时隔两年又三个多月,英伟达终于带来了全新的geforce rtx 50系显卡。然而受到相关规定(满足综合运算性能tpp不超过4800的限制)的影响,rtx 5090的命运和rtx 4090一样,化身rtx 5090 d进入国内市场。同时,rtx 5090 d是没有公版(founder edition)的,因此,高端玩家们就只能从一众非公显卡里面去挑选适合自己的那一款了。

而说起耕升的踏雪系列,可能大家第一时间更多会想到纯白设计、中高端定位,很难会将过往最高只搭载过rtx 4070 ti super芯片的它和旗舰显卡联想到一起。不过,当英伟达正式进入rtx 50系显卡时代之后,踏雪也迎来的蜕变,出现在了耕升的rtx 5090 d的产品名单里面。在了解耕升 geforce rtx 5090 d 踏雪之前,我们先来简单回顾一下英伟达rtx 50系显卡到底有什么新的特点。
关于rtx 5090 d
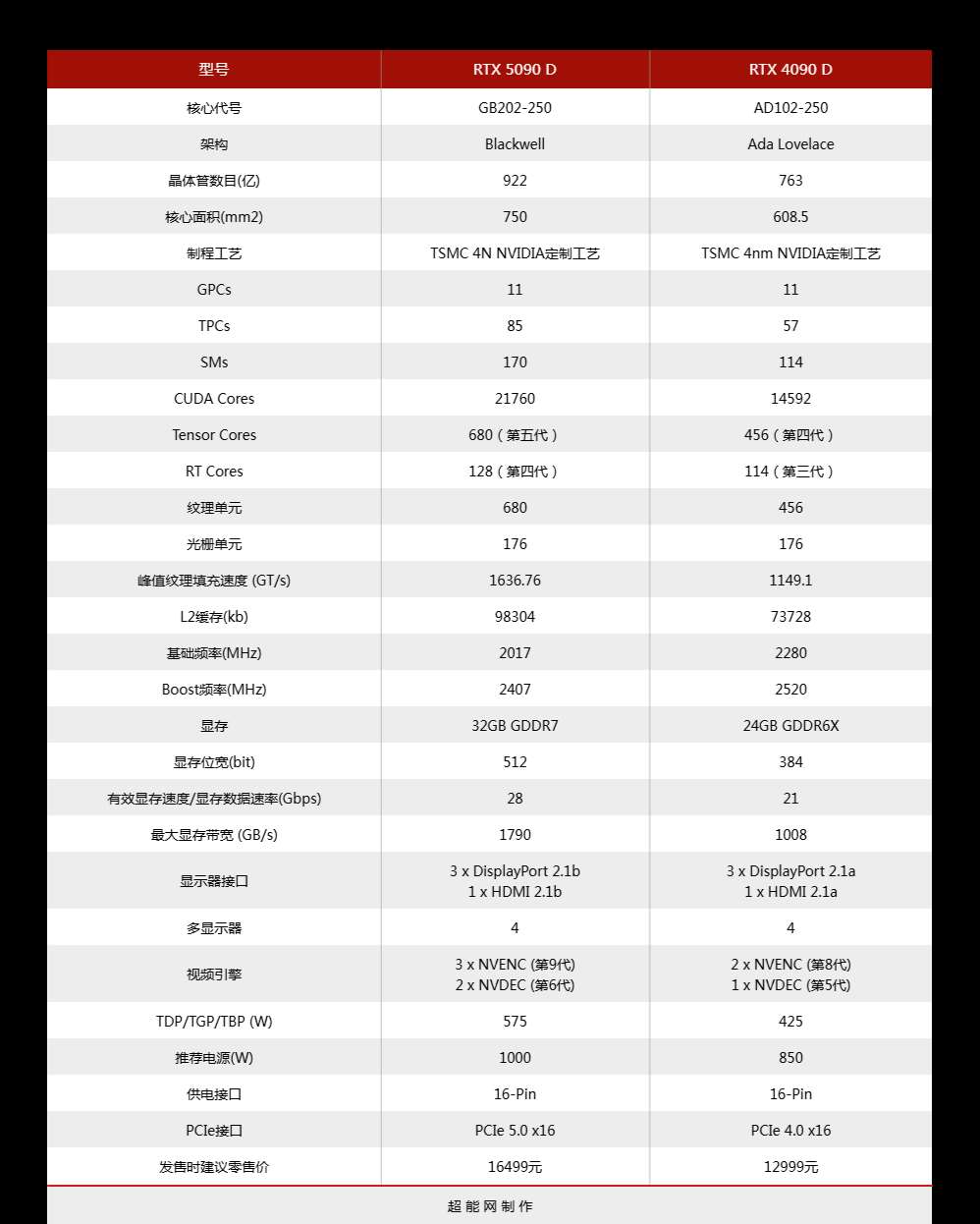
相较于上一代rtx 4090 d来看,rtx 5090 d在芯片的规模上有了较大幅度的升级。虽然制程工艺不变,依然是定制的tsmc 4n,但是,凭借更大的芯片面积和新一代的blackwell核心架构,后者的晶体管数量从763亿个增加至922亿个,cuda核心数量增加将近50%,而且同样是12个gpc,rtx 5090 d每个gpc里的tpc和sm数量增多了,tpc从6个增至8个,sm从12个增至16个。编解码器同样进行了迭代加码,新增了4:2:2色度采样视频编解码的能力,节省cpu的负担,提升内容创作者的工作效率。此外,rtx 5090 d还用上了容量更大、性能更强的gddr7显存,位宽也从384-bit增至512-bit。显示输出接口升级为3×displayport 2.1b+1×hdmi 2.1b的配置,借助dsc技术最高支持4k@480hz或8k@140hz。
不过,这次的rtx 5090 d的命运并不像rtx 4090 d一样在核心规格作出调整。我们从表面参数上基本看不出与rtx 5090有什么区别,对游戏性能造成的影响肯定是远小于rtx 4090 d当初的。至于ai性能嘛,rtx 5090 d则从rtx 5090的3352 ai tops降至2375 ai tops,降幅约29%。
blackwell架构有多牛
不断壮大的核心规模
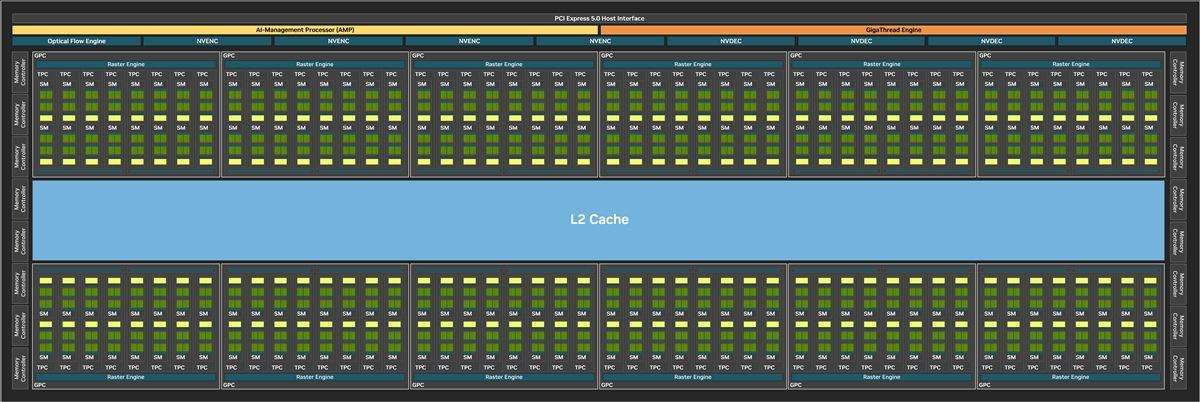
其实,完全体的 blackwell gb202共有12组gpc、24576个cuda核心,rtx 5090 d上的gb202-250则用了其中的88.5%。从整体结构图上还能看到,gigathread engine调度器隔壁多了一个叫做ai-management processor(ai管理处理器,简称amp)的帮手。amp是一个位于管线前端的risc-v处理器,支持windows硬件加速gpu计划,能够更自由地管理gpu。cuda、rt core和tensor core三大部分在它的带领下可以协调工作,实现ai响应速度提高的同时,游戏画面也不会受到影响。
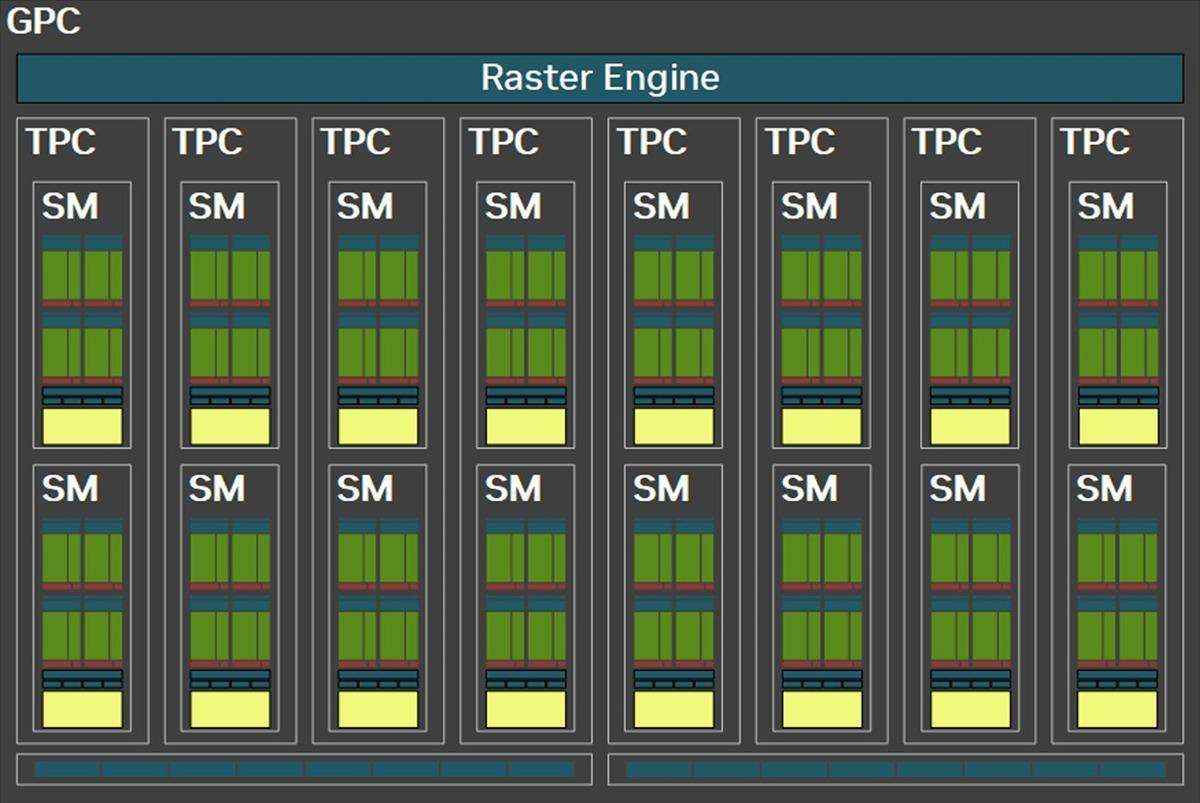
gpc段中,它所包含的tpc从ada lovelace的6组扩展到了8组。不过布局上还是一样的,一个独立的光栅引擎,两个rop分区(每个包含8个rop单元),而每组tpc包含两组sm。
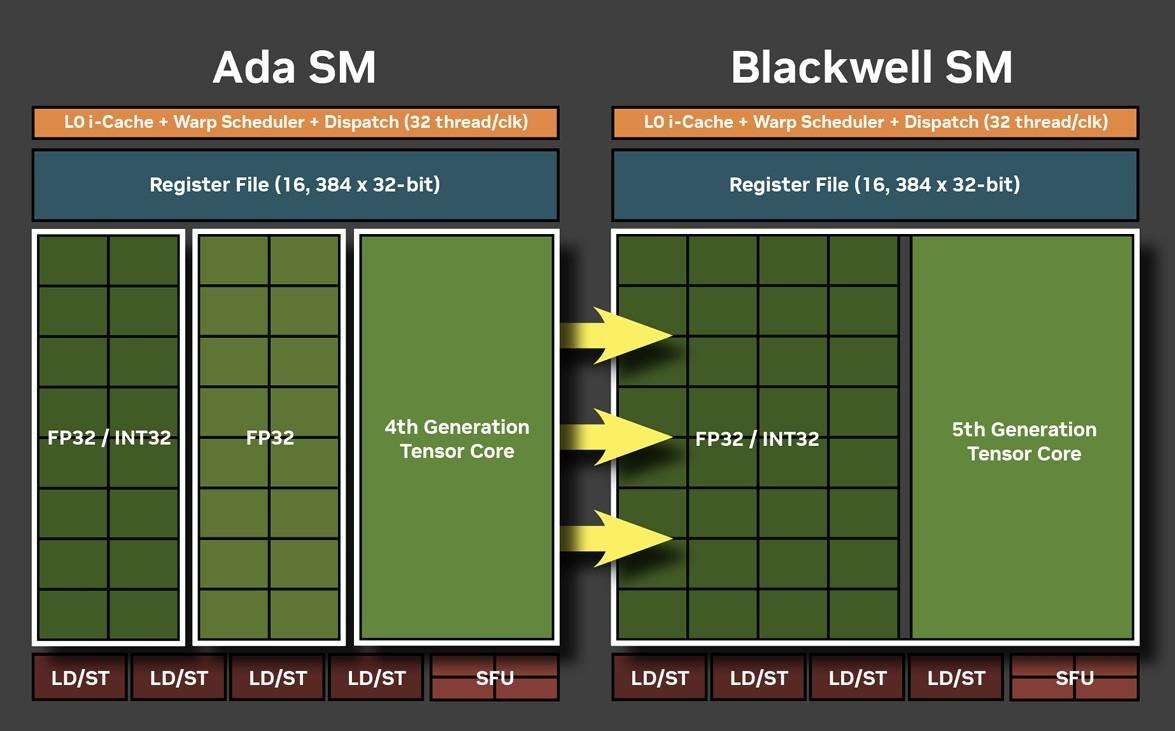
sm段的变化是比较大的。现在所有的32个cuda核心都能执行fp32/int32运算了,因此int32的算力可以说是增加了一倍。不过在一个时钟周期里面,核心只能二选一运算。nvidia表示,这种设计是为神经着色器优化的。
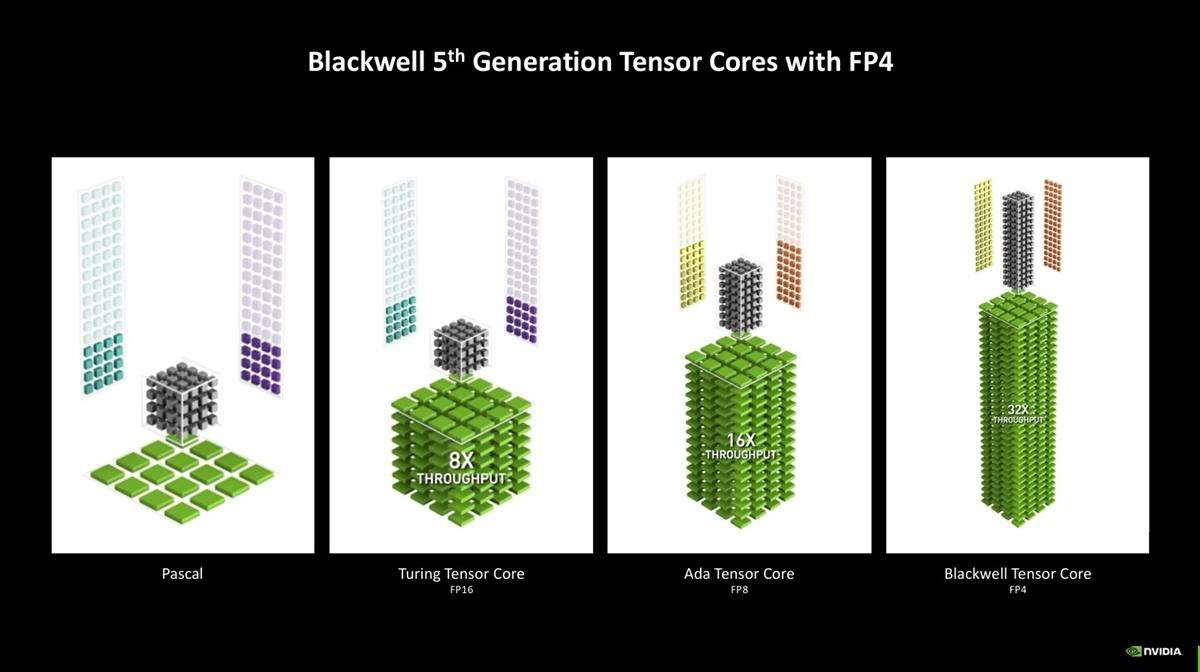
tensor core和rt core自然也有升级。第5代tensor core继承了上一代架构的特性,并新增了fp4、fp6的支持,还把fp8 transformer engine更新到了第二代。其中,fp4是个比较值得关注的点,它相比常规的fp16模型需要的显存更小,在tensorrt模型优化器的支持下能够做到几乎没有质量损失。
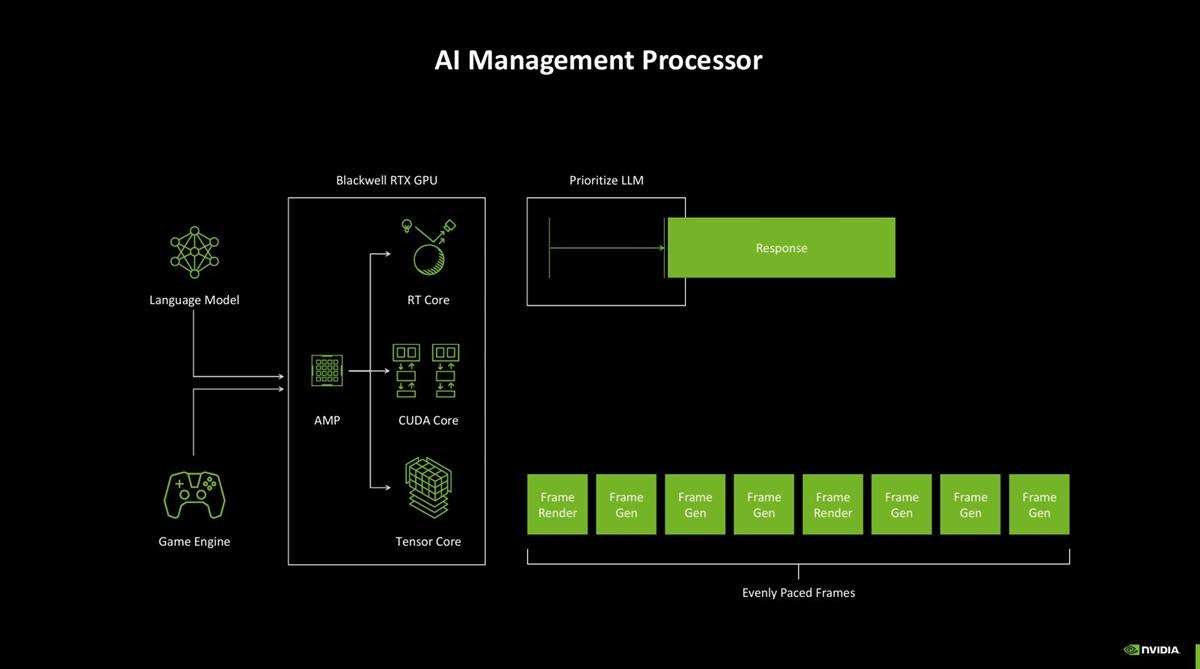
现在,blackwell上的ser(着色器重排序) 2.0还可以将神经网络的负载直接发送至tensor core处理,加速神经网络渲染,效率达到了ada lovelace上的2倍,降低开销之余还能提高精准度。
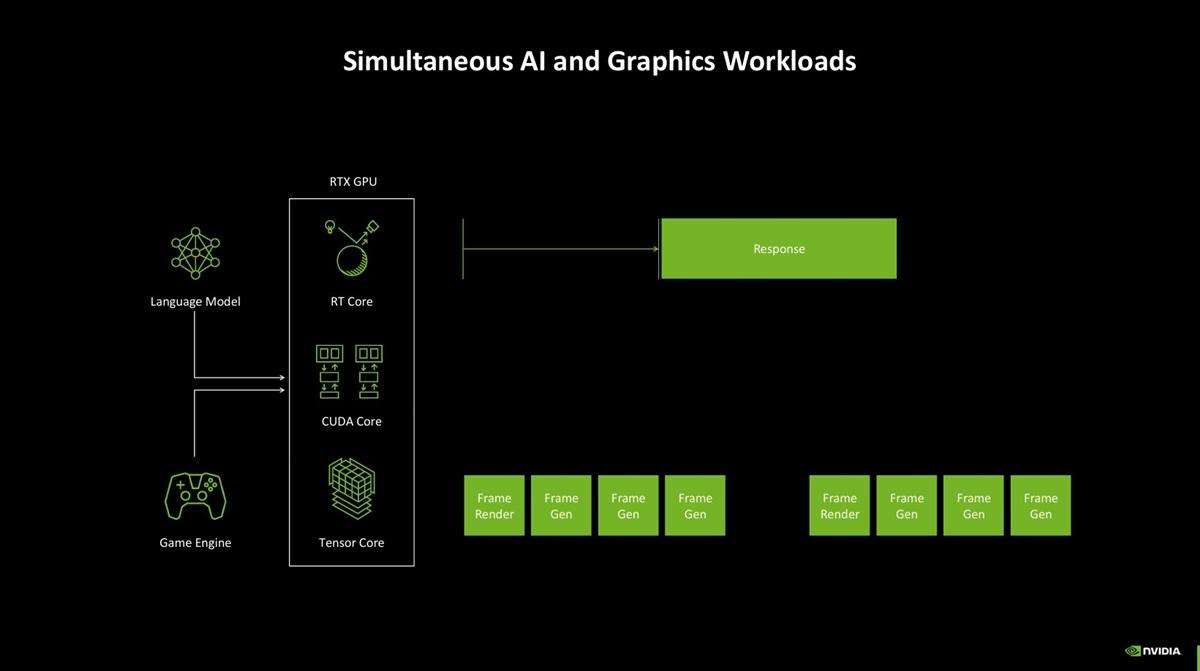
同时运作的话,llm的响应时间变慢,游戏帧率也会受影响
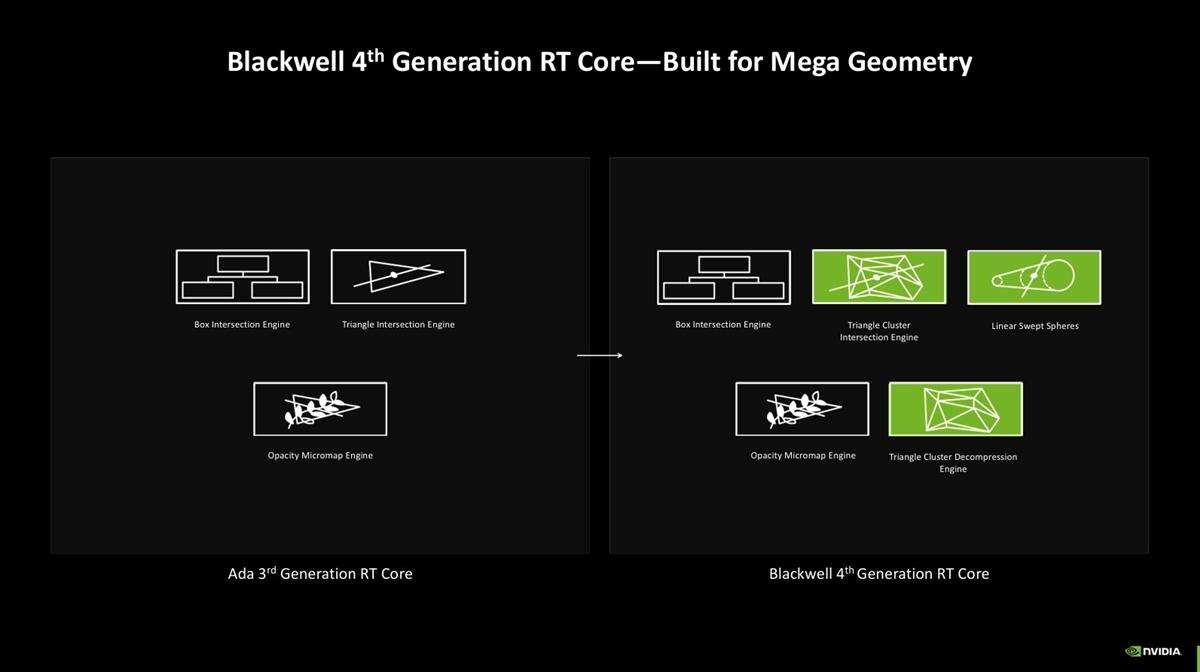
而第4代rt core中,新增的组件包括有triangle cluster intersection engine、triangle cluster compression engine以及linear swept spheres。同时,blackwell提供了两倍于上一代ada lovelace的ray-triangle交叉检测吞吐量。它们的出现,与mega geometry技术息息相关,起到一个打基础的作用。
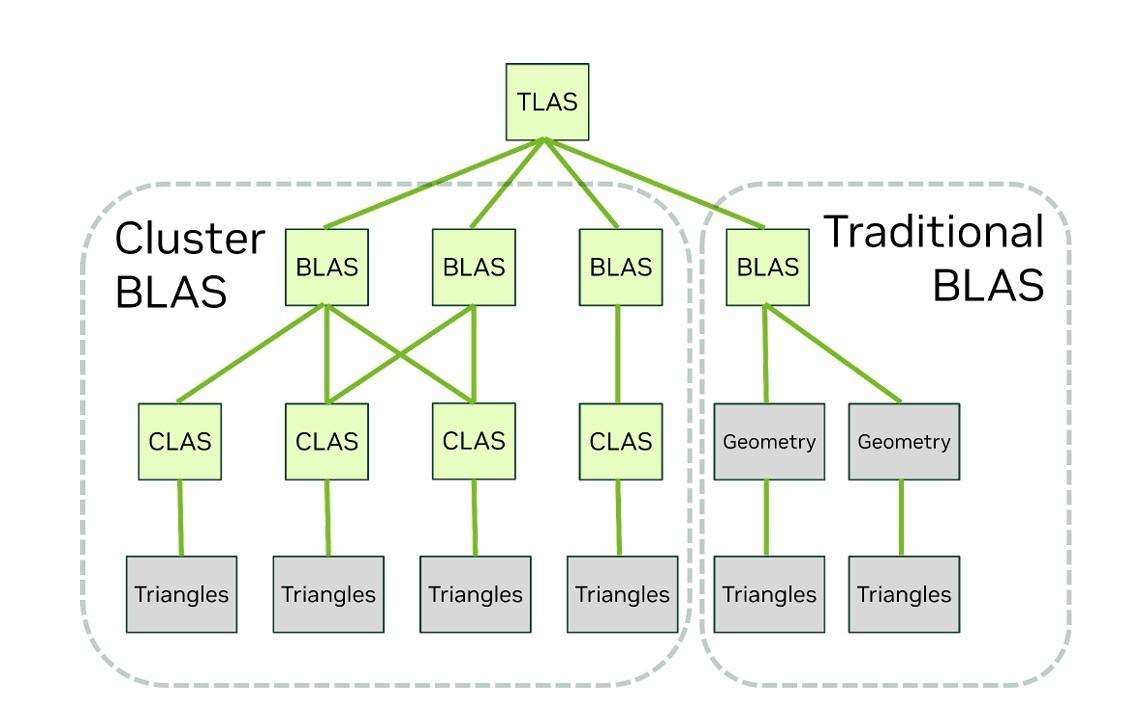
mega geometry是在tlas(顶层加速结构)和blas(底层加速结构)两个层级的架构上做改进。blas一侧的cluster-level acceleration structures(clas,簇级加速结构)最多能把256个三角形簇打包好,并将其作为bvh的基础部分输入,最后组成bvh树。同时,clas不仅能在游戏里面按需创建,还能缓存到硬盘里面,后面的帧要用的话直接从硬盘加载。这样一来,系统要处理的事情就少很多了。
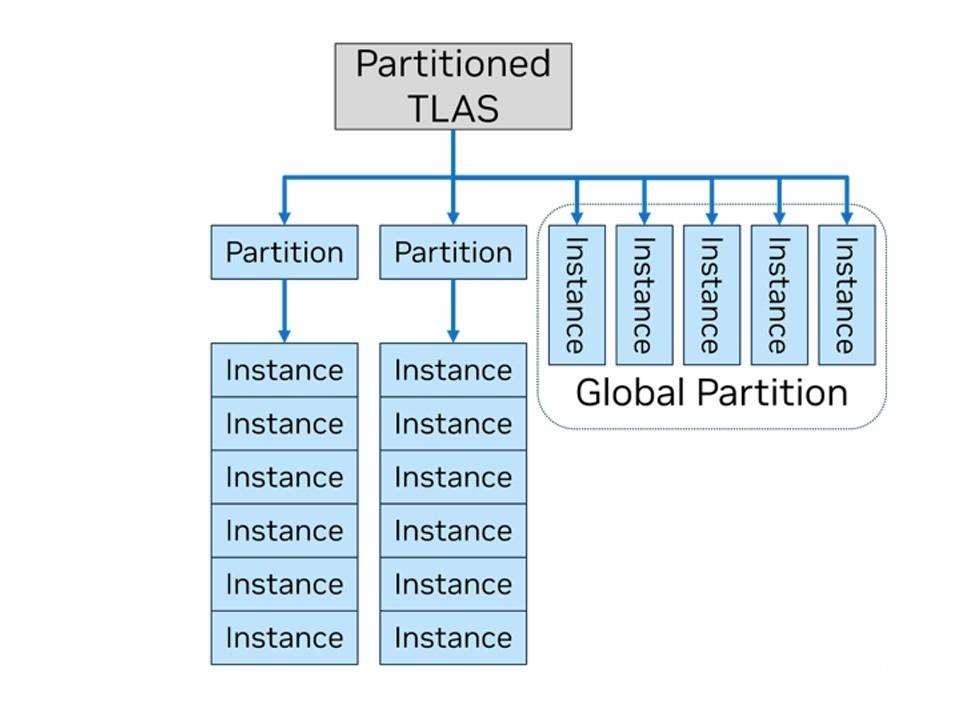
tlas还有个兄弟叫partitioned top-level acceleration structure(ptlas,分区顶层加速架构),是针对复杂场景设计的。nvidia表示,在很多游戏里面,场景内有不少物品比如建筑都是固定不变的,但是如果每一帧都要给它们构建一次tlas,肯定就不划算。而正如名称中的partitioned分区所示,ptlas把场景内的物体分成了多个区域,一些用来放置静态的物品,然后一个全局分区用于处理动态的物品,同样可以做到减轻了系统的压力,提高运算效率。
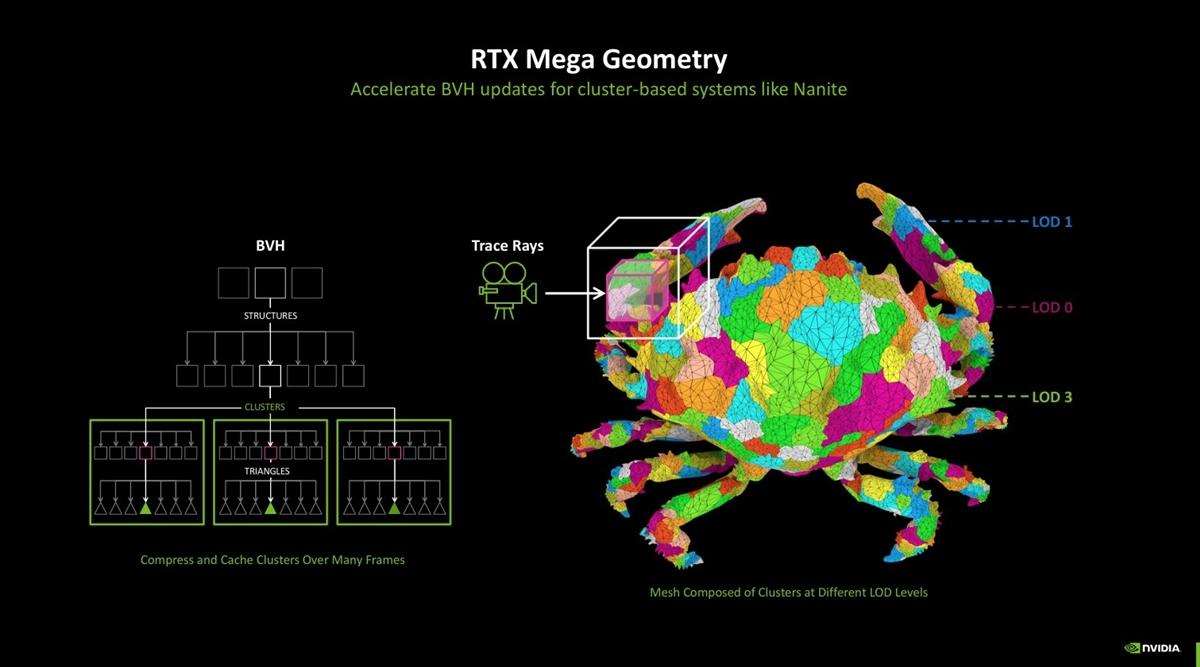
值得一提的是,所有rtx显卡都能支持mega geometry,但跟所有新技术一样,blackwell是目前支持最好的。
发表评论