安装
1.安装jdk:sudo apt-get install openjdk-8-jdk (kafka需要在jvm上运行)
验证安装结果:java -version
2.安装kafka:wget https://downloads.apache.org/kafka/3.5.1/kafka_2.13-3.5.1.tgz (下载官网离线安装包)
解压:tar -xzf ... -c /usr/local (解压到/usr/local目录下)
运行:
在kafka目录下启动zookeeper: bin/zookeeper-server-start.sh config/zookeeper.properties
启动kafka :bin/kafka-server-start.sh config/server.properties
查看kafka版本:bin/kafka-topics.sh --version
创建topic:bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --topic test --partitions 1 --replication-factor 1
...
kafka为什么快
数据分片(每个topic会把数据切分为多个partition,每个partition有自己对应的副本保证可靠性,但是副本在leader partition down掉前不会提供服务)可以横向扩容
连续读速度快
kafka虽然跑在jvm上但是使用堆外内存(内核缓冲区内存)pagecache,所以不需要做内存回收。
kafka会自动预热,把数据加载到缓冲区里
pagecache:linux内核态缓存
虚拟内存空间:分配给进程的一个逻辑内存空间,通过操作系统的page table(页映射表)对应到物理内存。
kafka的windows适配性不好
kafka ack保证数据写到内存里,刷盘策略决定数据什么时候落盘,所以ack不能保证数据不会丢失。
零拷贝
减少内核态缓冲区到用户态缓冲区的cpu拷贝
dma拷贝:io到内核的拷贝
普通拷贝:
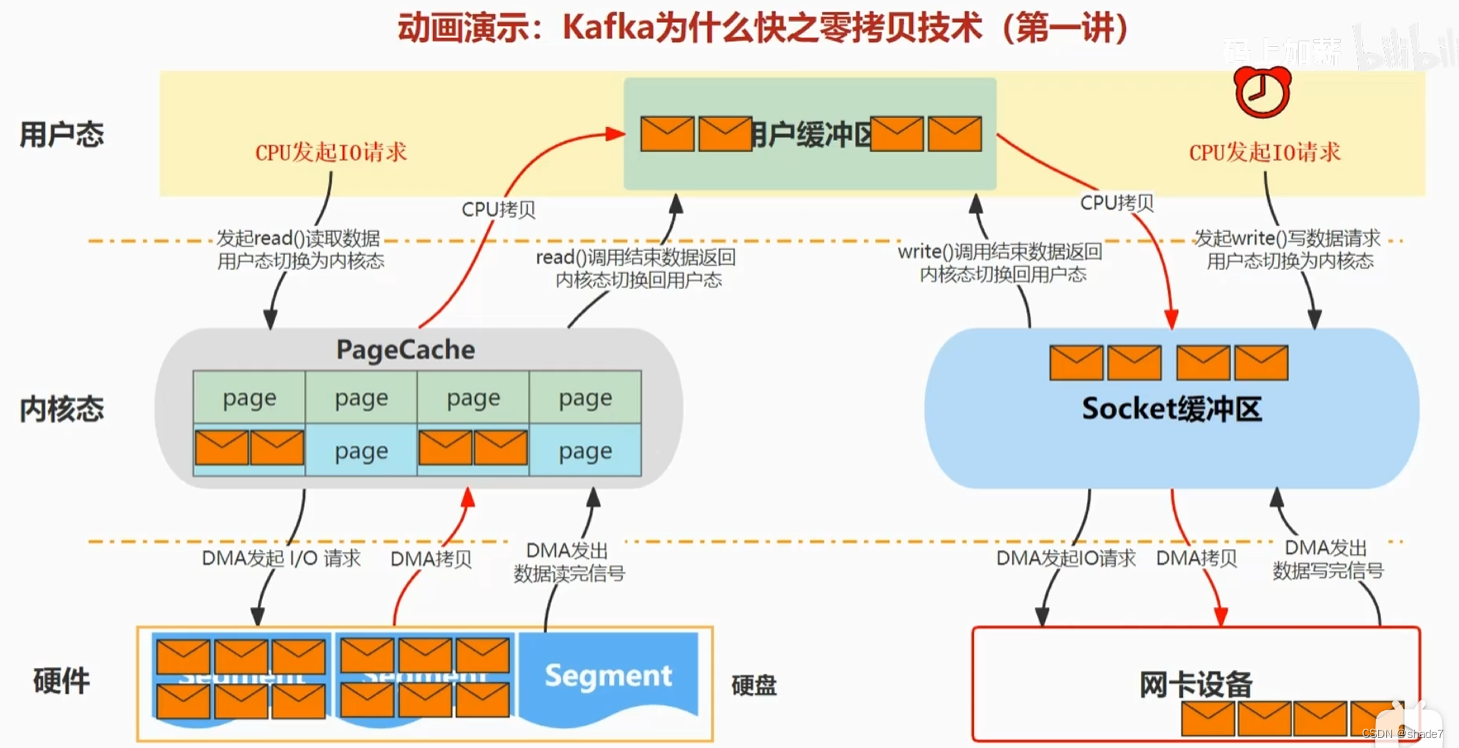
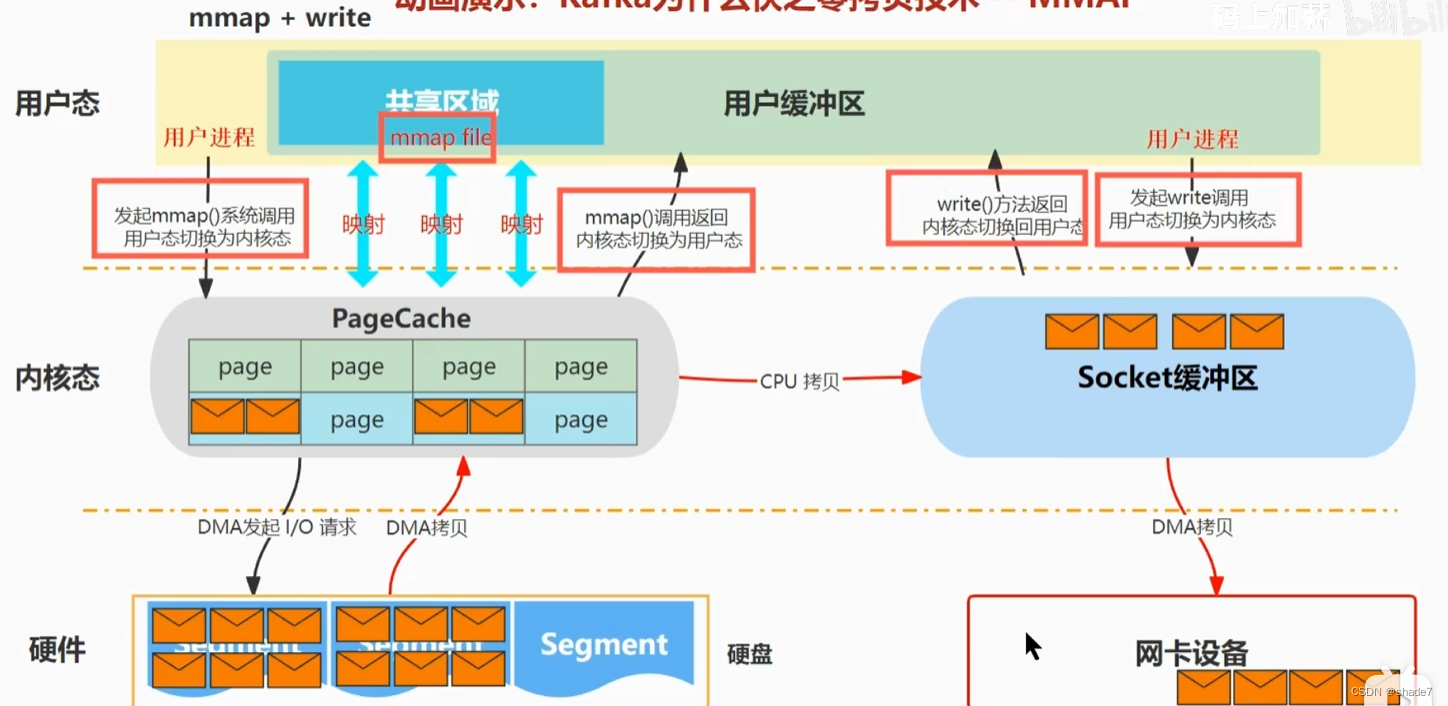
零拷贝:
producer的消息会包含key,来决定消息发送到哪个partition。
producer按批次发送数据,当数据停留指定时间或者数据达到一定量时,发送给kafka 中对应partition的leader 副本所在的broker节点的socket receive buffer;
socket通过network threads将数据包装成一个请求置入reque queue,然后通过一个io线程写入到page cache,pagecache根据刷盘策略落盘;
为了保证落盘前的数据可靠性,会将数据备份到其他的broker上,(follower副本会向leader副本拉取数据,这些follower在leader 副本 down掉前,只做备份,不会被使用。)
副本备份完毕后,会发送给producer一个ack,其中可以在network threads控制消息的顺序(上一条消息存储失败,则下一条数据卡在socket receive buffer)

hdd(机械硬盘)和ssd的随机写与顺序写
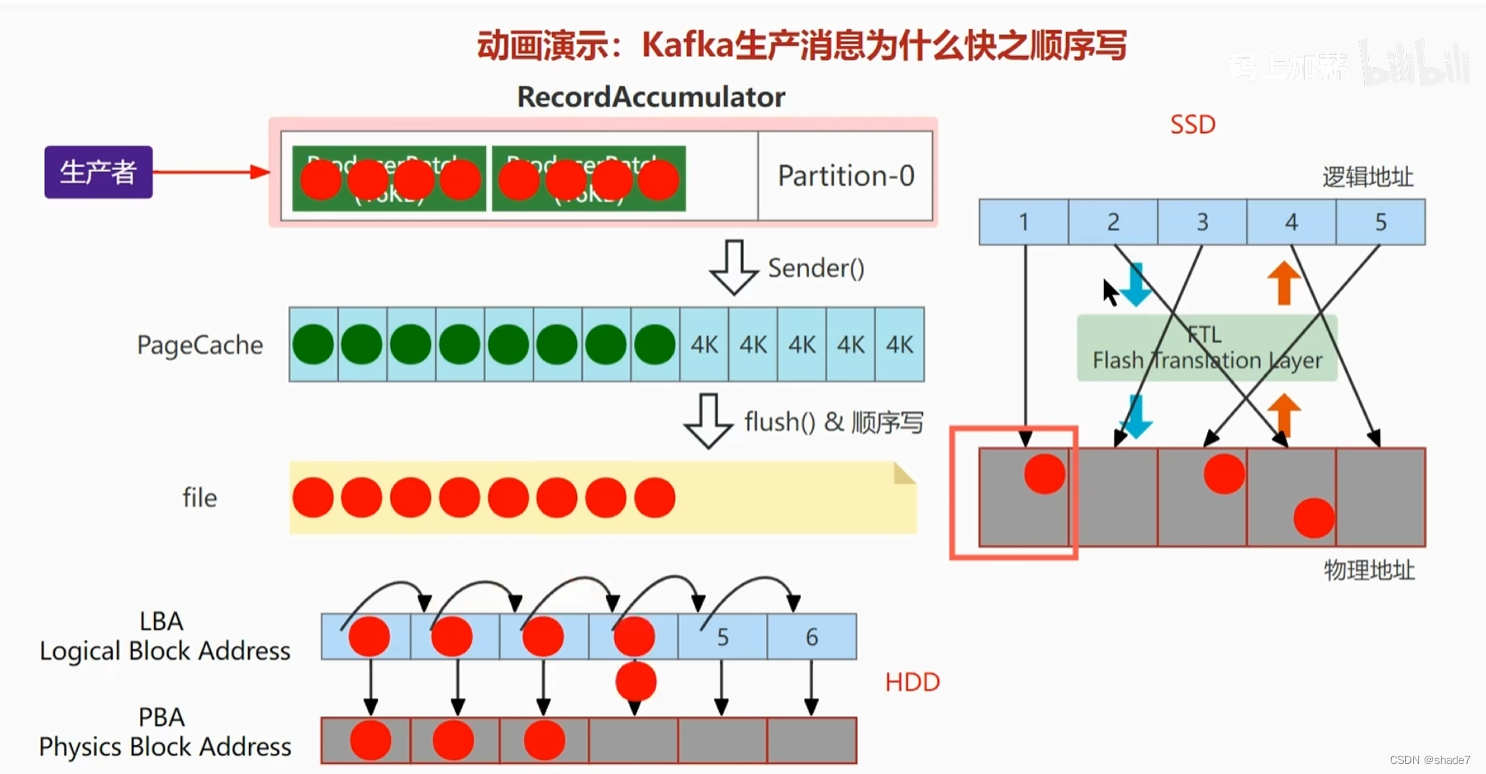
hdd :随机写时间浪费在寻址和旋转盘片
ssd:写入数据时,需要先擦除一块物理地址,然后写入在这块地址上的一个page里;因此随机写浪费在擦出有用数据时的数据迁移,并且会造成盘碎片化。
混合云
私有云+公有云
私有云:企业自己建设并为内部提供服务,企业可以更严格地控制访问权限和数据管理。
公有云:第三方云厂商所拥有和运营,用户通过互联网使用这些服务;用户只有服务的使用权,数据的控制权相对较弱。
机器扩容 超过 mysql连接数 导致服务崩溃


发表评论