因为工作需要在windows平台上对神经网络模型进行部署,前期进行了一些探索和调研,大概总结了一下。
windows平台上部署pytorch模型主要有四种方法:
- 优点:可以直接利用c++的强大功能和性能。对于需要在高性能环境(如游戏、实时图像处理等)中部署模型的场景,这是一个不错的选择。此外,对于那些希望避免使用python的场景(例如,因为python的性能较低或者想要在python之外的环境中使用模型),这可能是一个好的选择。
- 缺点:需要熟悉c++编程,并且在某些情况下,可能需要处理与c++编程相关的复杂问题。
- 优点:onnx是一个开放的模型格式,可以转换几乎任何深度学习框架的模型。我们可以将pytorch模型转换为onnx格式,然后在任何支持onnx的平台上运行。此外,onnx runtime的性能通常优于python解释器,因此对于性能要求较高的场景,这可能是一个更好的选择。
- 缺点:需要将模型转换为onnx格式,这可能会在转换过程中损失一些性能。此外,这个似乎问题比较多,反正我弄了几次是没弄好。
- 优点:使用torchscript可以将pytorch模型转换为可序列化和可执行的代码,使其在没有python解释器的环境中运行。与使用c++ api相比,编写torchscript代码要简单得多。
- 缺点:torchscript可能不会提供与使用c++ api相同的性能优化。此外,如果模型使用了pytorch的某些特性(例如动态计算图),则可能无法直接转换为torchscript。
- 优点:这种方法最简单,只需要在windows平台上运行python代码。此外,由于python api与pytorch紧密集成,因此这种方法通常可以实现最佳的性能和易用性。
- 缺点:如果需要在没有python环境的windows环境中部署模型,那么这种方法就不适用。此外,python的性能可能比c++或c#低,因此在性能要求较高的场景中,这可能不是最佳选择。
在上述四种方法中,基于c++/libtorch的部署方法在性能方面表现最佳,同时也无需依赖python环境。但是,这种方法需要对c++和机器视觉有一定的理解能力。
而今天我们主要讨论第三种方法,即利用torchscript技术和c#实现在windows平台上部署pytorch模型。通过这种方法,我们能够实现独立部署,无需依赖python环境。
主要从以下几个章节进行讨论,根据自己的进度看就行。
目录
1.模型训练
模型训练过程在ubuntu(22.04.3) anaconda(23.1.0) pytorch(1.8.0+cu111)环境下进行。
1.1 环境搭建
- 具体的安装方法如下连接所示,主要部署基于pytorch(1.8.0+cu111)的虚拟环境用于模型的搭建和训练。ubuntu22.04上安装anaconda3-csdn博客
- 同时,需要安装一下自己常用的库,因为做模型的训练,我这里为了方便起见,还需要安装一下timm库。
pip install timm1.2 数据集准备
- 使用imagefolder对数据进行加载
train_dataset = datasets.imagefolder(root=args.trainfolder, transform=data_train_transform)
test_dataset = datasets.imagefolder(root=args.testfolder, transform=data_test_transform)
print(train_dataset.class_to_idx)
train_loader = torch.utils.data.dataloader(train_dataset, batch_size=64, shuffle=true,num_workers=4,drop_last=true,pin_memory=true)
test_loader = torch.utils.data.dataloader(test_dataset, batch_size=64, shuffle=false,num_workers=4,pin_memory=true)- data_train_transform与data_test_transform数据预处理方法为,此处不写正则化,是想着简化后面在c#中的预处理步骤(统一除以255即可)
data_train_transform = transforms.compose([
transforms.randomhorizontalflip(),
transforms.gaussianblur(kernel_size=(5,5),sigma=(0.1,0.3)),
transforms.randomresizedcrop((224,224)),
# transforms.resize((224,224)),
#cutout(),
transforms.totensor(),
# transforms.normalize(mean=[0.49404827, 0.49592876, 0.4070973],
# std=[0.2071776, 0.2007362, 0.21388549])
])
data_test_transform = transforms.compose([
transforms.resize((224,224)),
transforms.totensor(),
# transforms.normalize(mean=[0.5006999, 0.50564367, 0.40601832],
# std=[0.21505603, 0.2077407, 0.2244142])
])1.3 训练过程搭建
- 我们直接使用timm库选择模型结构,因为后面c#选择cpu对模型进行推理,所以选择参数量和计算复杂度低的模型,这块我选择的是mobilevit。
model = timm.create_model('timm/mobilevit_xxs.cvnets_in1k',num_classes=args.num_classes,pretrained=true ,pretrained_cfg_overlay=dict(file='./pytorch_model.bin'))现在timm的模型预训练权重下载基本都得在huggingface[huggingface.co]上下载了。
- 模型训练与评估
for epoch in range(args.epoch):
model.train()
for i, (images, labels) in enumerate(train_loader):
images = images.to(device) / 255.0
labels = labels.to(device)
# 前向传播
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播和优化
loss.backward()
optimizer.step()
if (i + 1) % 10 == 0:
print('epoch [{}/{}], step [{}/{}], loss: {:.4f}'
.format(epoch + 1, args.epoch, i + 1, total_step, loss.item()))
model.eval()
tp = 0
total = 0
with torch.no_grad():
for step, (images, labels) in enumerate(tqdm(test_loader)):
images = images.to(device) / 255.0
labels = labels.to(device)
# 前向传播
outputs = torch.argmax(model(images),dim=1)
tp += outputs.eq(labels).sum().item()
total += images.shape[0]
print("acc is : {:.3f}".format(tp / total))1.4 torchscript模型推理
- 模型转换为torchscript
model.eval()
model.to(torch.device("cpu"))
x = torch.randn(size=(1,3,224,224), requires_grad=true)
net_trace = torch.jit.trace(model,x)
torch.jit.save(net_trace,args.weight_saved_path + 'bct.bin')1.5完整代码
import os
import torch
import shutil
import argparse
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision.models as models
import timm
from torchtoolbox.transform import cutout
from tqdm import tqdm
# 定义数据转换
data_train_transform = transforms.compose([
transforms.randomhorizontalflip(),
transforms.gaussianblur(kernel_size=(5,5),sigma=(0.1,0.3)),
transforms.randomresizedcrop((224,224)),
transforms.totensor(),
])
data_test_transform = transforms.compose([
transforms.resize((224,224)),
transforms.totensor(),
])
parser = argparse.argumentparser()
parser.add_argument("--epoch",default=10,required=false)
parser.add_argument("--lr",default=1e-4,required=false)
parser.add_argument("--num_classes",default=2,required=false)
parser.add_argument("--weight_saved_path",default=r'./weight/',required=false)
parser.add_argument("--trainfolder",default=r'/home/lenovo/deeplearning/forge/train/',required=false)
parser.add_argument("--testfolder",default=r'/home/lenovo/deeplearning/forge/test/',required=false)
args = parser.parse_args()
if(not os.path.exists(args.weight_saved_path)):
os.mkdir(args.weight_saved_path)
if(not (os.path.exists(args.trainfolder) or os.path.exists(args.testfolder))):
raise "dataset folder not exists"
train_dataset = datasets.imagefolder(root=args.trainfolder, transform=data_train_transform)
test_dataset = datasets.imagefolder(root=args.testfolder, transform=data_test_transform)
print(train_dataset.class_to_idx)
train_loader = torch.utils.data.dataloader(train_dataset, batch_size=64, shuffle=true,num_workers=4,drop_last=true,pin_memory=true)
test_loader = torch.utils.data.dataloader(test_dataset, batch_size=64, shuffle=false,num_workers=4,pin_memory=true)
# 加载预训练的 resnet-18 模型并修改最后一个全连接层
model = timm.create_model('timm/mobilevit_xxs.cvnets_in1k',num_classes=args.num_classes,pretrained=true ,pretrained_cfg_overlay=dict(file='./pytorch_model.bin'))
print(model.default_cfg)
# 定义损失函数和优化器
criterion = nn.crossentropyloss() # 修改为交叉熵损失函数
optimizer = optim.adamw(model.parameters(), lr=args.lr)
device = torch.device('cuda')
print(device)
model.to(device)
total_step = len(train_loader)
for epoch in range(args.epoch):
model.train()
for i, (images, labels) in enumerate(train_loader):
images = images.to(device) / 255.0
labels = labels.to(device)
# 前向传播
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播和优化
loss.backward()
optimizer.step()
if (i + 1) % 10 == 0:
print('epoch [{}/{}], step [{}/{}], loss: {:.4f}'
.format(epoch + 1, args.epoch, i + 1, total_step, loss.item()))
model.eval()
tp = 0
total = 0
with torch.no_grad():
for step, (images, labels) in enumerate(tqdm(test_loader)):
images = images.to(device) / 255.0
labels = labels.to(device)
# 前向传播
outputs = torch.argmax(model(images),dim=1)
tp += outputs.eq(labels).sum().item()
total += images.shape[0]
print("acc is : {:.3f}".format(tp / total))
# 保存模型
model.eval()
model.to(torch.device("cpu"))
x = torch.randn(size=(1,3,224,224), requires_grad=true)
net_trace = torch.jit.trace(model,x)
torch.jit.save(net_trace,args.weight_saved_path + 'forge_classification_transformer.bin')
2.模型训练和推理
模型本地化推理
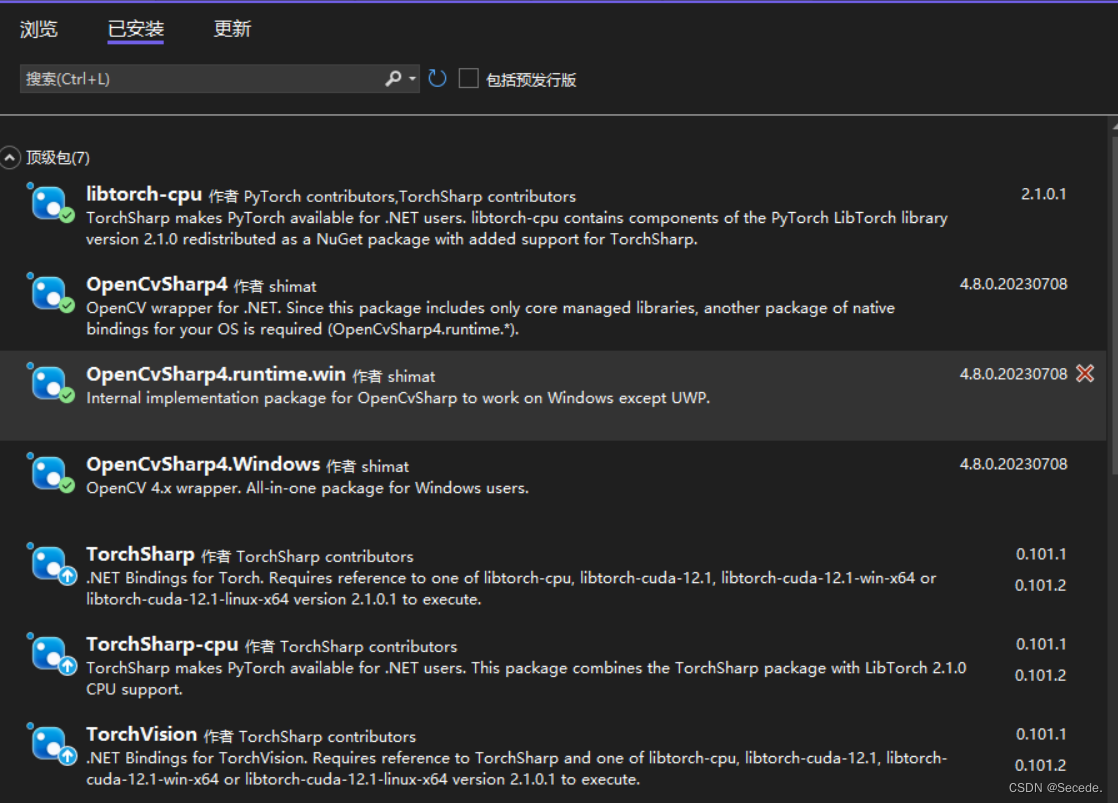
2.1 基础库选择
主要就是得有opencvsharp、torchsharp、libtorch三个主要的库
2.2 模型推理程序
- 数据预处理
using opencvsharp;
using torchsharp;
using static torchsharp.torch;
mat img = cv2.imread(this.targetpath).resize(new opencvsharp.size(224, 224));
img.convertto(img, mattype.cv_8uc3);
var data = img.tobytes();
torchvision.io.skiaimager x = new torchvision.io.skiaimager();
var image_tensor = x.decodeimage(data, torchvision.io.imagereadmode.rgb);
return image_tensor.unsqueeze(0).to(torch.float32) / 255.0f;- 模型加载
using opencvsharp;
using torchsharp;
using static torchsharp.torch;
try
{
net = jit.load(weight,devicetype.cpu);
}
catch (exception ex)
{
messagebox.show(ex.tostring());
}- 模型推理和结果输出
using opencvsharp;
using torchsharp;
using static torchsharp.torch;
net.eval();
var outputs = torch.softmax((torch.tensor)net.forward(temp_tensor),1);
var results = torch.argmax(outputs, 1);
/*
system.diagnostics.trace.writeline(outputs[0][0].item<float>());
...
system.diagnostics.trace.writeline(outputs[0][n].item<float>());
*/
system.diagnostics.trace.writeline(results.item<int64>());
system.diagnostics.trace.writeline(net.getnumberofinputs());2.2 异步线程更新ui
如果说我们的模型计算复杂度较大,那么一但进行推理,就会卡住程序,所以还是推荐异步来更新ui。
private async void infer_click(object sender, eventargs e)
{
this.infer.enabled = false;
this.infer.text = "推理中";
await infer_update();
info_update();
this.infer.text = "推理";
this.infer.enabled = true;
}
private task infer_update()
{
var task = task.run(() =>
{
jr = inf.getresult();
});
return task;
}
private void info_update()
{
this.label5.text = (jr.s1* 100).tostring("0.0") + "%";
this.label6.text = (jr.s2* 100).tostring("0.0") + "%";
this.label7.text = (jr.s3* 100).tostring("0.0") + "%";
this.label8.text = (jr.s4 * 100).tostring("0.0") + "%";
this.label10.text = jr.selected;
}基本就是这些东西了,核心就是先从训练环境把pytorch模型训练下来,然后转换torchscript。
最后加载到c#里面,使用异步线程技术完成模型推理就完事了。


发表评论