
 个人主页:在线oj的阿川
个人主页:在线oj的阿川
大佬的支持和鼓励,将是我成长路上最大的动力
阿川水平有限,如有错误,欢迎大佬指正


统计学
- 描述统计学
- 推断统计学
推断统计学简介
推断统计学
- 涉及假设检验
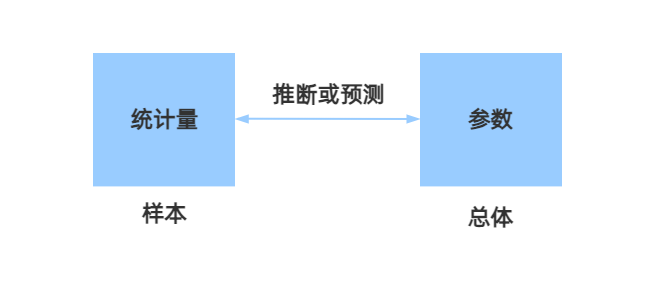
- 通过样本做出关于总体的推断或预测
- 样本:也称之为对象
- 统计量:描述样本特征的数值
- 总体:所有对象的集合
- 参数:特征的数值
- 样本:也称之为对象
- 通过样本做出关于总体的推断或预测
t检验/z检验概述
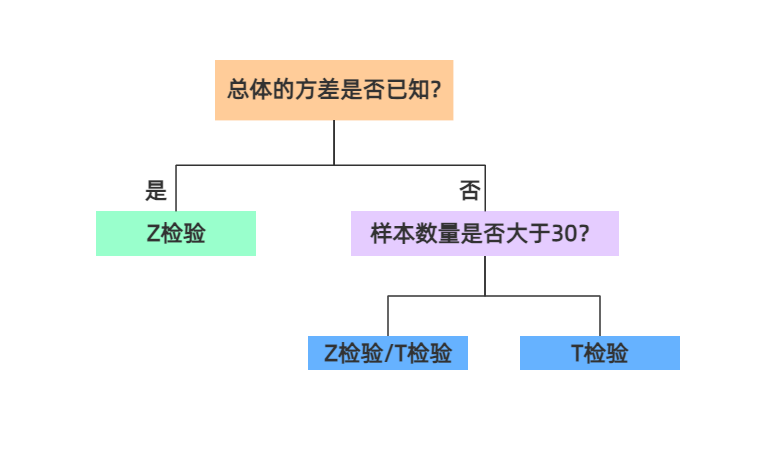
推断统计学中会涉及t检验和z检验(重点)
独立双样本t检验或z检验
- 独立:不同的总体,彼此之间无关联
- 双样本:比较两个不同样本
- t检验/z检验:用于确定样本的平均值之间 是否存在统计显著性(排除随机可能性)
- z检验相对于t检验而言,可以提供更高准确性和敏感性
前提条件
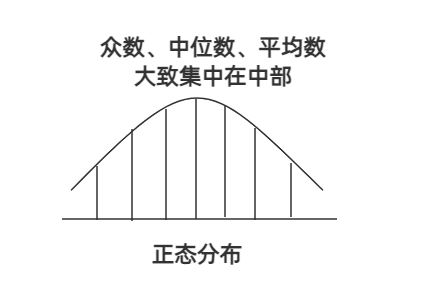
- 随机抽样
- 总体大致呈正态分布
- 中间值多
- 两边极端值少
- ( z检验)总体方差要已知或样本量大于30
检验具体实现
步骤一 建立假设
原假设h0(一般为不支持的可能)
参数a不高于参数b
备择假设h1(一般为支持的可能)
参数a高于参数b

步骤二 选择单尾或双尾检验
双尾:推断总体是否有差异,正差异和负差异都可以,不在乎 谁大谁小。
- 原假设:两个参数存在差异
- 备择假设:两个参数不存在差异
单尾:检验差异为正差异和负差异,在乎谁大谁小。
- 原假设:参数a没有大于参数b
- 备择假设:参数a大于参数b
或者 - 原假设:参数a没有小于参数b
- 备择假设:参数a小于参数b
步骤三 确定显著水平
允许检验犯错误的概率
- 允许检验犯错误的概率高,表示检验宽松
- 允许检验犯错误的概率低,表示检验严格
显著水平数值
-
双尾应小于0.05
- 表示如果检验结果是 拒绝原假设,原假设实际为 真概率为5%
- 即如果检验结果是 拒绝原假设,结论95%概率是对的。
- 表示如果检验结果是 拒绝原假设,原假设实际为 真概率为5%
-
单尾应小于0.025
- 表示如果检验结果是 拒绝原假设,原假设实际为真概率为2.5%
- 即如果检验结果是 拒绝原假设,结论97.5%概率是对的
- 表示如果检验结果是 拒绝原假设,原假设实际为真概率为2.5%

不同的项目,显著水平设定会有所不同(例如医药临床方面,显著水平设为一般为0.01)
显著性水平一般用alpha字母表示,用if跟p值进行比较来进行筛选
步骤四 计算t值/z值
表示两个样本之间均值的大小
t
=
x
1
−
x
2
s
1
2
n
1
+
s
2
2
n
2
t={ {x~1~ - x~2~ } \over \sqrt{ {s~1~ ^2\over n ~1~ }+{s~2~ ^2\over n ~2~ } }}
t=n 1 s 1 2+n 2 s 2 2x 1 −x 2
x1和x2 是两个样本的均值
s12和 s22 是两个样本的方差
n1和n2 是两个样本的大小
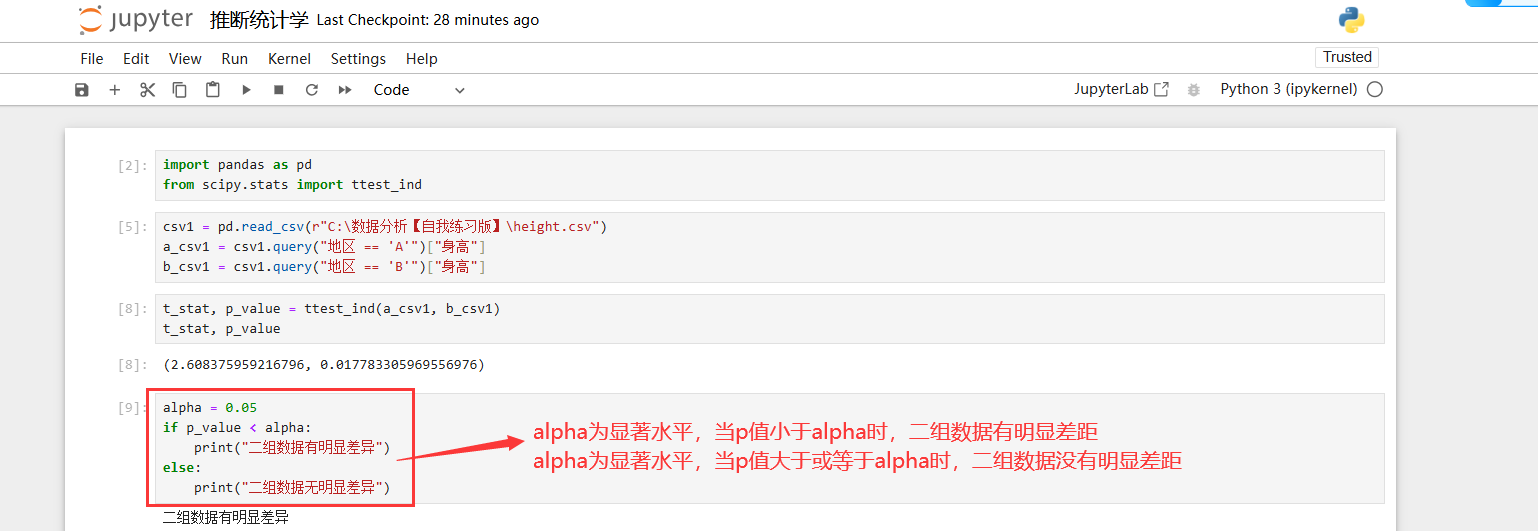
先安装scipy库(该库基于numpy)
- pip install scipy

导入
from scipy.stats import ttest_ind
-
专门用来做独立双样本t检验函数
- ttest_ind(样本对象1,样本对象2)

ttest_ind会返回t值和p值(默认p值为双尾,若是单尾检验,要在其返回值上除以二才是双尾的值)
样本对象p表示:
- 在总体之间 不存在显著差异,那样本之间存在当前这种显著或更极端的差异有多大概率
- p值小 假设总体没有差异的话,样本有当前的差异是小概率,即为拒绝原假设
- p值大 假设总体有没有差异的话,样本有当前的差异是大概率,即为接受原假设
z
=
x
1
−
x
2
σ
1
2
n
1
+
σ
2
2
n
2
z={ {x~1~ - x~2~ } \over \sqrt{ {\sigma~1~ ^2\over n ~1~ }+{\sigma~2~ ^2\over n ~2~ } }}
z=n 1 σ 1 2+n 2 σ 2 2x 1 −x 2
x1和x2 是两个样本的均值
σ
\sigma
σ1 2 和
σ
\sigma
σ2 2 是两个总体的 已知方差
n1和n2 是两个样本的大小
先安装 pip install statsmodels
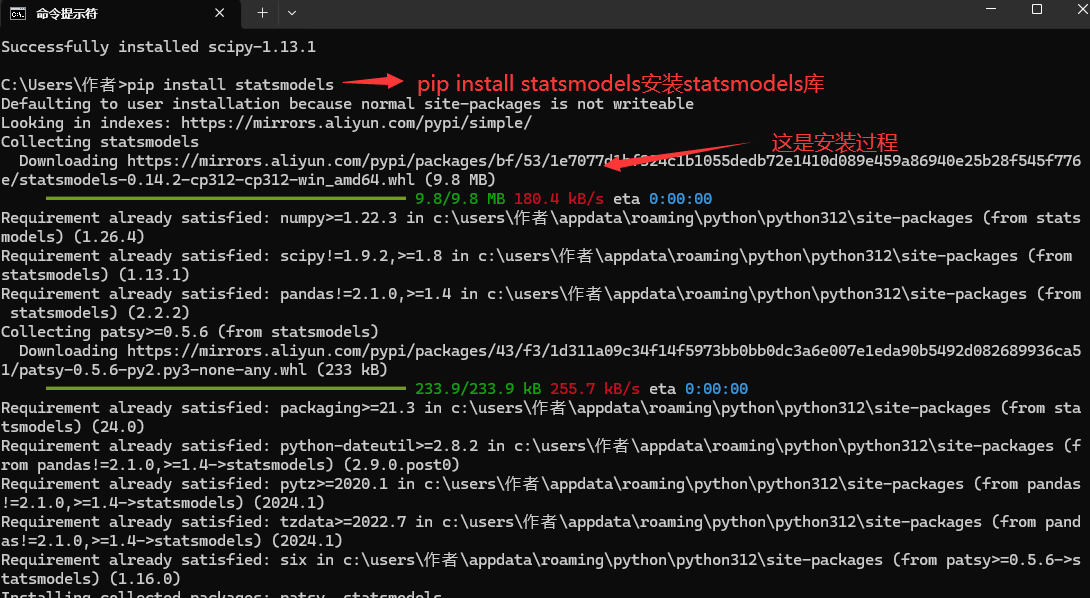
导入
statsmodels.stats.weightstats import ztest
- ztest(样本对象t,样本对象p,alternative=" ")
- alternative 该参数为可选择的
- =two-sided 表示两尾的
- =larger 表示单尾的
- =smaller 表示想推断第一个总体均值是否显著小于第二个总体均值
- alternative 该参数为可选择的
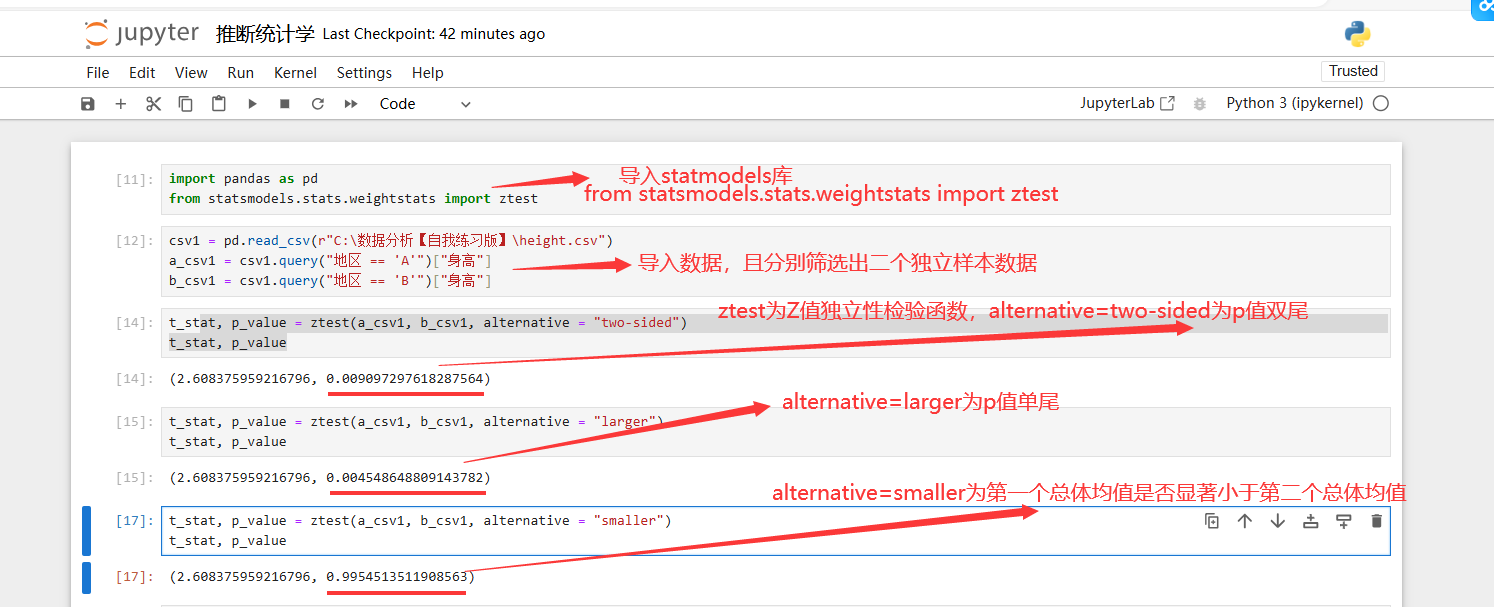
实际上:只需看p值和显著水平就可以查看接受或拒绝原假设了
步骤五 计算自由度( z检验不需要)
- 自由度=样本1+样本2 - 2
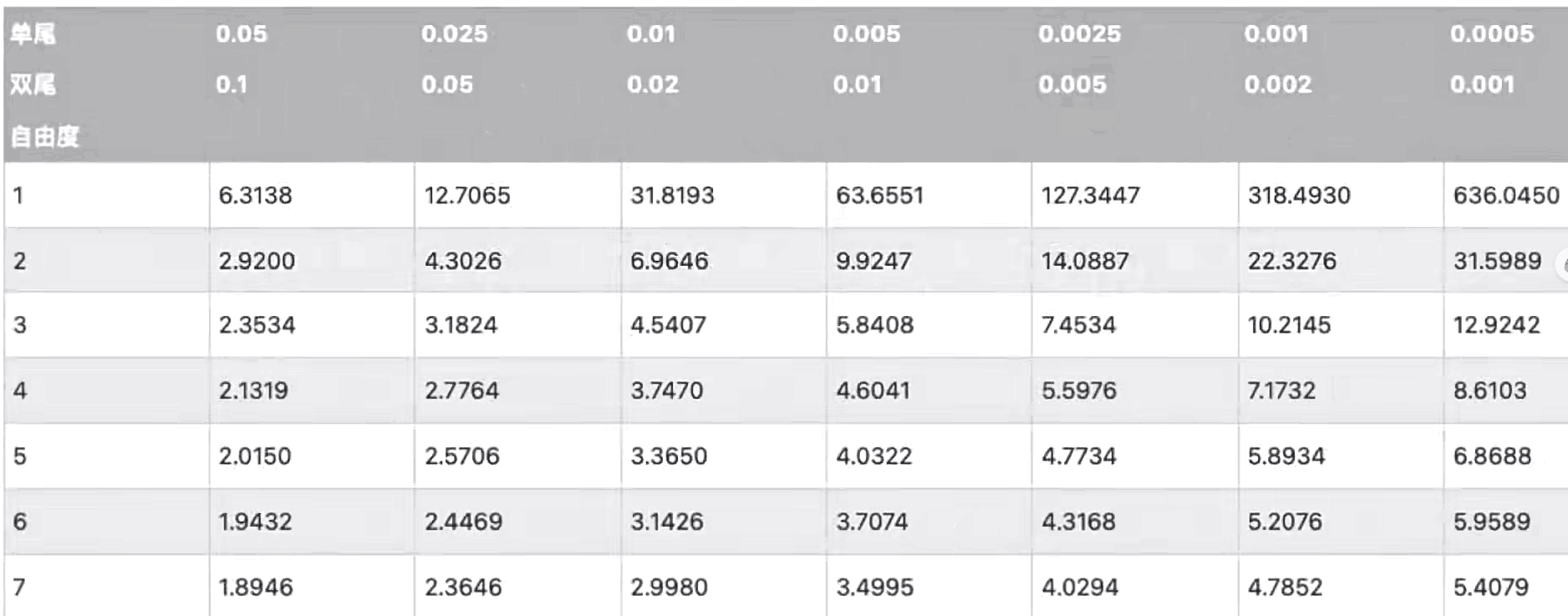
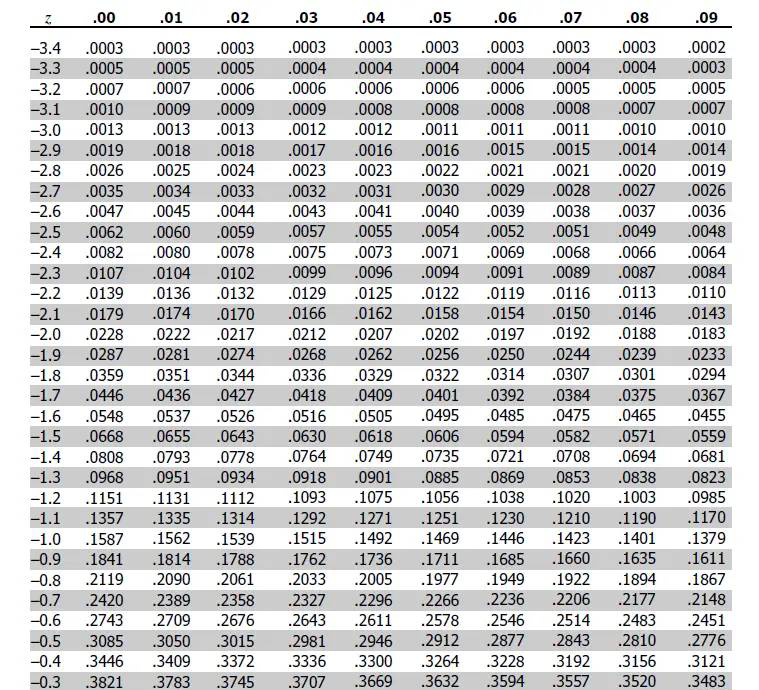
步骤六 查看t值/z值临界值表
t值临界值表
z值临界值表
步骤七 比较临界值和t值
- t值≥临界值 表示拒绝原假设
- t值<临界值 表示接受原假设
项目实战
项目实战-推断性统计和清洗评估鸢尾花数据,已上传到github
本人csdn博客主页资源上也有该项目实战
项目简介:
数据推断性统计和清洗和评估-项目实战4-分析鸢尾花数据-ipynb格式-python语法-用jupyter notebook打开
用来练习数据描述性统计和清洗和评估,整个流程特别清晰
每个步骤均用makedown编辑器进行编辑文字,每一步都给出了清晰的代码以及压缩包中给出了相应的数据集
可以按照步骤一步一步进行模仿,理解其中的思维逻辑,然后上手进行操作,在操作的过程中不断思考
等能力有了很大提升之后,就可以慢慢独立思考从事项目了
好的,到此为止啦,祝您变得更强
想说的话
实不相瞒,写的每篇博客都要写六个小时以上(加上自己学习和纸质笔记,共八九小时吧),很累,希望大佬支持
| 道阻且长 行则将至 |
|---|
个人主页:在线oj的阿川大佬的支持和鼓励,将是我成长路上最大的动力  |


发表评论