hadoop3.1.3搭建涉及的软件:
https://pan.quark.cn/s/6b6427bbdf62#/list/share
一、vmware软件中安装centos7
在vmware软件中安装centos7,安装完成后启动虚拟机。(步骤参见centos7安装教程)
二、linux环境搭建
1、配置虚拟机网络
(1)设置vmware虚拟机的网络方式为nat(网络地址转换)
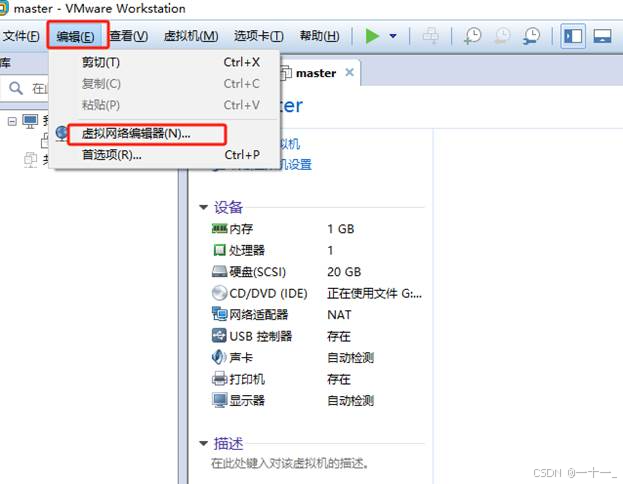
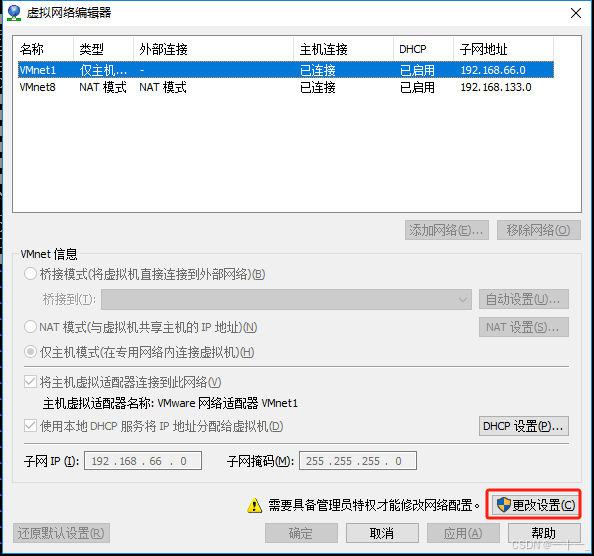
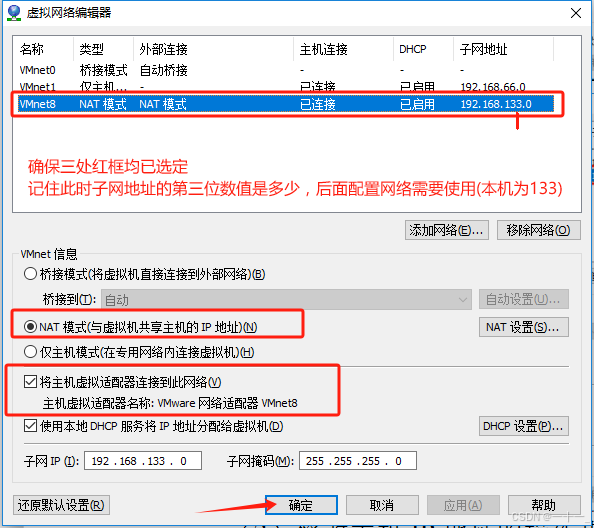
(2)修改主机ip地址的操作步骤如下:
① 启动虚拟机,登录root账户
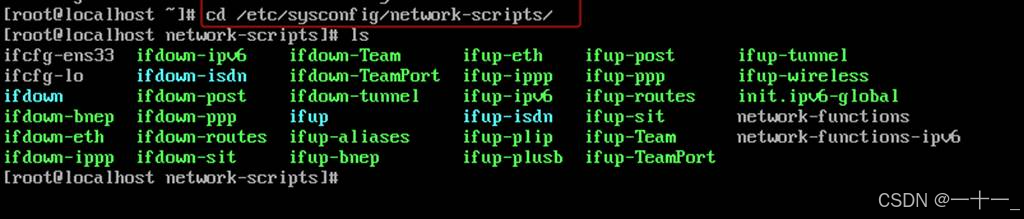
② 切换到/etc/sysconfig/network-scripts/目录下,命令如下所示:
cd /etc/sysconfig/network-scripts/
(可以通过ls命令查询该目录下有哪些目录及文件)
③ 编辑该目录下的ifcfg-ens33文件,命令如下所示:
vi ifcfg-ens33
![]()
按下键盘上的字母i,即可开始修改ifcfg-ens33中的内容,其中红色斜体字为需要修改内容
④网卡信息修改完成后,保存并退出vi编辑器(先按下esc键,再输入:wq),接着需要重新启动网络服务,使修改的内容生效,命令如下所示:
systemctl restart network

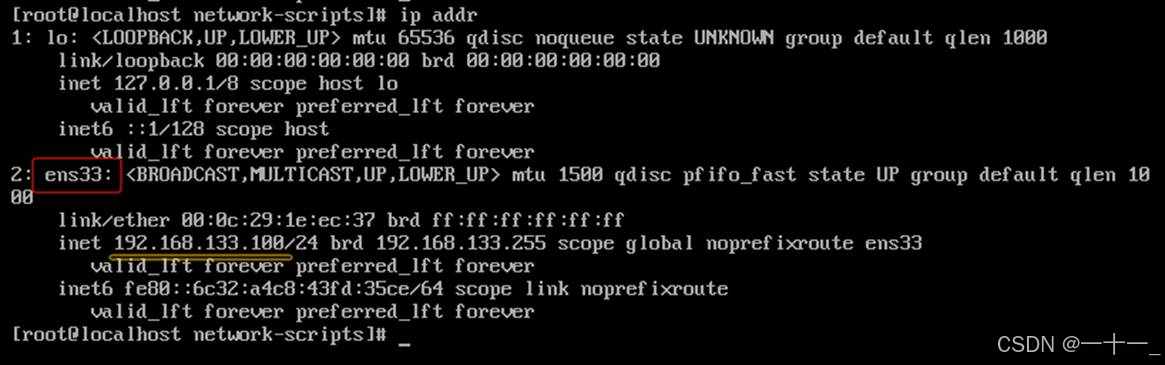
⑤网卡重启完成后,可以查看网络配置信息,命令如下所示:
ip addr
⑥ping一下外网,例如www.baidu.com,保证网络畅通(以上述ip地址为例,ping
www.baidu.com,停止ping使用ctrl+z)

2、修改主机名
(1) 编辑/etc/hostname文件,永久保存主机名
![]()
(2) 删除原有内容,添加master(将主机名修改为master)

添加完成后,保存并退出hostname文件
(3) 使用reboot命令重启使修改内容生效
![]()
启动后重新登录,可以看到主机名已修改成功
3、配置主机名和ip之间的对应关系
(1) 编辑/etc/hosts文件,将ip地址与主机名一一对应
![]()
(2) ip地址与主机名的映射输入格式为:ip地址 主机名(其中ip地址为前面设置的静态ip地址),不要删除原有内容,切换到新行,直接新增

4、关闭虚拟机防火墙
(1) 查看防火墙状态(systemctl statusfirewalld),默认防火墙是开启状态的
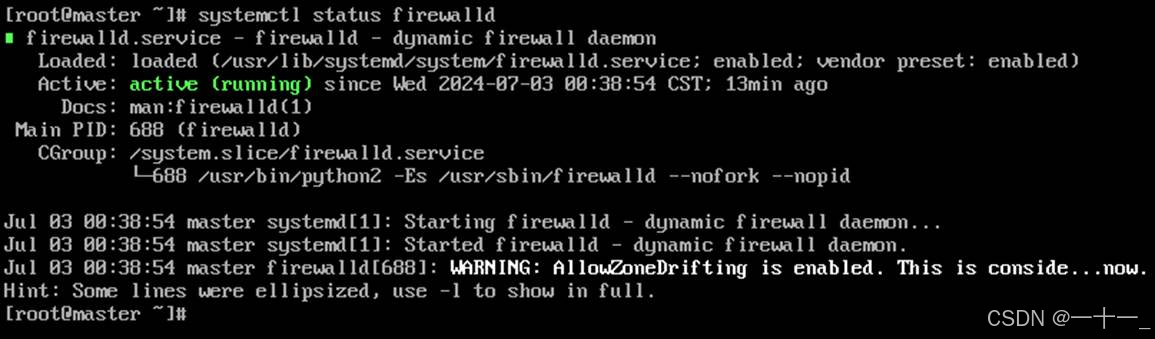
(2) 关闭防火墙(systemctlstop firewalld),然后设置防火墙开机不启动(systemctldisable firewalld)

5、mobaxterm进行远程连接(使用xshell、putty等工具也可以)
(主机ip需要自己主机设置的保持一致,用户名输入root)
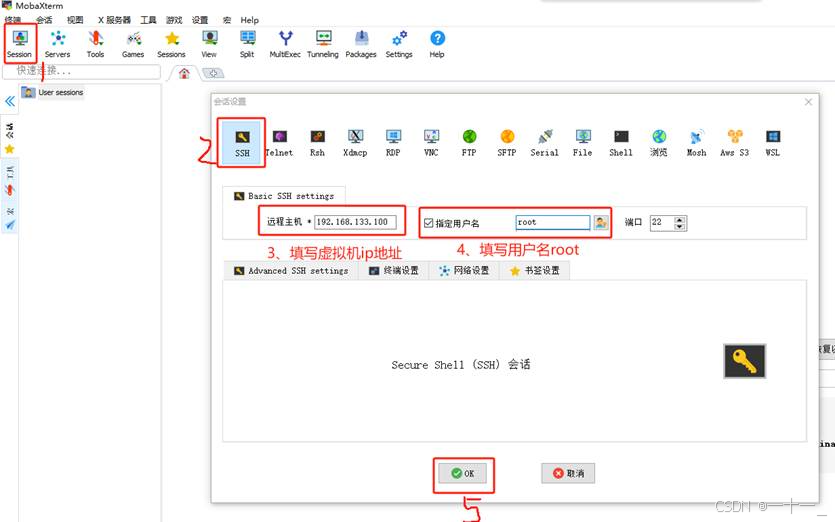
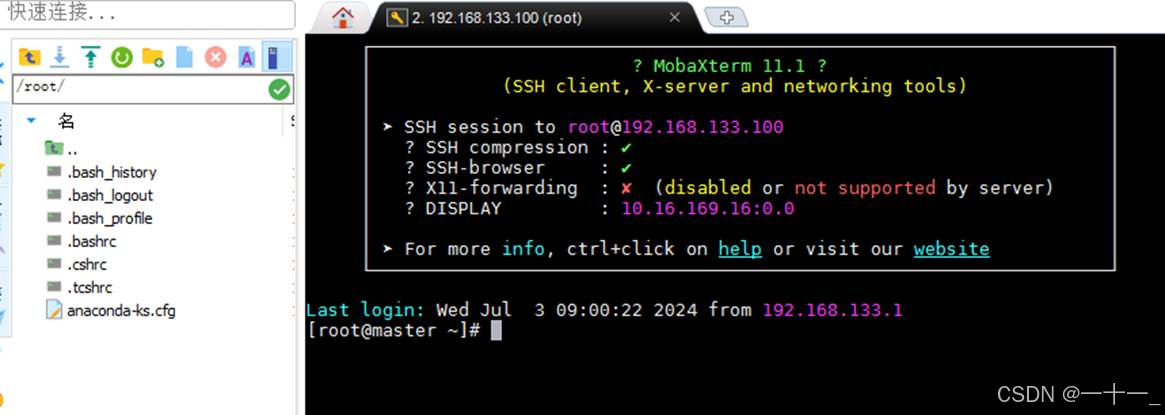
出现如下状态说明登录成功,后续的操作就可以在mobaxterm中继续
三、安装配置jdk
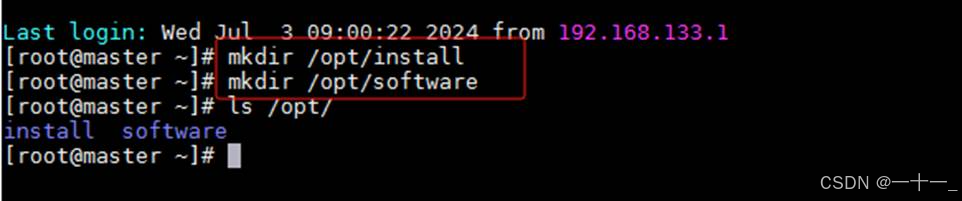
(1)在/opt/下新建两个目录software[存放安装包]、install[存放解压后的软件],命令为:
mkdir /opt/install
mkdir /opt/software
(2)上传jdk安装包到master主机
先在路径框中输入/opt/software,敲击回车键,定位到software目录后,点击上方绿色的上传按钮,即可将本地电脑的安装包上传至此目录下(hadoop安装包可以一起上传过去)
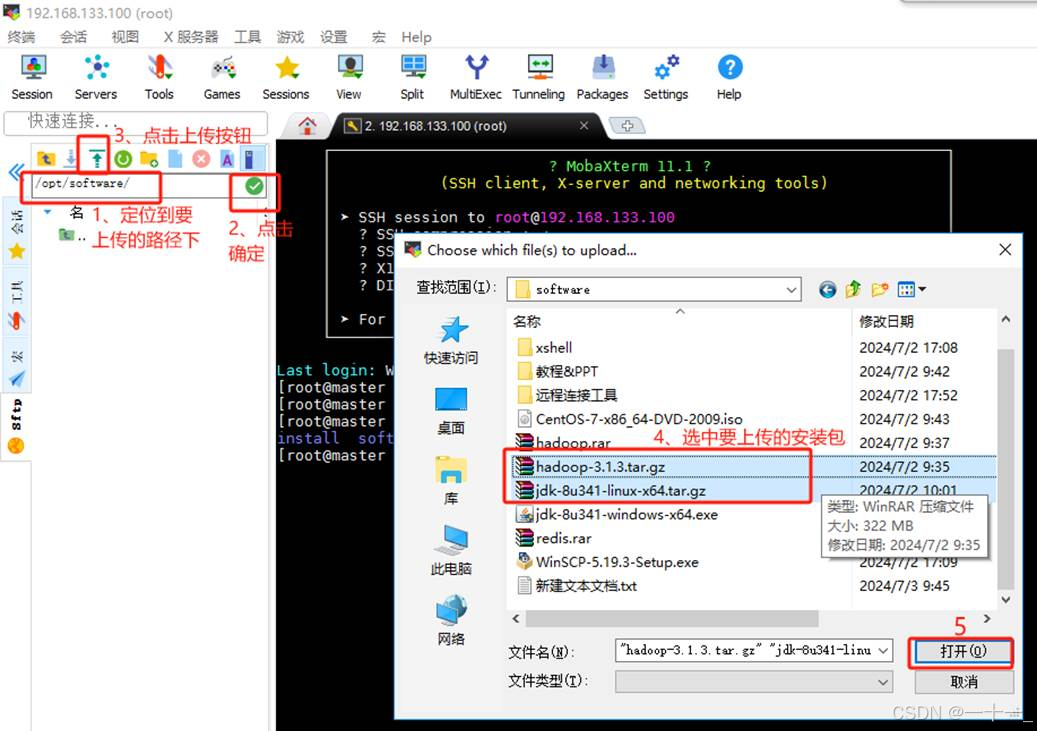
此时左下角会出现上传进度,上传完成后在software目录下可看到上传内容
(3)安装jdk到/opt/install/目录下(以下均使用绝对路径,可以自行选择使用相对路径):
jdk安装命令为:tar -zxvf /opt/software/jdk-8u341-linux-x64.tar.gz -c /opt/install/

(4)将安装后的目录简短重命名为jdk,方便后续配置环境变量
mv /opt/install/jdk1.8.0_341/ jdk

(5)配置jdk环境变量
①打开环境配置文档:vi /etc/profile
![]()
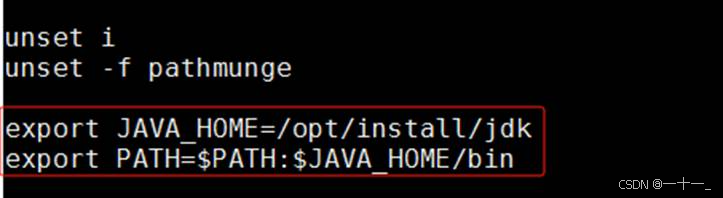
②在文件末尾添加以下指令,添加完成后保存退出编辑模式
| export java_home=/opt/install/jdk export path=$path:$java_home/bin
|
③使用source命令使配置的环境生效,命令为: source /etc/profile

④验证环境变量是否配置成功
验证java命令为: java -version

四、克隆虚拟机
1、关闭master主机,依次克隆出两台新的虚拟机
(指定不同的虚拟机名称和存储路径)
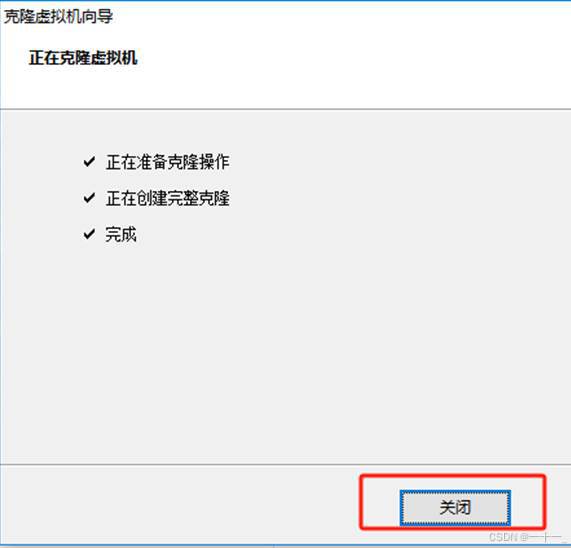
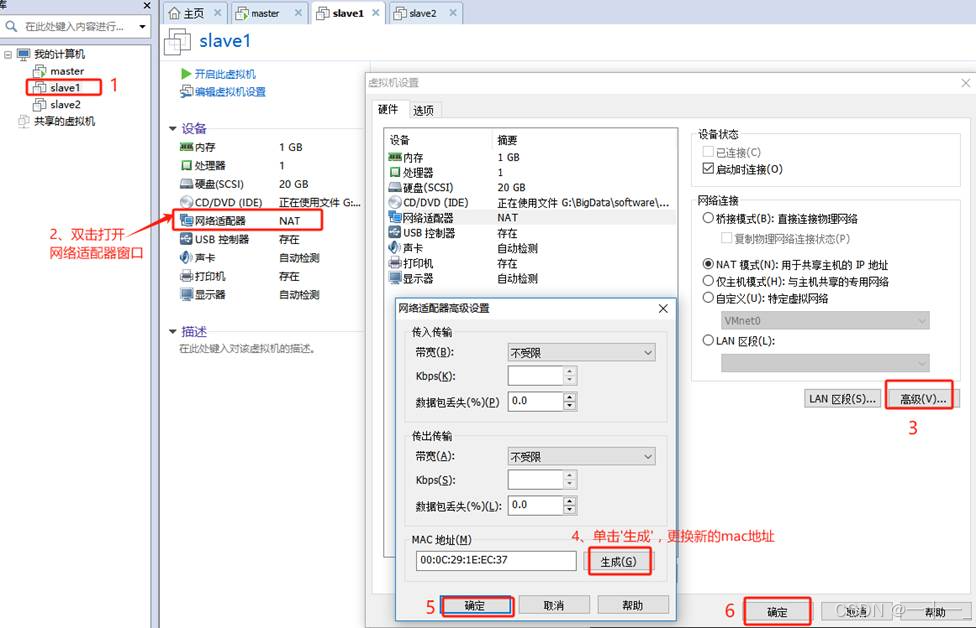
2、更改克隆后两台虚拟机的mac地址(两台虚拟机都需要操作)
3、修改两台新虚拟机的主机名、ip地址
(修改方法参照第一台虚拟机)[设置克隆后的第二、三台主机ip地址时将xx换成自己虚拟机查到的]
| 主机名 | ip地址 | |
| 第一台主机 | master | 192.168.xx.100 |
| 第二台主机 | slave1 | 192.168.xx.101 |
| 第三台主机 | slave2 | 192.168.xx.102 |
以第二台主机为例:
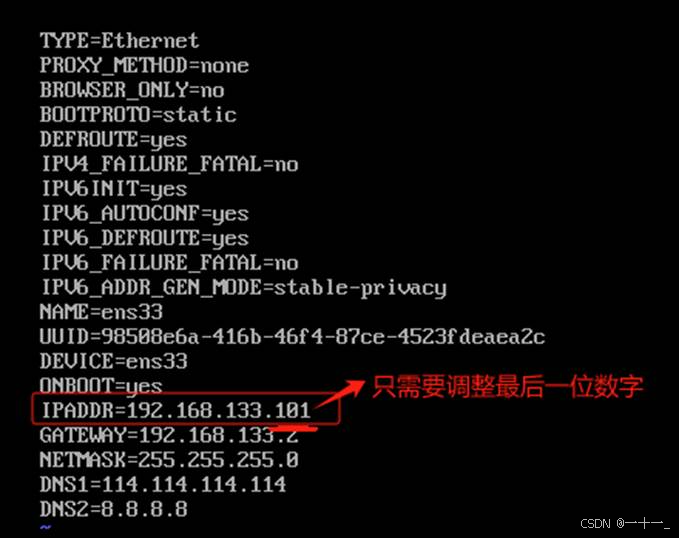
修改ip地址:
![]()
修改主机名
![]()

修改完毕后输入reboot,重启虚拟机,即可生效刚刚修改的内容
![]()

第三台虚拟机依样操作即可
4、设置三台虚拟机的映射关系
①在master主机下输入命令 vi /etc/hosts进入映射文件,新增另外两台主机和ip的映射关系
![]()

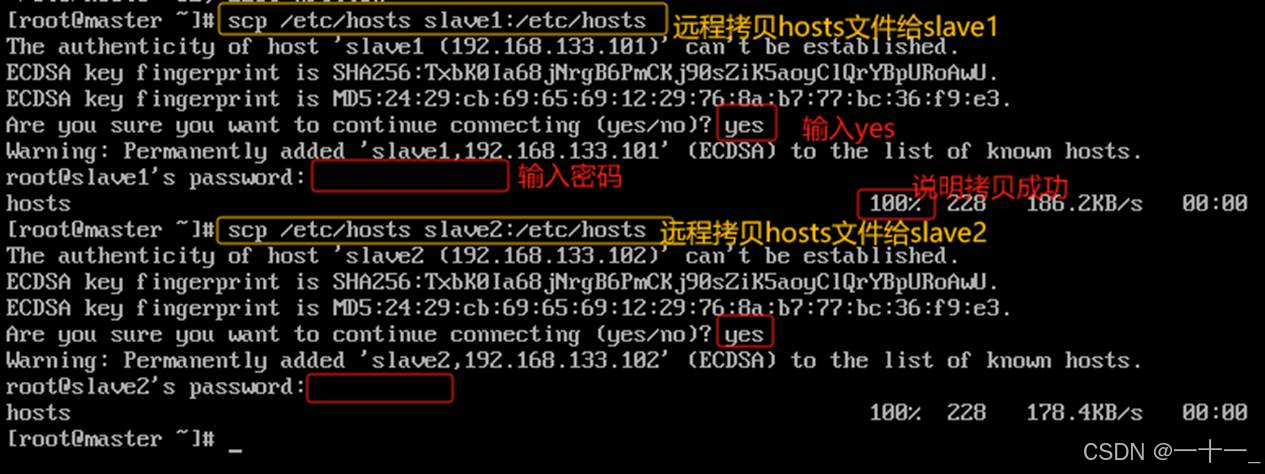
②通过scp远程命令,将更改后的hosts文件复制给slave1、slave2,指令分别为:
scp /etc/hosts slave1:/etc/hosts
scp /etc/hosts slave2:/etc/hosts
(由于尚未实现免密登录,所以在远程传输时需要输入传输主机的密码,后面配置过免密后就不再需要输密码了)
③ping另外两台主机名
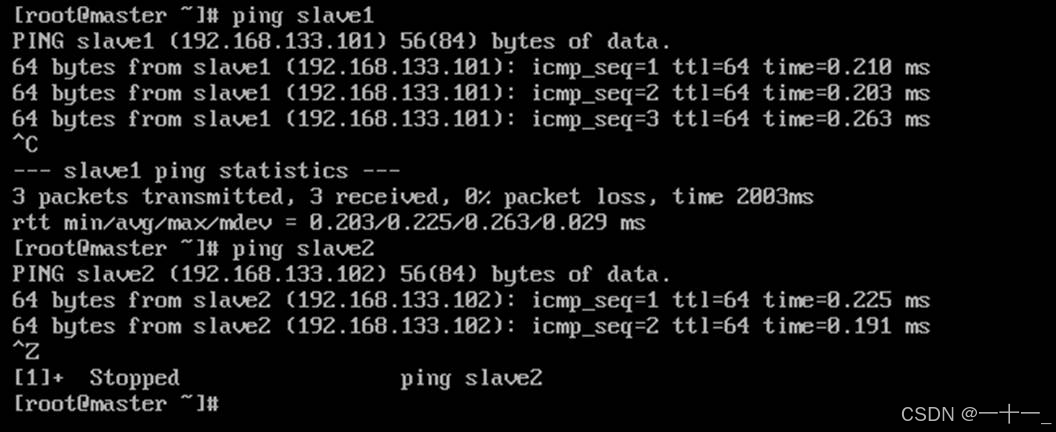
④接着在第二第三台主机上做同样的测试,如果都可以ping通,说明网络是互通的
五、配置免密登录
1、输入命令ssh-keygen生成密钥对
(注意:三台主机均需执行, ssh密钥默认保留在~/.ssh目录中)
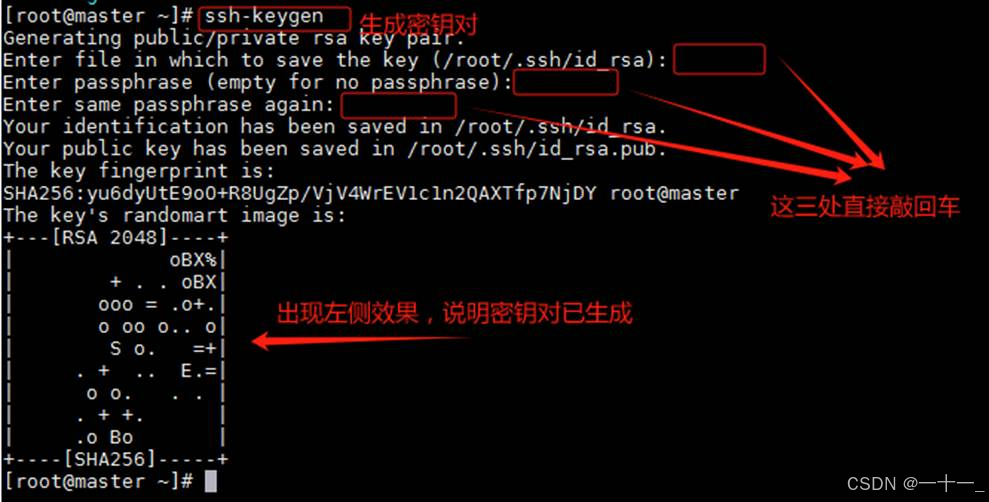
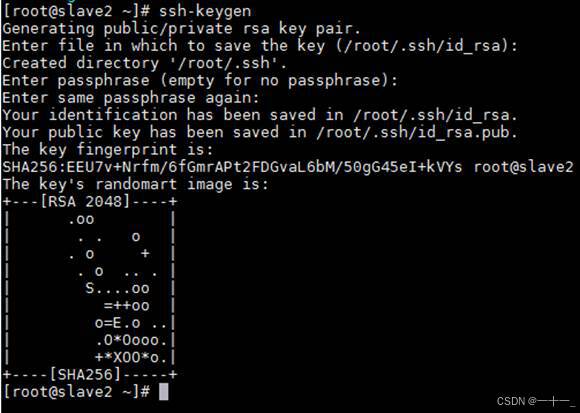
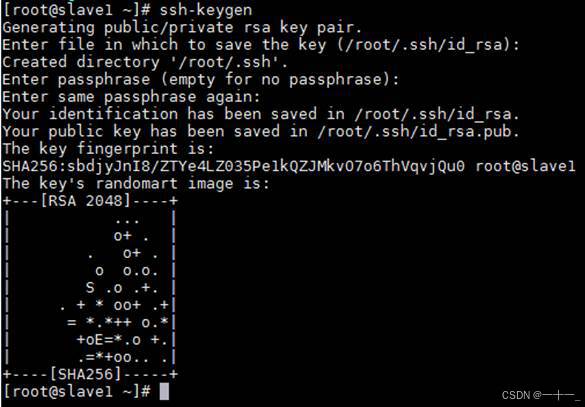
从一个节点到另外一个节点,也就是使用ssh命令时需要密码,配置免密后就可以实现无密码登录
2、拷贝公钥信息ssh-copy-id
分别在master、slave1和slave2三个节点上执行以下三条命令(该命令是将自身的公钥信息复制并追加到全部主机的授权文件authorized_keys中)
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
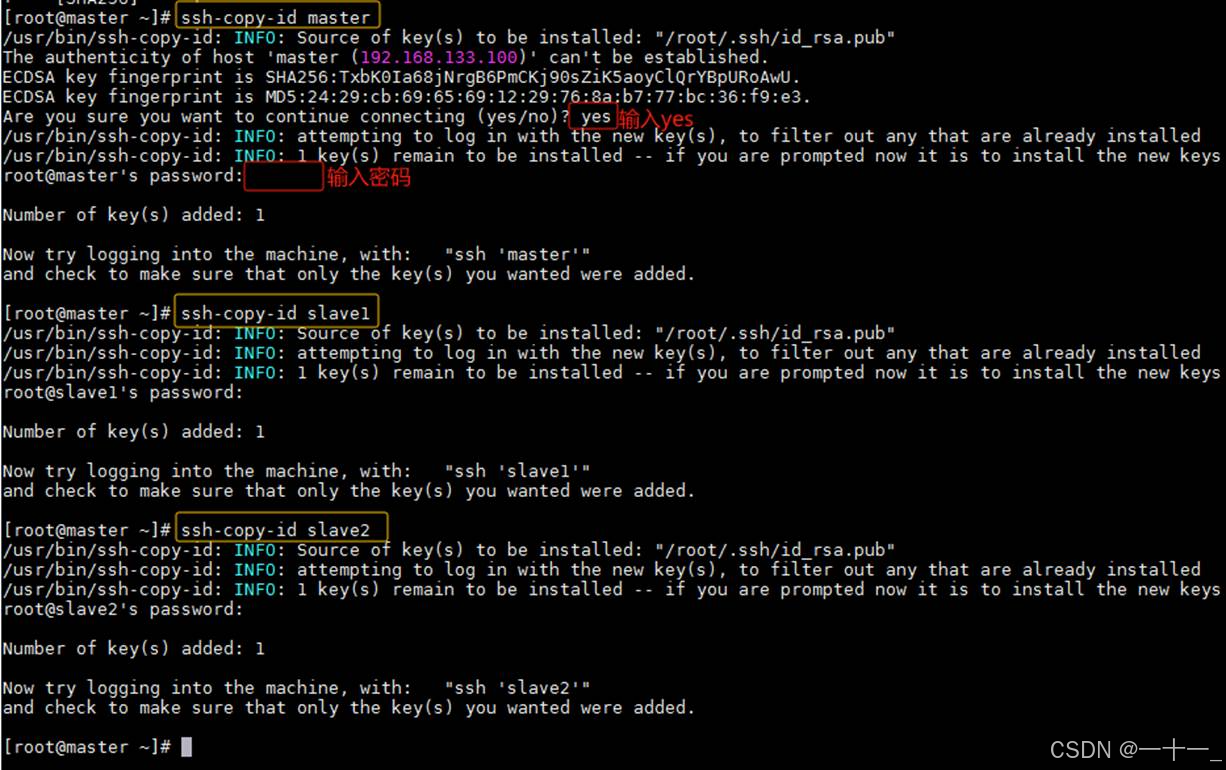
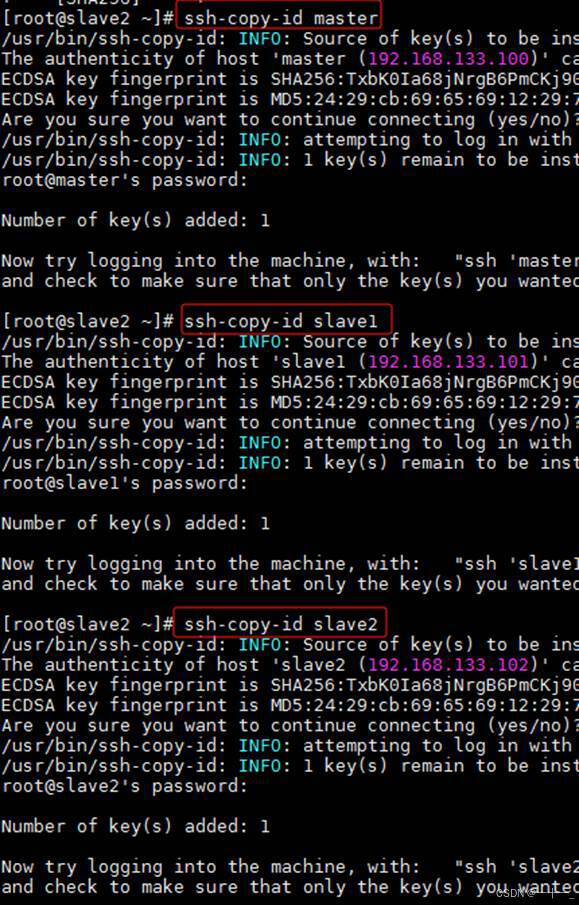
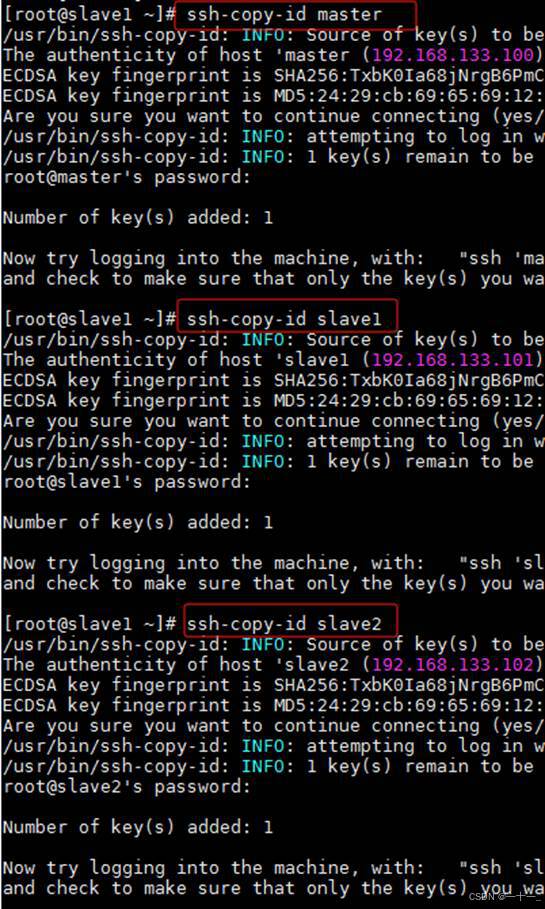
3、主机间相互登录做验证
使用ssh指令尝试三台主机相互登录,能相互间免密登录说明配置成功(exit可以退出当前登录状态),例如:
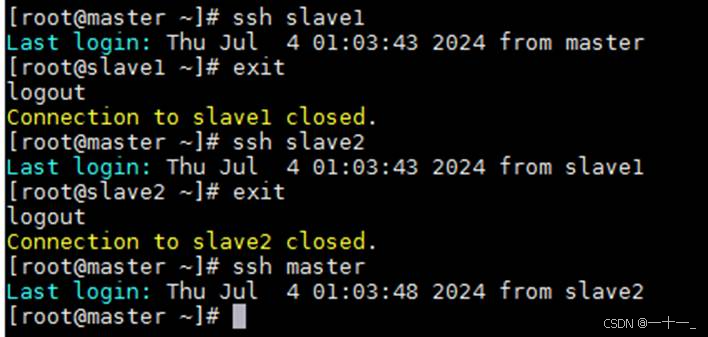
六、hadoop完全分布式安装
hadoop平台搭建3种模式:单机模式、伪分布式模式和全分布式集群模式
- 单机(本地)模式:这种模式在一台单机上运行,没有分布式文件系统,而是直接读写本地操作系统的文件系统。在单机模式中不会存在守护进程,所有东西都运行在一个jvm上。这里同样没有dfs,使用的是本地文件系统。单机模式适用于开发过程中运行mapreduce程序,这也是最少使用的一个模式。
- 伪分布式模式:也是在一台单机上运行,但用不同的java进程模仿分布式运行中的各类结点,伪分布式适用于开发和测试环境,在这个模式中,所有守护进程都在同一台机器上运行。
- 全分布式模式:全分布模式通常被用于生产环境,使用n台主机组成一个hadoop集群,hadoop守护进程运行在每台主机之上。在分布式环境下,主节点和从节点会分开。
hadoop 的完全分布式安装至少由三个及以上的实体机或者虚拟机组成的集群。一个hadoop集群环境中,进程namenode、secondaryname通常分配在不同的节点上。 各节点及守护进程安排如下:
| ip地址 | 主机名称 | hdfs | yarn |
| 192.168.xxx.100 | master(主节点) | namenode datanode | resourcemanager nodemanager |
| 192.168.xxx.101 | slave1(从节点) | secondarynamenode datanode | nodemanager |
| 192.168.xxx.102 | slave2(从节点) | datanode | nodemanager |
| ip地址和主机名都跟随自己配置的机器设置,指定一台做主节点,两台做从节点 | |||


1、hadoop环境配置
①安装hadoop到/opt/install/ 目录下(以下均使用绝对路径,可以自行选择相对路径),命令为:
tar -zxvf/opt/software/hadoop-3.1.3.tar.gz -c /opt/install/
![]()
②将安装后的目录简短重命名为hadoop,命令为
mv /opt/install/hadoop-3.1.3/ hadoop

③配置hadoop的环境变量
打开环境配置文档:vi /etc/profile
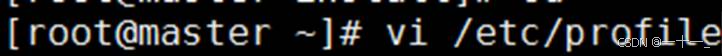
在文件末尾添加以下指令,添加完成后保存并退出编辑模式
| export hadoop_home=/opt/install/hadoop export path=$path:$hadoop_home/bin:$hadoop_home/sbin
export hdfs_namenode_user=root export hdfs_secondarynamenode_user=root export hdfs_datanode_user=root export yarn_resourcemanager_user=root export yarn_nodemanager_user=root
|
④使用source命令使配置的环境生效,命令为:
source /etc/profile

⑤验证环境变量是否配置成功
验证hadoop命令为: hadoop version

2、hadoop完全分布文件配置
(配置文件在hadoop安装目录下面的etc/hadoop中,全路径为:/opt/install/hadoop/etc/hadoop)
需要修改的核心配置文件包括:hadoop-env.sh、yarn-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、workers
①修改hadoop-env.sh 文件
![]()
在文件末尾添加java环境安装路径,指令:
export java_home=/opt/install/jdk

②修改 yarn-env.sh 文件
![]()
此文件是 yarn 框架运行环境配置,也需要在文件末尾添加java环境安装路径,指令:
export java_home=/opt/install/jdk
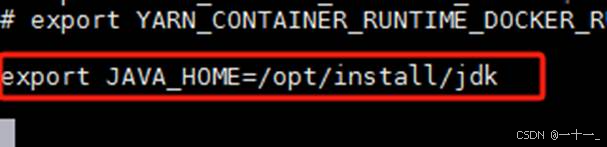
③修改 core-site.xml 文件
![]()
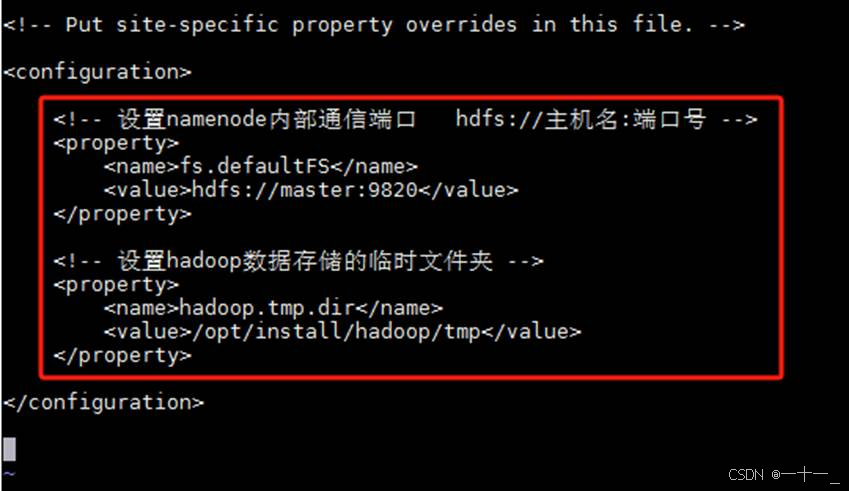
④修改hdfs-site.xml文件
![]()
⑤修改mapred-site.xml文件
![]()

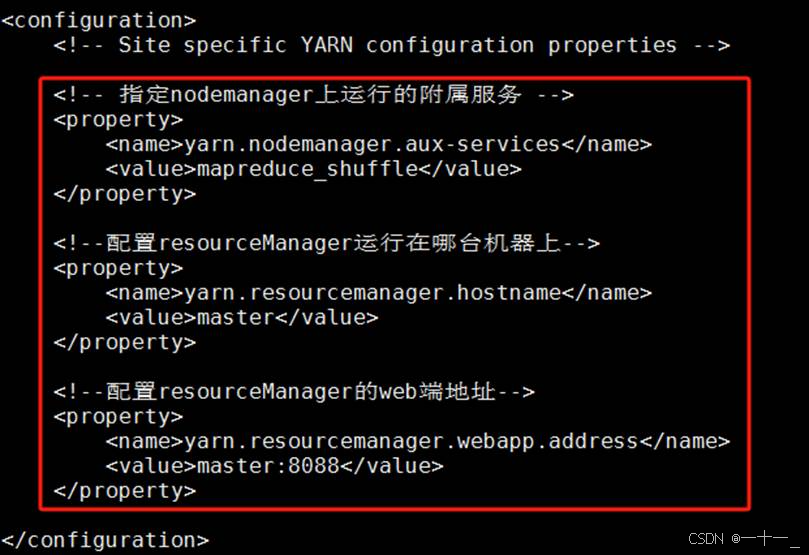
⑥修改yarn-site.xml文件
![]()
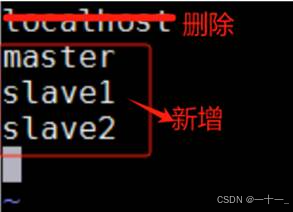
⑦修改workers文件
(把需要启动datanode进程的节点列入)
![]()
删除原有的localhost,新增master、slave1、slave2
3、拷贝hadoop安装目录到另外两台机器(slave1,slave2)
scp -r /opt/install/hadoop/ slave1:/opt/install/
![]()
scp -r /opt/install/hadoop/ slave2:/opt/install/
![]()
4、拷贝环境变量配置文件到另外两台机器(slave1,slave2)
scp /etc/profile slave1:/etc/profile
![]()
scp /etc/profile slave2:/etc/profile

5、在每一台机器都执行环境变量生效命令:
source /etc/profile
![]()
![]()
![]()
七、hadoop分布式集群启动
1、在master主机上格式化namenode节点
在 hadoop 的安装目录/opt/install/hadoop/bin下执行命令:
hdfs namenode -format
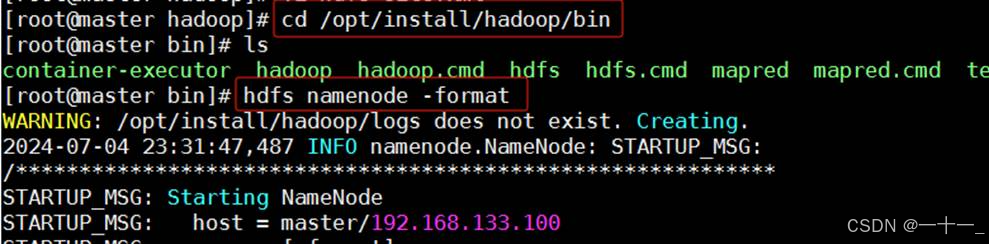
出现successfully formatted说明格式化成功
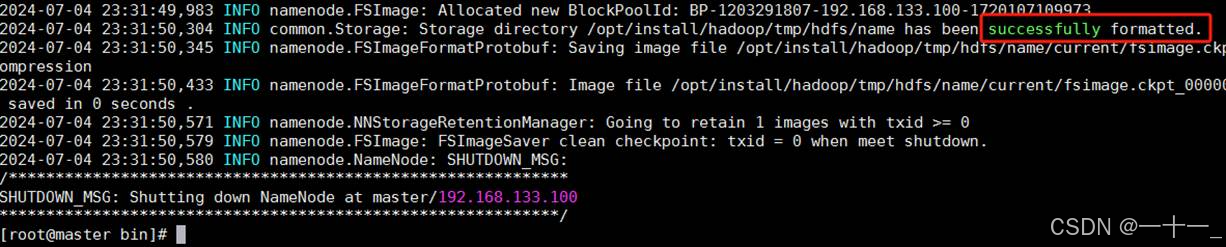
提示:格式化命令必须在namenode所在的节点上执行(本次操作将namenode配置在了master主机下,所以在master上进行格式化)
2、启动集群
在master主机的任意目录下操作即可
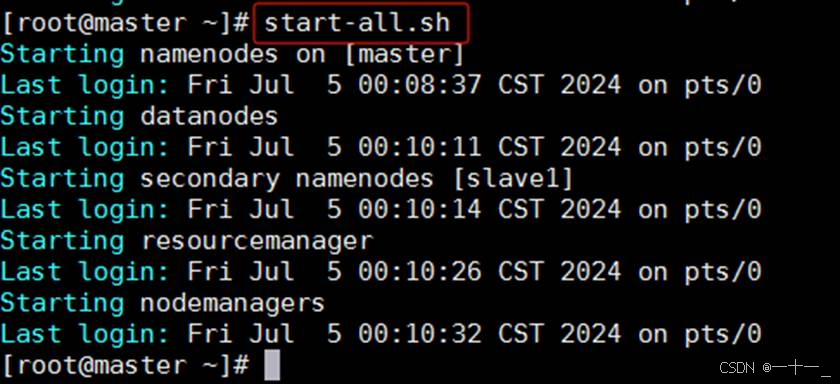
①启动namenode和datanode
一次性启动namenode和datanode节点,命令为:start-dfs.sh
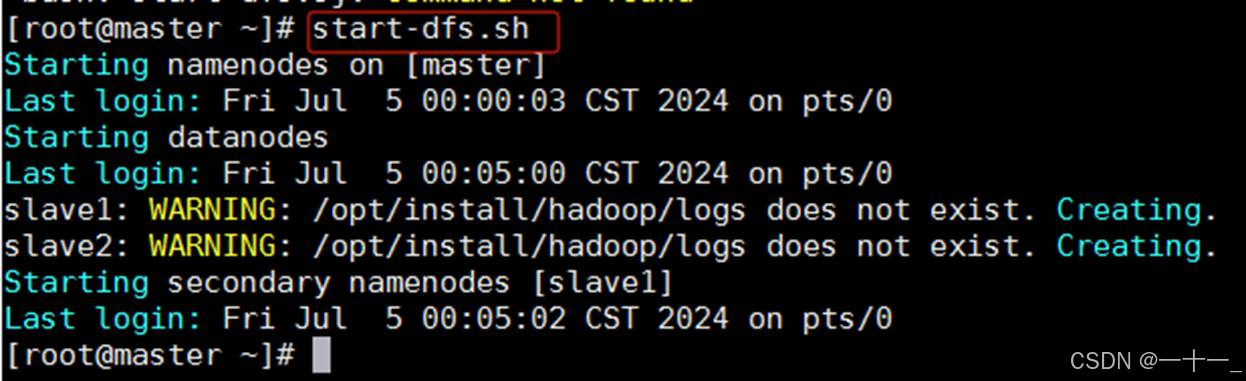
②启动resourcemanager和nodemanager
一次性启动resourcemanager和nodemanager节点,命令为:start-yarn.sh
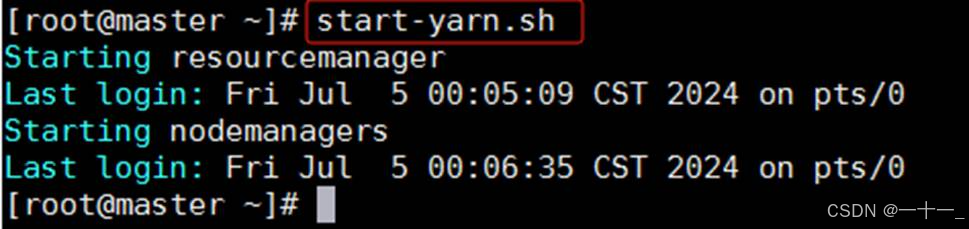
【可选】一次性启动namenode、datanode、resourcemanager和nodemanager,命令为:start-all.sh
3、停止集群
stop-dfs.sh、stop-yarn.sh【或者只使用stop-all.sh】
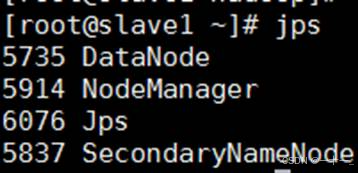
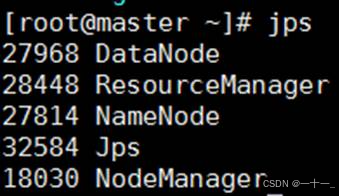
4、使用jps查看节点
各主机出现以下对应节点,说明启动成功
master主机:namenode、datanode、resourcemanager、nodemanager
slave1主机:secondarynamenode、datanode、nodemanager
slave2主机:datanode、nodemanager

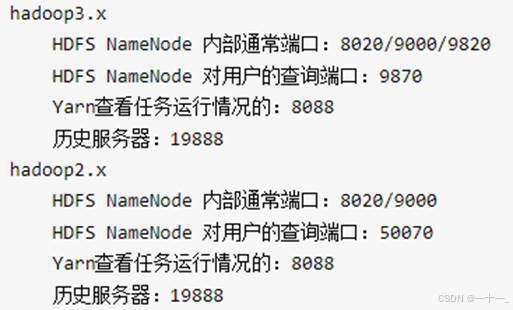
5、访问对应的web界面【通过[主机名:端口]访问】
查看namenode的web端: http://master:9870
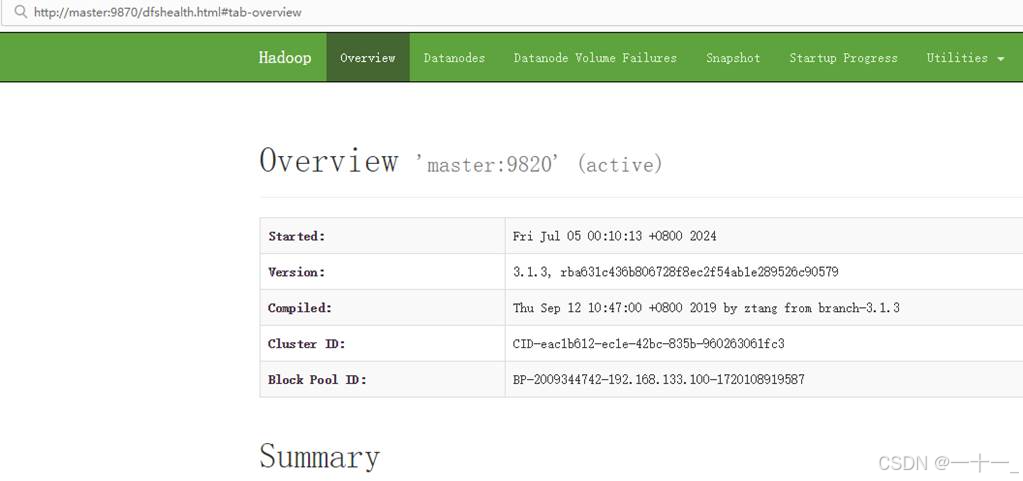
查看yarn的web端: http://master:8088

查看历史服务的web端:http://master:19888(该进程未启动的话就不用查看了)
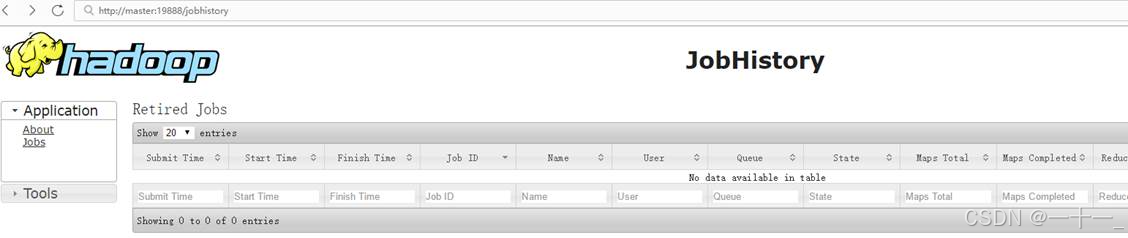
只能通过[ip:端口]访问web 端,无法通过[主机名:端口]访问
原因:本地电脑没有配置ip和主机名的映射关系,所以本地电脑无法识别主机名
解决方法:本地电脑找到hosts文件,添加映射关系
①输入路径:c:\windows\system32\drivers\etc
②打开hosts文件(使用记事本方式)
③将在虚拟机中配置过的三台主机的ip地址和主机名映射关系在hosts文件中再写一遍,然后保存即可



发表评论