目录
一、seed定义
二、为什么要使用seed()随机种子?
- 可重复性: 在科学实验、模型训练等需要随机性但也需要可重复性的场景下,设置种子可以确保多次运行产生相同的随机数序列,方便验证和调试。
- 复现性: 在机器学习中,如果模型的随机初始化在不同的训练运行中是随机的,那么结果可能会有所不同。通过设置种子,可以确保每次训练使用相同的初始权重,以便比较和分析模型性能。
三、随机种子在不同库中的使用
- python 中的 random 模块:random.seed(seed_value),用于生成伪随机数序列。
- numpy 中的 numpy.random:numpy.random.seed(seed_value),用于生成 numpy 库中的随机数组。
- 机器学习库中的随机性控制:比如 pytorch 中的 torch.manual_seed(seed) 用于控制随机数生成,在模型训练中确保重复性。
- 深度学习框架中的 gpu 随机性控制:对于使用 gpu 的深度学习框架(如 pytorch、tensorflow),通常也会有类似 torch.cuda.manual_seed(seed) 的函数,用于设置 gpu 相关的随机种子,以保证实验结果的一致性。
3.1 random.seed(seed)
代码实现:
import random
seed_value = 42 #可以随机设置
random.seed(seed_value)
for i in range(5):
random_number = random.random()
print('random_number_{}:{}'.format(i, random_number))
输出结果:
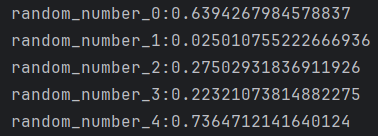
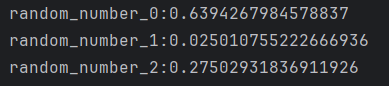
当我修改循环次数为3时,会发现输出结果和循环5次生成的前三次结果相同。
3.2 np.random.seed(seed)
代码实现:
import numpy as np
seed_value = 42 # 可以随机设置
np.random.seed(seed_value)
for i in range(5): #第二次修改成6
numpy_number = np.random.rand(3) # 生成数组
print('numpy_number_{}:{}'.format(i, numpy_number))
循环5次和循环6次输出结果如下,通过输出结果可以看出,两次输出的前5个数组内容相等。
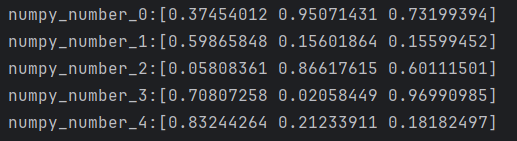
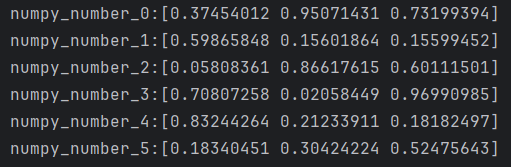
3.3 torch.manual_seed(seed)
代码实现:
import torch
# 设置cpu上的随机数生成器种子
seed_value = 42
torch.manual_seed(seed_value)
# 生成随机张量
random_tensor_cpu = torch.rand(3)
print("random tensor (cpu):", random_tensor_cpu)
输出结果:

在这个例子中,我们使用torch.rand(3)生成一个包含三个随机数的张量,并在之前设置了cpu上的随机数生成器种子。如果你多次运行这段代码,你会发现生成的随机张量在每次运行时都是相同的,这证明了torch.manual_seed(seed)在cpu上的作用。
值得注意的是,当你使用gpu时,如果没有设置gpu上的随机数生成器的种子,即使在cpu上设置了种子,gpu上生成的随机数仍然可能是不同的。因此,如果你在实验中使用了gpu,最好也设置一下gpu上的随机数生成器种子,使用 torch.cuda.manual_seed(seed)。
3.4 torch.cuda.manual_seed(seed)
代码实现:
import torch
seed_value = 42
torch.manual_seed(seed_value) # 放到cpu中
torch.cuda.manual_seed(seed_value) # 放到gpu中
if torch.cuda.is_available():
# 在gpu上生成随机张量
for i in range(3):
random_tensor_gpu = torch.rand(3).cuda()
print("random tensor (gpu):", random_tensor_gpu)
else:
print("cuda is not available.")
循环3次和循环5次的输出结果如下:


多次运行代码并且每次都得到相同的随机张量,那么你就可以确定torch.cuda.manual_seed(seed)成功设置了gpu上的随机数生成器的种子。这样可以确保在使用gpu进行计算时,实验结果的随机性是可控的,可以得到可重复的结果。
但是需要注意,经过测试,设置gpu种子的时候没有使用torch.manual_seed(seed_value),那么生成的随机数组每次都不一样,所以想要设置gpu上生成随机数每次一样,必须将随机种子同时放到cpu和gpu上。
四、注意事项
- 全局性: 设置种子是全局性的,一旦设置,会影响整个随机数生成器的行为,包括其他使用该随机数生成器的代码。
- 不同版本之间的兼容性: 不同版本的库可能会对随机数生成器的实现方式有所不同,因此在不同版本间可能会有微小的差异。
- 线程安全性: 在多线程环境下,设置种子需要特别小心,以避免竞争条件导致的问题。
总的来说,seed() 函数是一个控制随机性并确保实验结果可复现性的重要工具,但在使用时需要考虑全局影响和不同库之间的差异。

发表评论