魔法一般的神经网络渲染
铺垫了这么多的硬件基础,英伟达实际上是为了更好地构筑神经网络渲染这项技术,应用范围包括rtx神经网络纹理压缩、rtx神经网络材质、神经网络辐射缓存(nrc)以及rtx神经网络皮肤/面部。
rtx神经纹理压缩:使用ai在不到一分钟的时间内压缩数千种纹理,在相同的视觉质量下可以节省高达7倍的显存占用。
rtx神经材质:使用ai压缩通常保留给离线材质的复杂着色器代码,并且这些材质由多层组成,处理速度可提升5倍。
rtx神经网络辐射缓存:使用在实时游戏数据上训练的神经网络,能更准确和高效地估计游戏场景中的间接光照,而大幅减少光线追踪的计算量。
rtx神经网络皮肤/面部:能够使光线完成射入皮肤内的反射和折射,并且基于ai模型生成更真实的面部和表情,改善人物的身整体呈现和解决恐怖谷效应的问题。
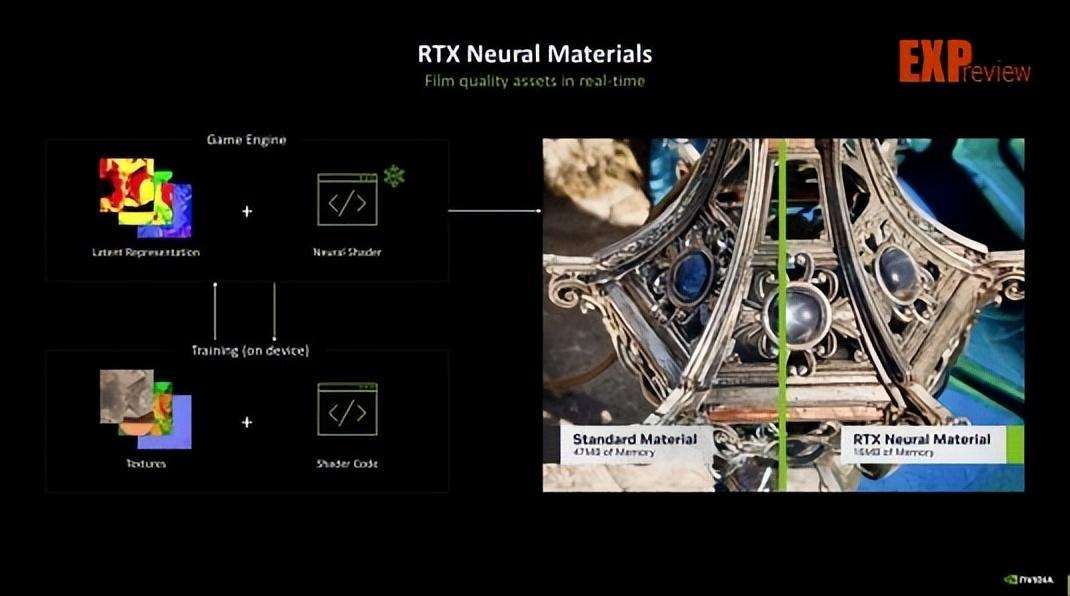
rtx神经材质

rtx神经网络辐射缓存

rtx神经网络皮肤
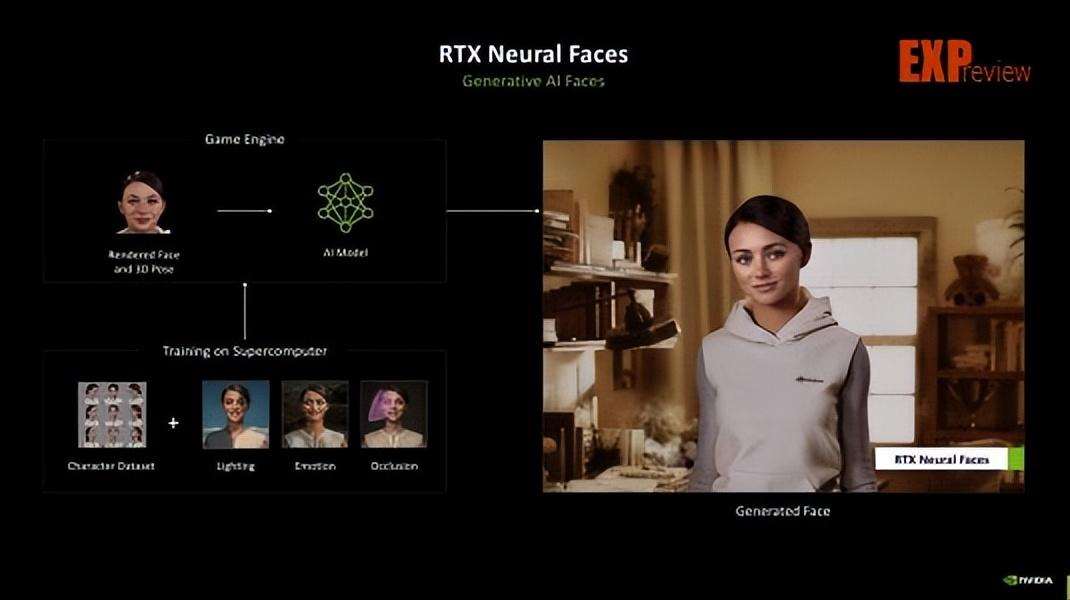
rtx神经网络面部
dlss 4:帧生成plus
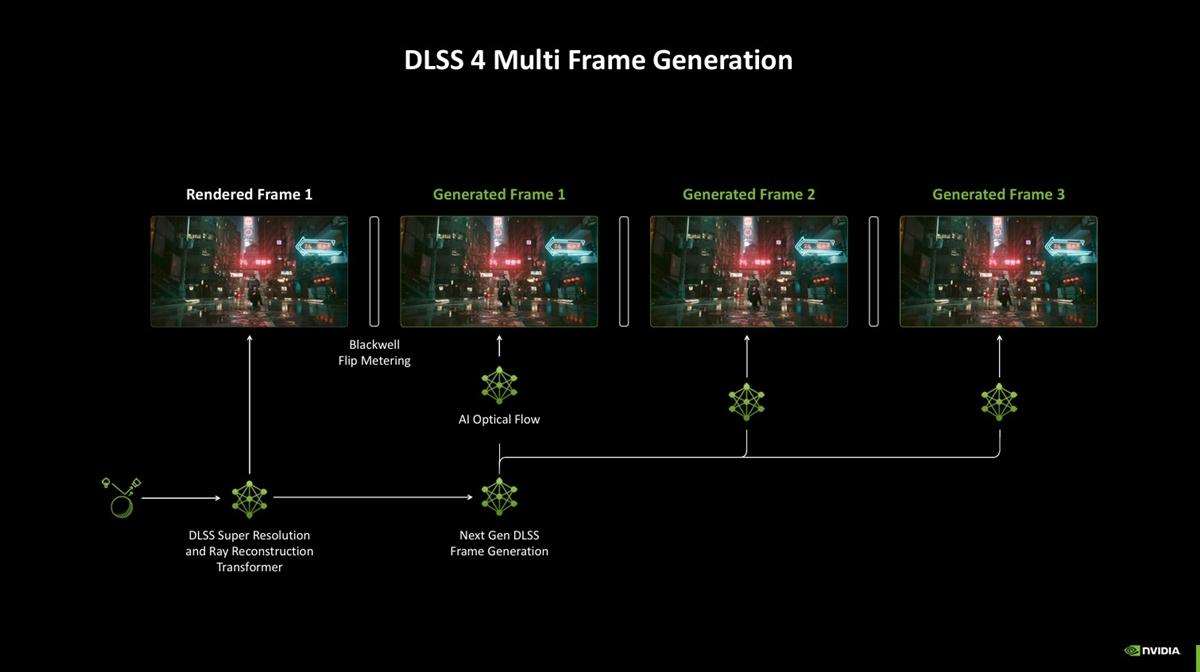
新一代blackwell架构gpu上引入了dlss 4,提供了多帧生成功能,即在每个传统渲染的帧之间生成多达三个额外的帧。这不仅基于blackwell的帧生成模型比上一代快了40%、显存占用降低30%的强大优势,而且用于提供光流场信息的不再是rtx 40系列上的光流加速器,而是一个更高效的ai模型。
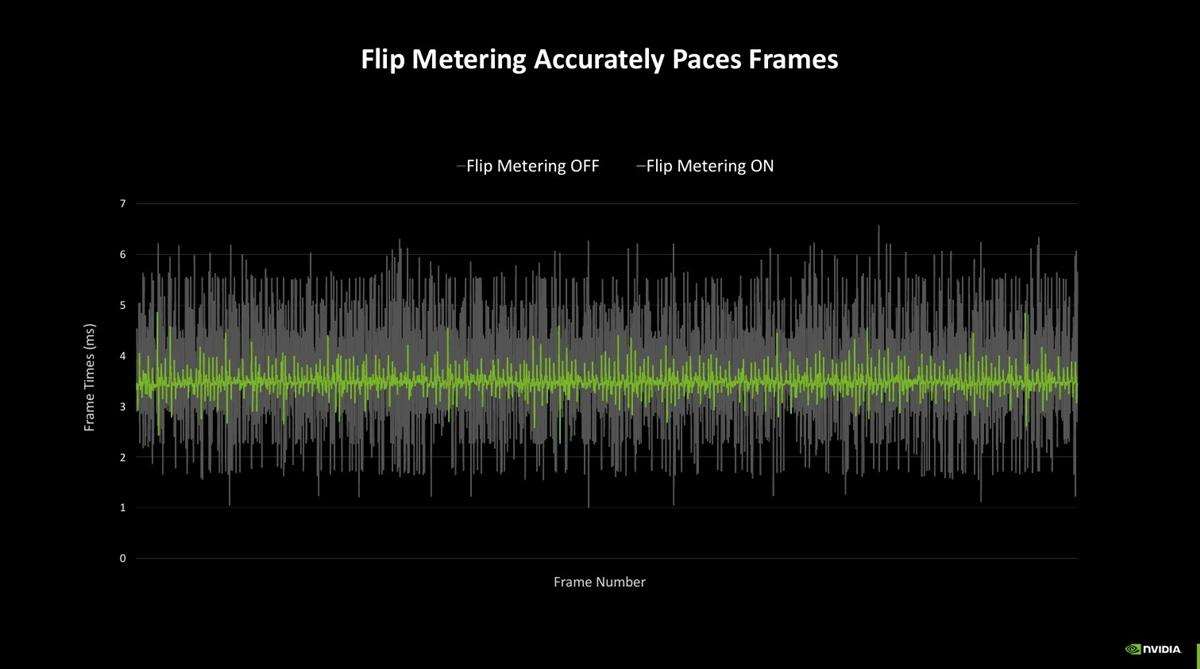
为了避免输出帧画面过多导致的顺序乱套,英伟达还引入了flip metering功能,能够将帧平滑逻辑从cpu转移到gpu的显示引擎上,让gpu更精确地掌控显示每一帧的节奏并降低帧时间。而刚好blackwell的显示引擎拥有较为出色的像素处理能力,可以以支持更高的分辨率和刷新率,从而实现带有dlss 4的flip metering。不过,由于dlss 4多帧生成需要用到第5代tensor core的强劲算力去计算光流场和生成多帧,因此这个功能目前是blackwell独占的。
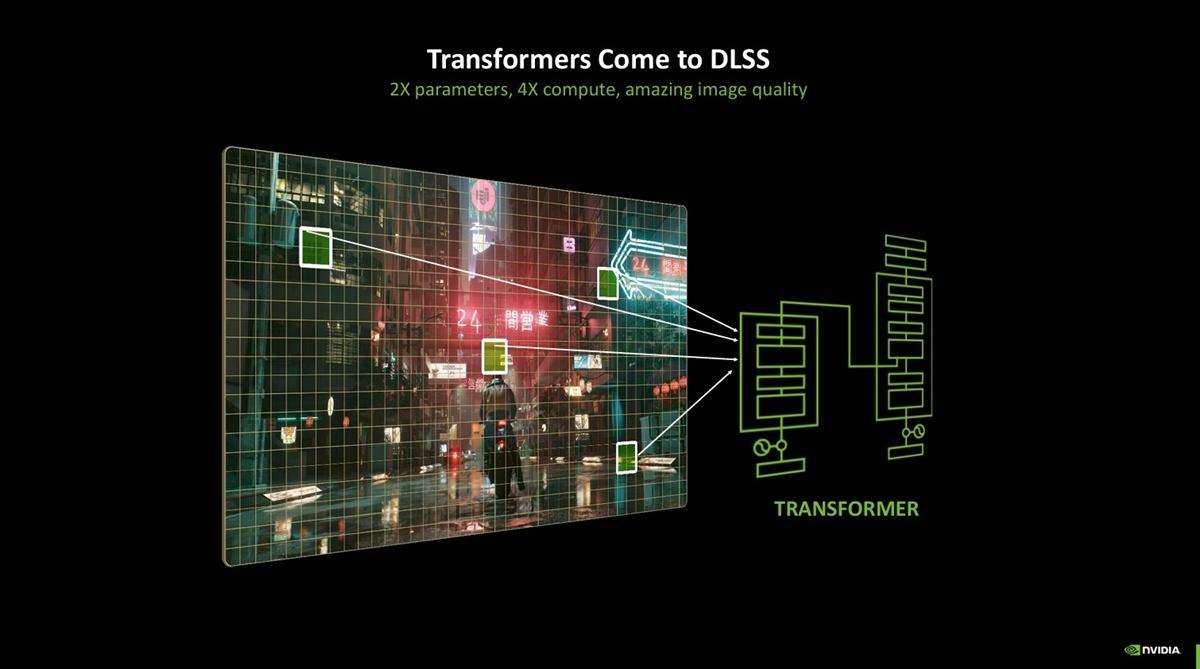
此外,超分辨率、光线重建、dlaa也获得了更新,它们的模型从cnn换成了transformer,是一个采用自注意力机制的神经网络,能够提高画面的稳定性,提升光照细节,给予动态物体更多细节。预计在未来数年里,图像质量会持续提升。

对于游戏和应用,dlss 4结合多帧生成、光线重建和超级分辨率技术,将帧率提升至普通渲染的最高8倍,并在从帧生成升级到多帧生成时,进一步提高帧率高达1.7倍,性能提升效果非常地明显。
延迟救星nvidia reflex 2
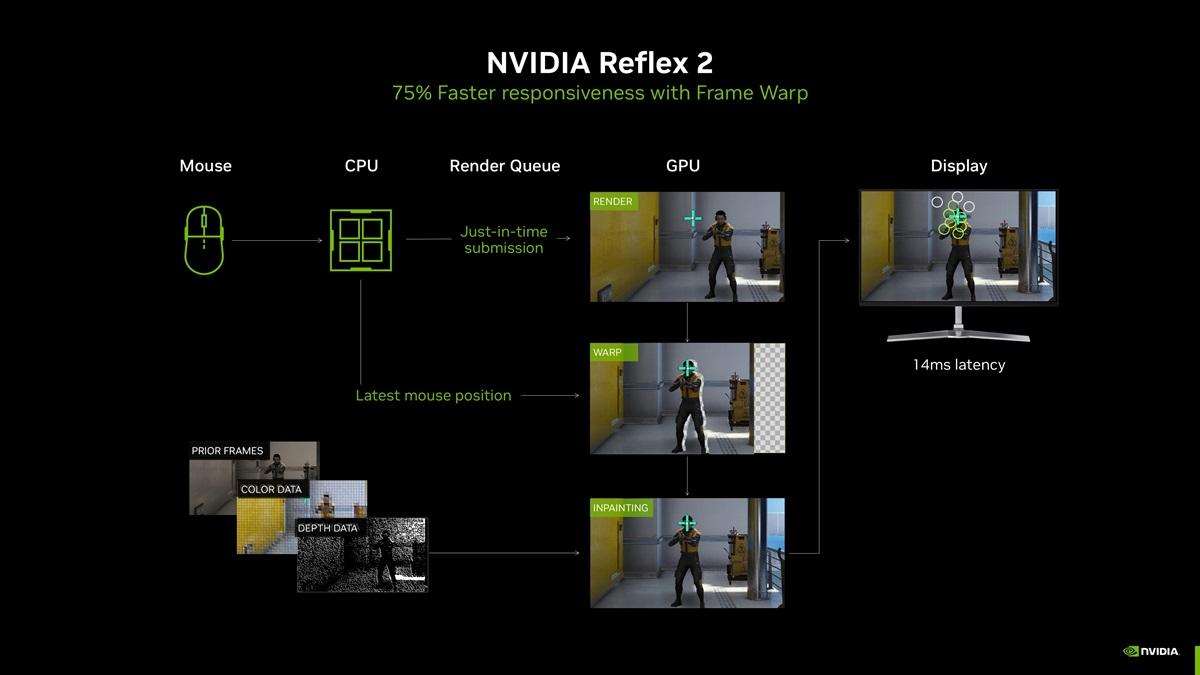
这时可能会有朋友说到了,dlss 4补帧这么猛,延迟不会大打折扣吗?英伟达对此早已给出了对策——nvidia reflex 2。它结合了reflex低延迟模式和新的frame warp技术,能够把最新的鼠标输入指令同步给渲染帧,及时更新渲染的游戏帧并在渲染帧被发送到显示器之前获取最新的鼠标信息,通过刷新渲染的游戏帧以进一步减少延迟,将pc延迟进一步降低多达75%。
nvenc和nvdec新增yuv422支持
目前很多摄像机都支持录制yuv422格式的视频,这是有原因的:yuv422相比起yuv444更节省储存空间,但是比起yuv420能保存更多的颜色,这样一来就给后期调色留下了充足的空间。blackwell这次新增了yuv422的编解码支持,从而能提高创作者的效率,比如说导出时间减少,更流畅的多路回放等。nvidia表示,第6代nvdec可同步解码和播放多达8个4k60 yuv422视频流。

而第9代nvenc则提升了hevc和av1的编码质量,为yuv422 h.264和hvec编码提供了支持。另外,还有一个全新的av1 ultra high quality(uhq)模式,它可以用更多的时间去获得额外5%的质量提升。nvidia还表示,这个模式在rtx 40系列上也可用,不过blackwell的质量是更好的。
显卡解析:踏雪至山巅
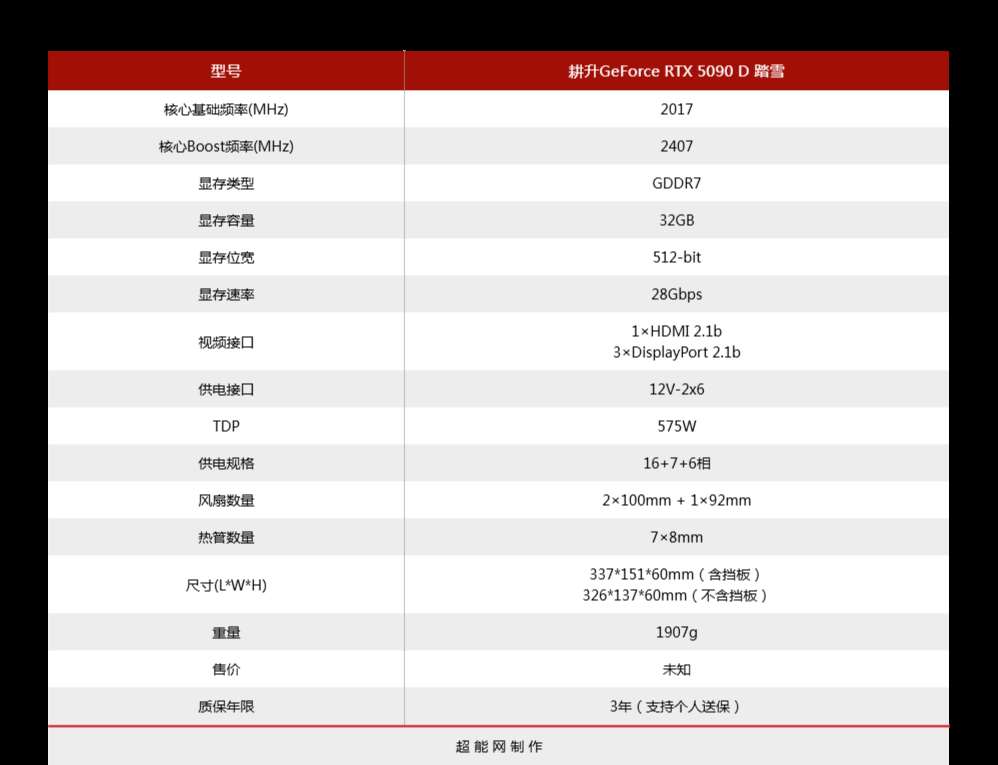
我们把目光放回我们本次评测的主角——耕升 rtx 5090 d 踏雪。由于它是不带oc的标准版,包括核心boost频率在内的绝大部分参数都与英伟达官方标称一致。
外观与包装

耕升 rtx 4070 super 踏雪
说实话,老踏雪给我的印象妥妥的是一张定位高端纯白显卡,如果将它的外观直接搬到万元级的rtx 5090 d上,多少是缺少诚意的,重新设计是势在必行。
发表评论