hdfs基础知识
1. 介绍一下hdfs组成架构?
组成部分:
- hdfs client,
- namenode,
- datanode
- secondary namenode( ha模式下是 standby namenode)
- client: 客户端
- 文件切分,文件上传hdfs时,client将文件切分成一个一个的block,然后进行存储。
- 与nn交互,获取文件的位置信息。
- 与dn交互,读取或者写入数据。
- client提供一些命令来管理hdfs, 比如启动或者关闭hdfs
- client可以通过一些命令来访问hdfs
- namenode: master,
- 管理hdfs的命名空间
- 管理数据块的映射信息
- 处理客户端的读写请求
- 配置副本策略
- datenode: slave,nn下达命令,dn执行实际的操作
- 存储实际的数据块
- 执行数据块的读写操作
- secondary namenode:
- 辅助nn,分担其工作量。
- 定期合并fsimage和edits log,生成新的fsimage替换旧的fsimage。
- 在紧急情况下辅助恢复nn。
2. namenode 和 secondarynamenode 的区别与联系
- 区别:
- namenode 负责管理整个文件系统的元数据,以及命名空间。
- secondary name node 负责定期合并fsimage和edit log。
- 联系:
- secondary name node 中保存了一份和namenode一致的fsimage(镜像文件)和edits log(编辑日志)。
- 在namenode 发生故障时, 可以从secondary namenode恢复数据。
3. nn和dn的区别和联系?
- 从角色来看:
- nn是master,承担管理者的角色,
- dn 是slave, 承担具体执行者的角色。
- 从工作内容:
- nn管理hdfs的名称空间,数据块的映射信息,处理客户端读写请求。
- dn 存储实际的数据块, 执行数据块的读/写操作。
4. hdfs在ha模式下的工作流程?
相较于非ha模式,多了3部分:
- 负责负载均衡的zk集群。
- edits log文件管理系统qjournal。
- zkfailovercontroller负责监测nn是否健康。
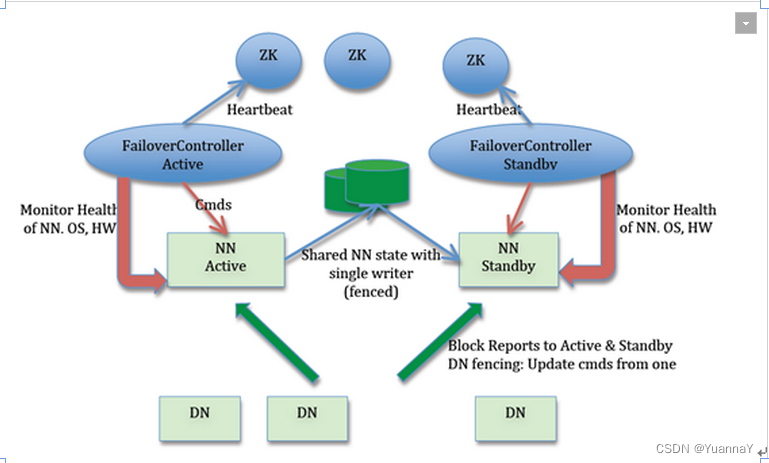
5. zkfailovercontroller的作用?(ha namenode的工作模式)
- 健康监测: 周期性的向它监控的nn发送健康探测命令,从而确定某个nn是否处于健康状态,如果机器宕机,心跳失败,zkfc就会标记该nn处于一个不健康的状态。
- 会话管理: 如果nn是健康的,zkfc就会在zk 中保持一个打开的会话,如果nn同时还是active状态,那么zkfc还会在zookeeper中占有一个类型为短暂类型的znode,当这个nn挂掉后,znode也将会被删掉,然后备用的nn,将会得到这把锁,升级为主nn,同时标记状态为active。
- 当宕机的nn新启动时,会再次注册zk, 发现已有znode锁,会自动变为standby状态(防止脑裂,出现两个active node)
- master选举:通过在zk中维持一个短暂类型的znode, 来实现抢占式的锁机制,从而判断哪个namenode为active状态。
6. hdfs的存储机制
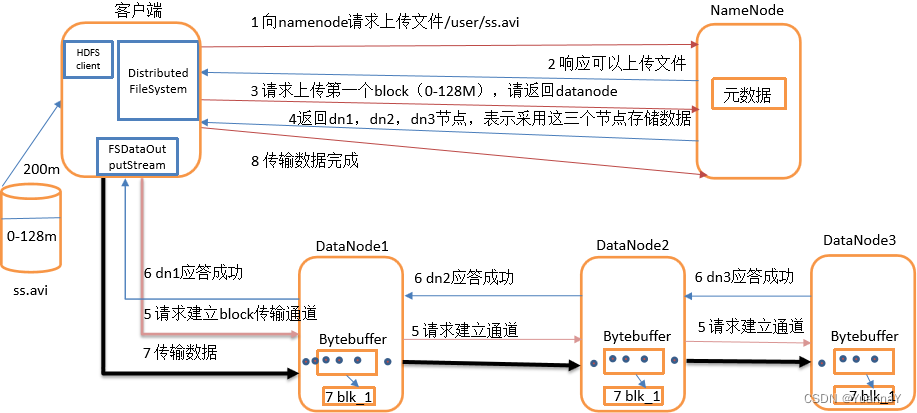
写数过程:
- 客户端通过 distributed filesystem模块向nn发其文件上传请求, nn检查目标文件是否已存在,父目录是否存在
- nn返回是客户端是否可以上传
- 客户端请求第一个block上传到哪几个dn服务器上
- nn返回3个dn节点,分别为dn1,dn2, dn3,表示采用这个三个节点存储数据。
- 客户端通过fsdataoutputstream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3, 将这个通信管道建立完成。
- dn1, dn2, dn3逐级应答客户端
- 客户端开始往dn1上传第一个block, 以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3; dn1每传一个packet会放入一个应答队列等待应答。
- 当一个block传输完成后, 客户端再次请求namenode上传第二个block的服务器。
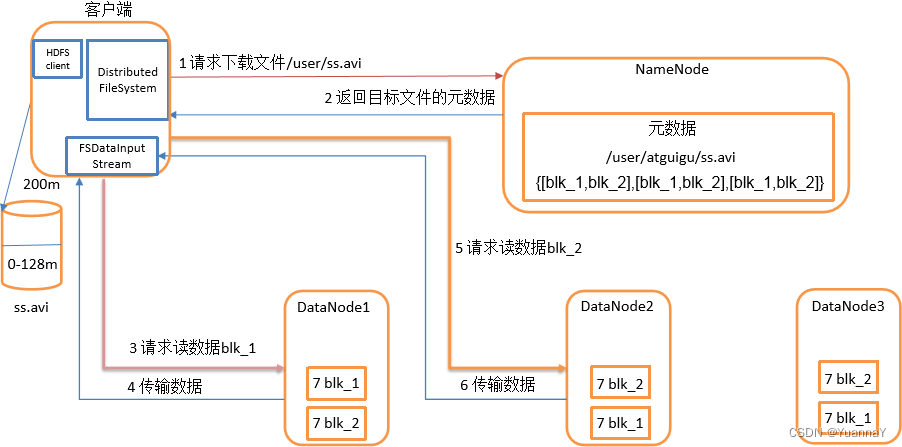
读数过程:
- 客户端通过 distribued filesystem 向namenode请求文件,namenode通过查询元数据,找到文件所在的datanode地址。
- 挑选一台datanode(就近原则)服务器,请求读取数据。
- datanode开始传输数据给客户端(从磁盘里读取数据输入流,以packet为单位来做校验)
- 客户端以packet为单位接收,现在本地缓存,然后写入目标文件。
7. secondary nn 和 ha模式下的standbynn的区别
- 首先强调,secondarynn 不是nn的备份,只能算是辅助,负责定期合并fsimage和edits log,形成新的fsimage 以替换旧的fsimage。简单理解:secondry nn负责的是定期存档,方便那天nn异常退出,可以快速回复。
- ha下的standby nn可以理解为是active的备份,实时合并fsimage和edits log,将合并后的fsimage 替换旧的fsimage。一旦active nn挂了,standby nn 就可以转正,继续提供服务,无需等待,即高可用性的含义。
- 对比,secondary nn 架构简单,但是存在元数据丢失的问题;ha架构复杂,但是元数据不会丢失。
8. hdfs中负责存储的是哪一部分
datenode,dn 负责具体的数据存储操作
9. hdfs中的block默认大小是多少?为什么这么设计?
block默认大小:
1.x版本是64mb,2.x和3.x是128mb。
block的大小是不能太大,也不能太小,这样做的目的是尽量减少寻址时间在总时间中的占比。
这么理解:
- 文件块越大,寻址时间越短,但磁盘传输时间越长;
- 文件块越小,寻址时间越长,但磁盘传输时间越短。
至于为什么是128m,根据统计,hdfs中平均寻址时间大概为10ms,经过测试,寻址时间为传输时间的1%时,为最佳状态
那么按照公式计算:
最佳传输时间为10ms/0.01=1000ms=1s
目前磁盘的传输速率普遍为100mb/s:
最佳block大小:100mb/s x 1s = 100mb
处于对2进制的执着,block设计为128mb。


发表评论