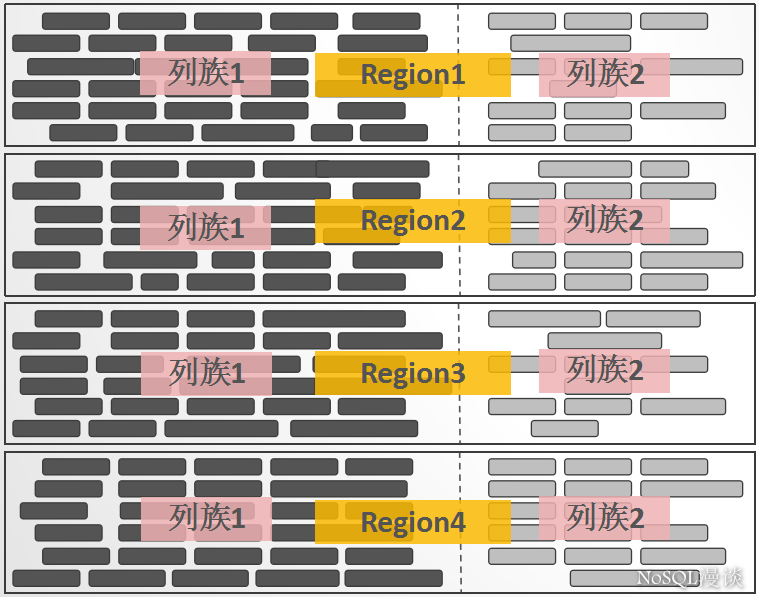
keyvalue
keyvalue的设计不是源自bigtable,而是要追溯至论文”the log-structured merge-tree(lsm-tree)”。每一行中的每一列数据,都被包装成独立的拥有特定结构的keyvalue,keyvalue中包含了丰富的自我描述信息:

看的出来,keyvalue是支撑”稀疏矩阵”设计的一个关键点:一些key相同的任意数量的独立keyvalue就可以构成一行数据。但这种设计带来的一个显而易见的缺点:每一个keyvalue所携带的自我描述信息,会带来显著的数据膨胀。
适用场景
在介绍完了hbase的数据模型以后,我们可以回答本文一开始的前两个问题:
hbase的数据模型比较简单,数据按照rowkey排序存放,适合hbase存储的数据,可以简单总结如下:
- 以实体为中心的数据
实体可以包括但不限于如下几种:
-
自然人/账户/手机号/车辆相关数据
-
用户画像数据(含标签类数据)
-
图数据(关系类数据)
描述这些实体的,可以有基础属性信息、实体关系(图数据)、所发生的事件(如交易记录、车辆轨迹点)等等。
-
以事件为中心的数据
-
监控数据
-
时序数据
-
实时位置类数据
-
消息/日志类数据
上面所描述的这些数据,有的是结构化数据,有的是半结构化或非结构化数据。hbase的“稀疏矩阵”设计,使其应对非结构化数据存储时能够得心应手,但在我们的实际用户场景中,结构化数据存储依然占据了比较重的比例。由于hbase仅提供了基于rowkey的单维度索引能力,在应对一些具体的场景时,依然还需要基于hbase之上构建一些专业的能力,如:
-
opentsdb 时序数据存储,提供基于metrics+时间+标签的一些组合维度查询与聚合能力
-
geomesa 时空数据存储,提供基于时间+空间范围的索引能力
-
janusgraph 图数据存储,提供基于属性、关系的图索引能力
hbase擅长于存储结构简单的海量数据但索引能力有限,而oracle等传统关系型数据库(rdbms)能够提供丰富的查询能力,但却疲于应对tb级别的海量数据存储,hbase对传统的rdbms并不是取代关系,而是一种补充。
hbase与hdfs
我们都知道hbase的数据是存储于hdfs里面的,相信大家也都有这么的认知:
理解了这一点,我们先来粗略回答本文已开始提出的其中两个问题:
集群角色
我们假设集群环境已经ready了,先来看一下集群中的关键角色:
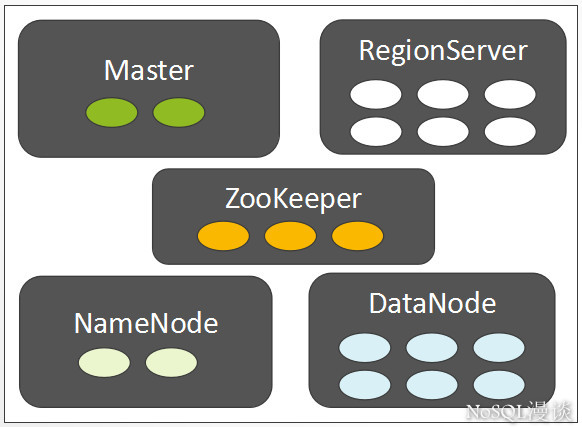
相信大部分人对这些角色都已经有了一定程度的了解,我们快速的介绍一下各个角色在集群中的主要职责(注意:这里不是列出所有的职责):
- zookeeper
在一个拥有多个节点的分布式系统中,假设,只能有一个节点是主节点,如何快速的选举出一个主节点而且让所有的节点都认可这个主节点?这就是hbase集群中存在的一个最基础命题。
利用zookeeper就可以非常简单的实现这类”仲裁”需求,zookeeper还提供了基础的事件通知机制,所有的数据都以 znode的形式存在,它也称得上是一个”微型数据库”。
- namenode
hdfs作为一个分布式文件系统,自然需要文件目录树的元数据信息,另外,在hdfs中每一个文件都是按照block存储的,文件与block的关联也通过元数据信息来描述。namenode提供了这些元数据信息的存储。
- datanode
hdfs的数据存放节点。
- regionserver
hbase的数据服务节点。
- master
hbase的管理节点,通常在一个集群中设置一个主master,一个备master,主备角色的”仲裁”由zookeeper实现。 master主要职责:
-
负责管理所有的regionserver
-
建表/修改表/删除表等ddl操作请求的服务端执行主体
-
管理所有的数据分片(region)到regionserver的分配
-
如果一个regionserver宕机或进程故障,由master负责将它原来所负责的regions转移到其它的regionserver上继续提供服务
-
master自身也可以作为一个regionserver提供服务,该能力是可配置的
集群部署建议
如果基于物理机/虚拟机部署,通常建议:
- regionserver与datanode联合部署,regionserver与datanode按1:1比例设置。
这种部署的优势在于,regionserver中的数据文件可以存储一个副本于本机的datanode节点中,从而在读取时可以利用hdfs中的”短路径读取(short circuit)“来绕过网络请求,降低读取时延。
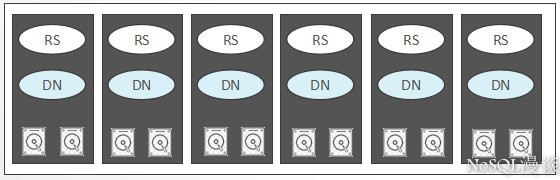
- 管理节点独立于数据节点部署
如果是基于物理机部署,每一台物理机节点上可以设置几个regionservers/datanodes来提升资源使用率。
也可以选择基于容器来部署,如在hbasecon asia 2017大会知乎的演讲主题中,就提到了知乎基于kubernetes部署hbase服务的实践。
对于公有云hbase服务而言,为了降低总体拥有成本(tco),通常选择”计算与存储物理分离“的方式,从架构上来说,可能导致平均时延略有下降,但可以借助于共享存储底层的io优化来做一些”弥补”。
hbase集群中的regionservers可以按逻辑划分为多个groups,一个表可以与一个指定的group绑定,可以将regionserver group理解成将一个大的集群划分成了多个逻辑子集群,借此可以实现多租户间的隔离,这就是hbase中的regionserver group特性。
示例数据
给出一份我们日常都可以接触到的数据样例,先简单给出示例数据的字段定义:

如上定义与实际的通话记录字段定义相去甚远,本文力求简洁,仅给出了最简单的示例。如下是”虚构”的样例数据:
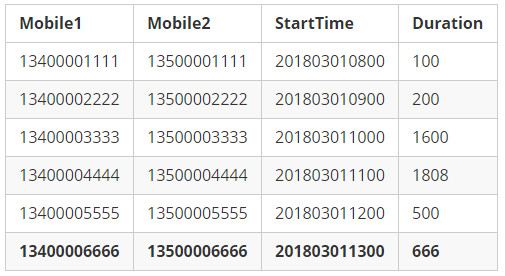
在本文大部分内容中所涉及的一条数据,是上面加粗的最后一行”mobile1“为”13400006666“这行记录。
写数据之前:建立连接
login
在启用了安全特性的前提下,login阶段是为了完成用户认证(确定用户的合法身份),这是后续一切安全访问控制的基础。
当前hadoop/hbase仅支持基于kerberos的用户认证,zookeeper除了kerberos认证,还能支持简单的用户名/密码认证,但都基于静态的配置,无法动态新增用户。如果要支持其它第三方认证,需要对现有的安全框架做出比较大的改动。
创建connection
connection可以理解为一个hbase集群连接的抽象,建议使用connectionfactory提供的工具方法来创建。因为hbase当前提供了两种连接模式:同步连接,异步连接,这两种连接模式下所创建的connection也是不同的。我们给出connectionfactory中关于获取这两种连接的典型方法定义:
completablefuture createasyncconnection(configuration conf,
user user);
connection createconnection(configuration conf, executorservice pool, user user)
throws ioexception;
connection中主要维护着两类共享的资源:
-
线程池
-
socket连接
这些资源都是在真正使用的时候才会被创建,因此,此时的连接还只是一个”虚拟连接”。
写数据之前:创建数据表
ddl操作的抽象接口 – admin
admin定义了常规的ddl接口,列举几个典型的接口:
void createnamespace(final namespacedescriptor descriptor) throws ioexception;
void createtable(final htabledescriptor desc, byte[][] splitkeys) throws ioexception;
tablename[] listtablenames() throws ioexception;
预设合理的数据分片 – region
分片数量会给读写吞吐量带来直接的影响,因此,建表时通常建议由用户主动指定划分region分割点,来设定region的数量。
hbase中数据是按照rowkey的字典顺序排列的,为了能够划分出合理的region分割点,需要依据如下几点信息:
-
key的组成结构
-
key的数据分布预估
如果不能基于key的组成结构来预估数据分布的话,可能会导致数据在region间的分布不均匀
- 读写并发度需求
依据读写并发度需求,设置合理的region数量
为表定义合理的schema
既然hbase号称”schema-less”的数据存储系统,那何来的是schema? 的确,在数据库范式的支持上,hbase非常弱,这里的schema,主要指如下一些信息的设置:
- namespace设置
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、oppo等大厂,18年进入阿里一直到现在。
深知大多数java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加v获取:vip1024b (备注java)

spring全套教学资料
spring是java程序员的《葵花宝典》,其中提供的各种大招,能简化我们的开发,大大提升开发效率!目前99%的公司使用了spring,大家可以去各大招聘网站看一下,spring算是必备技能,所以一定要掌握。
目录:


部分内容:
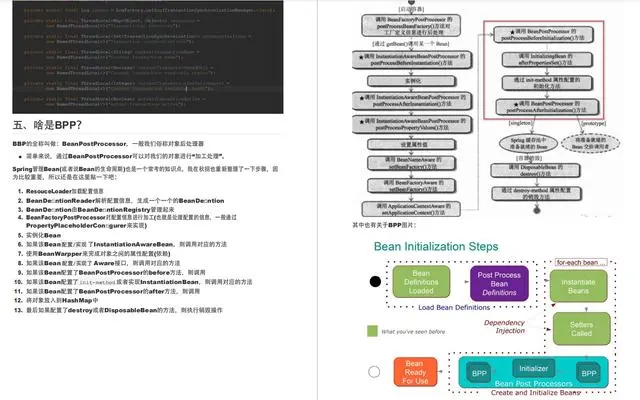
spring源码
- 第一部分 spring 概述
- 第二部分 核心思想
- 第三部分 手写实现 ioc 和 aop(自定义spring框架)
- 第四部分 spring ioc 高级应用
基础特性
高级特性 - 第五部分 spring ioc源码深度剖析
设计优雅
设计模式
注意:原则、方法和技巧 - 第六部分 spring aop 应用
声明事务控制 - 第七部分 spring aop源码深度剖析
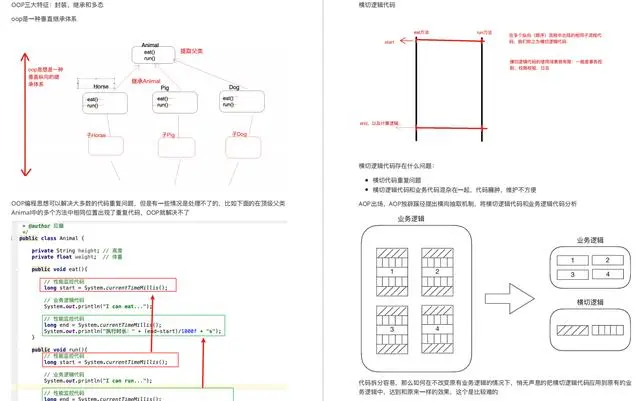
必要的笔记、必要的图、通俗易懂的语言化解知识难点

脚手框架:springboot技术
- springboot入门
- 配置文件
- 日志
- web开发
- docker
- springboot与数据访问
- 启动配置原理
- 自定义starter
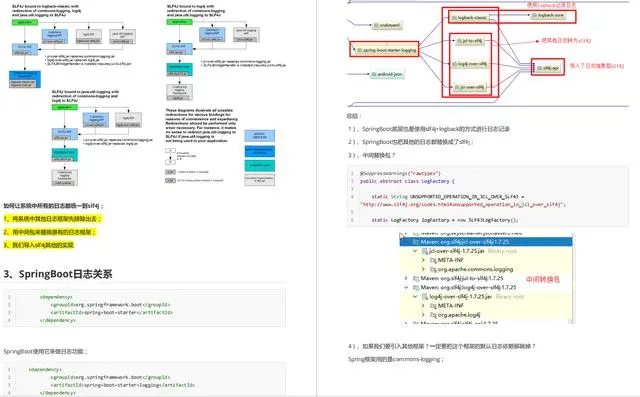

微服务架构:spring cloud alibaba
- 微服务架构介绍
- spring cloud alibaba介绍
- 微服务环境搭建
- 服务治理
- 服务容错
- 服务网关
- 链路追踪
- zipkin集成及数据持久化
- 消息驱动
- 短信服务
- nacos confifig—服务配置
- seata—分布式事务
- dubbo—rpc通信
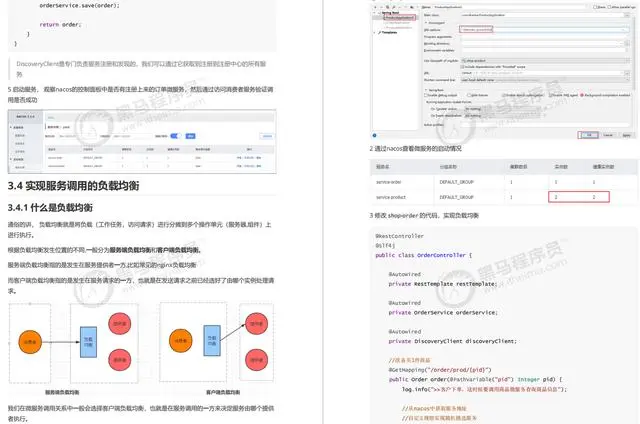
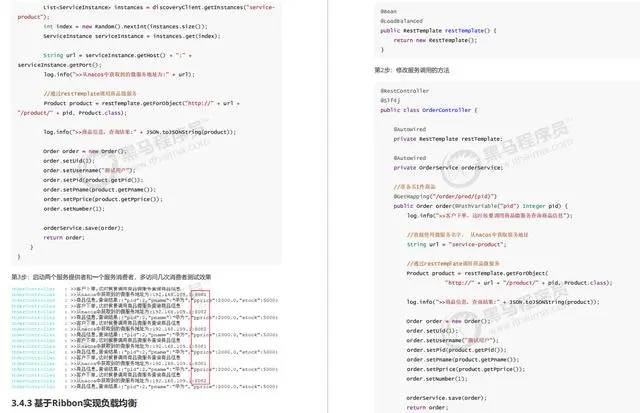
spring mvc
目录:



部分内容:


程模型轻松使用这些组件来开发分布式应用服务。
- 微服务架构介绍
- spring cloud alibaba介绍
- 微服务环境搭建
- 服务治理
- 服务容错
- 服务网关
- 链路追踪
- zipkin集成及数据持久化
- 消息驱动
- 短信服务
- nacos confifig—服务配置
- seata—分布式事务
- dubbo—rpc通信
[外链图片转存中…(img-ieg0w5lk-1711740401706)]
[外链图片转存中…(img-ibhuyjnd-1711740401706)]
spring mvc
目录:
[外链图片转存中…(img-lp2yrswy-1711740401707)]
[外链图片转存中…(img-lxbdk3f1-1711740401707)]
[外链图片转存中…(img-ca9wm0xc-1711740401708)]
部分内容:
[外链图片转存中…(img-kywqywtu-1711740401708)]
[外链图片转存中…(img-e46lfkha-1711740401708)]


发表评论