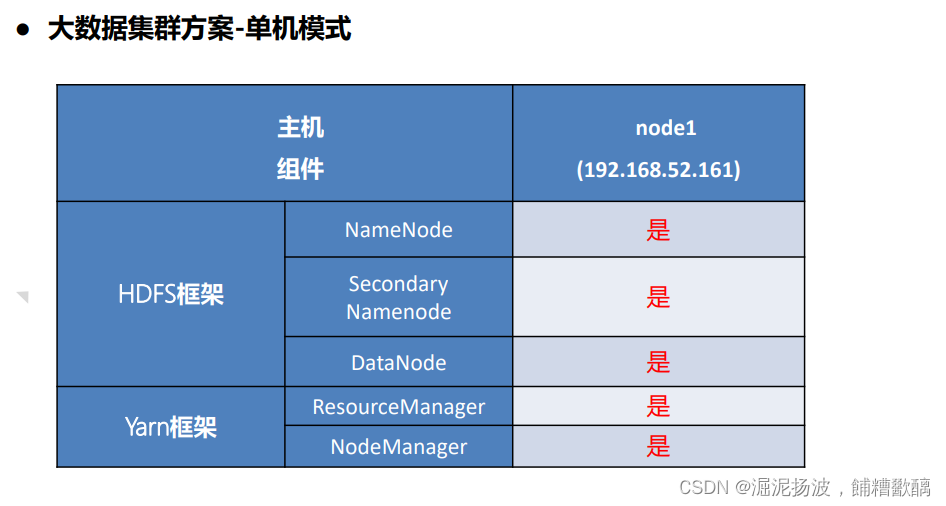
hadoop集群具体来说包含两个集群:hdfs集群和yarn集群,两者逻辑上分离,但物理上常在一起。
➢ hdfs集群 namenode、datanode、secondarynamenode
➢ yarn集群 resourcemanager、nodemanager`
集群一键启动和关闭
• 一键启动大数据环境
/onekey/my-stop-all.sh
• 一键关闭大数据环境
/onekey/my-start-all.sh
查看启动进程-jps
[root@node1 bin]# jps
2976 runjar
2881 jobhistoryserver
2692 nodemanager
2262 datanode
2583 resourcemanager
2123 namenode
2413 secondarynamenode
13726 jps
2975 runjar
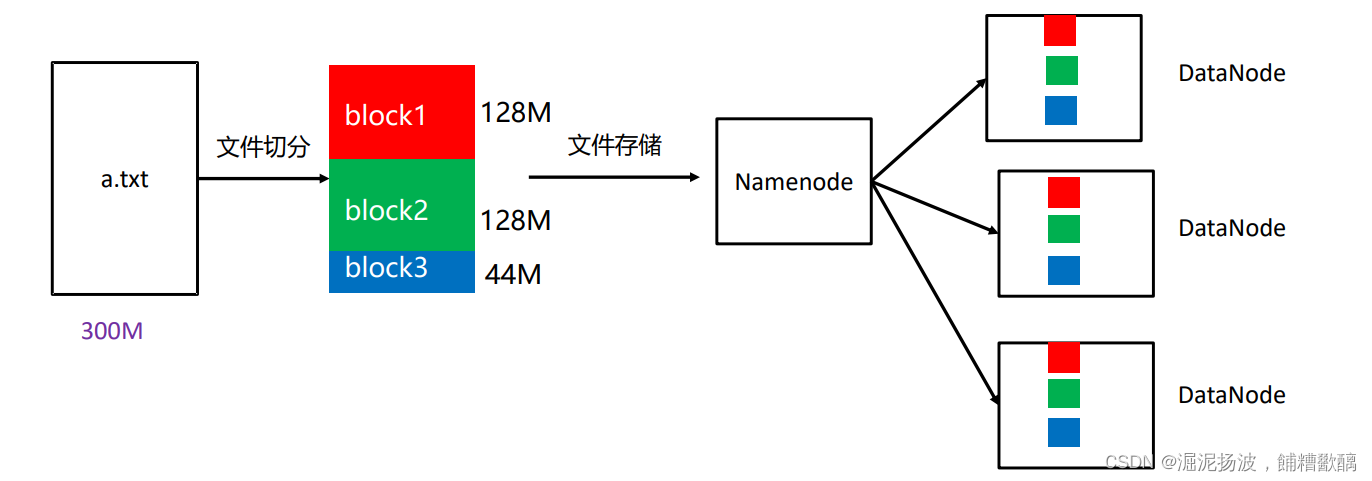
hdfs 集群架构介绍:
hdfs 架构主要由 namenode 和 datanode 两部分组成:
namenode:namenode 是 hdfs 的主节点,负责管理文件系统的命名空间,维护文件系统的元数据信息,包括文件目录结构、文件属性以及文件与数据块之间的映射关系。namenode 还负责协调客户端的读写请求,并控制数据块的复制和移动。
datanode:datanode 是 hdfs 的数据节点,负责存储实际的数据块。每个数据节点都会定期向 namenode 报告自己所存储的数据块信息,并根据 namenode 的指示执行数据块的复制、删除和移动等操作。
在 hdfs 集群中,通常会有一个 namenode 和多个 datanode 组成,数据节点分布在不同的物理机器上,以实现数据的分布式存储和高可靠性。通过复制数据块到多个数据节点上,hdfs 实现了数据的冗余备份,提高了数据的可靠性和容错性。
hdfs的副本机制


发表评论