一:背景
1. 讲故事
前段时间训练营里的一位朋友提了一个问题,我用readasync做文件异步读取时,我知道在win32层面会传 lpoverlapped 到内核层,那在内核层回头时,它是如何通过这个 lpoverlapped 寻找到 readasync 这个异步的task的呢?
这是一个好问题,这需要回答人对异步完整的运转流程有一个清晰的认识,即使有清晰的认识也不能很好的口头表述出来,就算表述出来对方也不一定能听懂,所以干脆开两篇文章来尝试解读一下吧。
二:lpoverlapped 如何映射
1. 测试案例
为了能够讲清楚,我们先用 filestream.readasync 方法来写一段异步读取来产生overlapped,参考代码如下:
static void main(string[] args)
{
useawaitasync();
console.readline();
}
static async task<string> useawaitasync()
{
string filepath = "d:\\dumps\\trace-1\\genhome.dmp";
console.writeline($"{datetime.now.tostring("yyyy-mm-dd hh:mm:ss:fff")} 请求发起...");
filestream filestream = new filestream(filepath, filemode.open, fileaccess.read, fileshare.read, buffersize: 16, useasync: true);
{
byte[] buffer = new byte[filestream.length];
int bytesread = await filestream.readasync(buffer, 0, buffer.length);
string content = encoding.utf8.getstring(buffer, 0, bytesread);
var query = $"{datetime.now.tostring("yyyy-mm-dd hh:mm:ss:fff")} 获取到结果:{content.length}";
console.writeline(query);
return query;
}
}很显然上面的方法会调用 win32 中的 readfile,接下来上一下它的签名和 _overlapped 结构体。
bool readfile(
[in] handle hfile,
[out] lpvoid lpbuffer,
[in] dword nnumberofbytestoread,
[out, optional] lpdword lpnumberofbytesread,
[in, out, optional] lpoverlapped lpoverlapped
);
typedef struct _overlapped {
ulong_ptr internal;
ulong_ptr internalhigh;
union {
struct {
dword offset;
dword offsethigh;
} dummystructname;
pvoid pointer;
} dummyunionname;
handle hevent;
} overlapped, *lpoverlapped;
2. 寻找映射的两端
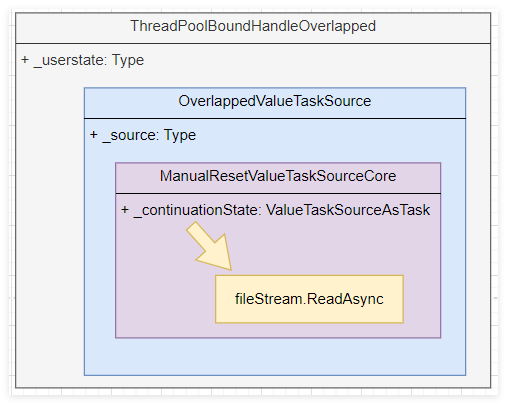
既然是映射嘛,肯定要找到两个端口,即非托管层的 nativeoverlapped 和 托管层的 threadpoolboundhandleoverlapped。
1.非托管 _overlapped
在 c# 中用 nativeoverlapped 结构体表示 win32 的 _overlapped 结构,参考如下:
public struct nativeoverlapped
{
public nint internallow;
public nint internalhigh;
public int offsetlow;
public int offsethigh;
public nint eventhandle;
}
2.托管 threadpoolboundhandleoverlapped
readasync 所产生的 task<int> 在底层是经过valuetask, overlappedvaluetasksource 一阵痉挛后弄出来的,最后会藏匿在 overlapped 子类的 threadpoolboundhandleoverlapped 中,参考代码和模型图如下:
public override task<int> readasync(byte[] buffer, int offset, int count, cancellationtoken cancellationtoken)
{
valuetask<int> valuetask = this.readasync(new memory<byte>(buffer, offset, count), cancellationtoken);
if (!valuetask.iscompletedsuccessfully)
{
return valuetask.astask();
}
return this._lastsynccompletedreadtask.gettask(valuetask.result);
}
private unsafe static valuetuple<safefilehandle.overlappedvaluetasksource, int> queueasyncreadfile(safefilehandle handle, memory<byte> buffer, long fileoffset, cancellationtoken cancellationtoken, osfilestreamstrategy strategy)
{
safefilehandle.overlappedvaluetasksource overlappedvaluetasksource = handle.getoverlappedvaluetasksource();
nativeoverlapped* ptr = overlappedvaluetasksource.prepareforoperation(buffer, fileoffset, strategy);
if (interop.kernel32.readfile(handle, (byte*)overlappedvaluetasksource._memoryhandle.pointer, buffer.length, intptr.zero, ptr) == 0)
{
overlappedvaluetasksource.registerforcancellation(cancellationtoken);
}
overlappedvaluetasksource.finishedscheduling();
return new valuetuple<safefilehandle.overlappedvaluetasksource, int>(overlappedvaluetasksource, -1);
}
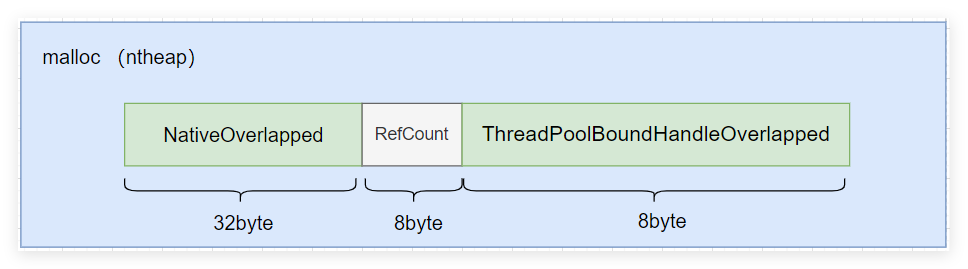
最后就是两端的映射关系了,先通过 malloc 分配了一块私有内存,中间隔了一个refcount 的 8byte大小,模型图如下:
3. 眼见为实
要想眼见为实,可以从c#源码中的overlapped.allocatenativeoverlapped方法寻找答案。
public unsafe class overlapped
{
private nativeoverlapped* allocatenativeoverlapped(object? userdata)
{
nativeoverlapped* pnativeoverlapped = null;
nuint handlecount = 1;
pnativeoverlapped = (nativeoverlapped*)nativememory.alloc((nuint)(sizeof(nativeoverlapped) + sizeof(nuint)) + handlecount * (nuint)sizeof(gchandle));
gchandlecountref(pnativeoverlapped) = 0;
pnativeoverlapped->internallow = default;
pnativeoverlapped->internalhigh = default;
pnativeoverlapped->offsetlow = _offsetlow;
pnativeoverlapped->offsethigh = _offsethigh;
pnativeoverlapped->eventhandle = _eventhandle;
gchandleref(pnativeoverlapped, 0) = gchandle.alloc(this);
gchandlecountref(pnativeoverlapped)++;
return pret;
}
private static ref nuint gchandlecountref(nativeoverlapped* pnativeoverlapped)
=> ref *(nuint*)(pnativeoverlapped + 1);
private static ref gchandle gchandleref(nativeoverlapped* pnativeoverlapped, nuint index)
=> ref *((gchandle*)((nuint*)(pnativeoverlapped + 1) + 1) + index);
}卦中代码先用 nativememory.alloc 方法分配了一块私有内存,随后还把 overlapped 给 gchandle.alloc 住了,这是防止异步期间对象被移动,有了代码接下来上windbg去眼见为实,在 kernel32!readfile 中下断点观察方法的第五个参数。
0:000> bp kernel32!readfile
0:000> g
breakpoint 0 hit
kernel32!readfile:
00007ffd`fa2f56a0 ff25caca0500 jmp qword ptr [kernel32!_imp_readfile (00007ffd`fa352170)] ds:00007ffd`fa352170={kernelbase!readfile (00007ffd`f85c5520)}
0:000> k 5
# child-sp retaddr call site
00 000000ff`8837e1c8 00007ffd`96229ce3 kernel32!readfile
01 000000ff`8837e1d0 00007ffd`96411a4a system_private_corelib!interop.kernel32.readfile+0xa3 [/_/src/coreclr/system.private.corelib/microsoft.interop.libraryimportgenerator/microsoft.interop.libraryimportgenerator/libraryimports.g.cs @ 6797]
02 000000ff`8837e2d0 00007ffd`96411942 system_private_corelib!system.io.randomaccess.queueasyncreadfile+0x8a
03 000000ff`8837e350 00007ffd`96433677 system_private_corelib!system.io.randomaccess.readatoffsetasync+0x112 [/_/src/libraries/system.private.corelib/src/system/io/randomaccess.windows.cs @ 238]
04 000000ff`8837e3f0 00007ffd`9642d5f8 system_private_corelib!system.io.strategies.osfilestreamstrategy.readasync+0xb7 [/_/src/libraries/system.private.corelib/src/system/io/strategies/osfilestreamstrategy.cs @ 290]
0:000> uf 00007ffd`96229ce3
...
6797 00007ffd`96229c98 4c8b7d30 mov r15,qword ptr [rbp+30h]
6797 00007ffd`96229c9c 4c897c2420 mov qword ptr [rsp+20h],r15
6797 00007ffd`96229ca1 498bce mov rcx,r14
6797 00007ffd`96229ca4 48894dac mov qword ptr [rbp-54h],rcx
6797 00007ffd`96229ca8 488bd3 mov rdx,rbx
6797 00007ffd`96229cab 488955a4 mov qword ptr [rbp-5ch],rdx
6797 00007ffd`96229caf 448bc6 mov r8d,esi
6797 00007ffd`96229cb2 448945b4 mov dword ptr [rbp-4ch],r8d
6797 00007ffd`96229cb6 4c8bcf mov r9,rdi
6797 00007ffd`96229cb9 4c894d9c mov qword ptr [rbp-64h],r9
6797 00007ffd`96229cbd 488d8d40ffffff lea rcx,[rbp-0c0h]
6797 00007ffd`96229cc4 ff159e909e00 call qword ptr [system_private_corelib!interop.callstringmethod+0x5ab9c8 (00007ffd`96c12d68)]
6797 00007ffd`96229cca 488b055708a100 mov rax,qword ptr [system_private_corelib!interop.callstringmethod+0x5d3188 (00007ffd`96c3a528)]
6797 00007ffd`96229cd1 488b4dac mov rcx,qword ptr [rbp-54h]
6797 00007ffd`96229cd5 488b55a4 mov rdx,qword ptr [rbp-5ch]
6797 00007ffd`96229cd9 448b45b4 mov r8d,dword ptr [rbp-4ch]
6797 00007ffd`96229cdd 4c8b4d9c mov r9,qword ptr [rbp-64h]
6797 00007ffd`96229ce1 ff10 call qword ptr [rax]
6797 00007ffd`96229ce3 8bd8 mov ebx,eax
仔细阅读卦中的汇编代码,通过这句 r15,qword ptr [rbp+30h] 可知 pnativeoverlapped 是保存在 r15 寄存器中。
0:000> r r15
r15=00000241ca2d4d70
0:000> dp 00000241ca2d4d70
00000241`ca2d4d70 00000000`00000000 00000000`00000000
00000241`ca2d4d80 00000000`00000000 00000000`00000000
00000241`ca2d4d90 00000000`00000001 00000241`c8761358
根据上面的模型图,00000241ca2d4d90 保存的是引用计数,00000241c8761358 就是我们的 threadpoolboundhandleoverlapped ,可以 !do 它一下便知。
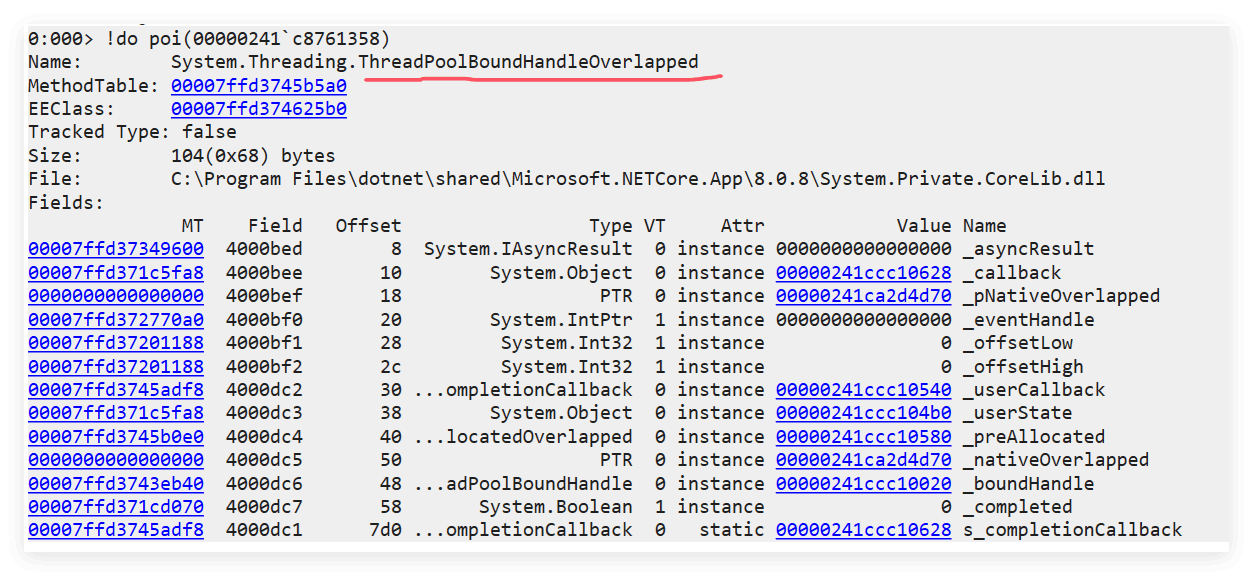
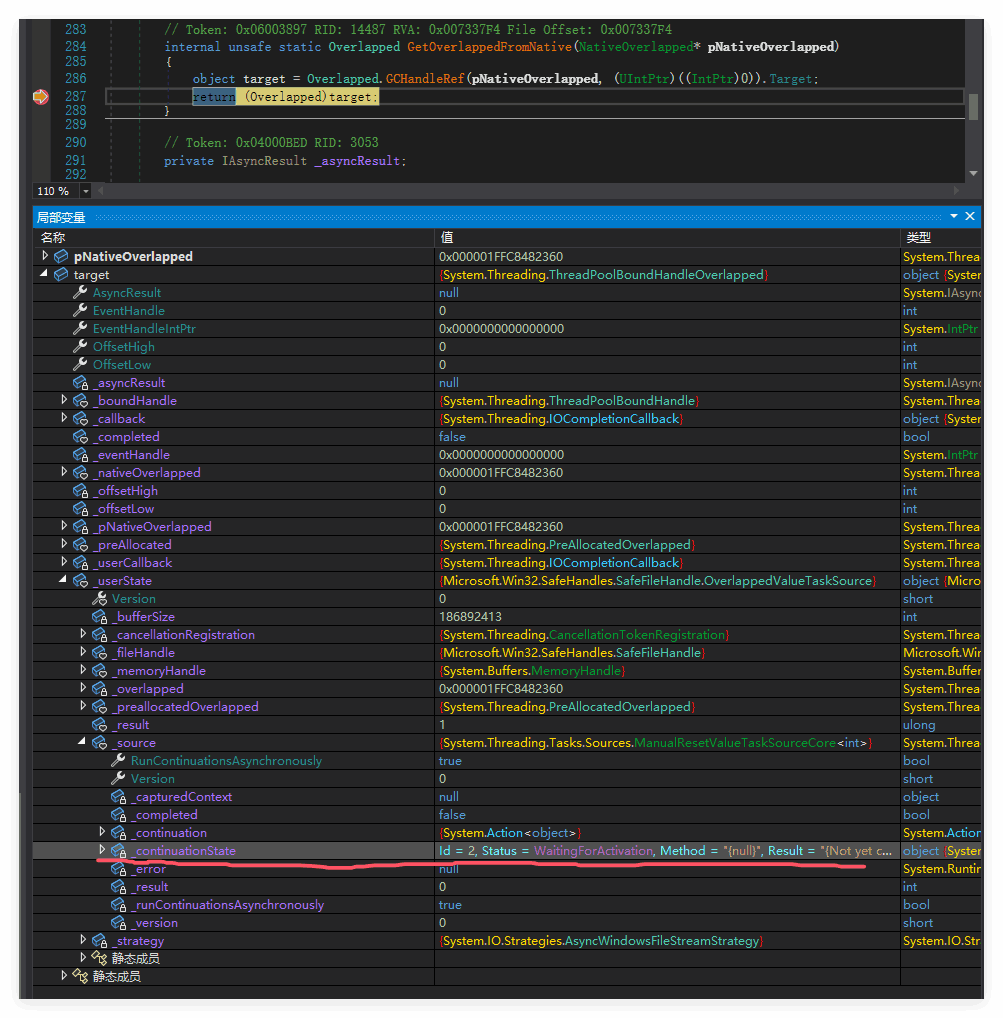
最后用 dnspy 在 overlapped.getoverlappedfromnative 方法中下一个断点,这个方法会在异步处理完成后,执行nativeoverlapped寻址threadpoolboundhandleoverlapped 的逻辑,截图如下,那个 readasync保存在内部的 _continuationstate 字段里。
三:总结
c#的传统做法大多都是采用传参数的方式来建议映射关系,而本篇中用 malloc 开辟一块私有区域来映射两者的关系也真是独一份,实属无奈!
到此这篇关于浅析c#异步中的overlapped是如何寻址的的文章就介绍到这了,更多相关c#异步overlapped如何寻址内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!




发表评论