
同样使用梯度下降优化算法,去减少损失函数的值,这样去更新逻辑回归前面对应算法的权重参数,提升原本属于1类别的概率,降低原本是0类别的概率
逻辑回归api
sklearn.linear_model.logisticregression(solve='libinear', penalty='12', c= 1.0)
- solver:优化求解方式(默认开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数)
- sag 根据数据集自动选择,随机平均梯度下降
- penalty 正则化的种类
- c 正则化力度
(默认将类别数量少的当做正例)
logisticregression方法相当于sgdclassifier(loss=‘log’,penalty=""),sgdclassifier实现了一个普通的随机梯度下降学习,也支持平均随机梯度下降法(asgd),也可以通过设置average=true,而使用logisticregression(实现了sag)
import pandas as pd
import numpy as np
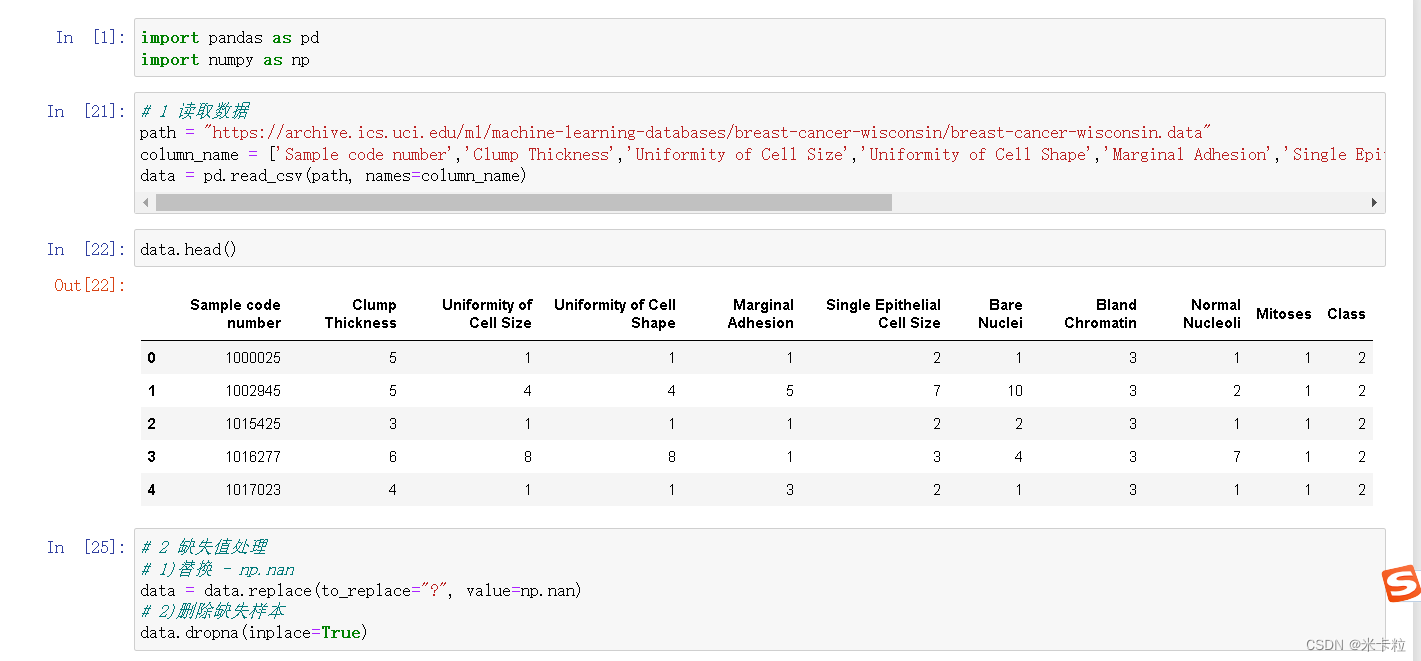
# 1 读取数据
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/"
column_name = [1,2,3,4,5,6,7,8,9]
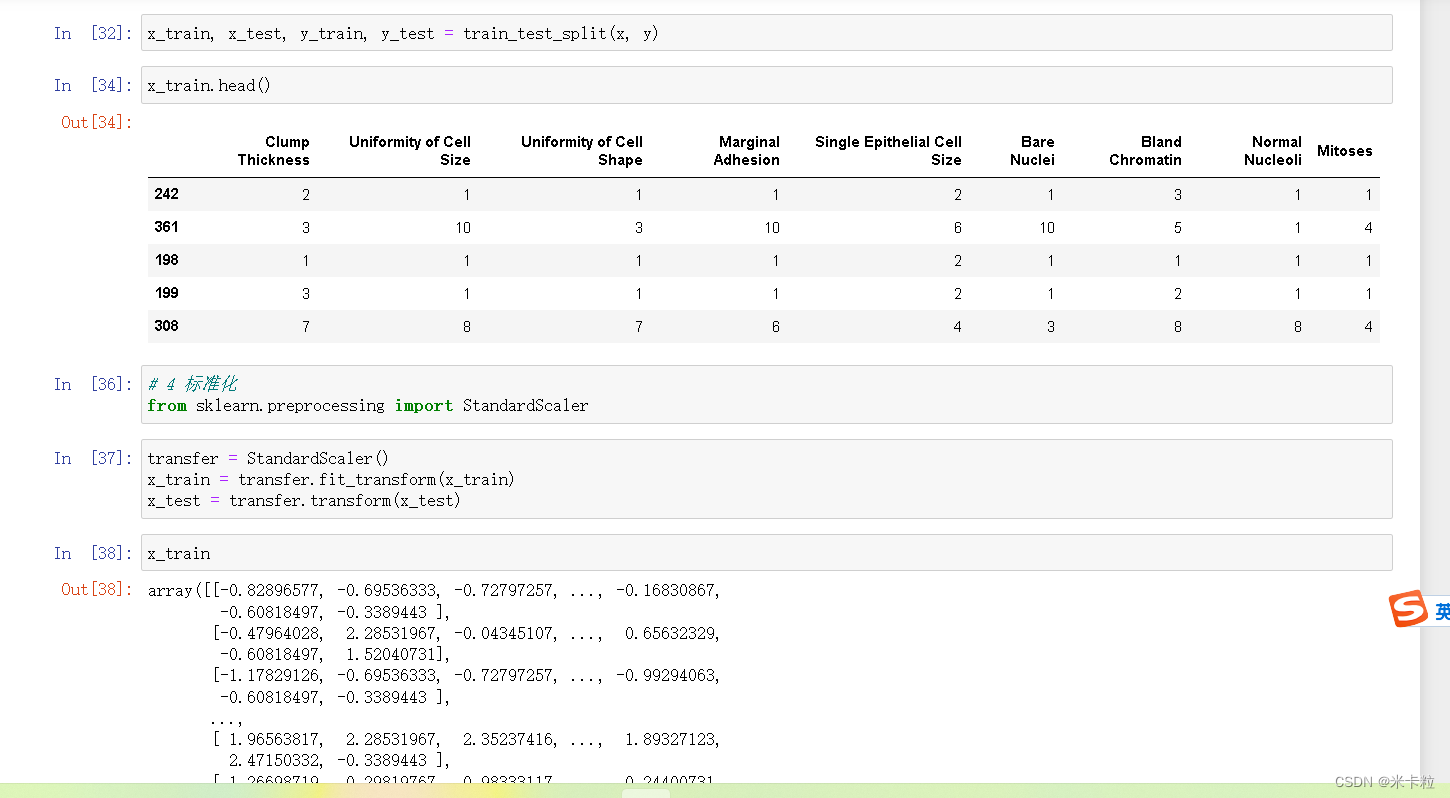
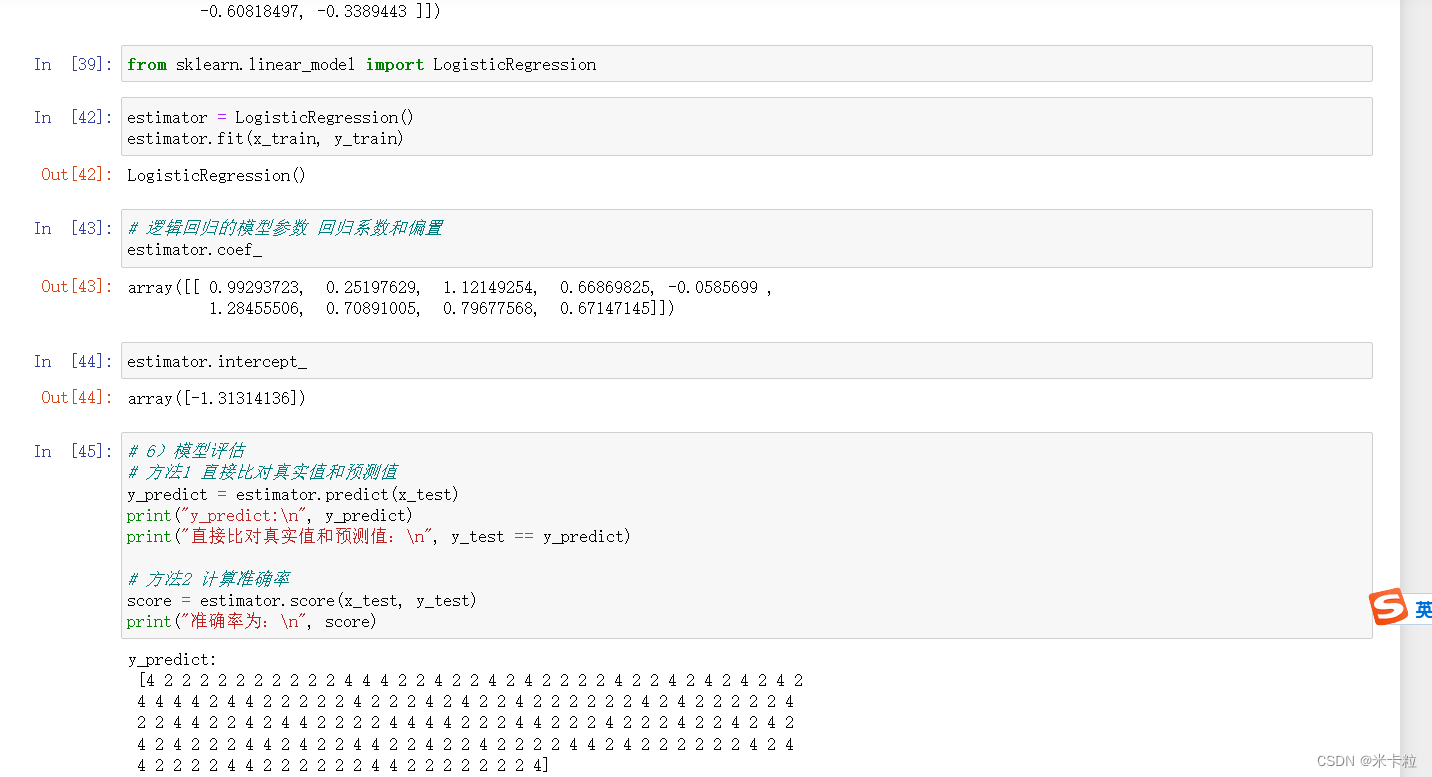
data = pd.read_csv(path, names=column_name)jupyter 代码截图运行如下
为什么代码写一点点就开始截图呢
因为wotailanle
精确率与召回率
精确率 预测结果为正中真实为正例的比例
召回率 真实为正例的样本中预测结果为正例的比例
(其他预估标准,f1-score,反映了模型的稳健性)
分类评估报告api
sklearn.metrics.classificaction_report(y_true,y_predict,labels=[],target_names=none)
- y_true 真实标准值
- y_predict 估计器预测目标值
- labels 指定类别对应的数字
- target_names 目标类别的名字
- return 每个类别精确率与召回率
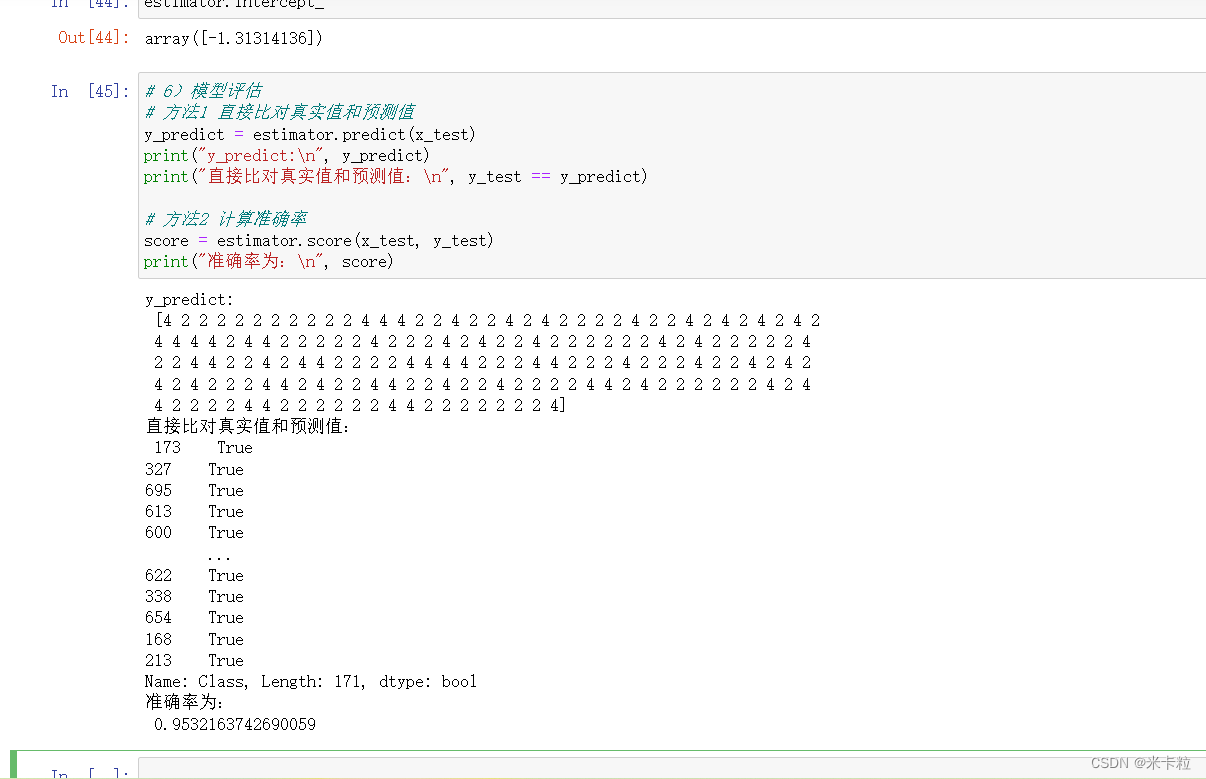
# 查看精确率、召回率、f1-score
from sklearn.metrics import classification_report
report = classification_report(y_test, y_predict, labels=[2,4], target_names=["良性", "恶性"])
print(report)roc auc曲线
roc曲线
该曲线的横轴就是fprate,当二者相等是,表示的意义则是:对于不论真实类别是1还是0的样本,分类器预测为1的概率是相等的,此时auc为0.5
auc指标
auc的概率意义是随机取一对正负样本得分大于负样本的概率
最小值为0.5 最大值为1 取值越高越好
auc=1完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测,绝大多数预测的场合,不存在完美分类器
优于随机猜测,这个分类器妥着设定阈值的话,能有预测价值
api
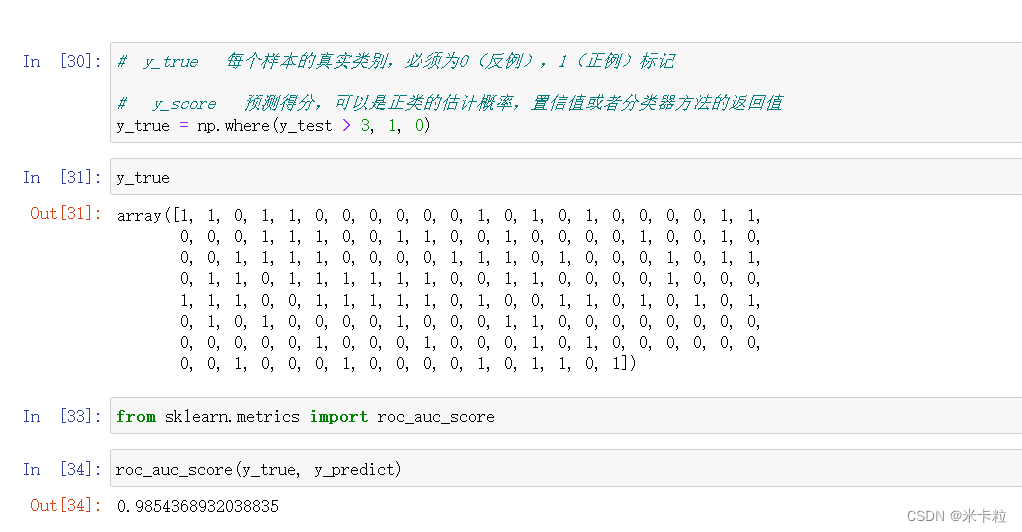
from sklearn.metrics imort roc_auc_score
sklearn.metrics.roc_auc_score(y_true, y_score)
计算roc曲线面积,即auc值
y_true 每个样本的真实类别,必须为0(反例),1(正例)标记
y_score 预测得分,可以是正类的估计概率,置信值或者分类器方法的返回值



发表评论