flink 的八种分区策略(源码解读)
flink 包含 8 种分区策略,这 8 种分区策略(分区器)分别如下面所示,本文将从源码的角度解读每个分区器的实现方式。
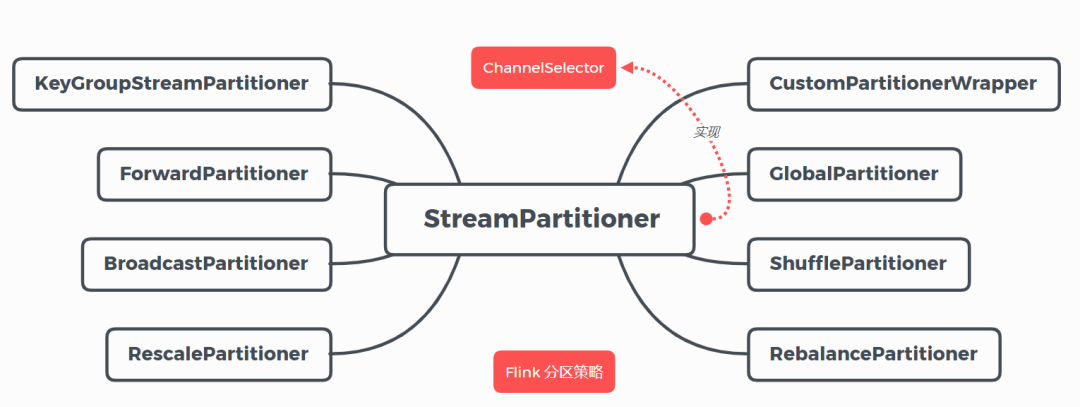
globalpartitionershufflepartitionerrebalancepartitionerrescalepartitionerbroadcastpartitionerforwardpartitionerkeygroupstreampartitionercustompartitionerwrapper
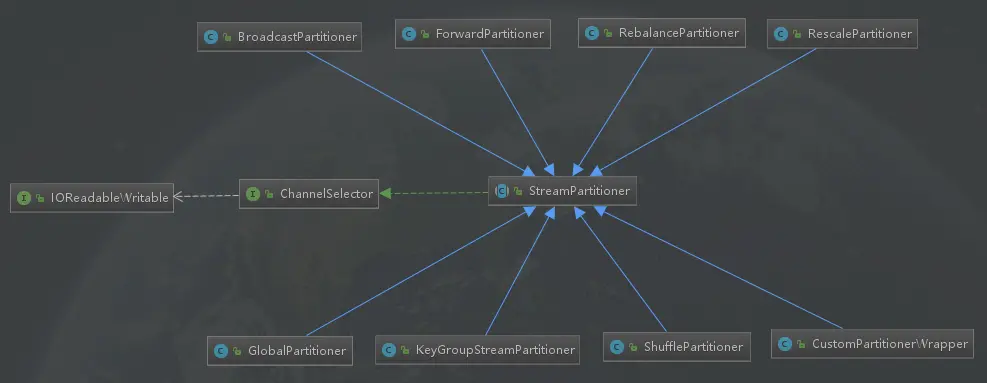
1.继承关系图
1.1 接口:channelselector
public interface channelselector<t extends ioreadablewritable> {
/**
* 初始化channels数量,channel可以理解为下游operator的某个实例(并行算子的某个subtask).
*/
void setup(int numberofchannels);
/**
*根据当前的record以及channel总数,
*决定应将record发送到下游哪个channel。
*不同的分区策略会实现不同的该方法。
*/
int selectchannel(t record);
/**
*是否以广播的形式发送到下游所有的算子实例
*/
boolean isbroadcast();
}
1.2 抽象类:streampartitioner
public abstract class streampartitioner<t> implements
channelselector<serializationdelegate<streamrecord<t>>>, serializable {
private static final long serialversionuid = 1l;
protected int numberofchannels;
@override
public void setup(int numberofchannels) {
this.numberofchannels = numberofchannels;
}
@override
public boolean isbroadcast() {
return false;
}
public abstract streampartitioner<t> copy();
}
1.3 继承关系图
2.分区策略
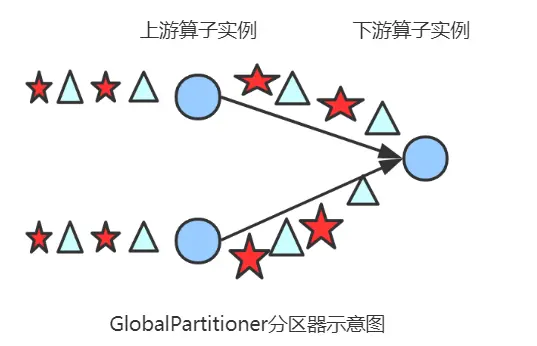
2.1 globalpartitioner
该分区器会将所有的数据都发送到下游的某个算子实例(subtask id = 0)。
/**
* 发送所有的数据到下游算子的第一个task(id = 0)
* @param <t>
*/
@internal
public class globalpartitioner<t> extends streampartitioner<t> {
private static final long serialversionuid = 1l;
@override
public int selectchannel(serializationdelegate<streamrecord<t>> record) {
//只返回0,即只发送给下游算子的第一个task
return 0;
}
@override
public streampartitioner<t> copy() {
return this;
}
@override
public string tostring() {
return "global";
}
}
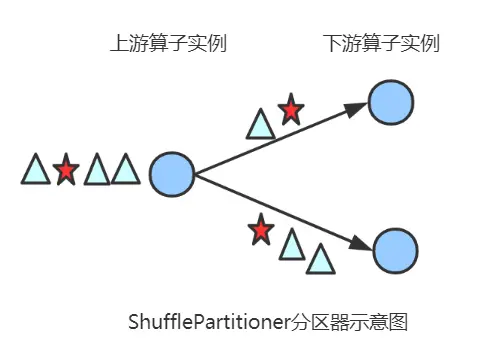
2.2 shufflepartitioner
随机选择一个下游算子实例进行发送。
/**
* 随机的选择一个channel进行发送
* @param <t>
*/
@internal
public class shufflepartitioner<t> extends streampartitioner<t> {
private static final long serialversionuid = 1l;
private random random = new random();
@override
public int selectchannel(serializationdelegate<streamrecord<t>> record) {
//产生[0,numberofchannels)伪随机数,随机发送到下游的某个task
return random.nextint(numberofchannels);
}
@override
public streampartitioner<t> copy() {
return new shufflepartitioner<t>();
}
@override
public string tostring() {
return "shuffle";
}
}
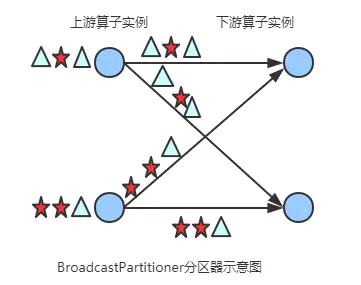
2.3 broadcastpartitioner
发送到下游所有的算子实例。
/**
* 发送到所有的channel
*/
@internal
public class broadcastpartitioner<t> extends streampartitioner<t> {
private static final long serialversionuid = 1l;
/**
* broadcast模式是直接发送到下游的所有task,所以不需要通过下面的方法选择发送的通道
*/
@override
public int selectchannel(serializationdelegate<streamrecord<t>> record) {
throw new unsupportedoperationexception("broadcast partitioner does not support select channels.");
}
@override
public boolean isbroadcast() {
return true;
}
@override
public streampartitioner<t> copy() {
return this;
}
@override
public string tostring() {
return "broadcast";
}
}
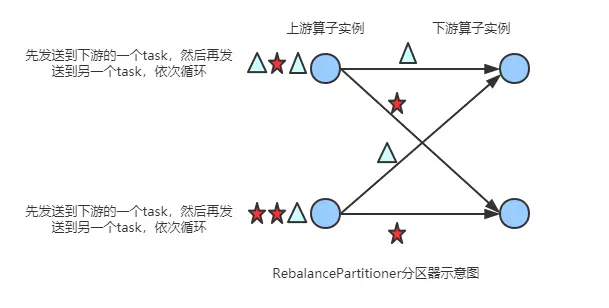
2.4 rebalancepartitioner
通过循环的方式依次发送到下游的 task。
/**
*通过循环的方式依次发送到下游的task
* @param <t>
*/
@internal
public class rebalancepartitioner<t> extends streampartitioner<t> {
private static final long serialversionuid = 1l;
private int nextchanneltosendto;
@override
public void setup(int numberofchannels) {
super.setup(numberofchannels);
//初始化channel的id,返回[0,numberofchannels)的伪随机数
nextchanneltosendto = threadlocalrandom.current().nextint(numberofchannels);
}
@override
public int selectchannel(serializationdelegate<streamrecord<t>> record) {
//循环依次发送到下游的task,比如:nextchanneltosendto初始值为0,numberofchannels(下游算子的实例个数,并行度)值为2
//则第一次发送到id = 1的task,第二次发送到id = 0的task,第三次发送到id = 1的task上...依次类推
nextchanneltosendto = (nextchanneltosendto + 1) % numberofchannels;
return nextchanneltosendto;
}
public streampartitioner<t> copy() {
return this;
}
@override
public string tostring() {
return "rebalance";
}
}
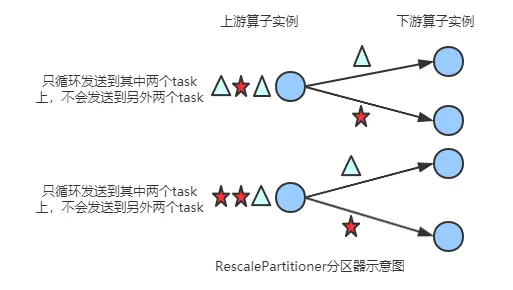
2.5 rescalepartitioner
基于上下游 operator 的并行度,将记录以循环的方式输出到下游 operator 的每个实例。
举例:
- 上游并行度是 2,下游是 4,则上游一个并行度以循环的方式将记录输出到下游的两个并行度上;上游另一个并行度以循环的方式将记录输出到下游另两个并行度上。
- 若上游并行度是 4,下游并行度是 2,则上游两个并行度将记录输出到下游一个并行度上;上游另两个并行度将记录输出到下游另一个并行度上。
@internal
public class rescalepartitioner<t> extends streampartitioner<t> {
private static final long serialversionuid = 1l;
private int nextchanneltosendto = -1;
@override
public int selectchannel(serializationdelegate<streamrecord<t>> record) {
if (++nextchanneltosendto >= numberofchannels) {
nextchanneltosendto = 0;
}
return nextchanneltosendto;
}
public streampartitioner<t> copy() {
return this;
}
@override
public string tostring() {
return "rescale";
}
}
flink 中的执行图可以分成四层:streamgraph ➡ jobgraph ➡ executiongraph ➡ 物理执行图。
- streamgraph:是根据用户通过 stream api 编写的代码生成的最初的图。用来表示程序的拓扑结构。
- jobgraph:streamgraph 经过优化后生成了 jobgraph,提交给 jobmanager 的数据结构。主要的优化为,将多个符合条件的节点
chain在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化 / 反序列化 / 传输消耗。 - executiongraph:jobmanager 根据 jobgraph 生成 executiongraph。executiongraph 是 jobgraph 的并行化版本,是调度层最核心的数据结构。
- 物理执行图:jobmanager 根据 executiongraph 对 job 进行调度后,在各个 taskmanager 上部署 task 后形成的 “图”,并不是一个具体的数据结构。
而 streamingjobgraphgenerator 就是 streamgraph 转换为 jobgraph。在这个类中,把 forwardpartitioner 和 rescalepartitioner 列为 pointwise 分配模式,其他的为 all_to_all 分配模式。代码如下:
if (partitioner instanceof forwardpartitioner || partitioner instanceof rescalepartitioner) {
jobedge = downstreamvertex.connectnewdatasetasinput(
headvertex,
// 上游算子(生产端)的实例(subtask)连接下游算子(消费端)的一个或者多个实例(subtask)
distributionpattern.pointwise,
resultpartitiontype);
} else {
jobedge = downstreamvertex.connectnewdatasetasinput(
headvertex,
// 上游算子(生产端)的实例(subtask)连接下游算子(消费端)的所有实例(subtask)
distributionpattern.all_to_all,
resultpartitiontype);
}
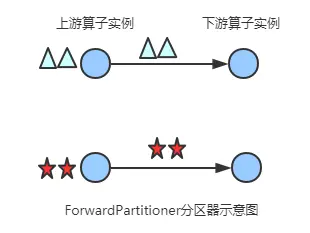
2.6 forwardpartitioner
发送到下游对应的第一个 task,保证上下游算子并行度一致,即上游算子与下游算子是
1
:
1
1:1
1:1 的关系。
/**
* 发送到下游对应的第一个task
* @param <t>
*/
@internal
public class forwardpartitioner<t> extends streampartitioner<t> {
private static final long serialversionuid = 1l;
@override
public int selectchannel(serializationdelegate<streamrecord<t>> record) {
return 0;
}
public streampartitioner<t> copy() {
return this;
}
@override
public string tostring() {
return "forward";
}
}
在上下游的算子没有指定分区器的情况下,如果上下游的算子并行度一致,则使用 forwardpartitioner,否则使用 rebalancepartitioner,对于 forwardpartitioner,必须保证上下游算子并行度一致,否则会抛出异常。
//在上下游的算子没有指定分区器的情况下,如果上下游的算子并行度一致,则使用forwardpartitioner,否则使用rebalancepartitioner
if (partitioner == null && upstreamnode.getparallelism() == downstreamnode.getparallelism()) {
partitioner = new forwardpartitioner<object>();
} else if (partitioner == null) {
partitioner = new rebalancepartitioner<object>();
}
if (partitioner instanceof forwardpartitioner) {
//如果上下游的并行度不一致,会抛出异常
if (upstreamnode.getparallelism() != downstreamnode.getparallelism()) {
throw new unsupportedoperationexception("forward partitioning does not allow " +
"change of parallelism. upstream operation: " + upstreamnode + " parallelism: " + upstreamnode.getparallelism() +
", downstream operation: " + downstreamnode + " parallelism: " + downstreamnode.getparallelism() +
" you must use another partitioning strategy, such as broadcast, rebalance, shuffle or global.");
}
}
2.7 keygroupstreampartitioner
根据 key 的分组索引选择发送到相对应的下游 subtask。
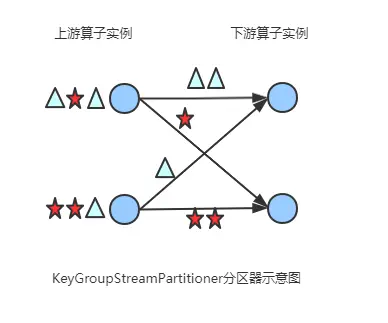
org.apache.flink.streaming.runtime.partitioner.keygroupstreampartitioner
/**
* 根据key的分组索引选择发送到相对应的下游subtask
* @param <t>
* @param <k>
*/
@internal
public class keygroupstreampartitioner<t, k> extends streampartitioner<t> implements configurablestreampartitioner {
...
@override
public int selectchannel(serializationdelegate<streamrecord<t>> record) {
k key;
try {
key = keyselector.getkey(record.getinstance().getvalue());
} catch (exception e) {
throw new runtimeexception("could not extract key from " + record.getinstance().getvalue(), e);
}
//调用keygrouprangeassignment类的assignkeytoparalleloperator方法,代码如下所示
return keygrouprangeassignment.assignkeytoparalleloperator(key, maxparallelism, numberofchannels);
}
...
}
org.apache.flink.runtime.state.keygrouprangeassignment
public final class keygrouprangeassignment {
...
/**
* 根据key分配一个并行算子实例的索引,该索引即为该key要发送的下游算子实例的路由信息,
* 即该key发送到哪一个task
*/
public static int assignkeytoparalleloperator(object key, int maxparallelism, int parallelism) {
preconditions.checknotnull(key, "assigned key must not be null!");
return computeoperatorindexforkeygroup(maxparallelism, parallelism, assigntokeygroup(key, maxparallelism));
}
/**
*根据key分配一个分组id(keygroupid)
*/
public static int assigntokeygroup(object key, int maxparallelism) {
preconditions.checknotnull(key, "assigned key must not be null!");
//获取key的hashcode
return computekeygroupforkeyhash(key.hashcode(), maxparallelism);
}
/**
* 根据key分配一个分组id(keygroupid),
*/
public static int computekeygroupforkeyhash(int keyhash, int maxparallelism) {
//与maxparallelism取余,获取keygroupid
return mathutils.murmurhash(keyhash) % maxparallelism;
}
//计算分区index,即该key group应该发送到下游的哪一个算子实例
public static int computeoperatorindexforkeygroup(int maxparallelism, int parallelism, int keygroupid) {
return keygroupid * parallelism / maxparallelism;
}
...
2.8 custompartitionerwrapper
通过 partitioner 实例的 partition 方法(自定义的)将记录输出到下游。
public class custompartitionerwrapper<k, t> extends streampartitioner<t> {
private static final long serialversionuid = 1l;
partitioner<k> partitioner;
keyselector<t, k> keyselector;
public custompartitionerwrapper(partitioner<k> partitioner, keyselector<t, k> keyselector) {
this.partitioner = partitioner;
this.keyselector = keyselector;
}
@override
public int selectchannel(serializationdelegate<streamrecord<t>> record) {
k key;
try {
key = keyselector.getkey(record.getinstance().getvalue());
} catch (exception e) {
throw new runtimeexception("could not extract key from " + record.getinstance(), e);
}
//实现partitioner接口,重写partition方法
return partitioner.partition(key, numberofchannels);
}
@override
public streampartitioner<t> copy() {
return this;
}
@override
public string tostring() {
return "custom";
}
}
比如:
public class custompartitioner implements partitioner<string> {
// key: 根据key的值来分区
// numpartitions: 下游算子并行度
@override
public int partition(string key, int numpartitions) {
return key.length() % numpartitions;//在此处定义分区策略
}
}



发表评论