
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
在输入框中输入所需的限额,例如 “1”,填写完毕后,点击“请求”按钮提交请求:
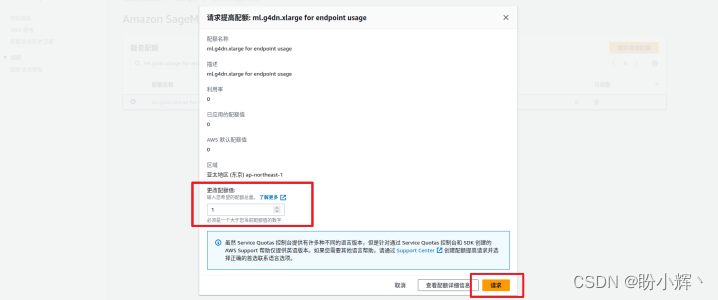
等待配额请求通过后,就可以继续该实验过程。
3.2 创建 amazon sagemaker notebook 实例
amazon sagemaker notebook 实例是运行 jupyter notebook 应用程序的机器学习计算实例。amazon sagemaker 用于管理实例和相关资源的创建,我们可以在 notetbook 实例中使用 jupyter notebook 准备和处理数据、编写代码来训练模型、或将模型部署到 amazon sagemaker 中,并测试或验证模型。接下来,我们将创建 amazon sagemaker notebook 示例,用于运行相关 jupyter notebook 代码。
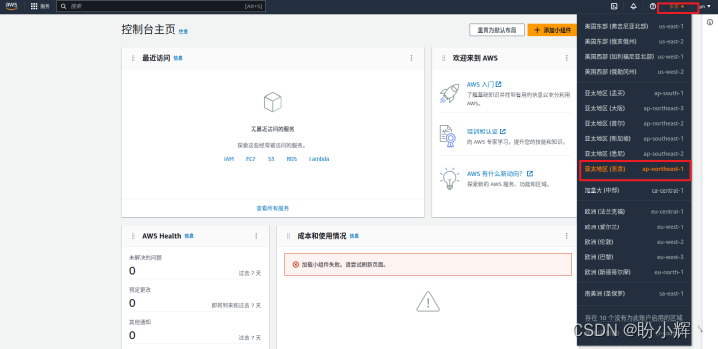
(1) 登录 amazon 云科技控制台,并将当前区域修改为 tokyo 区域:
(2) 在搜索框中搜索 amazon sagemaker,并点击进入 amazon sagemaker 服务:
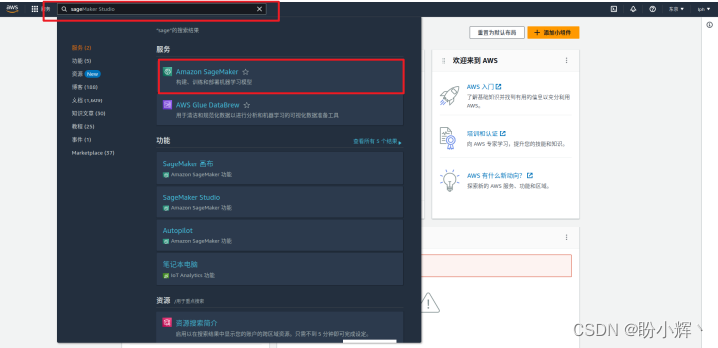
(3) 在左侧菜单栏,首先点击“笔记本”按钮,然后点击“笔记本实例”,进入笔记本 (notebook) 实例控制面板,并点击右上角”创建笔记本实例“按钮:
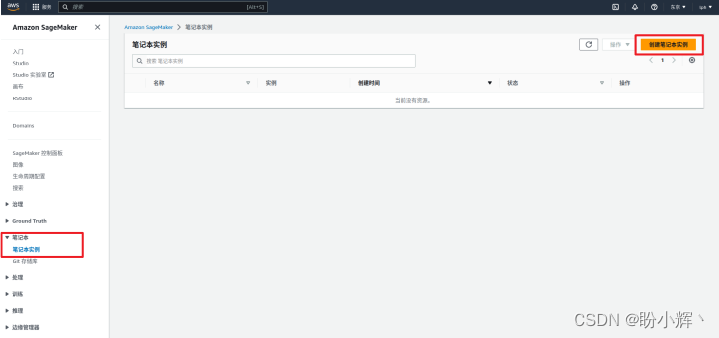
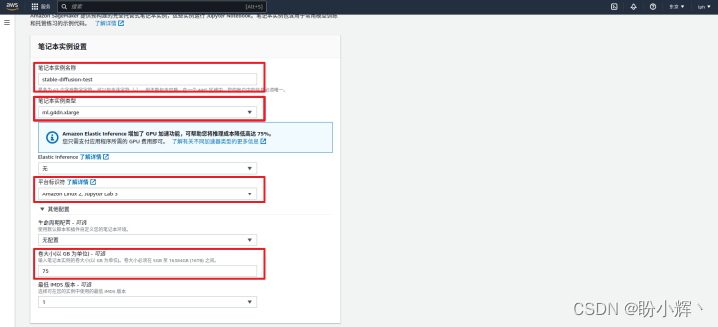
(4) 配置笔记本实例设置,在创建笔记本实例详情页中,配置笔记本实例的基本信息,包括笔记本实例名称(例如 stable-diffusion)、笔记本实例类型(选择 ml.g4dn.xlarge 实例类型,该类型实例搭载 nvidia t4 tensor core gpu 显卡,提供了模型所需执行浮点数计算的能力)、平台标识符( amazon linux 2, jupyter lab 3 )和在“其他配置”下的卷大小(推荐至少 75gb 磁盘大小,用于存储机器学习模型):
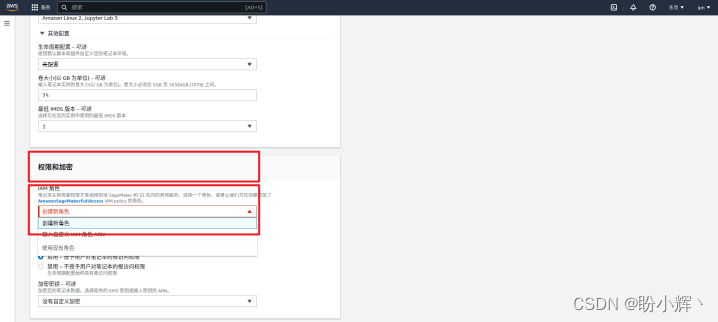
(5) 配置笔记本实例权限,为笔记本实例创建一个 iam 角色,用于调用包括 amazon sagemaker 和 s3 在内的服务,例如上传模型,部署模型等。在“权限和加密”下的 iam 角色中,点击下拉列表,单击“创建新角色”:
在配置页面中,保持默认配置,并点击“创建角色”按钮:
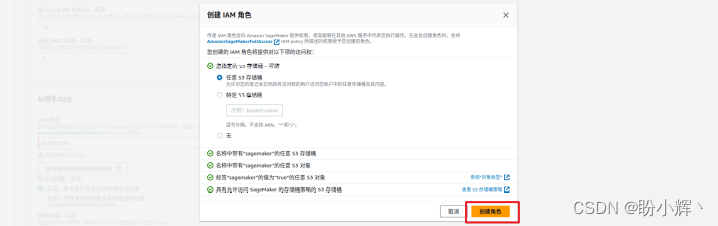
成功创建 iam 角色后,可以得到类似下图的提示信息:
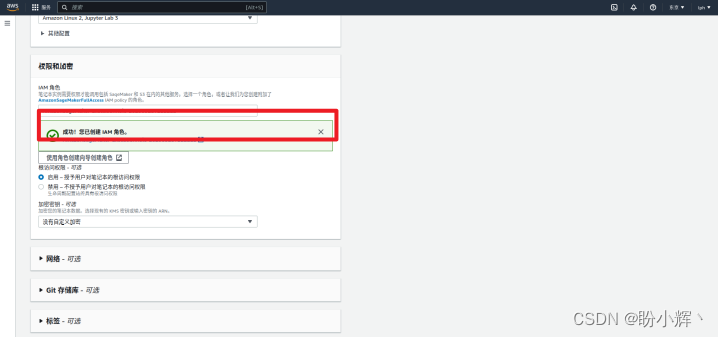
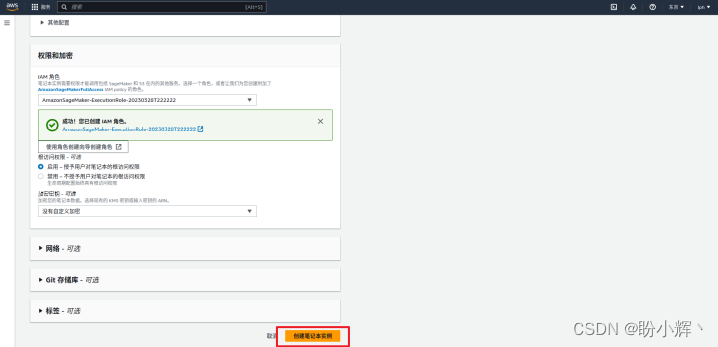
(6) 检查配置的信息,确认无误后点击“创建笔记本实例”按钮,等待实例创建完成。
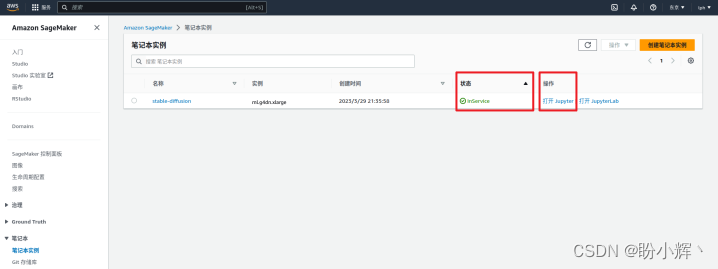
(7) 当笔记本状态变为 inservice 后,点击“打开jupyter”进入 jupyter notebook:
3.3 端到端体验 aigc
接下来,我们可以保存 notebook 代码文件,并将其上传到 jupyter notebook,然后直接运行代码,但亲手编写代码的体验是无与伦比,我们将介绍代码文件的主要内容,从头开始端到端体验 aigc!需要注意的是,需要确保 kernel 以 conda_pytorch 开头。
(1) 安装相关库并进行环境配置工作:
# 检查环境版本
!nvcc --version
!pip list | grep torch
# 安装notebook运行模型所需的库文件
!sudo yum -y install pigz
!pip install -u pip
!pip install -u transformers==4.26.1 diffusers==0.13.1 ftfy accelerate
!pip install -u torch==1.13.1+cu117 -f https://download.pytorch.org/whl/torch_stable.html
!pip install -u sagemaker
!pip list | grep torch
(2) 下载模型文件,我们将使用 stable diffusion v2 版本,其包含一个具有鲁棒性的文本生成图像模型,能够极大的提高了图像生成质量,模型相关介绍参见 github:
# 安装git lfs以克隆模型仓库
!curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.rpm.sh | sudo bash
!sudo yum install git-lfs -y
# 设定模型版本的环境变量,使用 stable diffusion v2
sd_space="stabilityai/"
sd_model = "stable-diffusion-2-1"
# 克隆代码仓库
# estimated time to spend 3min(v1), 8min(v2)
%cd ~/sagemaker
!printf "=======current path========%s\n"
!rm -rf $sd_model
# !git lfs clone https://huggingface.co/$sd\_space$sd\_model -x "\*.safetensors"
!mkdir $sd_model
%cd $sd_model
!git init
!git config core.sparsecheckout true
!echo "/\*" >> .git/info/sparse-checkout
!echo "!\*\*/\*.safetensors" >> .git/info/sparse-checkout
!git remote add -f master https://huggingface.co/$sd_space$sd_model
!git pull master main
%cd ~/sagemaker
!printf "=======folder========%s\n$(ls)\n"
(3) 在 notebook 中配置并使用模型,首先加载相关库与模型:
import torch
import datetime
from diffusers import stablediffusionpipeline
# load stable diffusion
pipe = stablediffusionpipeline.from_pretrained(sd_model, torch_dtype=torch.float16)
使用 gpu 进行运算并设定超参数,部分超参数如下:
- prompt (str 或 list[str]):引导图像生成的文本提示或文本列表
- height (int, *optional, v2 默认模型可支持到
768像素):生成图像的高度(以像素为单位) - width (int, *optional, v2 默认模型可支持到
768像素):生成图像的宽度(以像素为单位) - num_inference_steps (int, *optional, 默认降噪步数为
50):降噪步数,更多的降噪步数通常会以较慢的推理为代价获得更高质量的图像 - guidance_scale (float, *optional, 默认指导比例为
7.5):较高的指导比例会导致图像与提示密切相关,但会牺牲图像质量,当guidance_scale<=1时会被忽略 - negative_prompt (str or list[str], *optional):不引导图像生成的文本或文本列表
- num_images_per_prompt (int, *optional, 默认每个提示生成
1张图像):每个提示生成的图像数量
# move model to the gpu
torch.cuda.empty_cache()
pipe = pipe.to("cuda")
print(datetime.datetime.now())
prompts =[
"eiffel tower landing on the mars",
"a photograph of an astronaut riding a horse,van gogh style",
]
generated_images = pipe(
prompt=prompts,
height=512,
width=512,
num_images_per_prompt=1
).images # image here is in [pil format](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)
print(f"prompts: {prompts}\n")
print(datetime.datetime.now())
for image in generated_images:
display(image)
(4) 将模型部署至 sagemaker inference endpoint,构建和训练模型后,可以将模型部署至终端节点,以获取预测推理结果:
import sagemaker
import boto3
sess = sagemaker.session()
# sagemaker session bucket -> used for uploading data, models and logs
# sagemaker will automatically create this bucket if it not exists
sagemaker_session_bucket=none
if sagemaker_session_bucket is none and sess is not none:
# set to default bucket if a bucket name is not given
sagemaker_session_bucket = sess.default_bucket()
try:
role = sagemaker.get_execution_role()
except valueerror:
iam = boto3.client('iam')
role = iam.get_role(rolename='sagemaker\_execution\_role')['role']['arn']
sess = sagemaker.session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default\_bucket()}")
print(f"sagemaker session region: {sess.boto\_region\_name}")
创建自定义推理脚本 inference.py:
!mkdir ./$sd_model/code
# 为模型创建所需依赖声明的文件
%%writefile ./$sd_model/code/requirements.txt
diffusers==0.13.1
transformers==4.26.1
# 编写 inference.py 脚本
%%writefile ./$sd_model/code/inference.py
import base64
import torch
from io import bytesio
from diffusers import stablediffusionpipeline
def model\_fn(model_dir):
# load stable diffusion and move it to the gpu
pipe = stablediffusionpipeline.from_pretrained(model_dir, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
return pipe
def predict\_fn(data, pipe):
# get prompt & parameters
prompt = data.pop("prompt", "")
# set valid hp for stable diffusion
height = data.pop("height", 512)
width = data.pop("width", 512)
num_inference_steps = data.pop("num\_inference\_steps", 50)
guidance_scale = data.pop("guidance\_scale", 7.5)
num_images_per_prompt = data.pop("num\_images\_per\_prompt", 1)
# run generation with parameters
generated_images = pipe(
prompt=prompt,
height=height,
width=width,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
num_images_per_prompt=num_images_per_prompt,
)["images"]
# create response
encoded_images = []
for image in generated_images:
buffered = bytesio()
image.save(buffered, format="jpeg")
encoded_images.append(base64.b64encode(buffered.getvalue()).decode())
# create response
return {"generated\_images": encoded_images}
打包模型并上传至 s3 桶:
#package model, estimated time to spend 2min(v1),5min(v2)
!echo $(date)
!tar --exclude .git --use-compress-program=pigz -pcvf ./$sd_model'.tar.gz' -c ./$sd_model/ .
!echo $(date)
from sagemaker.s3 import s3uploader
print(datetime.datetime.now())
# upload model.tar.gz to s3, estimated time to spend 30s(v1), 1min(v2)
sd_model_uri=s3uploader.upload(local_path=f"{sd\_model}.tar.gz", desired_s3_uri=f"s3://{sess.default\_bucket()}/stable-diffusion")
print(f"=======s3 file location========\nmodel uploaded to:\n{sd\_model\_uri}")
print(datetime.datetime.now())
使用 huggingface 将模型部署至 amazon sagemaker:
#init variables
huggingface_model = {}
predictor = {}
from sagemaker.huggingface.model import huggingfacemodel
# create hugging face model class
huggingface_model[sd_model] = huggingfacemodel(
model_data=sd_model_uri, # path to your model and script
role=role, # iam role with permissions to create an endpoint
transformers_version="4.17", # transformers version used
pytorch_version="1.10", # pytorch version used
py_version='py38', # python version used
)
# deploy the endpoint endpoint, estimated time to spend 8min(v2)
print(datetime.datetime.now())
predictor[sd_model] = huggingface_model[sd_model].deploy(
initial_instance_count=1,
instance_type="ml.g4dn.xlarge",
endpoint_name=f"{sd\_model}-endpoint"
)
print(f"\n{datetime.datetime.now()}")
基于推理终端节点生成自定义图片:
from pil import image
from io import bytesio
import base64
# helper decoder
def decode\_base64\_image(image_string):
base64_image = base64.b64decode(image_string)
buffer = bytesio(base64_image)
return image.open(buffer)
response = predictor[sd_model].predict(data={
"prompt": [
"a bird is flying in space",
"a photograph of an astronaut riding a horse",
],
"height" : 512,
"width" : 512,
"num\_images\_per\_prompt":1
}
)
#decode images
decoded_images = [decode_base64_image(image) for image in response["generated\_images"]]
#visualize generation
for image in decoded_images:
display(image)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事it行业的老鸟或是对it行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
splay(image)
[外链图片转存中...(img-vvkx13vs-1715401945337)]
[外链图片转存中...(img-go2ayydy-1715401945337)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事it行业的老鸟或是对it行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
发表评论