1月7日,英伟达在ces 2025发布了备受期待的geforce rtx 50系列显卡,首发产品包括rtx 5090(d)、rtx 5080、rtx 5070ti和rtx 5070四个型号。geforce rtx 50系列显卡搭载了全新的blackwell架构,可以说是近年来变革最大的gpu架构,为我们带来了全新的sm单元流处理器、第四代rt core、第五代tensor core、gddr7显存等新特性,另外还有rtx神经网络着色器、dlss 4、reflex 2、transformer模型、多帧生成等新技术的诞生,可谓是重新定义了未来游戏发展的新方向,将ai技术纳入图形渲染的核心地位。


nvidia blackwell架构
sm单元
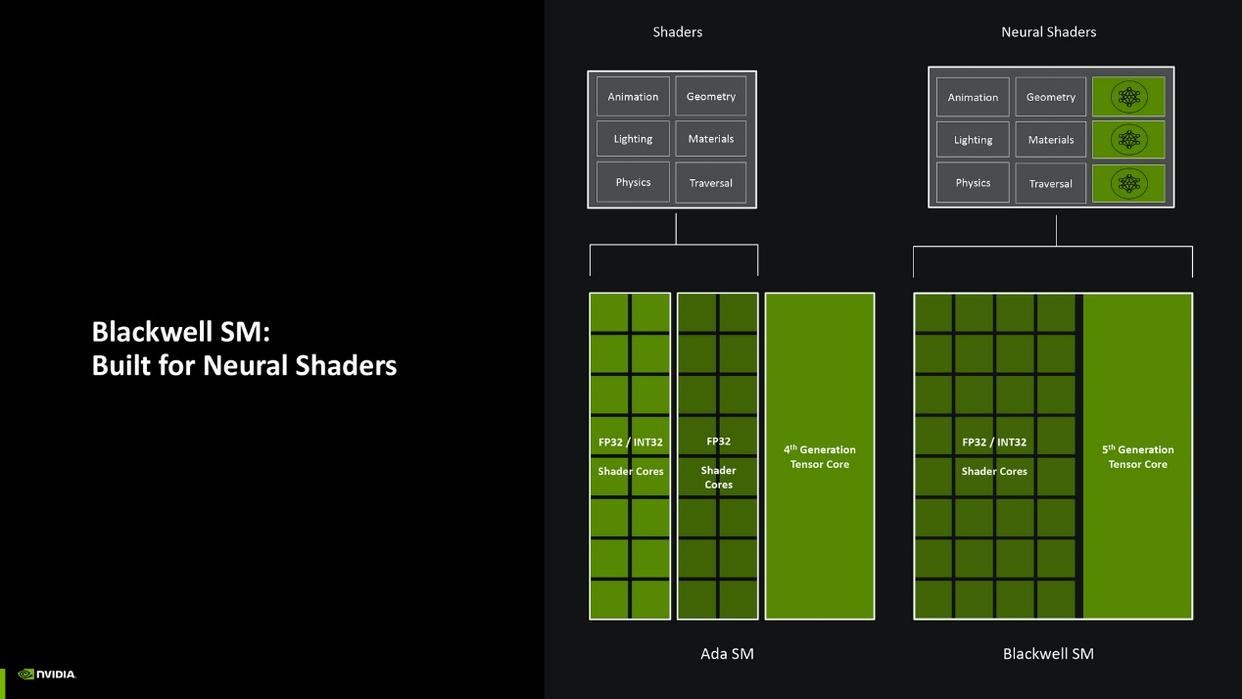
我们先来简单了解一下blackwell架构的变化。首先是sm单元,上代ada架构sm单元里的着色器核心有两种,一种能执行fp32运算,另一种能执行fp32或int32运算,运算能力更倾向于浮点运算。而blackwell则升级成了统一着色器核心,可按需执行fp32或int32运算,大幅度提高了着色器核心的整数运算能力,运算效率和调度也更为灵活。英伟达表示这种运算单元的改动是为了神经网络着色器而优化。
第五代tensor核心
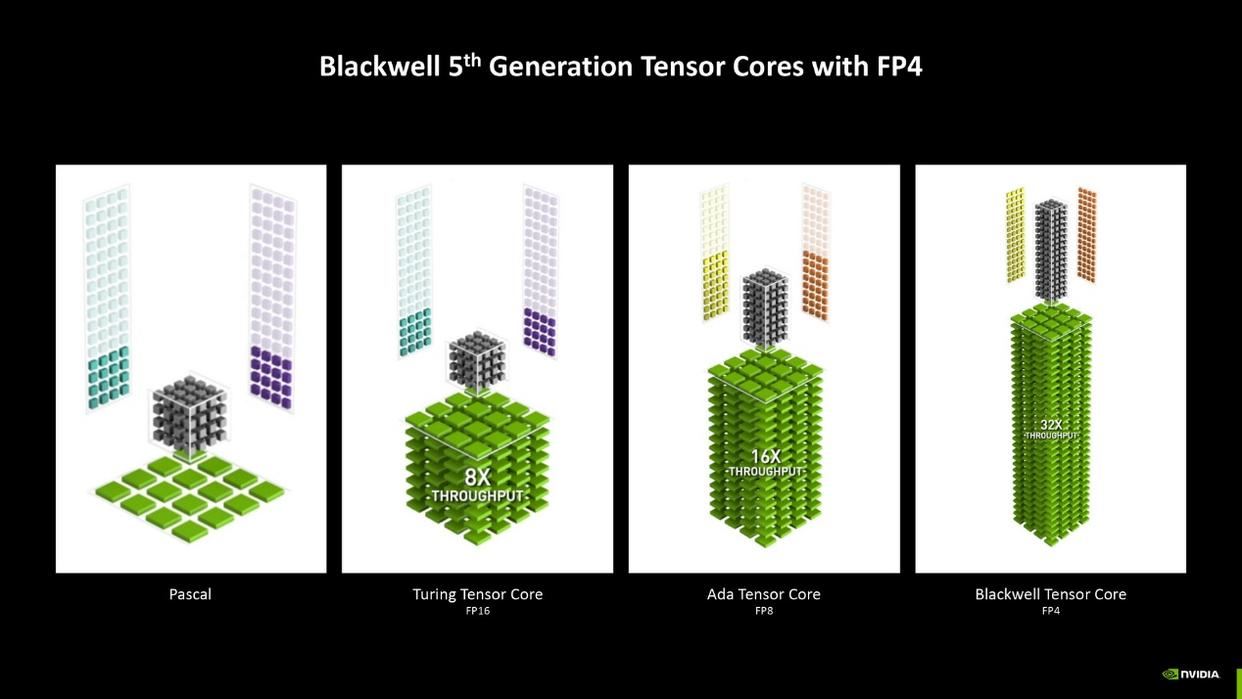
第五代tensor核心增加了对fp4精度的支持,相较于上代ada核心的fp8精度,fp4精度的运算吞吐量可提升2倍。模型精度越低对运算性能和空间的开销也就越低,低精度的量化可以减少模型的体积,降低对显存的要求,提高运算速度。而在端侧的推理运算大部分都采用低精度模型,偶有高精度模型也会通过量化操作来降低精度,所以更低精度的支持意味着显卡有更高的灵活度减少硬件的开销
第四代rt核心
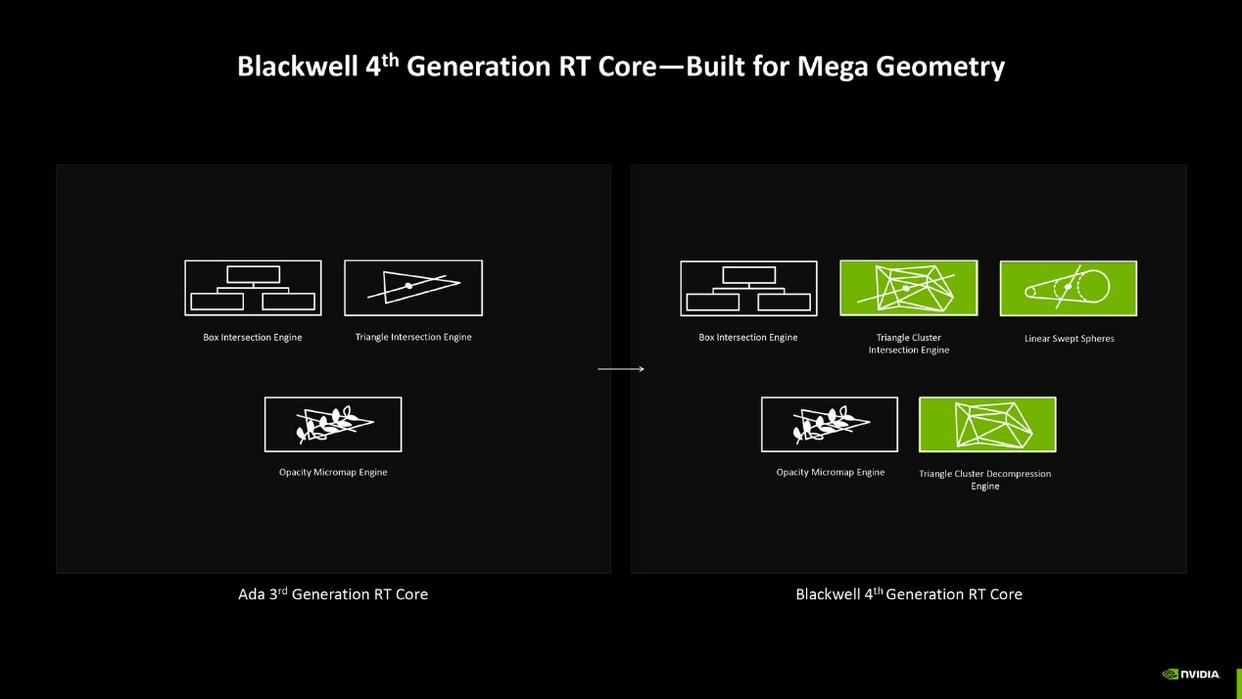
第四代rt核心继承了上代的 box intersection engine和opacity micromap engine,原有的triangle intersection engine升级为triangle cluster intersection engine,并新增triangle cluster decompression engine用以处理更大规模的三角形相交场景。另外还新增了 linear swept spheres用以处理毛发的光线碰撞,减少硬件开销。
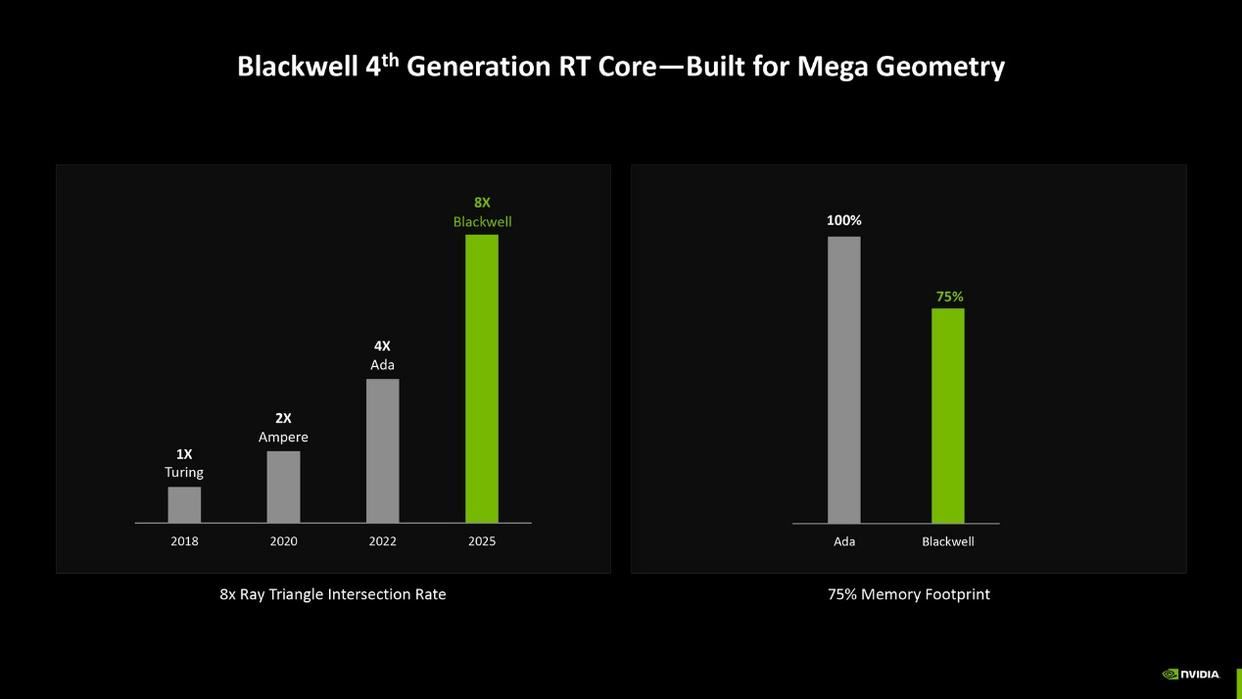
英伟达将其称为mega geometry,并表示其处理几何图形相交的能力要比ada架构提升2倍,显存开销降低25%。
gddr7显存
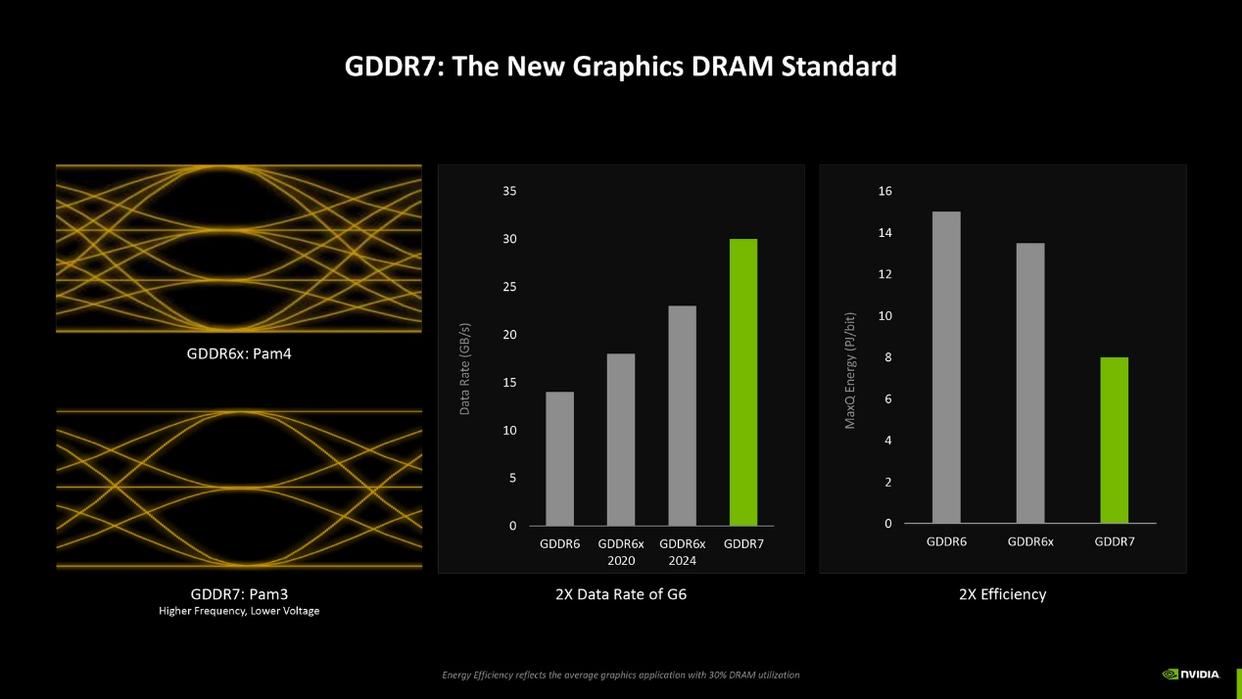
rtx 50系列显卡还搭载了gddr7显存,因为采用了pam3信号编码,数据速率可达gddr6的2倍,但功耗只需要gddr6的一半。
编解码功能
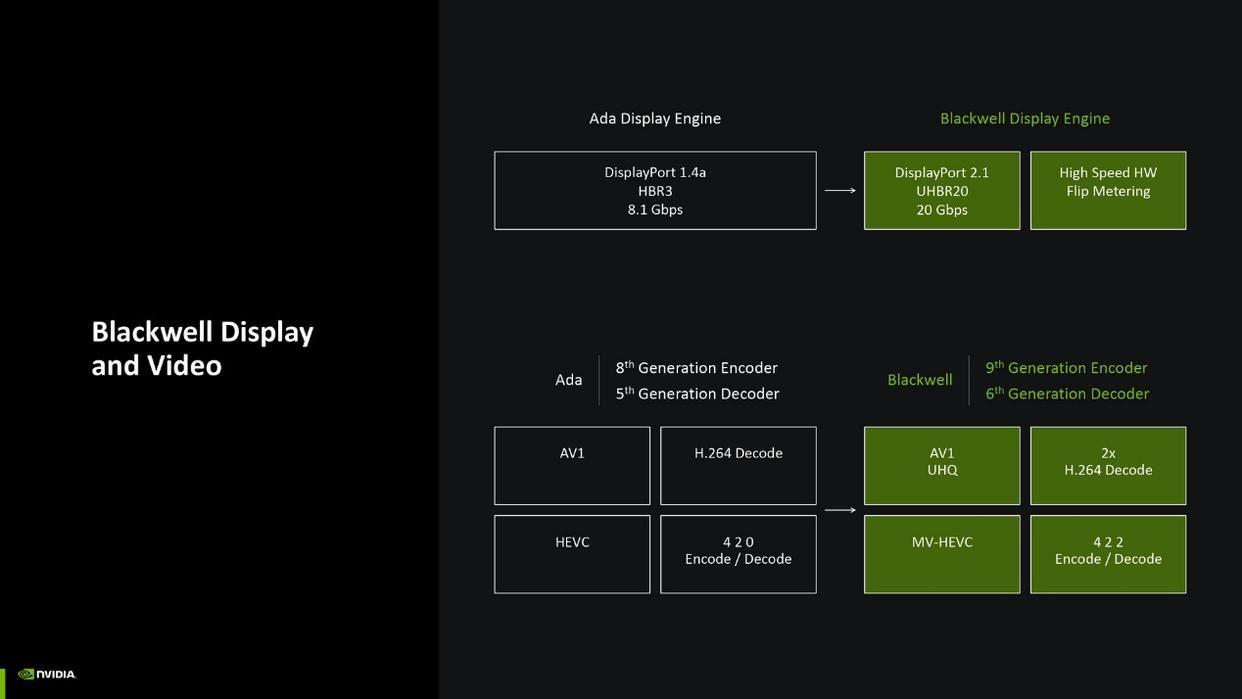
还有一个需要补充的是,blackwell架构终于支持displayport 2.1 uhbr 20模式,可以输出最高8k 165hz的画面,并且nvdec解码引擎升级到第九代,nvenc编码引擎升级到第六代,av1格式支持了uhq超高质量模式,hevc(h.265)格式支持到mv-hevc,色度空间支持更高规格4:2:2格式。
rtx神经网络着色器
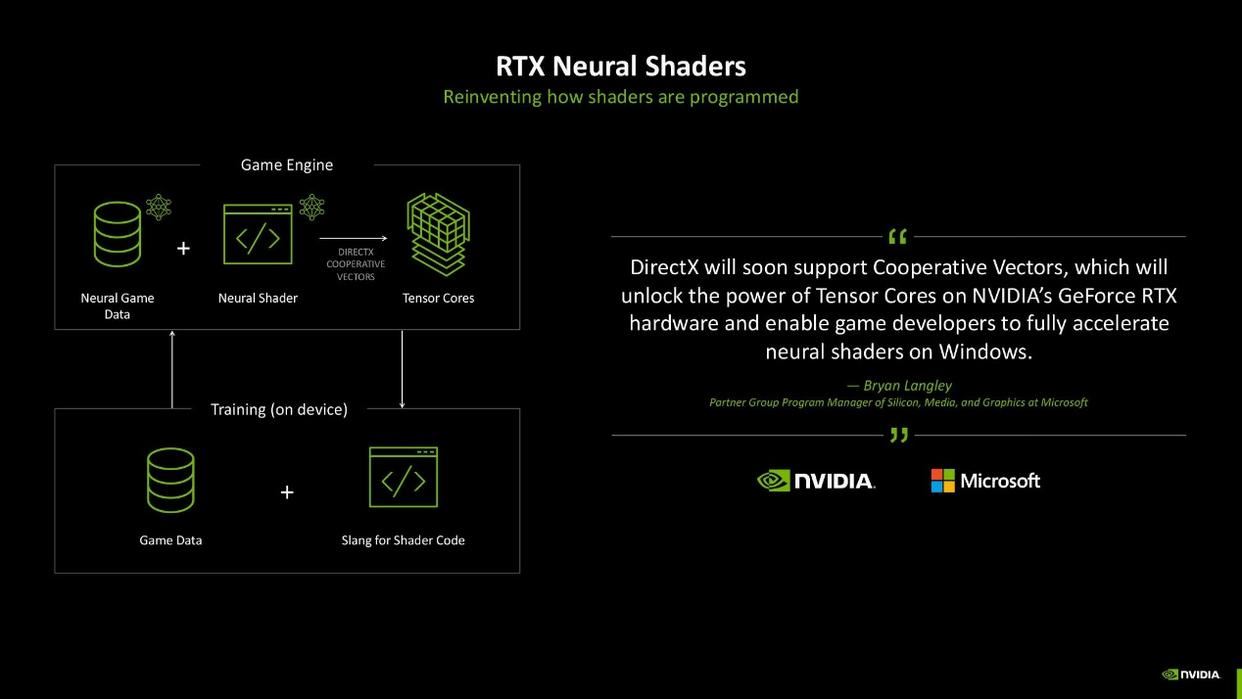
rtx神经网络着色器是一项颇具科幻色彩的技术,咋听之下似乎无法理解,但我们可以简单理解为它是一项借助ai训练来简化、压缩渲染流程和材质数据的技术。这其中又细分为神经网络纹理(neural textures)、神经网络材质(neural materials)、神经网络体积云(neural volumes)、神经网络辐射场(neural radiance fields)、神经网络辐射缓存(neural radiance cache)等5项技术。通过这项技术,开发者可以更高效、智能的完成开发过程,导出更匹配rtx的着色器数据。用户也可以以更低的硬件开销,获得更高质量的渲染画面,可谓是双赢的局面。
dlss4
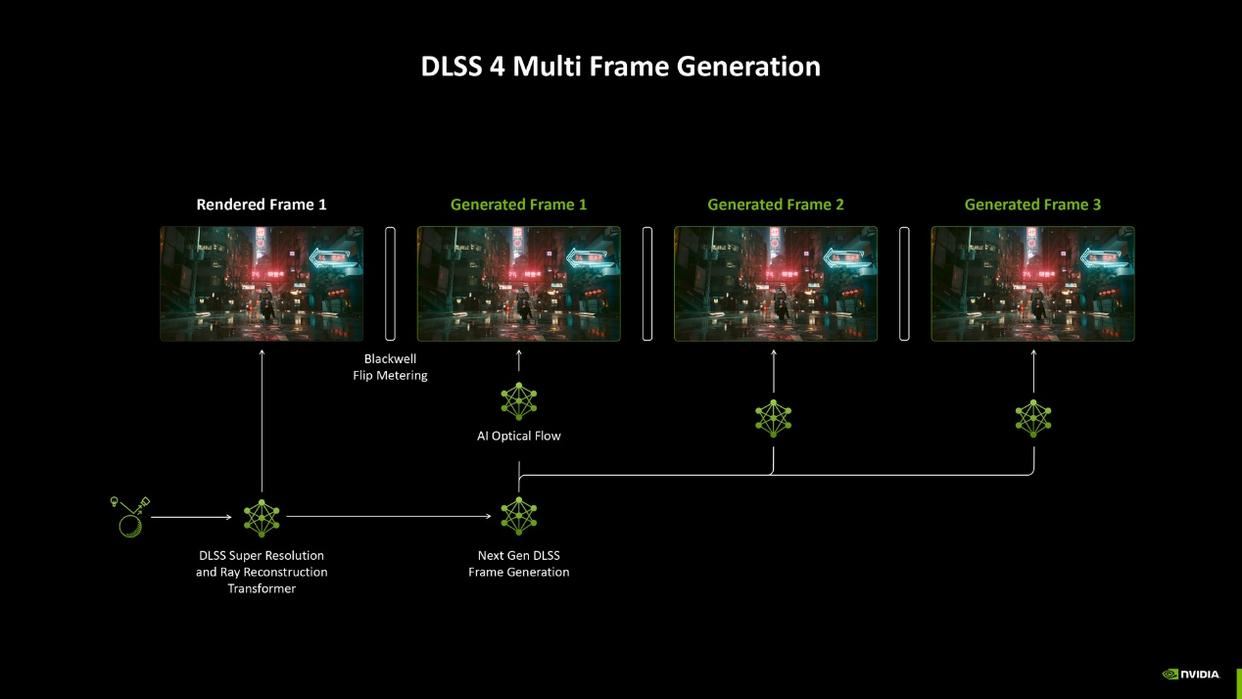

dlss 4迎来了自2019年dlss发布以来的最大革新:多帧生成技术(mfg)和transformer模型。dlss 3的帧生成技术是通过超采样和光线重构技术生成额外帧,并通过光流加速器插入原始帧中获得几乎翻倍的帧数提升。而dlss 4技术得益于第五代tensor核心的算力提升,可以在dlss 3的基础上再额外通过ai模型生成2帧画面。如此以来,配合超采样、光线重构、光流插针以及多帧生成模型,dlss4可以实现15/16的画面生成,实现最高8倍的帧数提升。除了多帧生成技术,dlss4还将原有的cnn卷积神经网络模型替换为transformer模型(可选),能够更好的处理自然语言和多头注意力权重,生成的画面会更稳定,鬼影和运动模糊等问题也会大幅度减少。
发表评论