
🐇明明跟你说过:
🏅个人专栏:《数据流专家:kafka探索》🏅
🔖行路有良友,便是天堂🔖
目录
2、pods、services、deployments等基本概念
一、引言
1、kafka简介
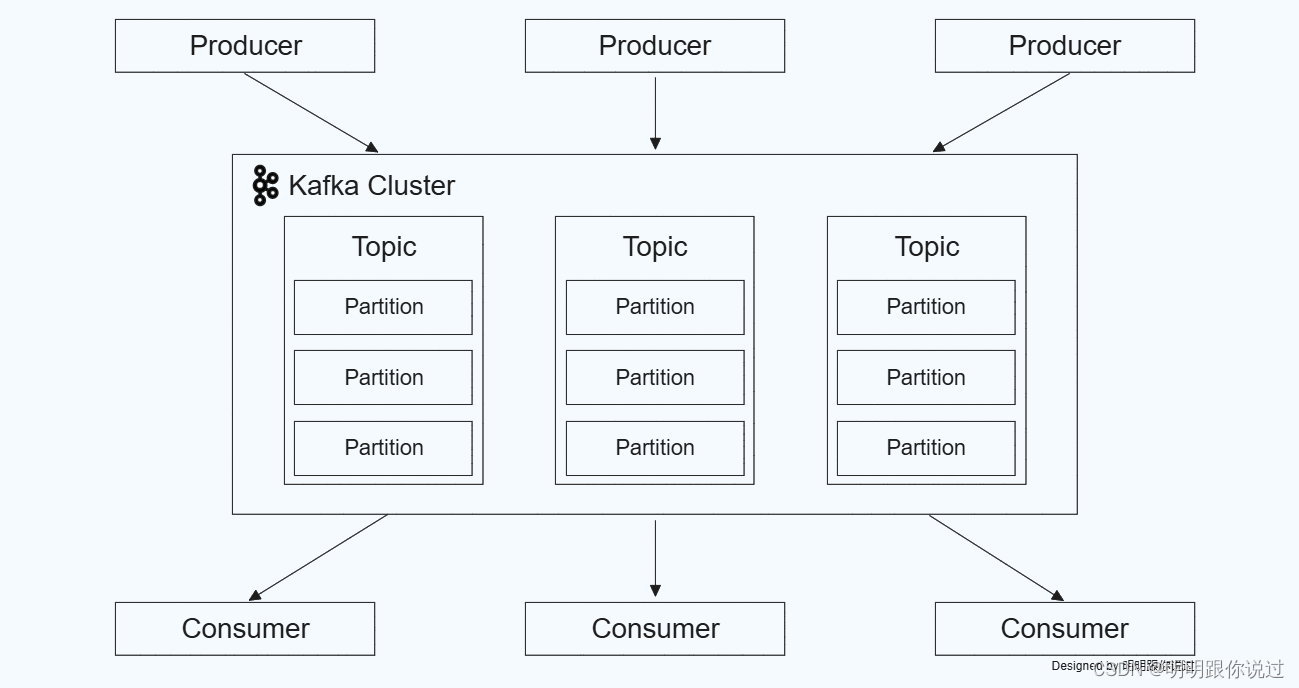
kafka的核心概念
1. producer(生产者):
- 生产者是向kafka主题(topic)发送消息的应用程序。它们负责将数据推送到kafka集群。
2. consumer(消费者):
- 消费者是从kafka主题中读取消息的应用程序。它们可以是单个消费者或消费者组(consumer group),每个消费者组中的消费者可以并行地读取数据。
3. topic(主题):
- 主题是kafka中的一个逻辑分类,用于将消息进行分组。每个主题可以细分为多个分区(partition),每个分区内的消息是有序的,但不同分区之间没有顺序保证。
4. partition(分区):
- 分区是主题的一个子单元,每个分区可以存储大量消息,并且每个分区可以被多个消费者读取。分区使得kafka能够水平扩展。
5. broker(代理):
- broker是kafka集群中的一个服务器节点,负责接收、存储和发送消息。一个kafka集群可以包含多个broker,以提供高可用性和容错能力。
6. zookeeper:
- kafka使用zookeeper来进行分布式协调和管理集群状态。zookeeper负责维护配置信息、分区的leader选举以及消费组的offset管理等。
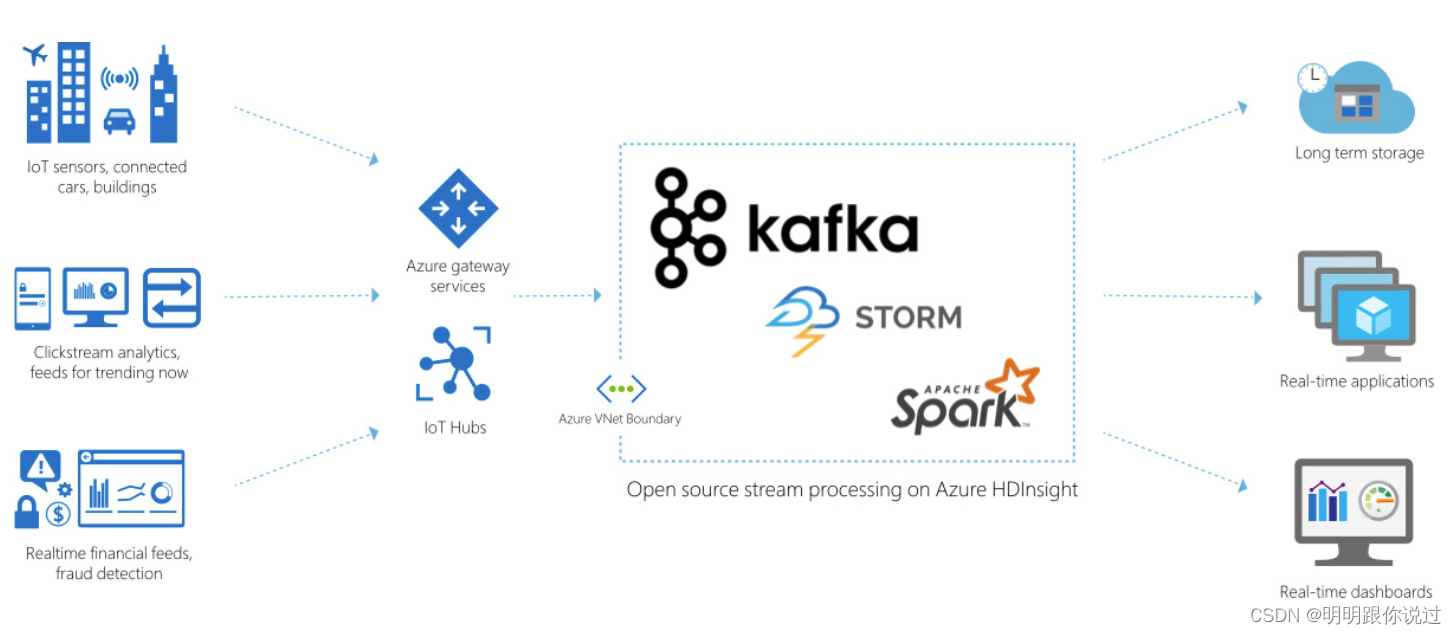
kafka的主要功能
1. 消息持久化:
- kafka将消息持久化到磁盘,并且允许设置保留策略,确保数据的可靠性。
2. 高吞吐量:
- kafka能够处理高吞吐量的数据流,适合处理大规模的数据流应用。
3. 低延迟:
- kafka的设计优化了数据传输路径,使得消息传输具有低延迟。
4. 扩展性:
- kafka的分区机制允许在集群中增加更多的broker和分区,从而实现水平扩展。
5. 容错性:
- 通过复制机制,kafka确保了数据的高可用性,即使个别节点故障,数据仍然能够恢复。

kafka的应用场景
1. 日志收集和聚合:
- 作为一种高效的日志收集系统,kafka可以收集和聚合分布式系统的日志数据。
2. 实时数据流处理:
- kafka与流处理框架(如apache flink、apache storm等)结合,可以进行实时数据分析和处理。
3. 消息队列:
- kafka可以充当高吞吐量的消息队列系统,用于不同应用程序之间的解耦和异步通信。
4. 事件源:
- kafka可以用作事件源系统,捕获和存储所有变化事件,以便后续处理和回放。
2、为什么在kubernetes中部署kafka
- 弹性和可伸缩性:kubernetes提供了强大的自动伸缩和调度功能,可以根据负载情况自动扩展kafka集群的节点数量,以满足不同工作负载的需求。这种弹性能力使得kafka能够更好地应对数据量的变化和突发性负载。
- 易于管理:kubernetes提供了统一的管理接口和工具,简化了kafka集群的部署、扩展、更新和监控。通过kubernetes的控制面板,管理员可以轻松地管理kafka集群的生命周期,而无需深入了解底层的部署细节。
- 高可用性:kubernetes具有自动故障检测和恢复机制,可以在节点故障时自动重新调度kafka的副本,确保数据的高可用性和持久性。
- 资源隔离:通过kubernetes的命名空间和资源限制功能,可以实现kafka集群与其他应用程序之间的资源隔离,避免因资源竞争导致的性能问题。

![]() 编辑
编辑
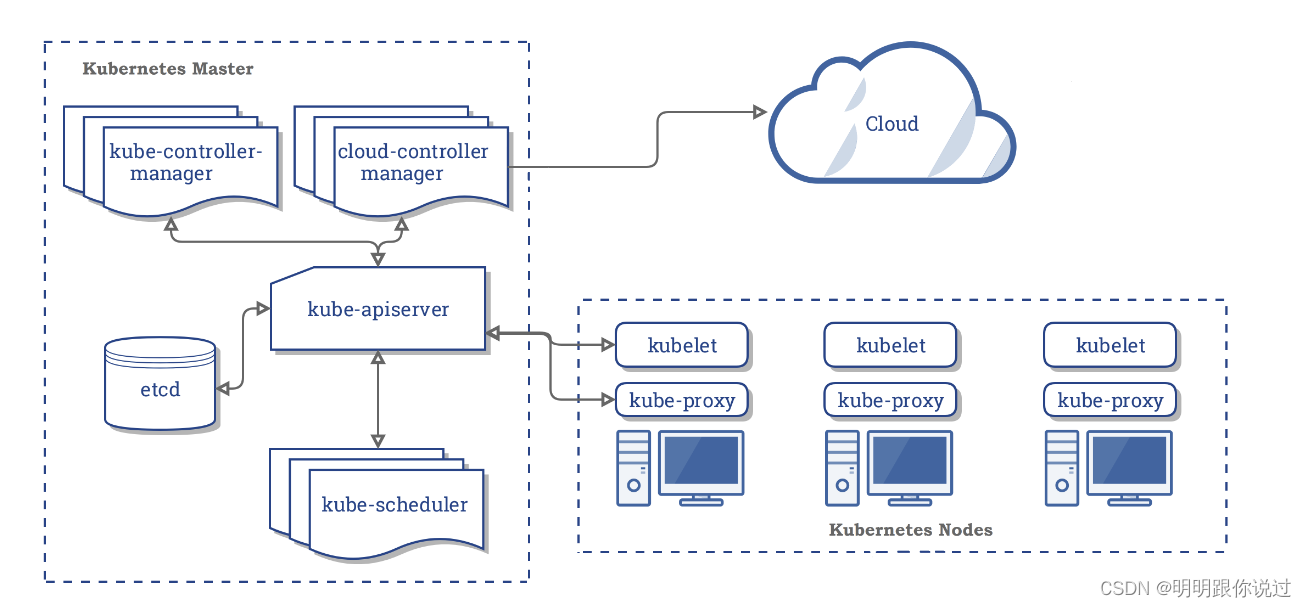
二、kubernetes基础
1、kubernetes概述
kubernetes的主要功能
1. 自动化部署和扩展:
- kubernetes提供了丰富的调度和自动伸缩功能,可以根据负载情况自动调度和扩展应用程序的副本数量,以适应不同的工作负载需求。
2. 服务发现和负载均衡:
- kubernetes通过service对象提供了统一的服务发现和负载均衡功能,使得应用程序可以通过简单的域名访问其他服务,并自动实现负载均衡。
3. 存储管理:
- kubernetes支持多种存储后端和存储卷类型,可以为应用程序提供持久化存储和共享存储功能,如persistentvolume、persistentvolumeclaim等。
4. 自我修复:
- kubernetes具有自我修复和健康检查机制,可以监控容器和节点的健康状态,并在出现故障时自动进行修复和恢复。
2、pods、services、deployments等基本概念
1. pods(容器组)
pod是kubernetes中最小的可部署单元,它可以包含一个或多个紧密相关的容器。这些容器共享相同的网络命名空间和存储卷,并且通常在同一节点上运行。pod提供了一种逻辑主机的概念,使得容器之间可以共享资源和通信。pod通常用于部署一个应用程序的一组相关容器。
2. services(服务)
服务是kubernetes中一种抽象,用于定义一组pod的逻辑集合,并为它们提供统一的访问入口。服务通过标签选择器(selector)将请求路由到对应的pod,并实现负载均衡和服务发现功能。kubernetes支持多种类型的服务,如clusterip、nodeport、loadbalancer和externalname。
3. deployments(部署)
部署是kubernetes中用于管理pod副本数量和应用程序版本更新的对象。部署定义了应用程序的期望状态,包括所需的副本数量、容器镜像和其他配置信息。部署控制器负责根据部署的定义创建、更新和删除pod实例,同时提供滚动更新和回滚的功能。
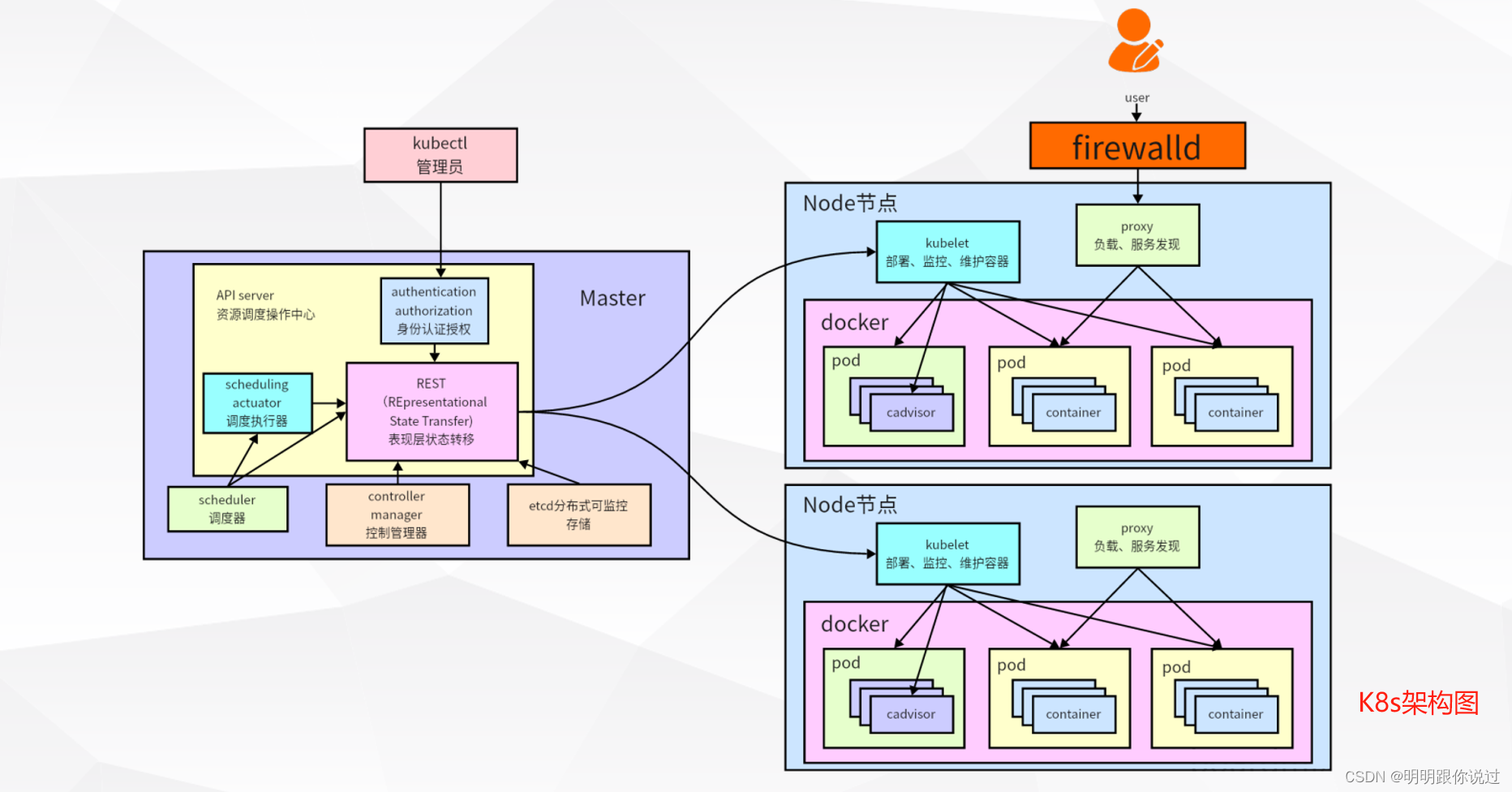
三、kafka集群架构
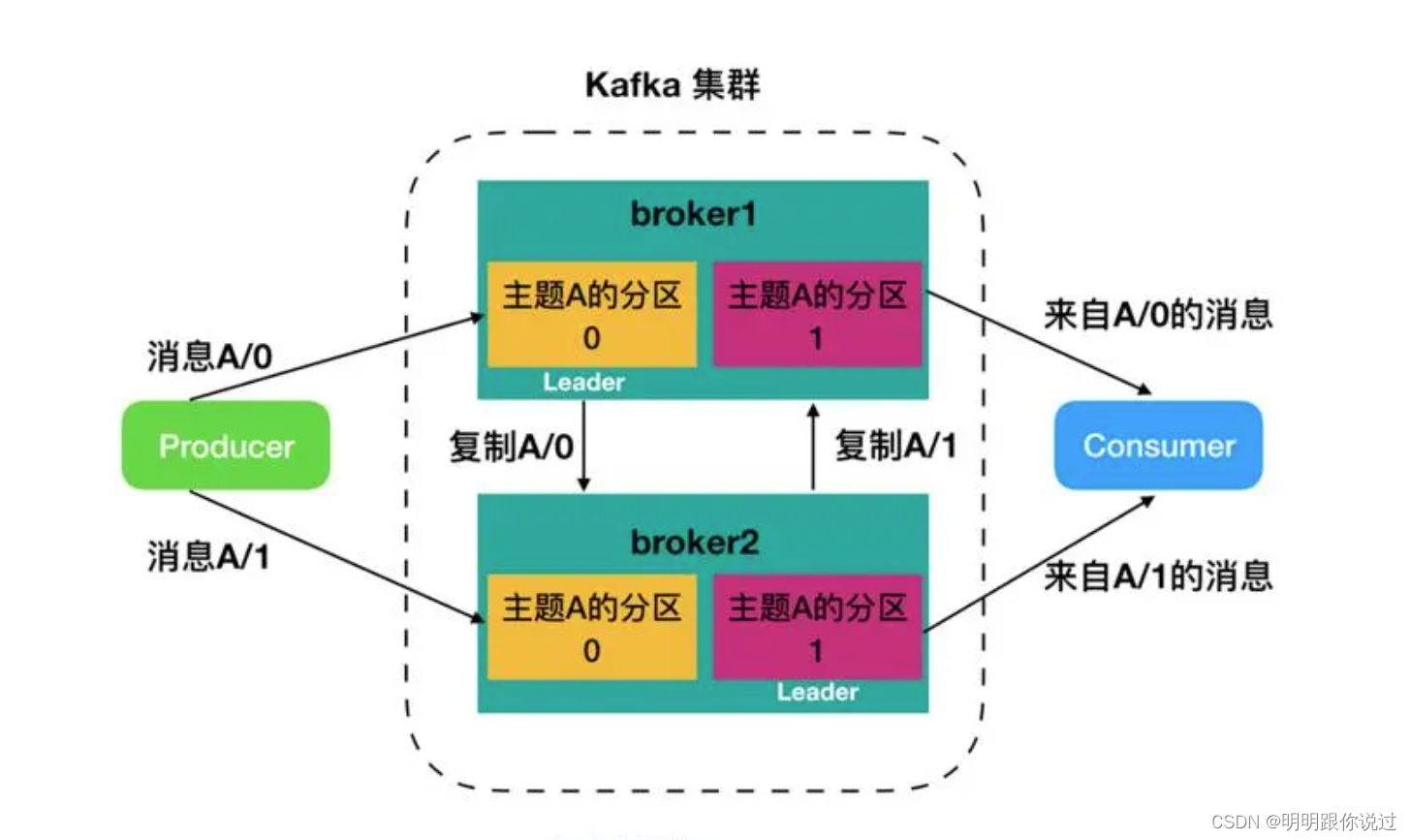
1、kafka集群的组成与工作原理
工作原理
1. 消息存储:
- 生产者将消息发布到主题,并根据主题的分区策略选择将消息存储到对应的分区中。每个分区的消息按顺序存储,并根据消息的偏移量(offset)进行标识。
2. 消息复制:
- kafka通过副本集机制实现数据的高可用性和持久性。每个分区都有一个主副本(leader replica)和多个副本(follower replica),主副本负责处理读写请求,而副本用于备份数据。当主副本故障时,kafka会自动选举一个新的主副本来接管工作。
3. 消息传输:
- 生产者将消息发送到broker的主副本,broker负责将消息复制到副本并进行持久化存储。消费者从broker的主副本拉取消息进行处理,可以选择从不同的副本读取消息以实现负载均衡和故障恢复。
4. 消息保留策略:
- kafka支持设置消息的保留策略,包括基于时间、基于大小或基于日志段的策略。一旦消息达到保留期限或超过指定的大小限制,kafka将自动删除过期消息,以释放存储空间。
2、kafka集群的高可用性设计
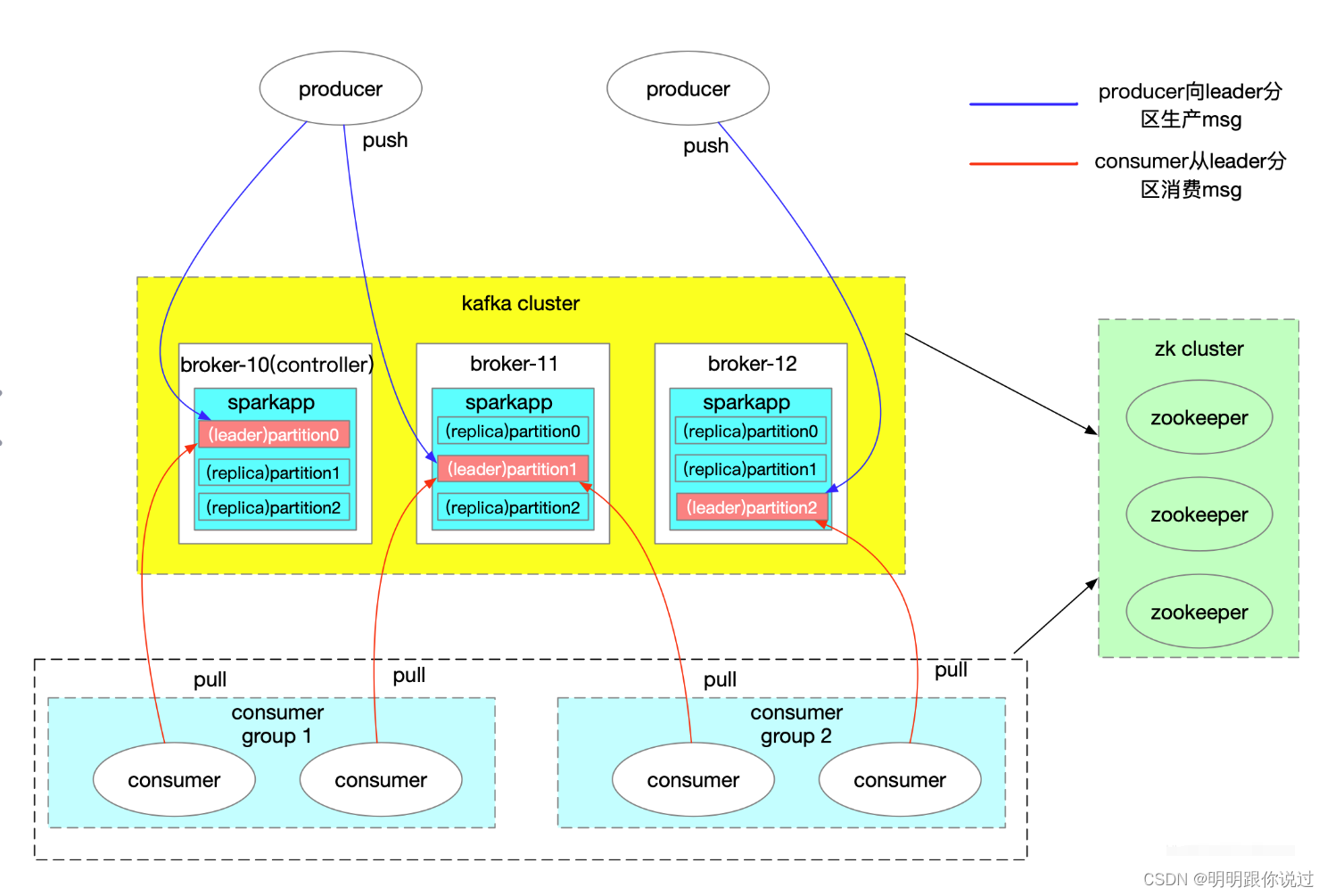
1. 多副本复制
- kafka通过在多个broker之间复制分区的副本来实现数据的冗余和高可用性。每个分区通常有多个副本,其中一个是主副本(leader replica),负责处理读写请求;其他副本是从副本(follower replica),用于备份数据。当主副本发生故障时,kafka会自动选举一个新的主副本来接管工作,确保数据的可用性和一致性。
2. 自动故障检测与恢复
- kafka集群内置了自动故障检测和恢复机制,可以监控broker和分区的健康状态,并在发现故障时自动进行故障转移和数据恢复。当broker或分区发生故障时,kafka会触发重新选举过程,选举出新的主副本并将数据复制到新的副本中,以实现快速的故障恢复。
3. 副本分布和均衡
- kafka会将分区的副本分布在不同的broker上,以确保数据的冗余和均衡。通过将副本分布在不同的机架、数据中心或云区域中,可以提高系统的容错能力,即使整个机架或数据中心发生故障,系统仍然能够继续运行。
4. 水平扩展和动态伸缩
- kafka支持水平扩展和动态伸缩,可以根据负载情况和性能需求来增加或减少broker的数量和容量。通过添加更多的broker和分区,可以提高系统的吞吐量和容量,同时降低单点故障的风险,实现更高的可用性和可伸缩性。
四、准备部署环境
1、准备k8s集群
这里我们使用的k8s集群版本为 1.23,也可以使用其他的版本,只是镜像导入命令不通,如果还未搭建k8s集群,请参考《在centos中搭建 k8s 1.23 集群超详细讲解》这篇文章
2、准备storageclass
因为我们要对kafka中的数据进行持久化,避免pod漂移后数据丢失,保证数据的完整性与可用性
如果还未创建存储类,请参考《k8s 存储类(storageclass)创建与动态生成pv解析,(附带镜像)》这篇文件。

3、准备部署kafka集群所需的镜像
在k8s node节点上执行以下命令
[root@node1 ~]# docker pull zookeeper:3.8
[root@node1 ~]# docker pull kafka:3.1.0
[root@node2 ~]# docker pull zookeeper:3.8
[root@node2 ~]# docker pull kafka:3.1.0
[root@node3 ~]# docker pull zookeeper:3.8
[root@node3 ~]# docker pull kafka:3.1.0五、部署kafka集群
1、部署zookeeper集群
为什么部署kafka前要部署zookeeper?
kafka依赖zookeeper来实现分布式协调和配置管理。在kafka集群中,zookeeper扮演着多种角色,包括:
- 配置管理:kafka集群的配置信息和元数据存储在zookeeper中,包括主题(topics)、分区(partitions)、副本(replicas)等配置信息。
- leader选举:kafka的分区(partitions)被分布式存储在集群中的多个broker上,每个分区都有一个leader和多个follower。zookeeper负责leader选举,确保每个分区都有一个活跃的leader。
- broker注册:kafka broker在启动时会向zookeeper注册自己的信息,包括地址、id等,以便其他broker和客户端发现和连接。
- 健康监测:zookeeper监控kafka集群中各个节点的健康状态,并在节点出现故障或宕机时触发相应的处理操作。
因此,在部署kafka之前,需要先部署zookeeper,确保kafka集群正常运行所需的分布式协调和配置管理功能可用。没有zookeeper,kafka无法正常运行,并且无法实现高可用性、数据一致性和故障容错等特性。

编写部署zookeeper集群的yaml文件
[root@master ~]# vim zook.yaml
# 添加如下内容
apiversion: v1
kind: namespace
metadata:
name: kafka
---
apiversion: v1
kind: service
metadata:
name: zookeeper-cluster #无头服务的名称,需要通过这个获取ip,与主机的对应关系
namespace: kafka
labels:
app: zookeeper
spec:
ports:
- port: 2181
name: zookeeper
- port: 2188
name: cluster1
- port: 3888
name: cluster2
clusterip: none
selector:
app: zookeeper
---
apiversion: v1
kind: service
metadata:
name: zookeeper-nodeport-service-0
namespace: kafka
spec:
type: nodeport
selector:
statefulset.kubernetes.io/pod-name: zookeeper-0
ports:
- protocol: tcp
port: 80 # service 暴露的端口
targetport: 2181 # pod 中容器的端口
nodeport: 32181 # nodeport 类型的端口范围为 30000-32767,可以根据需要调整
---
apiversion: v1
kind: service
metadata:
name: zookeeper-nodeport-service-1
namespace: kafka
spec:
type: nodeport
selector:
statefulset.kubernetes.io/pod-name: zookeeper-1
ports:
- protocol: tcp
port: 80 # service 暴露的端口
targetport: 2181 # pod 中容器的端口
nodeport: 32182 # nodeport 类型的端口范围为 30000-32767,可以根据需要调整
---
apiversion: v1
kind: service
metadata:
name: zookeeper-nodeport-service-2
namespace: kafka
spec:
type: nodeport
selector:
statefulset.kubernetes.io/pod-name: zookeeper-2
ports:
- protocol: tcp
port: 80 # service 暴露的端口
targetport: 2181 # pod 中容器的端口
nodeport: 32183 # nodeport 类型的端口范围为 30000-32767,可以根据需要调整
---
apiversion: v1
kind: configmap
metadata:
name: zookeeper-config
namespace: kafka
labels:
app: zookeeper
data: #具体挂载的配置文件
zoo.cfg: |+
ticktime=2000
initlimit=10
synclimit=5
datadir=/data
datalogdir=/datalog
clientport=2181
server.1=zookeeper-0.zookeeper-cluster.kafka:2188:3888
server.2=zookeeper-1.zookeeper-cluster.kafka:2188:3888
server.3=zookeeper-2.zookeeper-cluster.kafka:2188:3888
4lw.commands.whitelist=*
---
apiversion: apps/v1
kind: statefulset
metadata:
name: zookeeper
namespace: kafka
spec:
servicename: "zookeeper-cluster" #填写无头服务的名称
replicas: 3
selector:
matchlabels:
app: zookeeper
template:
metadata:
labels:
app: zookeeper
spec:
initcontainers:
- name: set-zk-id
image: busybox:latest
command: ['sh', '-c', "hostname | cut -d '-' -f 2 | awk '{print $0 + 1}' > /data/myid"]
volumemounts:
- name: data
mountpath: /data
containers:
- name: zookeeper
image: zookeeper:3.8
imagepullpolicy: never
resources:
requests:
memory: "500mi"
cpu: "500m"
limits:
memory: "1000mi"
cpu: "1000m"
ports:
- containerport: 2181
name: zookeeper
- containerport: 2188
name: cluster1
- containerport: 3888
name: cluster2
volumemounts:
- name: zook-config #挂载配置
mountpath: /conf/zoo.cfg
subpath: zoo.cfg
- name: data
mountpath: /data
env:
- name: my_pod_name
valuefrom:
fieldref:
fieldpath: metadata.name #metadata.name获取自己pod名称添加到变量my_pod_name
volumes:
- name: zook-config
configmap: #configmap挂载
name: zookeeper-config
volumeclaimtemplates: #这步自动创建pvc,并挂载动态pv
- metadata:
name: data
spec:
accessmodes: ["readwritemany"]
storageclassname: nfs
resources:
requests:
storage: 10gi创建zookeeper集群
[root@master ~]# kubectl apply -f zook.yaml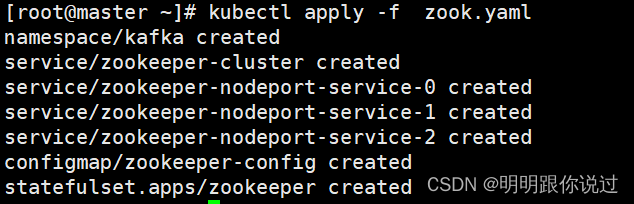
查看pod状态

2、部署kafka集群
编写部署kafka集群的yaml文件
[root@master ~]# vim kafka.yaml
# 输入如下内容
apiversion: v1
kind: service
metadata:
name: kafka-cluster #无头服务的名称,需要通过这个获取ip,与主机的对应关系
namespace: kafka
labels:
app: kafka
spec:
ports:
- port: 9092
name: kafka
clusterip: none
selector:
app: kafka
---
apiversion: v1
kind: service
metadata:
name: kafka-nodeport-service-0
namespace: kafka
spec:
type: nodeport
selector:
statefulset.kubernetes.io/pod-name: kafka0-0
ports:
- protocol: tcp
port: 9092 # service 暴露的端口
targetport: 9092 # pod 中容器的端口
nodeport: 30092 # nodeport 类型的端口范围为 30000-32767,可以根据需要调整
name: kafka
---
apiversion: v1
kind: service
metadata:
name: kafka-nodeport-service-1
namespace: kafka
spec:
type: nodeport
selector:
statefulset.kubernetes.io/pod-name: kafka1-0
ports:
- protocol: tcp
port: 9092 # service 暴露的端口
targetport: 9092 # pod 中容器的端口
nodeport: 30093 # nodeport 类型的端口范围为 30000-32767,可以根据需要调整
name: kafka
---
apiversion: v1
kind: service
metadata:
name: kafka-nodeport-service-2
namespace: kafka
spec:
type: nodeport
selector:
statefulset.kubernetes.io/pod-name: kafka2-0
ports:
- protocol: tcp
port: 9092 # service 暴露的端口
targetport: 9092 # pod 中容器的端口
nodeport: 30094 # nodeport 类型的端口范围为 30000-32767,可以根据需要调整
name: kafka
---
apiversion: apps/v1
kind: statefulset
metadata:
name: kafka0
namespace: kafka
spec:
servicename: "kafka-cluster" #填写无头服务的名称
replicas: 1
selector:
matchlabels:
app: kafka0
template:
metadata:
labels:
app: kafka0
spec:
containers:
- name: kafka
image: kafka:3.1.0
imagepullpolicy: never
resources:
requests:
memory: "500mi"
cpu: "500m"
limits:
memory: "1000mi"
cpu: "2000m"
ports:
- containerport: 9092
name: kafka
command:
- sh
- -c
- "exec /app/kafka/bin/kafka-server-start.sh /app/kafka/config/server.properties --override broker.id=0 \
--override listeners=plaintext://:9092 \
--override advertised.listeners=plaintext://192.168.40.181:30092 \
--override zookeeper.connect=192.168.40.181:32181,192.168.40.181:32182,192.168.40.181:32183/kafka \
--override log.dirs=/var/lib/kafka/data \
--override auto.create.topics.enable=true \
--override auto.leader.rebalance.enable=true \
--override background.threads=10 \
--override compression.type=producer \
--override delete.topic.enable=true \
--override leader.imbalance.check.interval.seconds=300 \
--override leader.imbalance.per.broker.percentage=10 \
--override log.flush.interval.messages=9223372036854775807 \
--override log.flush.offset.checkpoint.interval.ms=60000 \
--override log.flush.scheduler.interval.ms=9223372036854775807 \
--override log.retention.bytes=-1 \
--override log.retention.hours=168 \
--override log.roll.hours=168 \
--override log.roll.jitter.hours=0 \
--override log.segment.bytes=1073741824 \
--override log.segment.delete.delay.ms=60000 \
--override message.max.bytes=1000012 \
--override min.insync.replicas=1 \
--override num.io.threads=8 \
--override num.network.threads=3 \
--override num.recovery.threads.per.data.dir=1 \
--override num.replica.fetchers=1 \
--override offset.metadata.max.bytes=4096 \
--override offsets.commit.required.acks=-1 \
--override offsets.commit.timeout.ms=5000 \
--override offsets.load.buffer.size=5242880 \
--override offsets.retention.check.interval.ms=600000 \
--override offsets.retention.minutes=1440 \
--override offsets.topic.compression.codec=0 \
--override offsets.topic.num.partitions=50 \
--override offsets.topic.replication.factor=3 \
--override offsets.topic.segment.bytes=104857600 \
--override queued.max.requests=500 \
--override quota.consumer.default=9223372036854775807 \
--override quota.producer.default=9223372036854775807 \
--override replica.fetch.min.bytes=1 \
--override replica.fetch.wait.max.ms=500 \
--override replica.high.watermark.checkpoint.interval.ms=5000 \
--override replica.lag.time.max.ms=10000 \
--override replica.socket.receive.buffer.bytes=65536 \
--override replica.socket.timeout.ms=30000 \
--override request.timeout.ms=30000 \
--override socket.receive.buffer.bytes=102400 \
--override socket.request.max.bytes=104857600 \
--override socket.send.buffer.bytes=102400 \
--override unclean.leader.election.enable=true \
--override zookeeper.session.timeout.ms=6000 \
--override zookeeper.set.acl=false \
--override broker.id.generation.enable=true \
--override connections.max.idle.ms=600000 \
--override controlled.shutdown.enable=true \
--override controlled.shutdown.max.retries=3 \
--override controlled.shutdown.retry.backoff.ms=5000 \
--override controller.socket.timeout.ms=30000 \
--override default.replication.factor=1 \
--override fetch.purgatory.purge.interval.requests=1000 \
--override group.max.session.timeout.ms=300000 \
--override group.min.session.timeout.ms=6000 \
--override log.cleaner.backoff.ms=15000 \
--override log.cleaner.dedupe.buffer.size=134217728 \
--override log.cleaner.delete.retention.ms=86400000 \
--override log.cleaner.enable=true \
--override log.cleaner.io.buffer.load.factor=0.9 \
--override log.cleaner.io.buffer.size=524288 \
--override log.cleaner.io.max.bytes.per.second=1.7976931348623157e308 \
--override log.cleaner.min.cleanable.ratio=0.5 \
--override log.cleaner.min.compaction.lag.ms=0 \
--override log.cleaner.threads=1 \
--override log.cleanup.policy=delete \
--override log.index.interval.bytes=4096 \
--override log.index.size.max.bytes=10485760 \
--override log.message.timestamp.difference.max.ms=9223372036854775807 \
--override log.message.timestamp.type=createtime \
--override log.preallocate=false \
--override log.retention.check.interval.ms=300000 \
--override max.connections.per.ip=2147483647 \
--override num.partitions=1 \
--override producer.purgatory.purge.interval.requests=1000 \
--override replica.fetch.backoff.ms=1000 \
--override replica.fetch.max.bytes=1048576 \
--override replica.fetch.response.max.bytes=10485760 \
--override reserved.broker.max.id=1000"
volumemounts:
- name: data0
mountpath: /var/lib/kafka/data
env:
- name: my_pod_name
valuefrom:
fieldref:
fieldpath: metadata.name #metadata.name获取自己pod名称添加到变量my_pod_name
- name: allow_plaintext_listener
value: "yes"
- name: kafka_heap_opts
value : "-xms1g -xmx1g"
- name: jmx_port
value: "5555"
volumeclaimtemplates: #这步自动创建pvc,并挂载动态pv
- metadata:
name: data0
spec:
accessmodes: ["readwritemany"]
storageclassname: nfs
resources:
requests:
storage: 10gi
---
apiversion: apps/v1
kind: statefulset
metadata:
name: kafka1
namespace: kafka
spec:
servicename: "kafka-cluster" #填写无头服务的名称
replicas: 1
selector:
matchlabels:
app: kafka1
template:
metadata:
labels:
app: kafka1
spec:
containers:
- name: kafka
image: kafka:3.1.0
imagepullpolicy: never
resources:
requests:
memory: "500mi"
cpu: "500m"
limits:
memory: "1000mi"
cpu: "2000m"
ports:
- containerport: 9092
name: kafka
command:
- sh
- -c
- "exec /app/kafka/bin/kafka-server-start.sh /app/kafka/config/server.properties --override broker.id=1 \
--override listeners=plaintext://:9092 \
--override advertised.listeners=plaintext://192.168.40.181:30093 \
--override zookeeper.connect=192.168.40.181:32181,192.168.40.181:32182,192.168.40.181:32183/kafka \
--override log.dirs=/var/lib/kafka/data \
--override auto.create.topics.enable=true \
--override auto.leader.rebalance.enable=true \
--override background.threads=10 \
--override compression.type=producer \
--override delete.topic.enable=true \
--override leader.imbalance.check.interval.seconds=300 \
--override leader.imbalance.per.broker.percentage=10 \
--override log.flush.interval.messages=9223372036854775807 \
--override log.flush.offset.checkpoint.interval.ms=60000 \
--override log.flush.scheduler.interval.ms=9223372036854775807 \
--override log.retention.bytes=-1 \
--override log.retention.hours=168 \
--override log.roll.hours=168 \
--override log.roll.jitter.hours=0 \
--override log.segment.bytes=1073741824 \
--override log.segment.delete.delay.ms=60000 \
--override message.max.bytes=1000012 \
--override min.insync.replicas=1 \
--override num.io.threads=8 \
--override num.network.threads=3 \
--override num.recovery.threads.per.data.dir=1 \
--override num.replica.fetchers=1 \
--override offset.metadata.max.bytes=4096 \
--override offsets.commit.required.acks=-1 \
--override offsets.commit.timeout.ms=5000 \
--override offsets.load.buffer.size=5242880 \
--override offsets.retention.check.interval.ms=600000 \
--override offsets.retention.minutes=1440 \
--override offsets.topic.compression.codec=0 \
--override offsets.topic.num.partitions=50 \
--override offsets.topic.replication.factor=3 \
--override offsets.topic.segment.bytes=104857600 \
--override queued.max.requests=500 \
--override quota.consumer.default=9223372036854775807 \
--override quota.producer.default=9223372036854775807 \
--override replica.fetch.min.bytes=1 \
--override replica.fetch.wait.max.ms=500 \
--override replica.high.watermark.checkpoint.interval.ms=5000 \
--override replica.lag.time.max.ms=10000 \
--override replica.socket.receive.buffer.bytes=65536 \
--override replica.socket.timeout.ms=30000 \
--override request.timeout.ms=30000 \
--override socket.receive.buffer.bytes=102400 \
--override socket.request.max.bytes=104857600 \
--override socket.send.buffer.bytes=102400 \
--override unclean.leader.election.enable=true \
--override zookeeper.session.timeout.ms=6000 \
--override zookeeper.set.acl=false \
--override broker.id.generation.enable=true \
--override connections.max.idle.ms=600000 \
--override controlled.shutdown.enable=true \
--override controlled.shutdown.max.retries=3 \
--override controlled.shutdown.retry.backoff.ms=5000 \
--override controller.socket.timeout.ms=30000 \
--override default.replication.factor=1 \
--override fetch.purgatory.purge.interval.requests=1000 \
--override group.max.session.timeout.ms=300000 \
--override group.min.session.timeout.ms=6000 \
--override log.cleaner.backoff.ms=15000 \
--override log.cleaner.dedupe.buffer.size=134217728 \
--override log.cleaner.delete.retention.ms=86400000 \
--override log.cleaner.enable=true \
--override log.cleaner.io.buffer.load.factor=0.9 \
--override log.cleaner.io.buffer.size=524288 \
--override log.cleaner.io.max.bytes.per.second=1.7976931348623157e308 \
--override log.cleaner.min.cleanable.ratio=0.5 \
--override log.cleaner.min.compaction.lag.ms=0 \
--override log.cleaner.threads=1 \
--override log.cleanup.policy=delete \
--override log.index.interval.bytes=4096 \
--override log.index.size.max.bytes=10485760 \
--override log.message.timestamp.difference.max.ms=9223372036854775807 \
--override log.message.timestamp.type=createtime \
--override log.preallocate=false \
--override log.retention.check.interval.ms=300000 \
--override max.connections.per.ip=2147483647 \
--override num.partitions=1 \
--override producer.purgatory.purge.interval.requests=1000 \
--override replica.fetch.backoff.ms=1000 \
--override replica.fetch.max.bytes=1048576 \
--override replica.fetch.response.max.bytes=10485760 \
--override reserved.broker.max.id=1000"
volumemounts:
- name: data1
mountpath: /var/lib/kafka/data
env:
- name: my_pod_name
valuefrom:
fieldref:
fieldpath: metadata.name #metadata.name获取自己pod名称添加到变量my_pod_name
- name: allow_plaintext_listener
value: "yes"
- name: kafka_heap_opts
value : "-xms1g -xmx1g"
- name: jmx_port
value: "5555"
volumeclaimtemplates: #这步自动创建pvc,并挂载动态pv
- metadata:
name: data1
spec:
accessmodes: ["readwritemany"]
storageclassname: nfs
resources:
requests:
storage: 10gi
---
apiversion: apps/v1
kind: statefulset
metadata:
name: kafka2
namespace: kafka
spec:
servicename: "kafka-cluster" #填写无头服务的名称
replicas: 1
selector:
matchlabels:
app: kafka2
template:
metadata:
labels:
app: kafka2
spec:
containers:
- name: kafka
image: kafka:3.1.0
imagepullpolicy: never
resources:
requests:
memory: "500mi"
cpu: "500m"
limits:
memory: "1000mi"
cpu: "2000m"
ports:
- containerport: 9092
name: kafka
command:
- sh
- -c
- "exec /app/kafka/bin/kafka-server-start.sh /app/kafka/config/server.properties --override broker.id=2 \
--override listeners=plaintext://:9092 \
--override advertised.listeners=plaintext://192.168.40.181:30094 \
--override zookeeper.connect=192.168.40.181:32181,192.168.40.181:32182,192.168.40.181:32183/kafka \
--override log.dirs=/var/lib/kafka/data \
--override auto.create.topics.enable=true \
--override auto.leader.rebalance.enable=true \
--override background.threads=10 \
--override compression.type=producer \
--override delete.topic.enable=true \
--override leader.imbalance.check.interval.seconds=300 \
--override leader.imbalance.per.broker.percentage=10 \
--override log.flush.interval.messages=9223372036854775807 \
--override log.flush.offset.checkpoint.interval.ms=60000 \
--override log.flush.scheduler.interval.ms=9223372036854775807 \
--override log.retention.bytes=-1 \
--override log.retention.hours=168 \
--override log.roll.hours=168 \
--override log.roll.jitter.hours=0 \
--override log.segment.bytes=1073741824 \
--override log.segment.delete.delay.ms=60000 \
--override message.max.bytes=1000012 \
--override min.insync.replicas=1 \
--override num.io.threads=8 \
--override num.network.threads=3 \
--override num.recovery.threads.per.data.dir=1 \
--override num.replica.fetchers=1 \
--override offset.metadata.max.bytes=4096 \
--override offsets.commit.required.acks=-1 \
--override offsets.commit.timeout.ms=5000 \
--override offsets.load.buffer.size=5242880 \
--override offsets.retention.check.interval.ms=600000 \
--override offsets.retention.minutes=1440 \
--override offsets.topic.compression.codec=0 \
--override offsets.topic.num.partitions=50 \
--override offsets.topic.replication.factor=3 \
--override offsets.topic.segment.bytes=104857600 \
--override queued.max.requests=500 \
--override quota.consumer.default=9223372036854775807 \
--override quota.producer.default=9223372036854775807 \
--override replica.fetch.min.bytes=1 \
--override replica.fetch.wait.max.ms=500 \
--override replica.high.watermark.checkpoint.interval.ms=5000 \
--override replica.lag.time.max.ms=10000 \
--override replica.socket.receive.buffer.bytes=65536 \
--override replica.socket.timeout.ms=30000 \
--override request.timeout.ms=30000 \
--override socket.receive.buffer.bytes=102400 \
--override socket.request.max.bytes=104857600 \
--override socket.send.buffer.bytes=102400 \
--override unclean.leader.election.enable=true \
--override zookeeper.session.timeout.ms=6000 \
--override zookeeper.set.acl=false \
--override broker.id.generation.enable=true \
--override connections.max.idle.ms=600000 \
--override controlled.shutdown.enable=true \
--override controlled.shutdown.max.retries=3 \
--override controlled.shutdown.retry.backoff.ms=5000 \
--override controller.socket.timeout.ms=30000 \
--override default.replication.factor=1 \
--override fetch.purgatory.purge.interval.requests=1000 \
--override group.max.session.timeout.ms=300000 \
--override group.min.session.timeout.ms=6000 \
--override log.cleaner.backoff.ms=15000 \
--override log.cleaner.dedupe.buffer.size=134217728 \
--override log.cleaner.delete.retention.ms=86400000 \
--override log.cleaner.enable=true \
--override log.cleaner.io.buffer.load.factor=0.9 \
--override log.cleaner.io.buffer.size=524288 \
--override log.cleaner.io.max.bytes.per.second=1.7976931348623157e308 \
--override log.cleaner.min.cleanable.ratio=0.5 \
--override log.cleaner.min.compaction.lag.ms=0 \
--override log.cleaner.threads=1 \
--override log.cleanup.policy=delete \
--override log.index.interval.bytes=4096 \
--override log.index.size.max.bytes=10485760 \
--override log.message.timestamp.difference.max.ms=9223372036854775807 \
--override log.message.timestamp.type=createtime \
--override log.preallocate=false \
--override log.retention.check.interval.ms=300000 \
--override max.connections.per.ip=2147483647 \
--override num.partitions=1 \
--override producer.purgatory.purge.interval.requests=1000 \
--override replica.fetch.backoff.ms=1000 \
--override replica.fetch.max.bytes=1048576 \
--override replica.fetch.response.max.bytes=10485760 \
--override reserved.broker.max.id=1000"
volumemounts:
- name: data2
mountpath: /var/lib/kafka/data
env:
- name: my_pod_name
valuefrom:
fieldref:
fieldpath: metadata.name #metadata.name获取自己pod名称添加到变量my_pod_name
- name: allow_plaintext_listener
value: "yes"
- name: kafka_heap_opts
value : "-xms1g -xmx1g"
- name: jmx_port
value: "5555"
volumeclaimtemplates: #这步自动创建pvc,并挂载动态pv
- metadata:
name: data2
spec:
accessmodes: ["readwritemany"]
storageclassname: nfs
resources:
requests:
storage: 10gi创建kafka集群
[root@master ~]# kubectl apply -f kafka.yaml 
查看pod状态

至此,kafka集群部署完成


发表评论