动:
cd /usr/local/hadoop
./sbin/start-dfs.sh
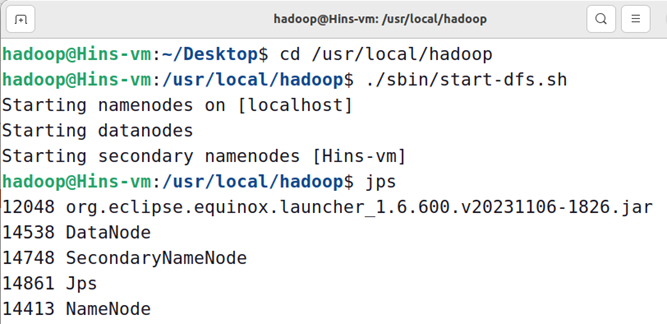
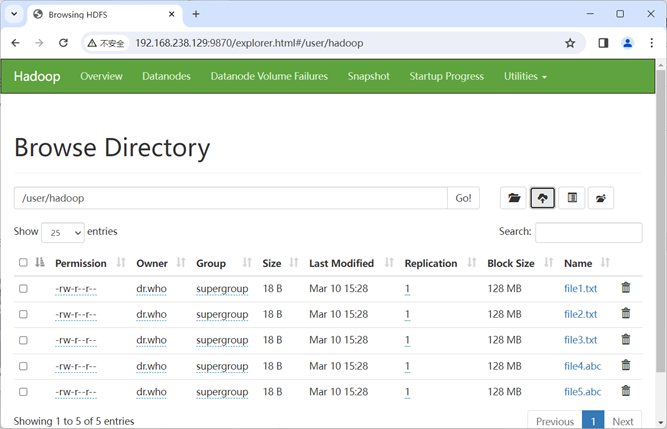
然后,要确保hdfs的“/user/hadoop”目录下已经存在file1.txt、file2.txt、file3.txt、file4.abc和file5.abc,每个文件里面有内容。这里,假设文件内容如下:
file1.txt的内容是:this is file1.txt
file2.txt的内容是:this is file2.txt
file3.txt的内容是:this is file3.txt
file4.abc的内容是:this is file4.abc
file5.abc的内容是:this is file5.abc
我们可以在windows端创建好文件,之后通过win端的浏览器上传
浏览器输入: http://[虚拟机ip]:9870/
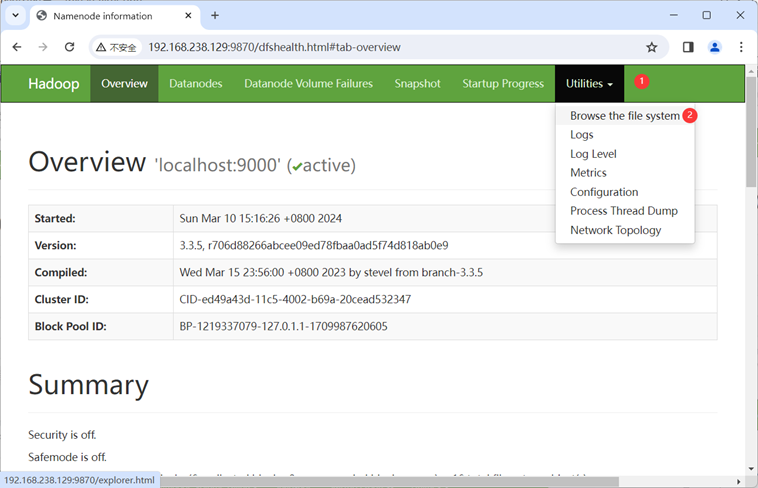
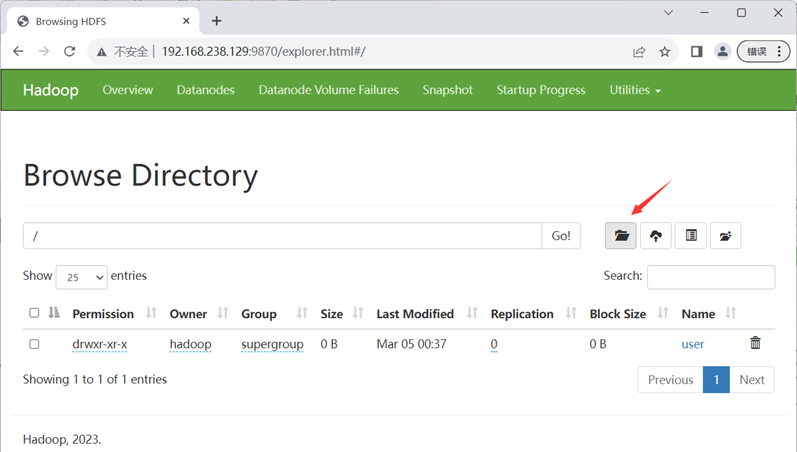
先创建好目录,再上传文件
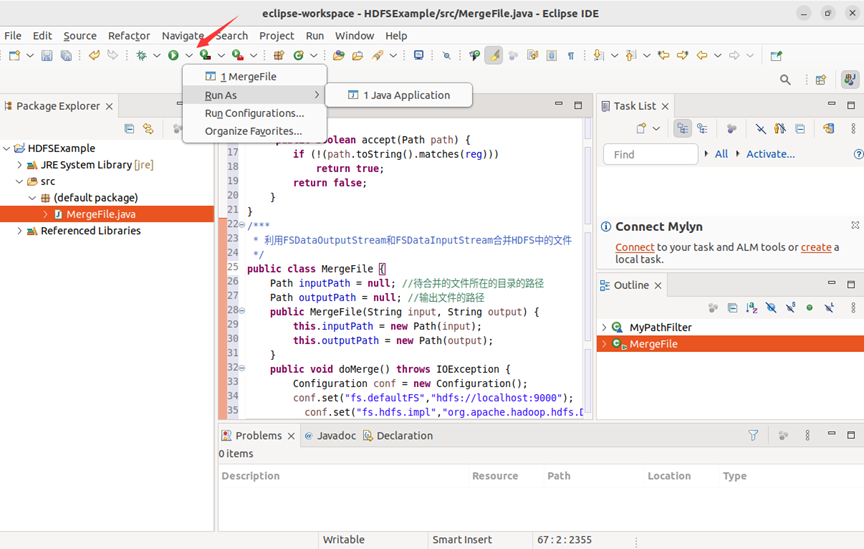
现在就可以编译运行上面编写的代码。可以直接点击eclipse工作界面上部的运行程序的快捷按钮,当把鼠标移动到该按钮上时,在弹出的菜单中选择“run as”,继续在弹出来的菜单中选择“java application”,如下图所示。
然后,会弹出如下图所示界面。
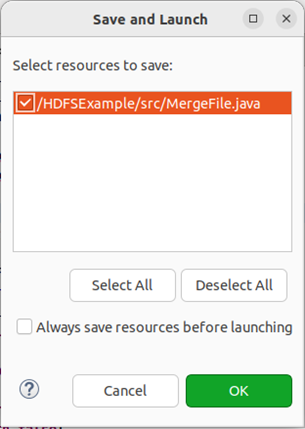
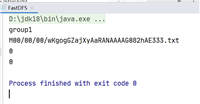
在该界面中,点击界面右下角的“ok”按钮,开始运行程序。程序运行结束后,会在底部的“console”面板中显示运行结果信息(如下图所示)。同时,“console”面板中还会显示一些类似“log4j:warn…”的警告信息,可以不用理会。

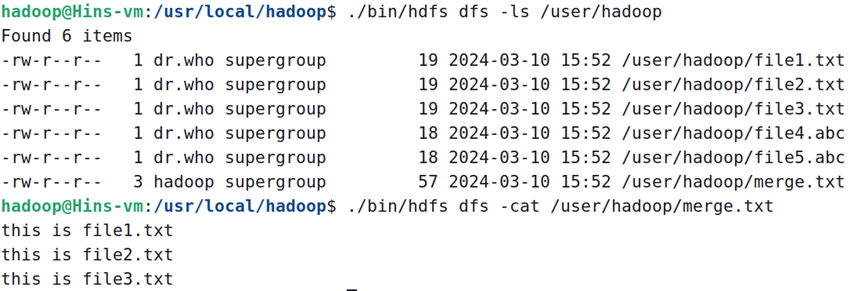
如果程序运行成功,这时,可以到hdfs中查看生成的merge.txt文件
在终端查看:
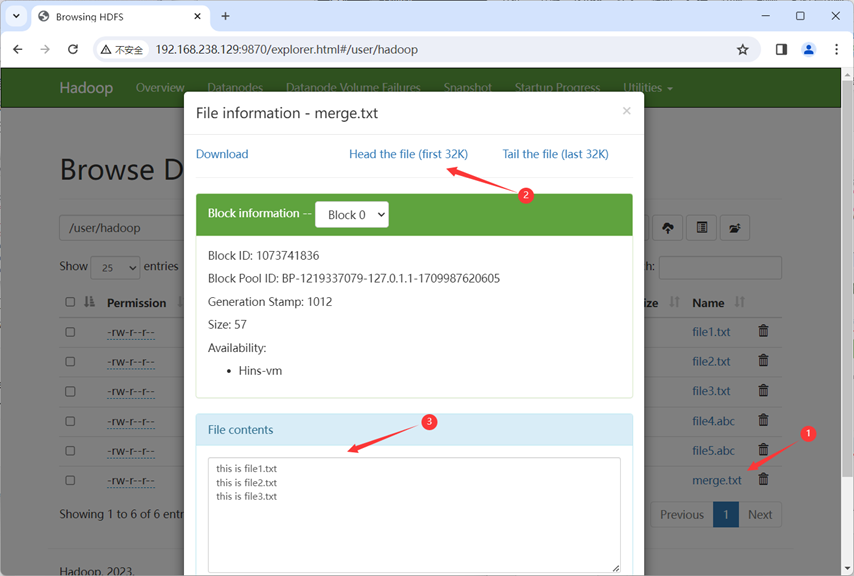
在web查看:
🕘 4.6 应用程序的部署
下面介绍如何把java应用程序生成jar包,部署到hadoop平台上运行。首先,在hadoop安装目录下新建一个名称为myapp的目录,用来存放我们自己编写的hadoop应用程序,可以在linux的终端中执行如下命令:
cd /usr/local/hadoop
mkdir myapp
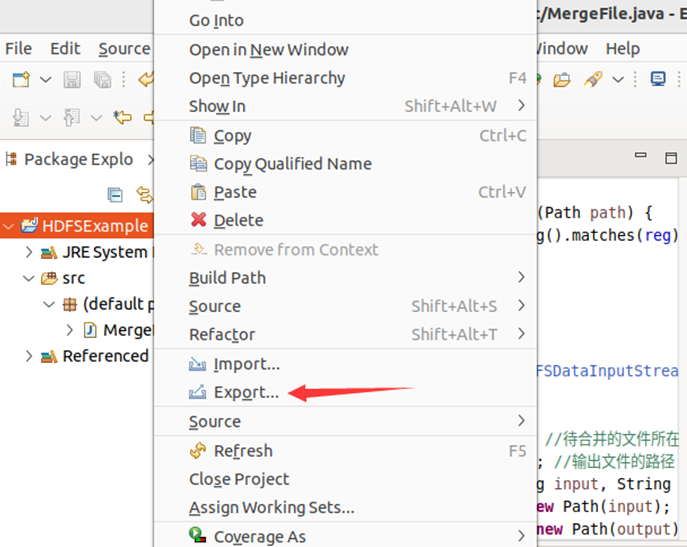
然后,在eclipse工作界面左侧的“package explorer”面板中,在工程名称“hdfsexample”上点击鼠标右键,在弹出的菜单中选择“export”,如下图所示。
在弹出的界面中,选择“runnable jar file”,然后,点击“next>”按钮,弹出如下图所示界面。
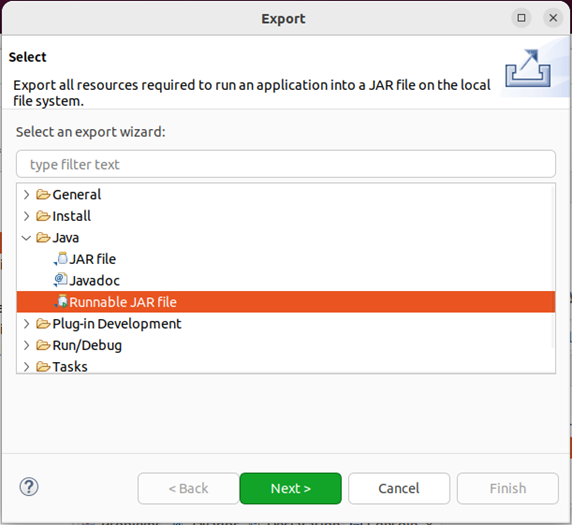
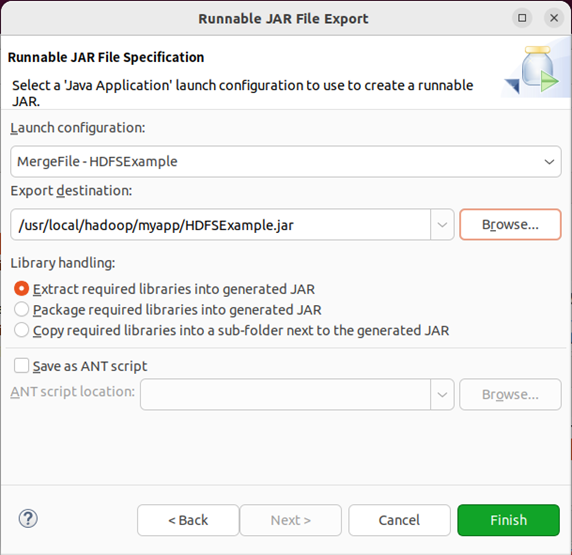
在该界面中,“launch configuration”用于设置生成的jar包被部署启动时运行的主类,需要在下拉列表中选择刚才配置的类“mergefile-hdfsexample”。在“export destination”中需要设置jar包要输出保存到哪个目录,比如,这里设置为“/usr/local/hadoop/myapp/hdfsexample.jar”。在“library handling”下面选择“extract required libraries into generated jar”。然后,点击“finish”按钮,之后会出现一些警告信息,点击ok无视即可。
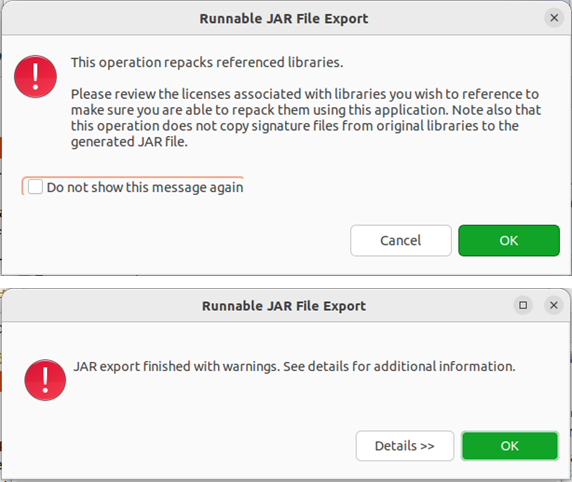
至此,已经顺利把hdfsexample工程打包生成了hdfsexample.jar。可以到linux系统中查看一下生成的hdfsexample.jar文件,可以在linux的终端中执行如下命令:

可以看到,“/usr/local/hadoop/myapp”目录下已经存在一个hdfsexample.jar文件。
由于之前已经运行过一次程序,已经生成了merge.txt,因此,需要首先执行如下命令删除该文件:
cd /usr/local/hadoop
./bin/hdfs dfs -rm /user/hadoop/merge.txt
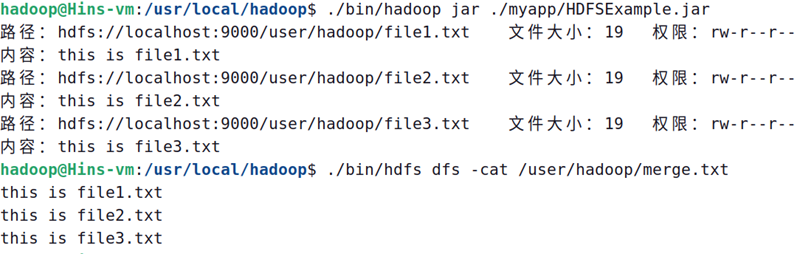
现在,就可以在linux系统中,使用hadoop jar命令运行程序,并到hdfs中查看生成的merge.txt文件:
cd /usr/local/hadoop
./bin/hadoop jar ./myapp/hdfsexample.jar
./bin/hdfs dfs -cat /user/hadoop/merge.txt
ok,以上就是本期知识点“hdfs分布式文件系统”的知识啦~~ ,感谢友友们的阅读。后续还会继续更新,欢迎持续关注哟📌~
💫如果有错误❌,欢迎批评指正呀👀~让我们一起相互进步🚀
🎉如果觉得收获满满,可以点点赞👍支持一下哟~
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事it行业的老鸟或是对it行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
oder
[外链图片转存中…(img-otwchieg-1714433802220)]
[外链图片转存中…(img-dx9v0odg-1714433802220)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事it行业的老鸟或是对it行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

发表评论