什么是spark?
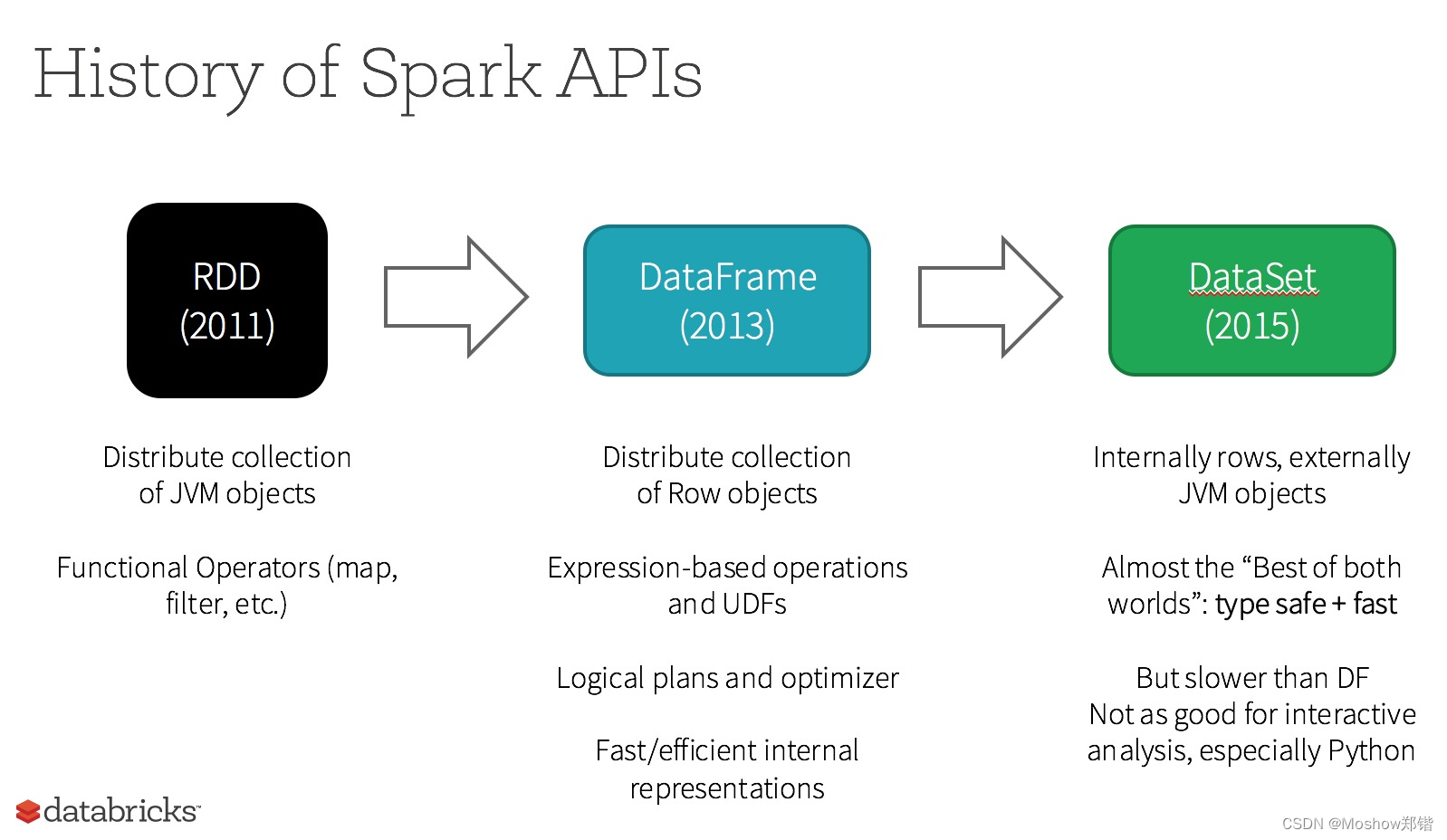
apache spark是一个开源的分布式计算系统,它提供了一个快速和通用的集群计算平台。spark 能够处理大规模数据,支持多种编程语言,如scala、java和python,并且具有多种高级功能,包括sql查询、机器学习、图处理和实时数据流处理。
以下是spark的一些基础概念和组件:
-
弹性分布式数据集(rdd):
- rdd是spark的最基本的数据抽象,代表一个不可变、分布式的数据集合。
- rdd提供了丰富的转换操作,如map、filter、reduce等,以及行动操作,如count、collect等。
-
dataframe:
- dataframe是一个以rdd为基础的更高级的抽象,提供了结构化的数据操作。
- dataframe api允许用户以声明式的方式进行数据查询,类似于sql。
-
dataset:
- dataset是spark的另一个数据抽象,结合了rdd的强类型和dataframe的结构化特性。
- dataset api提供了编译时类型检查和运行时的高性能优化。
-
spark sql:
- spark sql是spark的一个模块,提供了用于执行sql查询和操作dataframe和dataset的编程接口。
- 用户可以使用spark sql进行数据的读取、写入、转换和查询。
-
spark streaming:
- spark streaming是spark的实时数据流处理模块。
- 它允许用户以微批处理的方式处理实时数据流。
-
mllib:
- mllib是spark的机器学习库,提供了一系列的算法和工具,用于分类、回归、聚类等机器学习任务。
-
graphx:
- graphx是spark的图处理模块,用于处理图结构数据。
- 它提供了图的创建、查询、转换和迭代图计算的功能。
-
spark core:
- spark core是spark框架的核心,提供了基本的分布式任务调度和集群管理功能。
-
集群管理器:
- spark可以运行在多种集群管理器上,如standalone、hadoop yarn、apache mesos和kubernetes。
-
部署模式:
- spark支持不同的部署模式,包括本地模式和集群模式。
-
缓存和持久化:
- spark允许将数据缓存到内存中,以加速迭代算法或多次使用的数据集。
-
sparksession:
- 在spark 2.0及以后的版本中,sparksession是新的入口点,用于创建dataframe和dataset,以及访问spark sql功能。
-
dataframe转换操作:
- 转换操作包括select、filter、groupby、orderby、join等。
-
dataframe行动操作:
- 行动操作包括count、collect、show、save等。
-
spark ui:
- spark提供了一个web ui,用于监控和调试spark应用程序。
-
容错机制:
- spark使用 lineage信息和数据的不可变性来实现容错。
-
资源调度:
- spark提供了资源调度的机制,允许用户配置应用程序的资源需求。
spark是一个功能强大且灵活的计算平台,适用于各种大数据处理场景。通过其丰富的api和组件,spark能够满足从批处理到实时处理、从数据处理到机器学习的多种需求。
dataframe api
在java中使用apache spark的dataframe api,你首先需要在spring boot项目中添加spark的依赖。以下是在spring boot项目中集成apache spark并使用dataframe api的步骤:
-
添加依赖: 在你的
pom.xml文件中添加apache spark的依赖。由于spark的依赖可能与其他库有冲突,建议使用spark-sql模块,它包含了dataframe api所需的核心库。<dependencies> <!-- 其他依赖 --> <dependency> <groupid>org.apache.spark</groupid> <artifactid>spark-sql_2.12</artifactid> <version>3.1.1</version> <!-- 使用适合你的spark版本 --> </dependency> </dependencies> -
创建sparksession:
sparksession是使用dataframe api的入口点,你需要创建一个sparksession实例来开始使用dataframe。import org.apache.spark.sql.sparksession; public class sparkdemo { public static void main(string[] args) { sparksession spark = sparksession .builder() .appname("java spark dataframe api demo") .master("local[*]") // 使用本地所有核心 .getorcreate(); } } -
读取数据: 使用
sparksession读取数据,可以是json、csv、parquet等格式。import org.apache.spark.sql.dataset; import org.apache.spark.sql.row; dataset<row> df = spark.read().json("path_to_your_data.json"); -
dataframe操作: 使用dataframe api进行数据操作,如选择、过滤、聚合等。
import static org.apache.spark.sql.functions.*; // 选择列 df.select("column1", "column2").show(); // 过滤数据 df.filter(col("column1").equalto("value")).show(); // 聚合操作 df.groupby("column1").agg(sum("column2").alias("total")).show(); -
执行行动操作: 行动操作会触发实际的计算,如
collect、count、show等。long count = df.count(); // 计数 df.show(); // 显示前20行数据 -
停止sparksession: 在应用程序结束时,应该停止
sparksession以释放资源。spark.stop(); -
配置spring boot: 如果你希望spark集成到spring boot中,可以在spring boot的配置类中配置
sparksession,并通过spring的依赖注入将其注入到需要使用spark的组件中。import org.springframework.context.annotation.bean; import org.springframework.context.annotation.configuration; @configuration public class sparkconfig { @bean public sparksession sparksession() { return sparksession .builder() .appname("spring boot spark dataframe api") .master("local[*]") .getorcreate(); } }
请注意,在使用spark时,你可能需要根据你的数据源和业务需求进行配置和调整。此外,由于spark是一个分布式计算框架,通常用于处理大规模数据集,因此在本地模式下可能不会看到其全部优势。在生产环境中,你可能会配置spark以连接到一个集群。

发表评论