引言
如何精准地提取pdf格式中嵌入的表格数据,并将其无缝转换为更加易于分析和操作的形式,如纯文本、csv文件或excel工作表,是一项重要的文档处理技巧。使用java,我们可以简单地实现这一过程。本文将介绍如何利用java从pdf文档提取表格数据,并写入文本文件、csv文件以及excel工作表。
本文所使用的方法提取pdf表格主要需要免费的free spire.pdf for java库,可下载导入或通过maven导入:
<dependency>
<groupid>e-iceblue</groupid>
<artifactid>spire.pdf.free</artifactid>
<version>9.13.0</version>
</dependency>
提取pdf表格需要用到库中的pdftableextractor类。我们可以为载入的pdf文件创建pdftableextractor对象,然后使用pdftableextractor.extracttable()方法根据页面在文档中的参数提取指定pdf页面上所有表格,最后再使用pdftable.gettext()方法即可获取表格中的数据。以下是一般操作步骤示例:
- 创建
pdfdocument对象并使用pdfdocument.loadfromfile()方法载入pdf文档。 - 使用载入的pdf文档创建
pdftableextractor对象。 - 使用
pdftableextractor.extracttable()方法提取每个页面上的表格。 - 使用
pdftable.gettext()方法获取pdf表格的单元格数据。
使用上述方法获取表格数据后,我们就可以将其写入文本文件,或搭配其他工具制作csv或excel文件了。
提取pdf表格数据写入文本文件
使用pdftableextractor.extracttable()方法提取表格并使用pdftable.gettext()方法获取单元格数据后,我们可以通过构建字符串并写入文本文件来实现提取表格并保存为文本文件的目的。以下是详细操作步骤:
- 导入所需模块。
- 创建
pdfdocument对象并使用pdfdocument.loadfromfile()方法载入pdf文档。 - 使用载入的pdf文档创建
pdftableextractor对象。 - 遍历页面,使用
pdftableextractor.extracttable()方法提取每个页面上的所有表格。 - 遍历提取到的表格,为每个表格创建一个
stringbuilder对象。 - 遍历表格中的行和列,使用
pdftable.gettext()方法获取每个单元格的数据并去除换行符。然后将单元格数据添加到stringbuilder对象。 - 将
stringbuilder对象写入文本文件。 - 释放资源。
代码示例
import com.spire.pdf.pdfdocument;
import com.spire.pdf.utilities.pdftable;
import com.spire.pdf.utilities.pdftableextractor;
import java.io.filewriter;
import java.io.ioexception;
public class 从pdf中提取文本 {
public static void main(string[] args) throws ioexception {
// 创建一个pdfdocument对象
pdfdocument pdf = new pdfdocument();
// 加载一个pdf文档
pdf.loadfromfile("sample.pdf");
// 创建一个pdftableextractor对象
pdftableextractor extractor = new pdftableextractor(pdf);
// 从每一页中提取表格
for (int pageindex = 0; pageindex < pdf.getpages().getcount(); pageindex++) {
pdftable[] tables = extractor.extracttable(pageindex);
// 如果表格不为空,则遍历表格
if (tables != null) {
for (int tableindex = 0; tableindex < tables.length; tableindex++) {
pdftable table = tables[tableindex];
// 创建一个stringbuilder对象
stringbuilder tabletext = new stringbuilder();
// 遍历行和列
for (int rowindex = 0; rowindex < table.getrowcount(); rowindex++) {
for (int colindex = 0; colindex < table.getcolumncount(); colindex++) {
// 获取单元格文本并移除换行符
string celltext = table.gettext(rowindex, colindex);
celltext = celltext.replaceall("\\r|\\n", "");
if (colindex < table.getcolumncount() - 1) {
tabletext.append(celltext).append("\t");
} else {
tabletext.append(celltext).append("\n");
}
}
}
// 将表格写入文本文件
try (filewriter writer = new filewriter("output/tables/page" + (pageindex+1) + "-table" + (tableindex+1) + ".txt")) {
writer.write(tabletext.tostring());
}
}
}
}
}
}
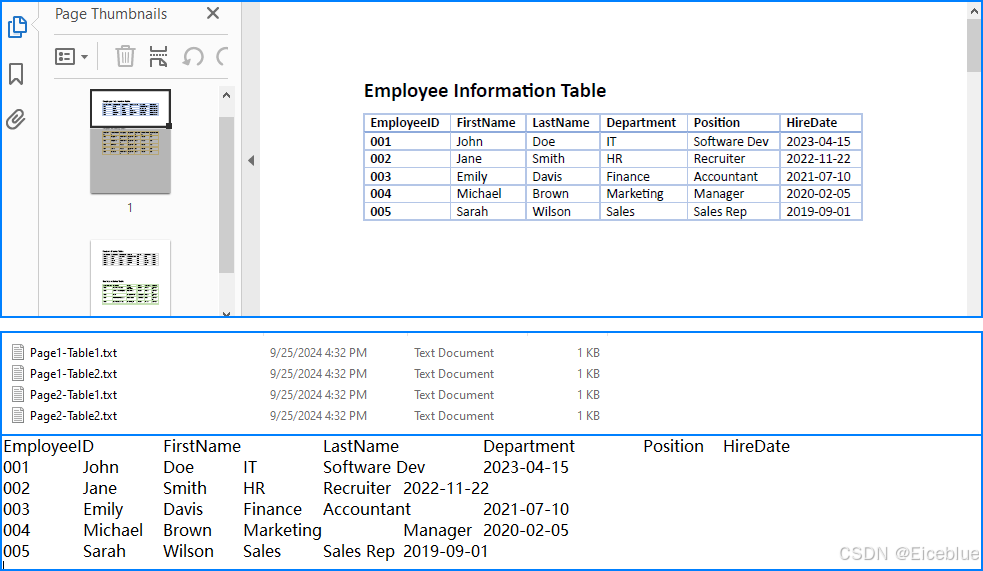
提取结果
提取pdf表格数据写入csv文件
我们也可以用同样的方法提取表格数据,然后搭配其他模块,如opencsv,将提取到的数据写入csv文件。也可以使用下面的提取pdf表格写入excel文件,最后保存时保存为csv文件。
opencsv:
<dependency> <groupid>com.opencsv</groupid> <artifactid>opencsv</artifactid> <version>5.9</version> </dependency>
以下是搭配opencsv提取pdf表格数据并写入csv文件的操作步骤:
- 导入所需模块。
- 创建
pdfdocument对象并使用pdfdocument.loadfromfile()方法载入pdf文档。 - 使用载入的pdf文档创建
pdftableextractor对象。 - 历页面面,使用
pdftableextractor.extracttable()方法提取每个页面上的所有表格。 - 遍历提取的表格,并构建csv文件名。
- 创建
csvwriter对象,遍历表格行以及行中的列,使用pdftable.gettext()方法获取每个单元格的数据并去除换行符,将提取的每行表格数据构建为字符串列表。最后将字符串列表写入为csv数据行。 - 释放资源。
代码示例
import com.opencsv.csvwriter;
import com.spire.pdf.pdfdocument;
import com.spire.pdf.utilities.pdftable;
import com.spire.pdf.utilities.pdftableextractor;
import java.io.filewriter;
import java.io.ioexception;
public class 从pdf表格提取到csv {
public static void main(string[] args) throws ioexception {
// 创建一个pdfdocument对象
pdfdocument pdf = new pdfdocument();
// 加载一个pdf文档
pdf.loadfromfile("sample.pdf");
// 创建一个pdftableextractor对象
pdftableextractor extractor = new pdftableextractor(pdf);
// 从每一页中提取表格
for (int pageindex = 0; pageindex < pdf.getpages().getcount(); pageindex++) {
pdftable[] tables = extractor.extracttable(pageindex);
// 如果表格不为空,则遍历表格
if (tables != null) {
for (int tableindex = 0; tableindex < tables.length; tableindex++) {
pdftable table = tables[tableindex];
// 创建csv文件名
string csvfilename = "output/tables/page" + (pageindex + 1) + "-table" + (tableindex + 1) + ".csv";
// 创建一个csvwriter对象
try (csvwriter writer = new csvwriter(new filewriter(csvfilename))) {
// 遍历行和列
for (int rowindex = 0; rowindex < table.getrowcount(); rowindex++) {
string[] row = new string[table.getcolumncount()];
for (int colindex = 0; colindex < table.getcolumncount(); colindex++) {
// 获取单元格文本并移除换行符
string celltext = table.gettext(rowindex, colindex).replaceall("\\r?\\n", "");
row[colindex] = celltext;
}
// 将行写入csv文件
writer.writenext(row);
}
}
}
}
}
// 关闭pdf文档
pdf.close();
}
}
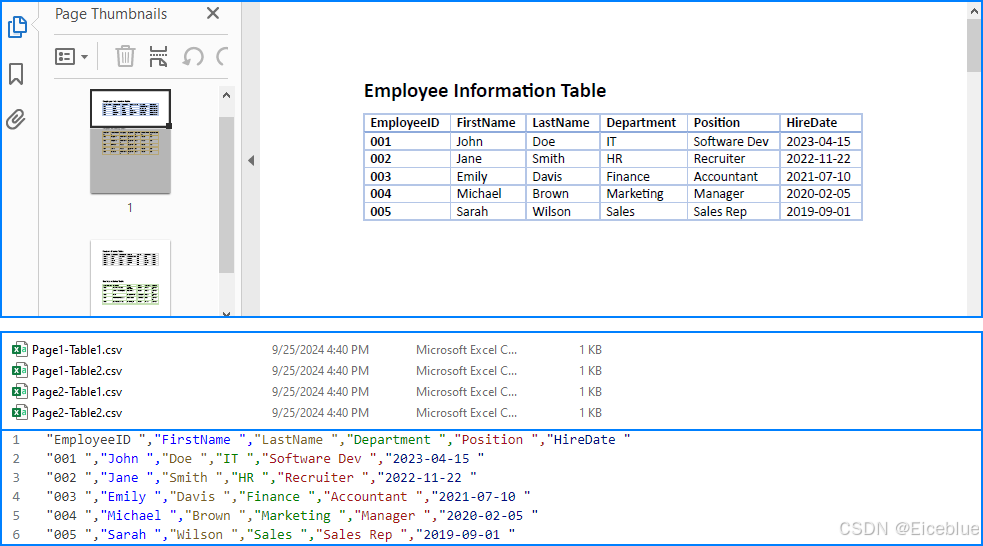
提取结果
提取pdf表格数据写入excel文件
保存pdf表格到表格需要用到free spire.xls for java。我们可以提取到pdf文档表格单元格数据后,使用worksheet.getrange().settext()方法将数据写入到创建的excel工作表的相应单元格并保存,从而实现pdf表格数据到excel文件的提取。同时,我们还可以在保存文件时将格式参数设置为csv,实现pdf表格数据到csv文件的提取。
free spire.xls for java:
<dependency>
<groupid>e-iceblue</groupid>
<artifactid>spire.xls.free</artifactid>
<version>5.3.0</version>
</dependency>
以下是详细操作步骤:
- 导入所需模块。
- 创建
pdfdocument对象并使用pdfdocument.loadfromfile()方法载入pdf文档。 - 创建
workbook对象,并使用workbook.getworksheets().clear()方法清除默认工作表。 - 使用载入的pdf文档创建
pdftableextractor对象。 - 历页面面,使用
pdftableextractor.extracttable()方法提取每个页面上的所有表格。 - 遍历提取的表格,使用
workbook.getworksheets().add()方法为每个表格创建一个指定名称的工作表。 - 遍历表格行和列,使用
pdftable.gettext()方法获取每个单元格的数据并去除换行符,然后使用worksheet.getrange().settext()方法将单元格数据写入到工作表的相应单元格。 - 设置工作表单元格的格式。
- 使用
worksheet.autofitrow()和worksheet.autofitcolumn()方法自动调整行高和列宽。 - 可以使用
worksheet.savetofile()方法将工作表保存为csv文件。 - 使用
workbook.savetofile()方法保存工作簿为excel文件。 - 释放资源。
代码示例
import com.spire.pdf.pdfdocument;
import com.spire.pdf.utilities.pdftable;
import com.spire.pdf.utilities.pdftableextractor;
import com.spire.xls.*;
public class 从pdf表格提取到excel {
public static void main(string[] args) {
// 创建一个pdfdocument对象
pdfdocument pdf = new pdfdocument();
// 加载一个pdf文档
pdf.loadfromfile("g:/documents/sample73.pdf");
// 创建一个workbook对象
workbook workbook = new workbook();
workbook.getworksheets().clear();
// 创建一个pdftableextractor对象
pdftableextractor extractor = new pdftableextractor(pdf);
// 从每一页中提取表格
for (int pageindex = 0; pageindex < pdf.getpages().getcount(); pageindex++) {
pdftable[] tables = extractor.extracttable(pageindex);
// 如果表格不为空,则遍历表格
if (tables != null) {
for (int tableindex = 0; tableindex < tables.length; tableindex++) {
// 向工作簿中添加一个工作表
worksheet sheet = workbook.getworksheets().add("page" + (pageindex + 1) + "-table" + (tableindex + 1));
// 遍历表格中的行和列
for (int rowindex = 0; rowindex < tables[tableindex].getrowcount(); rowindex++) {
for (int colindex = 0; colindex < tables[tableindex].getcolumncount(); colindex++) {
// 获取单元格文本并移除换行符
string celltext = tables[tableindex].gettext(rowindex, colindex).replaceall("\\r|\\n", "");
// 将单元格文本写入工作表
sheet.getcellrange(rowindex+1, colindex+1).settext(celltext);
}
}
// 设置单元格样式
cellrange[] rows = sheet.getrows();
rows[0].getstyle().getfont().setfontname("harmonyos sans sc");
rows[0].getstyle().getfont().setsize(12);
rows[0].getstyle().getfont().isbold(true);
rows[0].getstyle().sethorizontalalignment(horizontalaligntype.center);
for (int i = 1; i < rows.length; i++) {
rows[i].getstyle().getfont().setfontname("harmonyos sans sc");
rows[i].getstyle().getfont().setsize(12);
rows[i].getstyle().sethorizontalalignment(horizontalaligntype.left);
}
// 自动调整行和列
for (int i = 0; i < rows.length; i++) {
sheet.autofitrow(i+1);
}
for (int i = 0; i < sheet.getcolumns().length; i++) {
sheet.autofitcolumn(i+1);
}
// 保存工作表为csv文件
// sheet.savetofile("output/tables/pdftabletocsv-page" + (pageindex + 1) + "-table" + (tableindex + 1) + ".csv", ",");
}
}
}
// 保存工作簿
workbook.savetofile("output/pdftabletoexcel.xlsx");
// 关闭pdf文档
pdf.close();
// 释放工作簿资源
workbook.dispose();
}
}
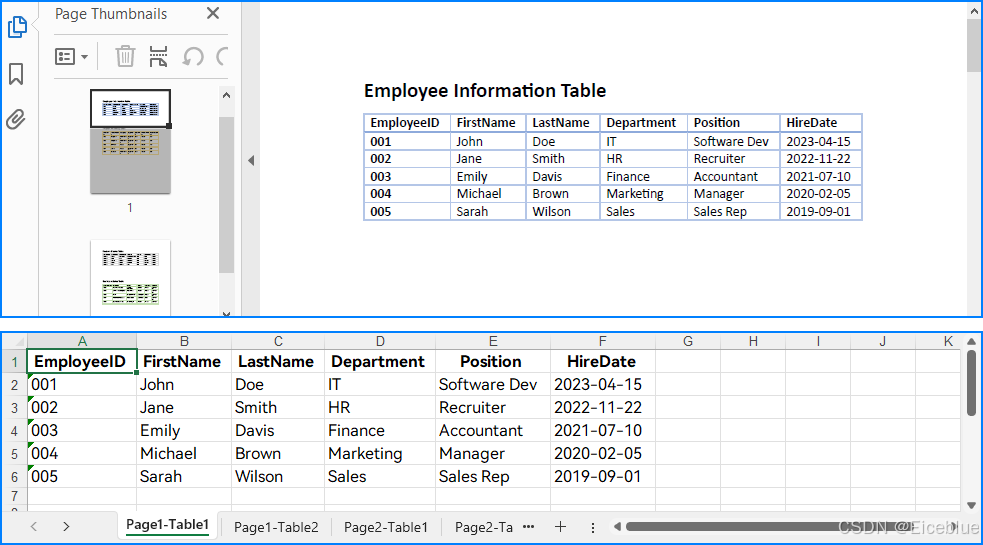
提取结果
本文演示了如何使用java提取pdf表格数据写入文本、csv以及excel文件。
以上就是利用java提取pdf表格到文本、csv及excel工作表的详细内容,更多关于java提取pdf表格的资料请关注代码网其它相关文章!

发表评论