
📝个人主页:
🔥系列专栏:
⛺️稳中求进,晒太阳

题目
示例
示例 1:
输入:grid = [ ["1","1","1","1","0"], ["1","1","0","1","0"], ["1","1","0","0","0"], ["0","0","0","0","0"] ] 输出:1
示例 2:
输入:grid = [ ["1","1","0","0","0"], ["1","1","0","0","0"], ["0","0","1","0","0"], ["0","0","0","1","1"] ] 输出:3s
思路
深度优先遍历
dfs 的基本结构
首先,网格结构中的格子有多少相邻结点?答案是上下左右四个。对于格子 (r, c) 来说(r 和 c 分别代表行坐标和列坐标),四个相邻的格子分别是 (r-1, c)、(r+1, c)、(r, c-1)、(r, c+1)。换句话说,网格结构是「四叉」的。
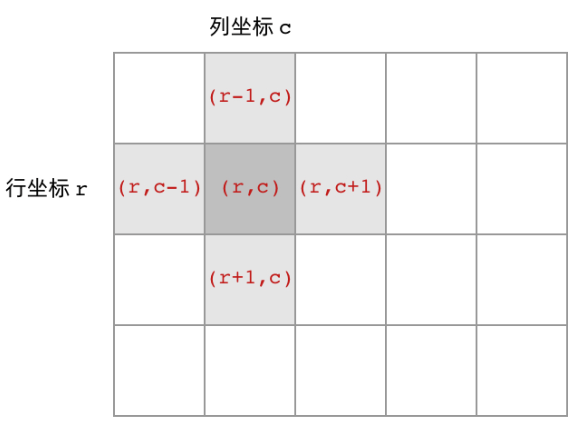
其次,网格 dfs 中的 base case 是什么?应该是网格中不需要继续遍历、grid[r][c] 会出现数组下标越界异常的格子,也就是那些超出网格范围的格子。
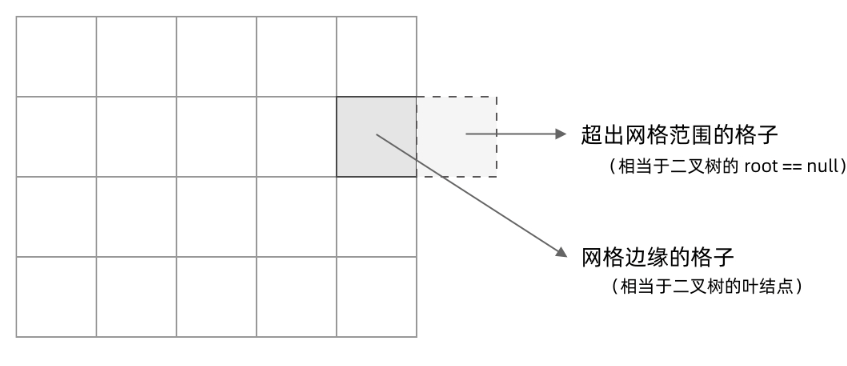
这一点稍微有些反直觉,坐标竟然可以临时超出网格的范围?这种方法我称为「先污染后治理」—— 甭管当前是在哪个格子,先往四个方向走一步再说,如果发现走出了网格范围再赶紧返回。这跟二叉树的遍历方法是一样的,先递归调用,发现 root == null 再返回。
如何避免重复遍历
网格结构的 dfs 与二叉树的 dfs 最大的不同之处在于,遍历中可能遇到遍历过的结点。这是因为,网格结构本质上是一个「图」,我们可以把每个格子看成图中的结点,每个结点有向上下左右的四条边。在图中遍历时,自然可能遇到重复遍历结点。
这时候,dfs 可能会不停地「兜圈子」,永远停不下来。
如何避免这样的重复遍历呢?答案是标记已经遍历过的格子。以岛屿问题为例,我们需要在所有值为 1 的陆地格子上做 dfs 遍历。每走过一个陆地格子,就把格子的值改为 2,这样当我们遇到 2 的时候,就知道这是遍历过的格子了。也就是说,每个格子可能取三个值:
0 —— 海洋格子
1 —— 陆地格子(未遍历过)
2 —— 陆地格子(已遍历过)
代码实现
class solution {
public int numislands(char[][] grid) {
if (grid == null || grid.length == 0) {
return 0;
}
int nr = grid.length;
int nc = grid[0].length;
int num_islands = 0;
for (int r = 0; r < nr; ++r) {
for (int c = 0; c < nc; ++c) {
if (grid[r][c] == '1') {
++num_islands;
dfs(grid, r, c);
}
}
}
return num_islands;
}
void dfs(char[][] grid, int r, int c) {
int nr = grid.length;
int nc = grid[0].length;
if (r < 0 || c < 0 || r >= nr || c >= nc || grid[r][c] == '0') {
return;
}
grid[r][c] = '0';
dfs(grid, r - 1, c);
dfs(grid, r + 1, c);
dfs(grid, r, c - 1);
dfs(grid, r, c + 1);
}
}运行结果



发表评论