前言
与开发接口比起来,登录认证功能对于新手来说理解起来更难,但是登录又是每个系统中必不可少的功能,很多系统中的功能,没有登录是无法使用的,比如商场中的购物车,你不用账号登录,根本不知道购物车中有啥。本篇博客主题就是登录认证。 最终我们要实现的效果就是用户必须登录之后,才可以访问后台系统中的功能。
需求
在登录界面中,我们可以输入用户的用户名以及密码,然后点击 “登录” 按钮就要请求服务器,服务端判断用户输入的用户名或者密码是否正确。如果正确,则返回成功结果,前端跳转至系统首页面。
接口文档
基本信息
请求路径:/login
请求方式:post
接口描述:该接口用于员工登录系统,登录完毕后,系统下发jwt令牌。
请求参数
参数格式:application/json
参数说明:
| 名称 | 类型 | 是否必须 | 备注 |
|---|---|---|---|
| username | string | 必须 | 用户名 |
| password | string | 必须 | 密码 |
请求数据样例:
{
"username": "jinyong",
"password": "123456"
}响应数据
参数格式:application/json
参数说明:
| 名称 | 类型 | 是否必须 | 默认值 | 备注 | 其他信息 |
|---|---|---|---|---|---|
| code | number | 必须 | 响应码, 1 成功 ; 0 失败 | ||
| msg | string | 非必须 | 提示信息 | ||
| data | string | 必须 | 返回的数据 , jwt令牌 |
响应数据样例:
{
"code": 1,
"msg": "success",
"data": "eyjhbgcioijiuzi1nij9.eyjuyw1lijoi6yer5bq4iiwiawqiojesinvzzxjuyw1lijoiamluew9uzyisimv4cci6mty2mjiwnza0oh0.kkuc_cxjzj8dd063eimx4h9ojfrr6xmj-yvzawcvzco"
}思路分析

登录服务端的核心逻辑就是:接收前端请求传递的用户名和密码 ,然后再根据用户名和密码查询用户信息,如果用户信息存在,则说明用户输入的用户名和密码正确。如果查询到的用户不存在,则说明用户输入的用户名和密码错误。
功能开发
logincontroller
@restcontroller
public class logincontroller {
@autowired
private empservice empservice;
@postmapping("/login")
public result login(@requestbody emp emp){
emp e = empservice.login(emp);
return e != null ? result.success():result.error("用户名或密码错误");
}
}empservice
public interface empservice {
/**
* 用户登录
* @param emp
* @return
*/
public emp login(emp emp);
//省略其他代码...
}empserviceimpl
@slf4j
@service
public class empserviceimpl implements empservice {
@autowired
private empmapper empmapper;
@override
public emp login(emp emp) {
//调用dao层功能:登录
emp loginemp = empmapper.getbyusernameandpassword(emp);
//返回查询结果给controller
return loginemp;
}
//省略其他代码...
}empmapper
@mapper
public interface empmapper {
@select("select id, username, password, name, gender, image, job, entrydate, dept_id, create_time, update_time " +
"from emp " +
"where username=#{username} and password =#{password}")
public emp getbyusernameandpassword(emp emp);
//省略其他代码...
}问题分析
我们已经完成了基础登录功能的开发,在我们登录成功后就可以进入到后台管理系统中进行数据的操作。
但是真正的登录功能应该是:登陆后才能访问后端系统页面,不登陆则跳转登陆页面进行登陆。
为什么会出现这个问题?其实原因很简单,就是因为针对于我们当前所开发的部门管理、员工管理以及文件上传等相关接口来说,我们在服务器端并没有做任何的判断,没有去判断用户是否登录了。所以无论用户是否登录,都可以访问部门管理以及员工管理的相关数据。所以我们目前所开发的登录功能,它只是徒有其表。而我们要想解决这个问题,我们就需要完成一步非常重要的操作:登录校验。
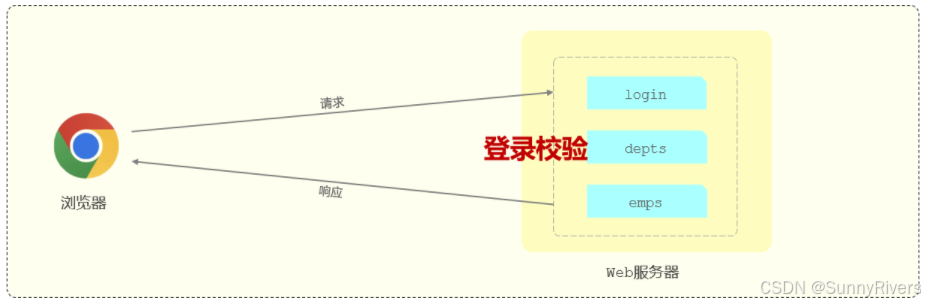
什么是登录校验?
所谓登录校验,指的是我们在服务器端接收到浏览器发送过来的请求之后,首先我们要对请求进行校验。先要校验一下用户登录了没有,如果用户已经登录了,就直接执行对应的业务操作就可以了;如果用户没有登录,此时就不允许他执行相关的业务操作,直接给前端响应一个错误的结果,最终跳转到登录页面,要求他登录成功之后,再来访问对应的数据。
了解完什么是登录校验之后,接下来我们分析一下登录校验大概的实现思路。
首先我们在宏观上先有一个认知:
前面在讲解http协议的时候,我们提到http协议是无状态协议。什么又是无状态的协议?
所谓无状态,指的是每一次请求都是独立的,下一次请求并不会携带上一次请求的数据。而浏览器与服务器之间进行交互,基于http协议也就意味着现在我们通过浏览器来访问了登陆这个接口,实现了登陆的操作,接下来我们在执行其他业务操作时,服务器也并不知道这个员工到底登陆了没有。因为http协议是无状态的,两次请求之间是独立的,所以是无法判断这个员工到底登陆了没有。
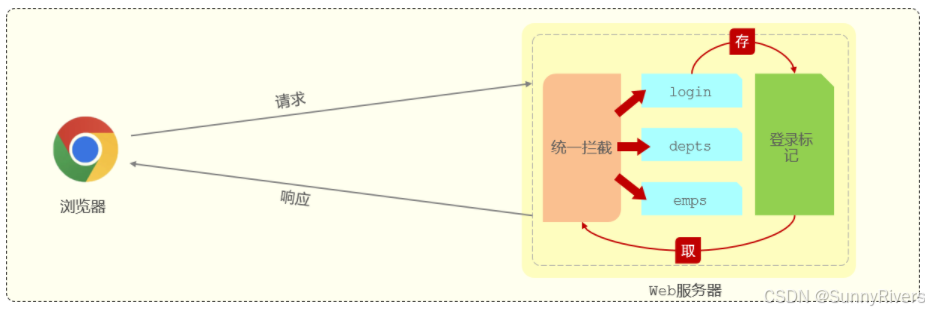
那应该怎么来实现登录校验的操作呢?具体的实现思路可以分为两部分:
- 在员工登录成功后,需要将用户登录成功的信息存起来,记录用户已经登录成功的标记。
- 在浏览器发起请求时,需要在服务端进行统一拦截,拦截后进行登录校验。
想要判断员工是否已经登录,我们需要在员工登录成功之后,存储一个登录成功的标记,接下来在每一个接口方法执行之前,先做一个条件判断,判断一下这个员工到底登录了没有。如果是登录了,就可以执行正常的业务操作,如果没有登录,会直接给前端返回一个错误的信息,前端拿到这个错误信息之后会自动的跳转到登录页面。
我们程序中所开发的查询功能、删除功能、添加功能、修改功能,都需要使用以上套路进行登录校验。此时就会出现:相同代码逻辑,每个功能都需要编写,就会造成代码非常繁琐。
为了简化这块操作,我们可以使用一种技术:统一拦截技术。
通过统一拦截的技术,我们可以来拦截浏览器发送过来的所有的请求,拦截到这个请求之后,就可以通过请求来获取之前所存入的登录标记,在获取到登录标记且标记为登录成功,就说明员工已经登录了。如果已经登录,我们就直接放行(意思就是可以访问正常的业务接口了)。
我们要完成以上操作,会涉及到web开发中的两个技术:
- 会话技术
- 统一拦截技术
而统一拦截技术现实方案也有两种:
- servlet规范中的filter过滤器
- spring提供的interceptor拦截器
下面我们先学习会话技术,然后再学习统一拦截技术。
会话技术介绍
什么是会话?
- 在我们日常生活当中,会话指的就是谈话、交谈。
- 在web开发当中,会话指的就是浏览器与服务器之间的一次连接,我们就称为一次会话。
在用户打开浏览器第一次访问服务器的时候,这个会话就建立了,直到有任何一方断开连接,此时会话就结束了。在一次会话当中,是可以包含多次请求和响应的。
比如:打开了浏览器来访问web服务器上的资源(浏览器不能关闭、服务器不能断开)
- 第1次:访问的是登录的接口,完成登录操作
- 第2次:访问的是部门管理接口,查询所有部门数据
- 第3次:访问的是员工管理接口,查询员工数据
只要浏览器和服务器都没有关闭,以上3次请求都属于一次会话当中完成的。
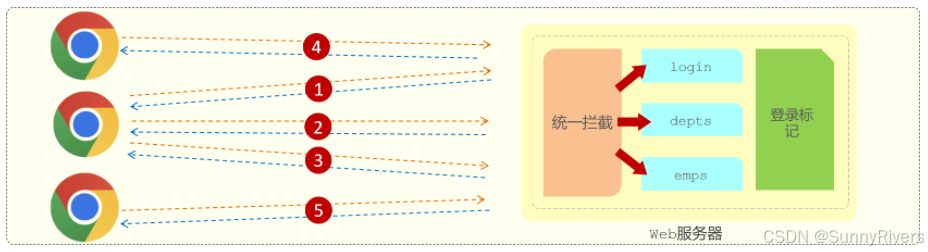
需要注意的是:会话是和浏览器关联的,当有三个浏览器客户端和服务器建立了连接时,就会有三个会话。同一个浏览器在未关闭之前请求了多次服务器,这多次请求是属于同一个会话。比如:1、2、3这三个请求都是属于同一个会话。当我们关闭浏览器之后,这次会话就结束了。而如果我们是直接把web服务器关了,那么所有的会话就都结束了。
知道了会话的概念了,接下来我们再来了解下会话跟踪。
会话跟踪:一种维护浏览器状态的方法,服务器需要识别多次请求是否来自于同一浏览器,以便在同一次会话的多次请求间共享数据。
服务器会接收很多的请求,但是服务器是需要识别出这些请求是不是同一个浏览器发出来的。比如:1和2这两个请求是不是同一个浏览器发出来的,3和5这两个请求不是同一个浏览器发出来的。如果是同一个浏览器发出来的,就说明是同一个会话。如果是不同的浏览器发出来的,就说明是不同的会话。而识别多次请求是否来自于同一浏览器的过程,我们就称为会话跟踪。
我们使用会话跟踪技术就是要完成在同一个会话中,多个请求之间进行共享数据。
为什么要共享数据呢?
由于http是无状态协议,在后面请求中怎么拿到前一次请求生成的数据呢?此时就需要在一次会话的多次请求之间进行数据共享。
会话跟踪技术有三种:
- cookie(客户端会话跟踪技术)
- 数据存储在客户端浏览器当中
- session(服务端会话跟踪技术)
- 数据存储在储在服务端
- 令牌技术
会话跟踪技术一:cookie
cookie 是客户端会话跟踪技术,它是存储在客户端浏览器的,我们使用 cookie 来跟踪会话,我们就可以在浏览器第一次发起请求来请求服务器的时候,我们在服务器端来设置一个cookie。
比如第一次请求了登录接口,登录接口执行完成之后,我们就可以设置一个cookie,在 cookie 当中我们就可以来存储用户相关的一些数据信息。比如我可以在 cookie 当中来存储当前登录用户的用户名,用户的id。
服务器端在给客户端在响应数据的时候,会自动的将 cookie 响应给浏览器,浏览器接收到响应回来的 cookie 之后,会自动的将 cookie 的值存储在浏览器本地。接下来在后续的每一次请求当中,都会将浏览器本地所存储的 cookie 自动地携带到服务端。
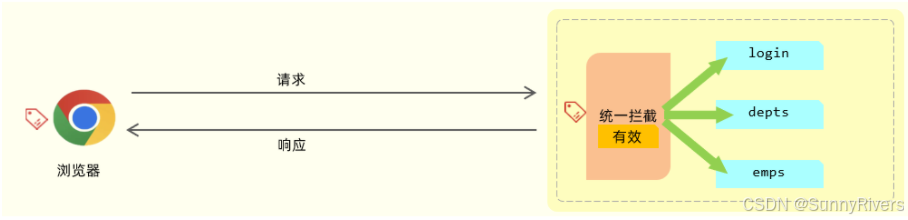
接下来在服务端我们就可以获取到 cookie 的值。我们可以去判断一下这个 cookie 的值是否存在,如果不存在这个cookie,就说明客户端之前是没有访问登录接口的;如果存在 cookie 的值,就说明客户端之前已经登录完成了。这样我们就可以基于 cookie 在同一次会话的不同请求之间来共享数据。
我刚才在介绍流程的时候,用了 3 个自动:
- 服务器会 自动 的将 cookie 响应给浏览器。
- 浏览器接收到响应回来的数据之后,会 自动 的将 cookie 存储在浏览器本地。
- 在后续的请求当中,浏览器会 自动 的将 cookie 携带到服务器端。
为什么这一切都是自动化进行的?
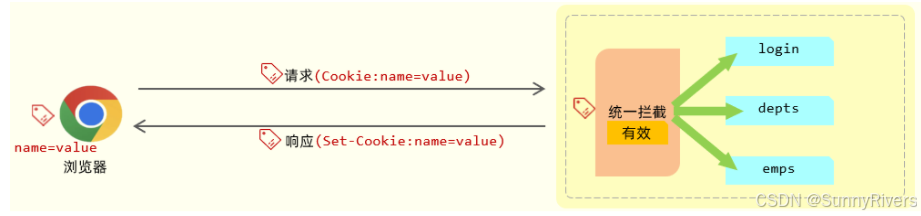
是因为 cookie 它是 htp 协议当中所支持的技术,而各大浏览器厂商都支持了这一标准。在 http 协议官方给我们提供了一个响应头和请求头:
- 响应头 set-cookie :设置cookie数据的
- 请求头 cookie:携带cookie数据的
代码测试
@slf4j
@restcontroller
public class sessioncontroller {
//设置cookie
@getmapping("/c1")
public result cookie1(httpservletresponse response){
response.addcookie(new cookie("login_username","xc")); //设置cookie/响应cookie
return result.success();
}
//获取cookie
@getmapping("/c2")
public result cookie2(httpservletrequest request){
cookie[] cookies = request.getcookies();
for (cookie cookie : cookies) {
if(cookie.getname().equals("login_username")){
system.out.println("login_username: "+cookie.getvalue()); //输出name为login_username的cookie
}
}
return result.success();
}
} a. 访问c1接口,设置cookie,http://localhost:8080/c1
我们可以看到,设置的cookie,通过响应头set-cookie响应给浏览器,并且浏览器会将cookie,存储在浏览器端。
b. 访问c2接口 http://localhost:8080/c2,此时浏览器会自动的将cookie携带到服务端,是通过请求头cookie,携带的。
优缺点
- 优点:http协议中支持的技术(像set-cookie 响应头的解析以及 cookie 请求头数据的携带,都是浏览器自动进行的,是无需我们手动操作的)
- 缺点:
- 移动端app(android、ios)中无法使用cookie
- 不安全,用户可以自己禁用cookie
- cookie不能跨域
跨域介绍:
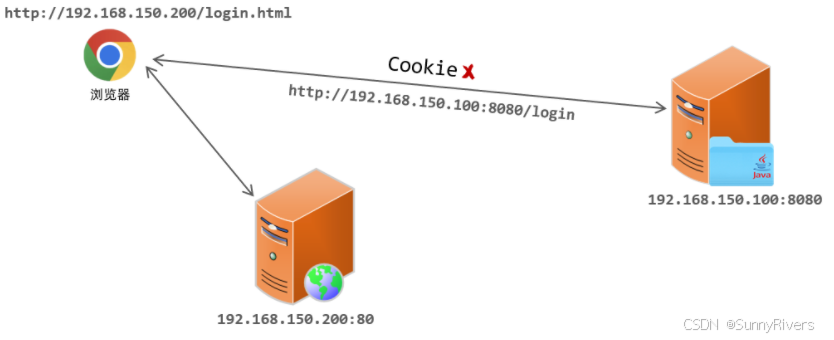
- 现在的项目,大部分都是前后端分离的,前后端最终也会分开部署,前端部署在服务器 192.168.150.200 上,端口 80,后端部署在 192.168.150.100上,端口 8080
- 我们打开浏览器直接访问前端工程,访问url:http://192.168.150.200/login.html
- 然后在该页面发起请求到服务端,而服务端所在地址不再是localhost,而是服务器的ip地址192.168.150.100,假设访问接口地址为:http://192.168.150.100:8080/login
- 那此时就存在跨域操作了,因为我们是在 http://192.168.150.200/login.html 这个页面上访问了http://192.168.150.100:8080/login 接口
- 此时如果服务器设置了一个cookie,这个cookie是不能使用的,因为cookie无法跨域
区分跨域的维度:
- 协议
- ip/协议
- 端口
只要上述的三个维度有任何一个维度不同,那就是跨域操作
举例:
http://192.168.150.200/login.html ----------> https://192.168.150.200/login [协议不同,跨域]
http://192.168.150.200/login.html ----------> http://192.168.150.100/login [ip不同,跨域]
http://192.168.150.200/login.html ----------> http://192.168.150.200:8080/login [端口不同,跨域]
http://192.168.150.200/login.html ----------> http://192.168.150.200/login [不跨域]
会话跟踪技术二:session
前面介绍的时候,我们提到session,它是服务器端会话跟踪技术,所以它是存储在服务器端的。而 session 的底层其实就是基于我们刚才所介绍的 cookie 来实现的。
获取session
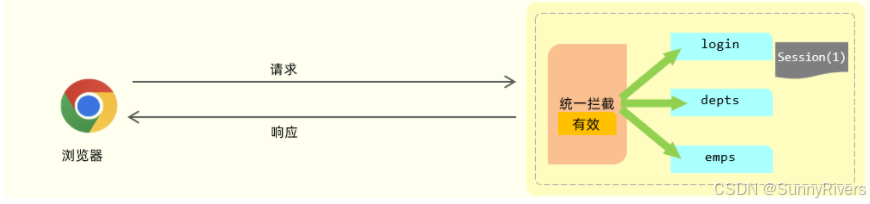
如果我们现在要基于 session 来进行会话跟踪,浏览器在第一次请求服务器的时候,我们就可以直接在服务器当中来获取到会话对象session。如果是第一次请求session ,会话对象是不存在的,这个时候服务器会自动的创建一个会话对象session 。而每一个会话对象session ,它都有一个id(示意图中session后面括号中的1,就表示id),我们称之为 session 的id。
响应cookie (jsessionid)
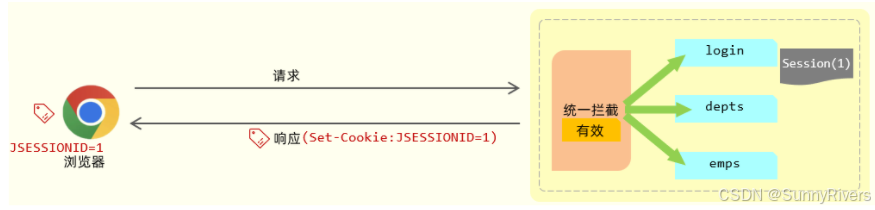
接下来,服务器端在给浏览器响应数据的时候,它会将 session 的 id 通过 cookie 响应给浏览器。其实在响应头当中增加了一个 set-cookie 响应头。这个 set-cookie 响应头对应的值是不是cookie? cookie 的名字是固定的 jsessionid 代表的服务器端会话对象 session 的 id。浏览器会自动识别这个响应头,然后自动将cookie存储在浏览器本地。
查找session
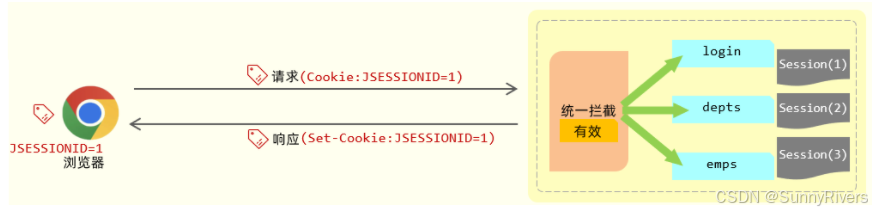
接下来,在后续的每一次请求当中,都会将 cookie 的数据获取出来,并且携带到服务端。接下来服务器拿到jsessionid这个 cookie 的值,也就是 session 的id。拿到 id 之后,就会从众多的 session 当中来找到当前请求对应的会话对象session。
这样我们是不是就可以通过 session 会话对象在同一次会话的多次请求之间来共享数据了?好,这就是基于 session 进行会话跟踪的流程。
代码测试
@slf4j
@restcontroller
public class sessioncontroller {
@getmapping("/s1")
public result session1(httpsession session){
log.info("httpsession-s1: {}", session.hashcode());
session.setattribute("loginuser", "tom"); //往session中存储数据
return result.success();
}
@getmapping("/s2")
public result session2(httpservletrequest request){
httpsession session = request.getsession();
log.info("httpsession-s2: {}", session.hashcode());
object loginuser = session.getattribute("loginuser"); //从session中获取数据
log.info("loginuser: {}", loginuser);
return result.success(loginuser);
}
}a. 访问 s1 接口,http://localhost:8080/s1
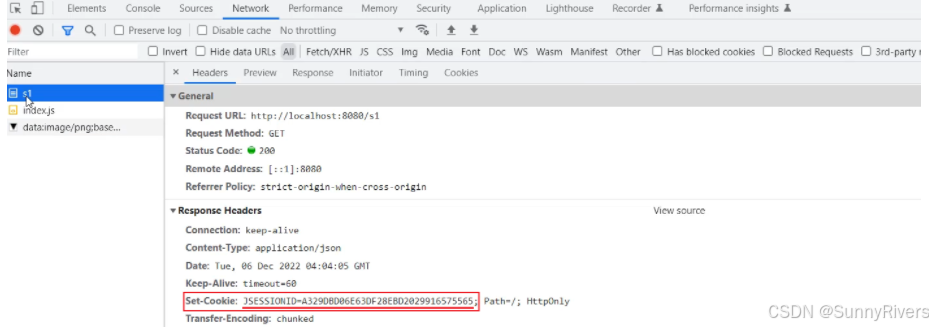
请求完成之后,在响应头中,就会看到有一个set-cookie的响应头,里面响应回来了一个cookie,就是jsessionid,这个就是服务端会话对象 session 的id。
b. 访问 s2 接口,http://localhost:8080/s2
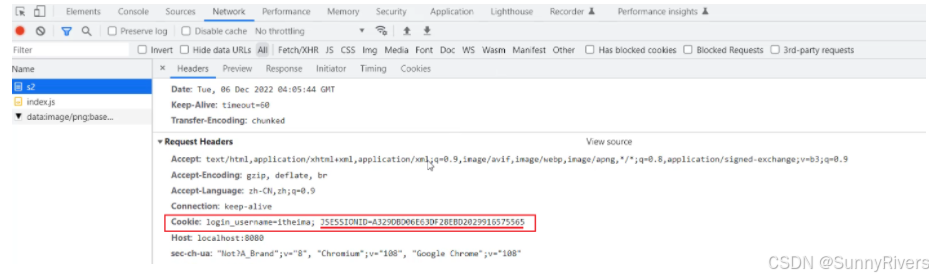
接下来,在后续的每次请求时,都会将cookie的值,携带到服务端,那服务端呢,接收到cookie之后,会自动的根据jsessionid的值,找到对应的会话对象session。
优缺点
- 优点:session是存储在服务端的,安全
- 缺点:
- 服务器集群环境下无法直接使用session
- 移动端app(android、ios)中无法使用cookie
- 用户可以自己禁用cookie
- cookie不能跨域
ps:session 底层是基于cookie实现的会话跟踪,如果cookie不可用,则该方案,也就失效了。
服务器集群环境为何无法使用session?

首先第一点,我们现在所开发的项目,一般都不会只部署在一台服务器上,因为一台服务器会存在一个很大的问题,就是单点故障。所谓单点故障,指的就是一旦这台服务器挂了,整个应用都没法访问了。
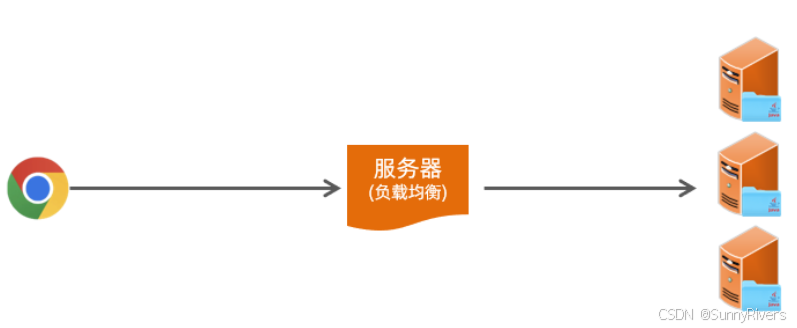
所以在现在的企业项目开发当中,最终部署的时候都是以集群的形式来进行部署,也就是同一个项目它会部署多份。比如这个项目我们现在就部署了 3 份。
而用户在访问的时候,到底访问这三台其中的哪一台?其实用户在访问的时候,他会访问一台前置的服务器,我们叫负载均衡服务器,我们在后面项目当中会详细讲解。目前大家先有一个印象负载均衡服务器,它的作用就是将前端发起的请求均匀的分发给后面的这三台服务器。
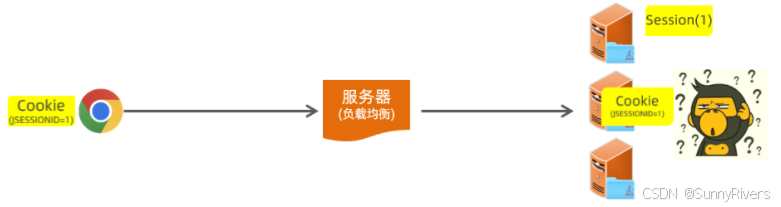
此时假如我们通过 session 来进行会话跟踪,可能就会存在这样一个问题。用户打开浏览器要进行登录操作,此时会发起登录请求。登录请求到达负载均衡服务器,将这个请求转给了第一台 tomcat 服务器。
tomcat 服务器接收到请求之后,要获取到会话对象session。获取到会话对象 session 之后,要给浏览器响应数据,最终在给浏览器响应数据的时候,就会携带这么一个 cookie 的名字,就是 jsessionid ,下一次再请求的时候,是不是又会将 cookie 携带到服务端?
好。此时假如又执行了一次查询操作,要查询部门的数据。这次请求到达负载均衡服务器之后,负载均衡服务器将这次请求转给了第二台 tomcat 服务器,此时他就要到第二台 tomcat 服务器当中。根据jsessionid 也就是对应的 session 的 id 值,要找对应的 session 会话对象。
我想请问在第二台服务器当中有没有这个id的会话对象 session, 是没有的。此时是不是就出现问题了?我同一个浏览器发起了 2 次请求,结果获取到的不是同一个会话对象,这就是session这种会话跟踪方案它的缺点,在服务器集群环境下无法直接使用session。
大家会看到上面这两种传统的会话技术,在现在的企业开发当中是不是会存在很多的问题。 为了解决这些问题,在现在的企业开发当中,基本上都会采用第三种方案,通过令牌技术来进行会话跟踪。接下来我们就来介绍一下令牌技术,来看一下令牌技术又是如何跟踪会话的。
会话跟踪技术三:令牌技术
这里我们所提到的令牌,其实它就是一个用户身份的标识,看似很高大上,很神秘,其实本质就是一个字符串。

如果通过令牌技术来跟踪会话,我们就可以在浏览器发起请求。在请求登录接口的时候,如果登录成功,我就可以生成一个令牌,令牌就是用户的合法身份凭证。接下来我在响应数据的时候,我就可以直接将令牌响应给前端。
接下来我们在前端程序当中接收到令牌之后,就需要将这个令牌存储起来。这个存储可以存储在 cookie 当中,也可以存储在其他的存储空间(比如:localstorage)当中。
接下来,在后续的每一次请求当中,都需要将令牌携带到服务端。携带到服务端之后,接下来我们就需要来校验令牌的有效性。如果令牌是有效的,就说明用户已经执行了登录操作,如果令牌是无效的,就说明用户之前并未执行登录操作。
此时,如果是在同一次会话的多次请求之间,我们想共享数据,我们就可以将共享的数据存储在令牌当中就可以了。
优缺点
- 优点:
- 支持pc端、移动端
- 解决集群环境下的认证问题
- 减轻服务器的存储压力(无需在服务器端存储)
- 缺点:需要自己实现(包括令牌的生成、令牌的传递、令牌的校验)
针对于这三种方案,现在企业开发当中使用的最多的就是第三种令牌技术进行会话跟踪。而前面的这两种传统的方案,现在企业项目开发当中已经很少使用了。所以在我们的课程当中,我们也将会采用令牌技术来解决案例项目当中的会话跟踪问题。
详解jwt令牌 介绍
jwt全称:json web token (官网:https://jwt.io/)
- 定义了一种简洁的、自包含的格式,用于在通信双方以json数据格式安全的传输信息。由于数字签名的存在,这些信息是可靠的。
简洁:是指jwt就是一个简单的字符串。可以在请求参数或者是请求头当中直接传递。
自包含:指的是jwt令牌,看似是一个随机的字符串,但是我们是可以根据自身的需求在jwt令牌中存储自定义的数据内容。如:可以直接在jwt令牌中存储用户的相关信息。
简单来讲,jwt就是将原始的json数据格式进行了安全的封装,这样就可以直接基于jwt在通信双方安全的进行信息传输了。
jwt的组成: (jwt令牌由三个部分组成,三个部分之间使用英文的点来分割)
- 第一部分:header(头), 记录令牌类型、签名算法等。 例如:{“alg”:“hs256”,“type”:“jwt”}
- 第二部分:payload(有效载荷),携带一些自定义信息、默认信息等。 例如:{“id”:“1”,“username”:“tom”}
- 第三部分:signature(签名),防止token被篡改、确保安全性。将header、payload,并加入指定秘钥,通过指定签名算法计算而来。
签名的目的就是为了防jwt令牌被篡改,而正是因为jwt令牌最后一个部分数字签名的存在,所以整个jwt 令牌是非常安全可靠的。一旦jwt令牌当中任何一个部分、任何一个字符被篡改了,整个令牌在校验的时候都会失败,所以它是非常安全可靠的。

jwt是如何将原始的json格式数据,转变为字符串的呢?
其实在生成jwt令牌时,会对json格式的数据进行一次编码:进行base64编码
base64:是一种基于64个可打印的字符来表示二进制数据的编码方式。既然能编码,那也就意味着也能解码。所使用的64个字符分别是a到z、a到z、 0- 9,一个加号,一个斜杠,加起来就是64个字符。任何数据经过base64编码之后,最终就会通过这64个字符来表示。当然还有一个符号,那就是等号。等号它是一个补位的符号
需要注意的是base64是编码方式,而不是加密方式。

jwt令牌最典型的应用场景就是登录认证:
- 在浏览器发起请求来执行登录操作,此时会访问登录的接口,如果登录成功之后,我们需要生成一个jwt令牌,将生成的 jwt令牌返回给前端。
- 前端拿到jwt令牌之后,会将jwt令牌存储起来。在后续的每一次请求中都会将jwt令牌携带到服务端。
- 服务端统一拦截请求之后,先来判断一下这次请求有没有把令牌带过来,如果没有带过来,直接拒绝访问,如果带过来了,还要校验一下令牌是否是有效。如果有效,就直接放行进行请求的处理。
在jwt登录认证的场景中我们发现,整个流程当中涉及到两步操作:
- 在登录成功之后,要生成令牌。
- 每一次请求当中,要接收令牌并对令牌进行校验。
稍后我们再来学习如何来生成jwt令牌,以及如何来校验jwt令牌。
生成和校验
简单介绍了jwt令牌以及jwt令牌的组成之后,接下来我们就来学习基于java代码如何生成和校验jwt令牌。
首先我们先来实现jwt令牌的生成。要想使用jwt令牌,需要先引入jwt的依赖:
<!-- jwt依赖-->
<dependency>
<groupid>io.jsonwebtoken</groupid>
<artifactid>jjwt</artifactid>
<version>0.9.1</version>
</dependency>在引入完jwt来赖后,就可以调用工具包中提供的api来完成jwt令牌的生成和校验
工具类:jwts
生成jwt代码实现:
@test
public void genjwt(){
map<string,object> claims = new hashmap<>();
claims.put("id",1);
claims.put("username","tom");
string jwt = jwts.builder()
.setclaims(claims) //自定义内容(载荷)
.signwith(signaturealgorithm.hs256, "xc") //签名算法
.setexpiration(new date(system.currenttimemillis() + 24*3600*1000)) //有效期
.compact();
system.out.println(jwt);
}运行测试方法:
eyjhbgcioijiuzi1nij9.eyjpzci6mswizxhwijoxnjcynzi5nzmwfq.fhi0ub8npbyt71uqlxddlyipptlgxbug_msugjtxtbk
输出的结果就是生成的jwt令牌,,通过英文的点分割对三个部分进行分割,我们可以将生成的令牌复制一下,然后打开jwt的官网,将生成的令牌直接放在encoded位置,此时就会自动的将令牌解析出来。
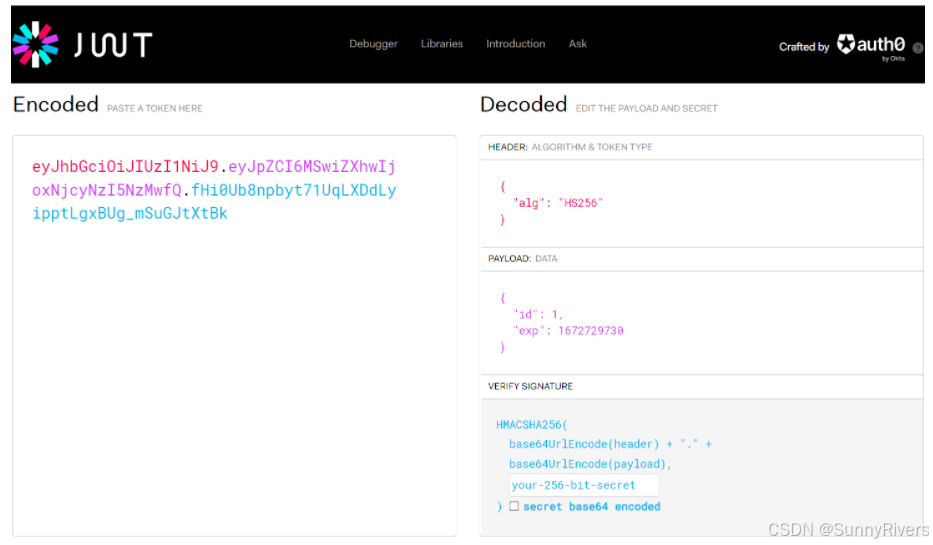
第一部分解析出来,看到json格式的原始数据,所使用的签名算法为hs256。
第二个部分是我们自定义的数据,之前我们自定义的数据就是id,还有一个exp代表的是我们所设置的过期时间。
由于前两个部分是base64编码,所以是可以直接解码出来。但最后一个部分并不是base64编码,是经过签名算法计算出来的,所以最后一个部分是不会解析的。
实现了jwt令牌的生成,下面我们接着使用java代码来校验jwt令牌(解析生成的令牌):
@test
public void parsejwt(){
claims claims = jwts.parser()
.setsigningkey("xc")//指定签名密钥(必须保证和生成令牌时使用相同的签名密钥)
.parseclaimsjws("eyjhbgcioijiuzi1nij9.eyjpzci6mswizxhwijoxnjcynzi5nzmwfq.fhi0ub8npbyt71uqlxddlyipptlgxbug_msugjtxtbk")
.getbody();
system.out.println(claims);
}运行测试方法:
{id=1, exp=1672729730}
令牌解析后,我们可以看到id和过期时间,如果在解析的过程当中没有报错,就说明解析成功了。
下面我们做一个测试:把令牌header中的数字9变为8,运行测试方法后发现报错:
原header: eyjhbgcioijiuzi1nij9
修改为: eyjhbgcioijiuzi1nij8

结论:篡改令牌中的任何一个字符,在对令牌进行解析时都会报错,所以jwt令牌是非常安全可靠的。
我们继续测试:修改生成令牌的时指定的过期时间,修改为1分钟
@test
public void genjwt(){
map<string,object> claims = new hashmap<>();
claims.put(“id”,1);
claims.put(“username”,“tom”);
string jwt = jwts.builder()
.setclaims(claims) //自定义内容(载荷)
.signwith(signaturealgorithm.hs256, “xc”) //签名算法
.setexpiration(new date(system.currenttimemillis() + 60*1000)) //有效期60秒
.compact();
system.out.println(jwt);
//输出结果:eyjhbgcioijiuzi1nij9.eyjpzci6mswizxhwijoxnjczmda5nzu0fq.rcvir65akgiax-id6fjw60elfh3tptkdok7ute4a1ro
}
@test
public void parsejwt(){
claims claims = jwts.parser()
.setsigningkey("xc")//指定签名密钥
.parseclaimsjws("eyjhbgcioijiuzi1nij9.eyjpzci6mswizxhwijoxnjczmda5nzu0fq.rcvir65akgiax-id6fjw60elfh3tptkdok7ute4a1ro")
.getbody();
system.out.println(claims);
}等待1分钟之后运行测试方法发现也报错了,说明:jwt令牌过期后,令牌就失效了,解析的为非法令牌。
通过以上测试,我们在使用jwt令牌时需要注意:
- jwt校验时使用的签名秘钥,必须和生成jwt令牌时使用的秘钥是配套的。
- 如果jwt令牌解析校验时报错,则说明 jwt令牌被篡改 或 失效了,令牌非法。
登录下发令牌
jwt令牌的生成和校验的基本操作我们已经学习完了,接下来我们就需要在案例当中通过jwt令牌技术来跟踪会话。具体的思路我们前面已经分析过了,主要就是两步操作:
- 生成令牌
- 在登录成功之后来生成一个jwt令牌,并且把这个令牌直接返回给前端
- 校验令牌
- 拦截前端请求,从请求中获取到令牌,对令牌进行解析校验
那我们首先来完成:登录成功之后生成jwt令牌,并且把令牌返回给前端。
jwt令牌怎么返回给前端呢?此时我们就需要再来看一下接口文档当中关于登录接口的描述(主要看响应数据):
- 响应数据
参数格式:application/json
参数说明:
| 名称 | 类型 | 是否必须 | 默认值 | 备注 | 其他信息 |
|---|---|---|---|---|---|
| code | number | 必须 | 响应码, 1 成功 ; 0 失败 | ||
| msg | string | 非必须 | 提示信息 | ||
| data | string | 必须 | 返回的数据 , jwt令牌 |
响应数据样例:
{
"code": 1,
"msg": "success",
"data": "eyjhbgcioijiuzi1nij9.eyjuyw1lijoi6yer5bq4iiwiawqiojesinvzzxjuyw1lijoiamluew9uzyisimv4cci6mty2mjiwnza0oh0.kkuc_cxjzj8dd063eimx4h9ojfrr6xmj-yvzawcvzco"
}备注说明
用户登录成功后,系统会自动下发jwt令牌,然后在后续的每次请求中,都需要在请求头header中携带到服务端,请求头的名称为 token ,值为 登录时下发的jwt令牌。
如果检测到用户未登录,则会返回如下固定错误信息:
{
"code": 0,
"msg": "not_login",
"data": null
}解读完接口文档中的描述了,目前我们先来完成令牌的生成和令牌的下发,我们只需要生成一个令牌返回给前端就可以了。
实现步骤:
- 引入jwt工具类
- 在项目工程下创建com.example.utils包,并把提供jwt工具类复制到该包下
- 登录完成后,调用工具类生成jwt令牌并返回
jwt工具类
public class jwtutils {
private static string signkey = "xc";//签名密钥
private static long expire = 43200000l; //有效时间
/**
* 生成jwt令牌
* @param claims jwt第二部分负载 payload 中存储的内容
* @return
*/
public static string generatejwt(map<string, object> claims){
string jwt = jwts.builder()
.addclaims(claims)//自定义信息(有效载荷)
.signwith(signaturealgorithm.hs256, signkey)//签名算法(头部)
.setexpiration(new date(system.currenttimemillis() + expire))//过期时间
.compact();
return jwt;
}
/**
* 解析jwt令牌
* @param jwt jwt令牌
* @return jwt第二部分负载 payload 中存储的内容
*/
public static claims parsejwt(string jwt){
claims claims = jwts.parser()
.setsigningkey(signkey)//指定签名密钥
.parseclaimsjws(jwt)//指定令牌token
.getbody();
return claims;
}
}登录成功,生成jwt令牌并返回
@restcontroller
@slf4j
public class logincontroller {
//依赖业务层对象
@autowired
private empservice empservice;
@postmapping("/login")
public result login(@requestbody emp emp) {
//调用业务层:登录功能
emp loginemp = empservice.login(emp);
//判断:登录用户是否存在
if(loginemp !=null ){
//自定义信息
map<string , object> claims = new hashmap<>();
claims.put("id", loginemp.getid());
claims.put("username",loginemp.getusername());
claims.put("name",loginemp.getname());
//使用jwt工具类,生成身份令牌
string token = jwtutils.generatejwt(claims);
return result.success(token);
}
return result.error("用户名或密码错误");
}
}服务器响应的jwt令牌存储在本地浏览器哪里了呢?
在当前案例中,jwt令牌存储在浏览器的本地存储空间local storage中了。 local storage是浏览器的本地存储,在移动端也是支持的。
过滤器filter
刚才通过浏览器的开发者工具,我们可以看到在后续的请求当中,都会在请求头中携带jwt令牌到服务端,而服务端需要统一拦截所有的请求,从而判断是否携带的有合法的jwt令牌。
那怎么样来统一拦截到所有的请求校验令牌的有效性呢?这里我们会学习两种解决方案:
- filter过滤器
- interceptor拦截器
我们首先来学习过滤器filter。
快速入门
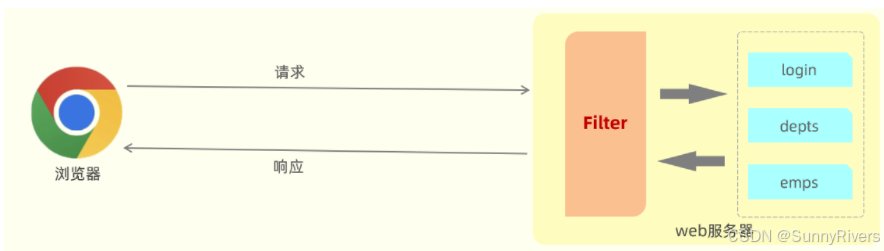
什么是filter?
- filter表示过滤器,是 javaweb三大组件(servlet、filter、listener)之一。
- 过滤器可以把对资源的请求拦截下来,从而实现一些特殊的功能
- 使用了过滤器之后,要想访问web服务器上的资源,必须先经过滤器,过滤器处理完毕之后,才可以访问对应的资源。
- 过滤器一般完成一些通用的操作,比如:登录校验、统一编码处理、敏感字符处理等。
下面我们通过filter快速入门程序掌握过滤器的基本使用操作:
- 第1步,定义过滤器 :1.定义一个类,实现 filter 接口,并重写其所有方法。
- 第2步,配置过滤器:filter类上加 @webfilter 注解,配置拦截资源的路径。引导类上加 @servletcomponentscan 开启servlet组件支持。
定义过滤器
//定义一个类,实现一个标准的filter过滤器的接口
public class demofilter implements filter {
@override //初始化方法, 只调用一次
public void init(filterconfig filterconfig) throws servletexception {
system.out.println("init 初始化方法执行了");
}
@override //拦截到请求之后调用, 调用多次
public void dofilter(servletrequest request, servletresponse response, filterchain chain) throws ioexception, servletexception {
system.out.println("demo 拦截到了请求...放行前逻辑");
//放行
chain.dofilter(request,response);
}
@override //销毁方法, 只调用一次
public void destroy() {
system.out.println("destroy 销毁方法执行了");
}
}- init方法:过滤器的初始化方法。在web服务器启动的时候会自动的创建filter过滤器对象,在创建过滤器对象的时候会自动调用init初始化方法,这个方法只会被调用一次。
- dofilter方法:这个方法是在每一次拦截到请求之后都会被调用,所以这个方法是会被调用多次的,每拦截到一次请求就会调用一次dofilter()方法。
- destroy方法: 是销毁的方法。当我们关闭服务器的时候,它会自动的调用销毁方法destroy,而这个销毁方法也只会被调用一次。
在定义完filter之后,filter其实并不会生效,还需要完成filter的配置,filter的配置非常简单,只需要在filter类上添加一个注解:@webfilter,并指定属性urlpatterns,通过这个属性指定过滤器要拦截哪些请求
@webfilter(urlpatterns = "/*") //配置过滤器要拦截的请求路径( /* 表示拦截浏览器的所有请求 )
public class demofilter implements filter {
@override //初始化方法, 只调用一次
public void init(filterconfig filterconfig) throws servletexception {
system.out.println("init 初始化方法执行了");
}
@override //拦截到请求之后调用, 调用多次
public void dofilter(servletrequest request, servletresponse response, filterchain chain) throws ioexception, servletexception {
system.out.println("demo 拦截到了请求...放行前逻辑");
//放行
chain.dofilter(request,response);
}
@override //销毁方法, 只调用一次
public void destroy() {
system.out.println("destroy 销毁方法执行了");
}
}当我们在filter类上面加了@webfilter注解之后,接下来我们还需要在启动类上面加上一个注解@servletcomponentscan,通过这个@servletcomponentscan注解来开启springboot项目对于servlet组件的支持。
@servletcomponentscan
@springbootapplication
public class webmanagementapplication {
public static void main(string[] args) {
springapplication.run(webmanagementapplication.class, args);
}
}注意事项:
在过滤器filter中,如果不执行放行操作,将无法访问后面的资源。 放行操作:chain.dofilter(request, response);
现在我们已完成了filter过滤器的基本使用,下面我们将学习filter过滤器在使用过程中的一些细节。
filter详解
filter过滤器的快速入门程序我们已经完成了,接下来我们就要详细的介绍一下过滤器filter在使用中的一些细节。主要介绍以下3个方面的细节:
- 过滤器的执行流程
- 过滤器的拦截路径配置
- 过滤器链
执行流程
首先我们先来看下过滤器的执行流程:
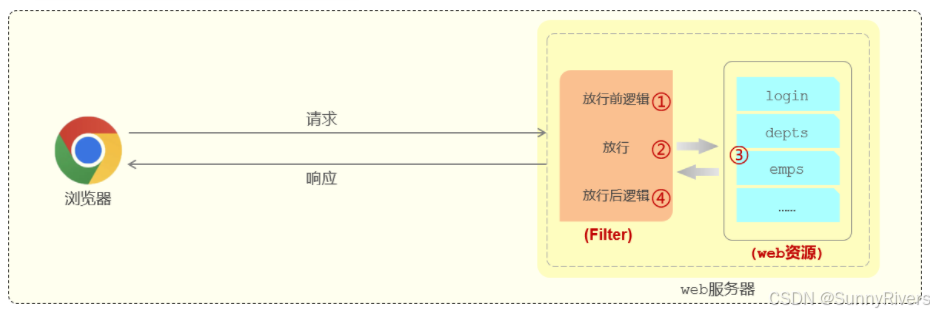
过滤器当中我们拦截到了请求之后,如果希望继续访问后面的web资源,就要执行放行操作,放行就是调用 filterchain对象当中的dofilter()方法,在调用dofilter()这个方法之前所编写的代码属于放行之前的逻辑。
在放行后访问完 web 资源之后还会回到过滤器当中,回到过滤器之后如有需求还可以执行放行之后的逻辑,放行之后的逻辑我们写在dofilter()这行代码之后。
@webfilter(urlpatterns = "/*")
public class demofilter implements filter {
@override //初始化方法, 只调用一次
public void init(filterconfig filterconfig) throws servletexception {
system.out.println("init 初始化方法执行了");
}
@override
public void dofilter(servletrequest servletrequest, servletresponse servletresponse, filterchain filterchain) throws ioexception, servletexception {
system.out.println("demofilter 放行前逻辑.....");
//放行请求
filterchain.dofilter(servletrequest,servletresponse);
system.out.println("demofilter 放行后逻辑.....");
}
@override //销毁方法, 只调用一次
public void destroy() {
system.out.println("destroy 销毁方法执行了");
}
}拦截路径
执行流程我们搞清楚之后,接下来再来介绍一下过滤器的拦截路径,filter可以根据需求,配置不同的拦截资源路径:
| 拦截路径 | urlpatterns值 | 含义 |
|---|---|---|
| 拦截具体路径 | /login | 只有访问 /login 路径时,才会被拦截 |
| 目录拦截 | /emps/* | 访问/emps下的所有资源,都会被拦截 |
| 拦截所有 | /* | 访问所有资源,都会被拦截 |
下面我们来测试"拦截具体路径":
@webfilter(urlpatterns = "/login") //拦截/login具体路径
public class demofilter implements filter {
@override
public void dofilter(servletrequest servletrequest, servletresponse servletresponse, filterchain filterchain) throws ioexception, servletexception {
system.out.println("demofilter 放行前逻辑.....");
//放行请求
filterchain.dofilter(servletrequest,servletresponse);
system.out.println("demofilter 放行后逻辑.....");
}
@override
public void init(filterconfig filterconfig) throws servletexception {
filter.super.init(filterconfig);
}
@override
public void destroy() {
filter.super.destroy();
}
}测试1:访问部门管理请求,发现过滤器没有拦截请求
测试2:访问登录请求/login,发现过滤器拦截请求
下面我们来测试"目录拦截":
@webfilter(urlpatterns = "/depts/*") //拦截所有以/depts开头,后面是什么无所谓
public class demofilter implements filter {
@override
public void dofilter(servletrequest servletrequest, servletresponse servletresponse, filterchain filterchain) throws ioexception, servletexception {
system.out.println("demofilter 放行前逻辑.....");
//放行请求
filterchain.dofilter(servletrequest,servletresponse);
system.out.println("demofilter 放行后逻辑.....");
}
@override
public void init(filterconfig filterconfig) throws servletexception {
filter.super.init(filterconfig);
}
@override
public void destroy() {
filter.super.destroy();
}
}测试1:访问部门管理请求,发现过滤器拦截了请求
测试2:访问登录请求/login,发现过滤器没有拦截请求
过滤器链
最后我们在来介绍下过滤器链,什么是过滤器链呢?所谓过滤器链指的是在一个web应用程序当中,可以配置多个过滤器,多个过滤器就形成了一个过滤器链。

比如:在我们web服务器当中,定义了两个过滤器,这两个过滤器就形成了一个过滤器链。
而这个链上的过滤器在执行的时候会一个一个的执行,会先执行第一个filter,放行之后再来执行第二个filter,如果执行到了最后一个过滤器放行之后,才会访问对应的web资源。
访问完web资源之后,按照我们刚才所介绍的过滤器的执行流程,还会回到过滤器当中来执行过滤器放行后的逻辑,而在执行放行后的逻辑的时候,顺序是反着的。
先要执行过滤器2放行之后的逻辑,再来执行过滤器1放行之后的逻辑,最后在给浏览器响应数据。
以上就是当我们在web应用当中配置了多个过滤器,形成了这样一个过滤器链以及过滤器链的执行顺序。下面我们通过idea来验证下过滤器链。
验证步骤:
- 在filter包下再来新建一个filter过滤器类:abcfilter
- 在abcfilter过滤器中编写放行前和放行后逻辑
- 配置abcfilter过滤器拦截请求路径为:/*
- 重启springboot服务,查看demofilter、abcfilter的执行日志
abcfilter过滤器
@webfilter(urlpatterns = "/*")
public class abcfilter implements filter {
@override
public void dofilter(servletrequest request, servletresponse response, filterchain chain) throws ioexception, servletexception {
system.out.println("abc 拦截到了请求... 放行前逻辑");
//放行
chain.dofilter(request,response);
system.out.println("abc 拦截到了请求... 放行后逻辑");
}
}demofilter过滤器
@webfilter(urlpatterns = "/*")
public class demofilter implements filter {
@override
public void dofilter(servletrequest servletrequest, servletresponse servletresponse, filterchain filterchain) throws ioexception, servletexception {
system.out.println("demofilter 放行前逻辑.....");
//放行请求
filterchain.dofilter(servletrequest,servletresponse);
system.out.println("demofilter 放行后逻辑.....");
}
}打开浏览器访问登录接口:
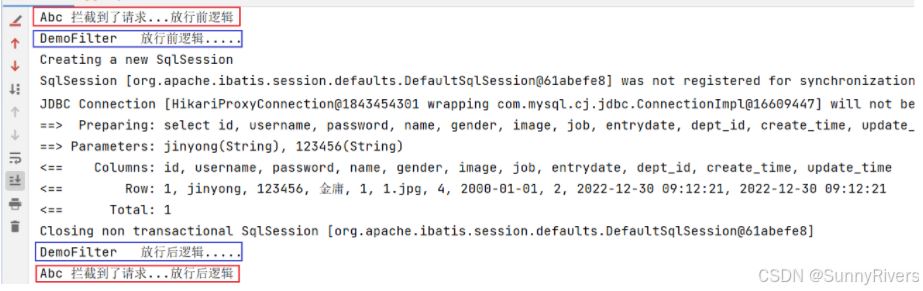
通过控制台日志的输出,大家发现abcfilter先执行demofilter后执行,这是为什么呢?
其实是和过滤器的类名有关系。以注解方式配置的filter过滤器,它的执行优先级是按时过滤器类名的自动排序确定的,类名排名越靠前,优先级越高。
假如我们想让demofilter先执行,怎么办呢?答案就是修改类名。
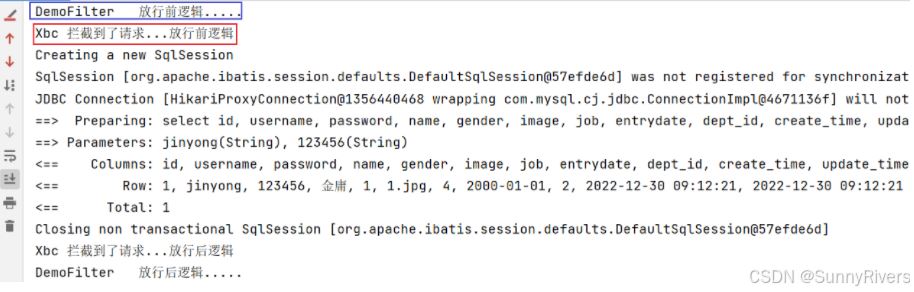
测试:修改abcfilter类名为xbcfilter,运行程序查看控制台日志
@webfilter(urlpatterns = "/*")
public class xbcfilter implements filter {
@override
public void dofilter(servletrequest request, servletresponse response, filterchain chain) throws ioexception, servletexception {
system.out.println("xbc 拦截到了请求...放行前逻辑");
//放行
chain.dofilter(request,response);
system.out.println("xbc 拦截到了请求...放行后逻辑");
}
}
到此,关于过滤器的使用细节,我们已经全部介绍完毕了。
登录校验-filter 分析
过滤器filter的快速入门以及使用细节我们已经介绍完了,接下来最后一步,我们需要使用过滤器filter来完成案例当中的登录校验功能。
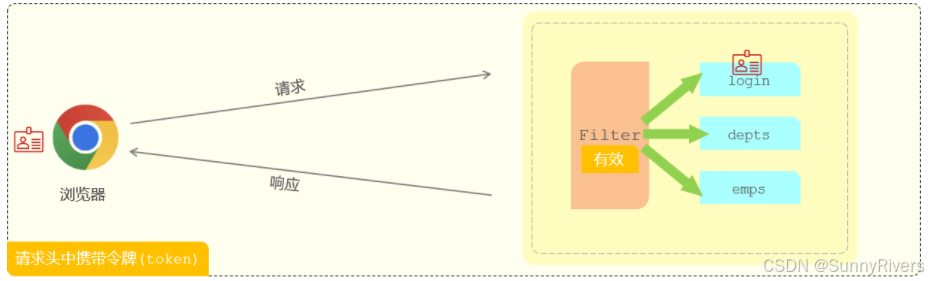
我们先来回顾下前面分析过的登录校验的基本流程:
- 要进入到后台管理系统,我们必须先完成登录操作,此时就需要访问登录接口login。
- 登录成功之后,我们会在服务端生成一个jwt令牌,并且把jwt令牌返回给前端,前端会将jwt令牌存储下来。
- 在后续的每一次请求当中,都会将jwt令牌携带到服务端,请求到达服务端之后,要想去访问对应的业务功能,此时我们必须先要校验令牌的有效性。
- 对于校验令牌的这一块操作,我们使用登录校验的过滤器,在过滤器当中来校验令牌的有效性。如果令牌是无效的,就响应一个错误的信息,也不会再去放行访问对应的资源了。如果令牌存在,并且它是有效的,此时就会放行去访问对应的web资源,执行相应的业务操作。
大概清楚了在filter过滤器的实现步骤了,那在正式开发登录校验过滤器之前,我们思考两个问题:
- 所有的请求,拦截到了之后,都需要校验令牌吗?
- 答案:登录请求例外
- 拦截到请求后,什么情况下才可以放行,执行业务操作?
- 答案:**有令牌,且令牌校验通过(合法);否则都返回未登录错误结果
具体流程
我们要完成登录校验,主要是利用filter过滤器实现,而filter过滤器的流程步骤:

基于上面的业务流程,我们分析出具体的操作步骤:
- 获取请求url
- 判断请求url中是否包含login,如果包含,说明是登录操作,放行
- 获取请求头中的令牌(token)
- 判断令牌是否存在,如果不存在,返回错误结果(未登录)
- 解析token,如果解析失败,返回错误结果(未登录)
- 放行
代码实现
分析清楚了以上的问题后,我们就参照接口文档来开发登录功能了,登录接口描述如下:
基本信息
请求路径:/login 请求方式:post 接口描述:该接口用于员工登录tlias智能学习辅助系统,登录完毕后,系统下发jwt令牌。
请求参数
参数格式:application/json
参数说明:
| 名称 | 类型 | 是否必须 | 备注 |
|---|---|---|---|
| username | string | 必须 | 用户名 |
| password | string | 必须 | 密码 |
请求数据样例:
{
"username": "jinyong",
"password": "123456"
}响应数据
参数格式:application/json
参数说明:
| 名称 | 类型 | 是否必须 | 默认值 | 备注 | 其他信息 |
|---|---|---|---|---|---|
| code | number | 必须 | 响应码, 1 成功 ; 0 失败 | ||
| msg | string | 非必须 | 提示信息 | ||
| data | string | 必须 | 返回的数据 , jwt令牌 |
响应数据样例:
{
"code": 1,
"msg": "success",
"data": "eyjhbgcioijiuzi1nij9.eyjuyw1lijoi6yer5bq4iiwiawqiojesinvzzxjuyw1lijoiamluew9uzyisimv4cci6mty2mjiwnza0oh0.kkuc_cxjzj8dd063eimx4h9ojfrr6xmj-yvzawcvzco"
}备注说明
用户登录成功后,系统会自动下发jwt令牌,然后在后续的每次请求中,都需要在请求头header中携带到服务端,请求头的名称为 token ,值为 登录时下发的jwt令牌。
如果检测到用户未登录,则会返回如下固定错误信息:
{
"code": 0,
"msg": "not_login",
"data": null
}登录校验过滤器:logincheckfilter
@slf4j
@webfilter(urlpatterns = "/*") //拦截所有请求
public class logincheckfilter implements filter {
@override
public void dofilter(servletrequest servletrequest, servletresponse servletresponse, filterchain chain) throws ioexception, servletexception {
//前置:强制转换为http协议的请求对象、响应对象 (转换原因:要使用子类中特有方法)
httpservletrequest request = (httpservletrequest) servletrequest;
httpservletresponse response = (httpservletresponse) servletresponse;
//1.获取请求url
string url = request.getrequesturl().tostring();
log.info("请求路径:{}", url); //请求路径:http://localhost:8080/login
//2.判断请求url中是否包含login,如果包含,说明是登录操作,放行
if(url.contains("/login")){
chain.dofilter(request, response);//放行请求
return;//结束当前方法的执行
}
//3.获取请求头中的令牌(token)
string token = request.getheader("token");
log.info("从请求头中获取的令牌:{}",token);
//4.判断令牌是否存在,如果不存在,返回错误结果(未登录)
if(!stringutils.haslength(token)){
log.info("token不存在");
result responseresult = result.error("not_login");
//把result对象转换为json格式字符串 (fastjson是阿里巴巴提供的用于实现对象和json的转换工具类)
string json = jsonobject.tojsonstring(responseresult);
response.setcontenttype("application/json;charset=utf-8");
//响应
response.getwriter().write(json);
return;
}
//5.解析token,如果解析失败,返回错误结果(未登录)
try {
jwtutils.parsejwt(token);
}catch (exception e){
log.info("令牌解析失败!");
result responseresult = result.error("not_login");
//把result对象转换为json格式字符串 (fastjson是阿里巴巴提供的用于实现对象和json的转换工具类)
string json = jsonobject.tojsonstring(responseresult);
response.setcontenttype("application/json;charset=utf-8");
//响应
response.getwriter().write(json);
return;
}
//6.放行
chain.dofilter(request, response);
}
}在上述过滤器的功能实现中,我们使用到了一个第三方json处理的工具包fastjson。我们要想使用,需要引入如下依赖:
<dependency>
<groupid>com.alibaba</groupid>
<artifactid>fastjson</artifactid>
<version>1.2.76</version>
</dependency>拦截器interceptor
学习完了过滤器filter之后,接下来我们继续学习拦截器interseptor。
拦截器我们主要分为三个方面进行讲解:
- 介绍下什么是拦截器,并通过快速入门程序上手拦截器
- 拦截器的使用细节
- 通过拦截器interceptor完成登录校验功能
我们先学习第一块内容:拦截器快速入门
快速入门
- 什么是拦截器?
- 是一种动态拦截方法调用的机制,类似于过滤器。拦截器是spring框架中提供的,用来动态拦截控制器方法的执行。
拦截器的作用:
- 拦截请求,在指定方法调用前后,根据业务需要执行预先设定的代码。
在拦截器当中,我们通常也是做一些通用性的操作,比如:我们可以通过拦截器来拦截前端发起的请求,将登录校验的逻辑全部编写在拦截器当中。在校验的过程当中,如发现用户登录了(携带jwt令牌且是合法令牌),就可以直接放行,去访问spring当中的资源。如果校验时发现并没有登录或是非法令牌,就可以直接给前端响应未登录的错误信息。
下面我们通过快速入门程序,来学习下拦截器的基本使用。拦截器的使用步骤和过滤器类似,也分为两步:
- 定义拦截器
- 注册配置拦截器
自定义拦截器:实现handlerinterceptor接口,并重写其所有方法
//自定义拦截器
@component
public class logincheckinterceptor implements handlerinterceptor {
//目标资源方法执行前执行。 返回true:放行 返回false:不放行
@override
public boolean prehandle(httpservletrequest request, httpservletresponse response, object handler) throws exception {
system.out.println("prehandle .... ");
return true; //true表示放行
}
//目标资源方法执行后执行
@override
public void posthandle(httpservletrequest request, httpservletresponse response, object handler, modelandview modelandview) throws exception {
system.out.println("posthandle ... ");
}
//视图渲染完毕后执行,最后执行
@override
public void aftercompletion(httpservletrequest request, httpservletresponse response, object handler, exception ex) throws exception {
system.out.println("aftercompletion .... ");
}
}注意:
prehandle方法:目标资源方法执行前执行。 返回true:放行 返回false:不放行
posthandle方法:目标资源方法执行后执行
aftercompletion方法:视图渲染完毕后执行,最后执行
注册配置拦截器:实现webmvcconfigurer接口,并重写addinterceptors方法
@configuration
public class webconfig implements webmvcconfigurer {
//自定义的拦截器对象
@autowired
private logincheckinterceptor logincheckinterceptor;
@override
public void addinterceptors(interceptorregistry registry) {
//注册自定义拦截器对象
registry.addinterceptor(logincheckinterceptor).addpathpatterns("/**");//设置拦截器拦截的请求路径( /** 表示拦截所有请求)
}
}interceptor详解
拦截器的入门程序完成之后,接下来我们来介绍拦截器的使用细节。拦截器的使用细节我们主要介绍两个部分:
- 拦截器的拦截路径配置
- 拦截器的执行流程
拦截路径
首先我们先来看拦截器的拦截路径的配置,在注册配置拦截器的时候,我们要指定拦截器的拦截路径,通过addpathpatterns("要拦截路径")方法,就可以指定要拦截哪些资源。
在入门程序中我们配置的是/**,表示拦截所有资源,而在配置拦截器时,不仅可以指定要拦截哪些资源,还可以指定不拦截哪些资源,只需要调用excludepathpatterns("不拦截路径")方法,指定哪些资源不需要拦截。
@configuration
public class webconfig implements webmvcconfigurer {
//拦截器对象
@autowired
private logincheckinterceptor logincheckinterceptor;
@override
public void addinterceptors(interceptorregistry registry) {
//注册自定义拦截器对象
registry.addinterceptor(logincheckinterceptor)
.addpathpatterns("/**")//设置拦截器拦截的请求路径( /** 表示拦截所有请求)
.excludepathpatterns("/login");//设置不拦截的请求路径
}
}在拦截器中除了可以设置/**拦截所有资源外,还有一些常见拦截路径设置:
| 拦截路径 | 含义 | 举例 |
|---|---|---|
| /* | 一级路径 | 能匹配/depts,/emps,/login,不能匹配 /depts/1 |
| /** | 任意级路径 | 能匹配/depts,/depts/1,/depts/1/2 |
| /depts/* | /depts下的一级路径 | 能匹配/depts/1,不能匹配/depts/1/2,/depts |
| /depts/** | /depts下的任意级路径 | 能匹配/depts,/depts/1,/depts/1/2,不能匹配/emps/1 |
下面主要来演示下/**与/*的区别:
- 修改拦截器配置,把拦截路径设置为
/*
@configuration
public class webconfig implements webmvcconfigurer {
//拦截器对象
@autowired
private logincheckinterceptor logincheckinterceptor;
@override
public void addinterceptors(interceptorregistry registry) {
//注册自定义拦截器对象
registry.addinterceptor(logincheckinterceptor)
.addpathpatterns("/*")
.excludepathpatterns("/login");//设置不拦截的请求路径
}
}执行流程
介绍完拦截路径的配置之后,接下来我们再来介绍拦截器的执行流程。通过执行流程,大家就能够清晰的知道过滤器与拦截器的执行时机。
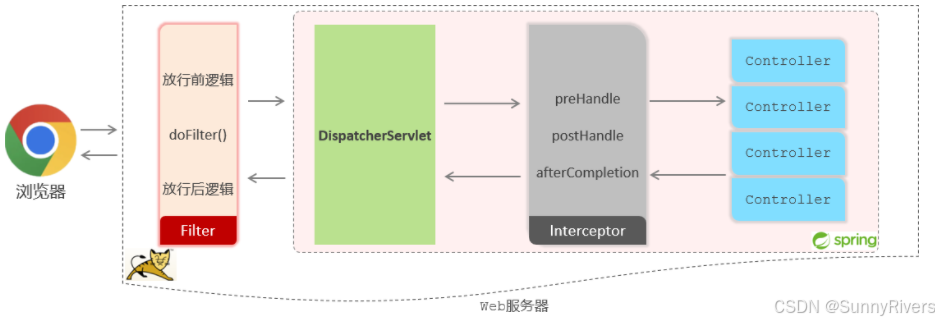
- 当我们打开浏览器来访问部署在web服务器当中的web应用时,此时我们所定义的过滤器会拦截到这次请求。拦截到这次请求之后,它会先执行放行前的逻辑,然后再执行放行操作。而由于我们当前是基于springboot开发的,所以放行之后是进入到了spring的环境当中,也就是要来访问我们所定义的controller当中的接口方法。
- tomcat并不识别所编写的controller程序,但是它识别servlet程序,所以在spring的web环境中提供了一个非常核心的servlet:dispatcherservlet(前端控制器),所有请求都会先进行到dispatcherservlet,再将请求转给controller。
- 当我们定义了拦截器后,会在执行controller的方法之前,请求被拦截器拦截住。执行
prehandle()方法,这个方法执行完成后需要返回一个布尔类型的值,如果返回true,就表示放行本次操作,才会继续访问controller中的方法;如果返回false,则不会放行(controller中的方法也不会执行)。 - 在controller当中的方法执行完毕之后,再回过来执行
posthandle()这个方法以及aftercompletion()方法,然后再返回给dispatcherservlet,最终再来执行过滤器当中放行后的这一部分逻辑的逻辑。执行完毕之后,最终给浏览器响应数据。
接下来我们就来演示下过滤器和拦截器同时存在的执行流程:
- 开启logincheckinterceptor拦截器
@component
public class logincheckinterceptor implements handlerinterceptor {
@override
public boolean prehandle(httpservletrequest request, httpservletresponse response, object handler) throws exception {
system.out.println("prehandle .... ");
return true; //true表示放行
}
@override
public void posthandle(httpservletrequest request, httpservletresponse response, object handler, modelandview modelandview) throws exception {
system.out.println("posthandle ... ");
}
@override
public void aftercompletion(httpservletrequest request, httpservletresponse response, object handler, exception ex) throws exception {
system.out.println("aftercompletion .... ");
}
}@configuration
public class webconfig implements webmvcconfigurer {
//拦截器对象
@autowired
private logincheckinterceptor logincheckinterceptor;
@override
public void addinterceptors(interceptorregistry registry) {
//注册自定义拦截器对象
registry.addinterceptor(logincheckinterceptor)
.addpathpatterns("/**")//拦截所有请求
.excludepathpatterns("/login");//不拦截登录请求
}
}开启demofilter过滤器
@webfilter(urlpatterns = "/*")
public class demofilter implements filter {
@override
public void dofilter(servletrequest servletrequest, servletresponse servletresponse, filterchain filterchain) throws ioexception, servletexception {
system.out.println("demofilter 放行前逻辑.....");
//放行请求
filterchain.dofilter(servletrequest,servletresponse);
system.out.println("demofilter 放行后逻辑.....");
}
}以上就是拦截器的执行流程。通过执行流程分析,大家应该已经清楚了过滤器和拦截器之间的区别,其实它们之间的区别主要是两点:
- 接口规范不同:过滤器需要实现filter接口,而拦截器需要实现handlerinterceptor接口。
- 拦截范围不同:过滤器filter会拦截所有的资源,而interceptor只会拦截spring环境中的资源。
登录校验- interceptor
讲解完了拦截器的基本操作之后,接下来我们需要完成最后一步操作:通过拦截器来完成案例当中的登录校验功能。
登录校验的业务逻辑以及操作步骤我们前面已经分析过了,和登录校验filter过滤器当中的逻辑是完全一致的。现在我们只需要把这个技术方案由原来的过滤器换成拦截器interceptor就可以了。
登录校验拦截器
//自定义拦截器
@component //当前拦截器对象由spring创建和管理
@slf4j
public class logincheckinterceptor implements handlerinterceptor {
//前置方式
@override
public boolean prehandle(httpservletrequest request, httpservletresponse response, object handler) throws exception {
system.out.println("prehandle .... ");
//1.获取请求url
//2.判断请求url中是否包含login,如果包含,说明是登录操作,放行
//3.获取请求头中的令牌(token)
string token = request.getheader("token");
log.info("从请求头中获取的令牌:{}",token);
//4.判断令牌是否存在,如果不存在,返回错误结果(未登录)
if(!stringutils.haslength(token)){
log.info("token不存在");
//创建响应结果对象
result responseresult = result.error("not_login");
//把result对象转换为json格式字符串 (fastjson是阿里巴巴提供的用于实现对象和json的转换工具类)
string json = jsonobject.tojsonstring(responseresult);
//设置响应头(告知浏览器:响应的数据类型为json、响应的数据编码表为utf-8)
response.setcontenttype("application/json;charset=utf-8");
//响应
response.getwriter().write(json);
return false;//不放行
}
//5.解析token,如果解析失败,返回错误结果(未登录)
try {
jwtutils.parsejwt(token);
}catch (exception e){
log.info("令牌解析失败!");
//创建响应结果对象
result responseresult = result.error("not_login");
//把result对象转换为json格式字符串 (fastjson是阿里巴巴提供的用于实现对象和json的转换工具类)
string json = jsonobject.tojsonstring(responseresult);
//设置响应头
response.setcontenttype("application/json;charset=utf-8");
//响应
response.getwriter().write(json);
return false;
}
//6.放行
return true;
}注册配置拦截器
@configuration
public class webconfig implements webmvcconfigurer {
//拦截器对象
@autowired
private logincheckinterceptor logincheckinterceptor;
@override
public void addinterceptors(interceptorregistry registry) {
//注册自定义拦截器对象
registry.addinterceptor(logincheckinterceptor)
.addpathpatterns("/**")
.excludepathpatterns("/login");
}
}到此这篇关于一文掌握javaweb登录认证的文章就介绍到这了,更多相关javaweb登录认证内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论