一、引言
百度是我们常用的搜索工具,其翻译是与爱词霸合作,总体看其反应速度较快,可以作为项目中重要的翻译工具。根据大家的需要,现提供两种python获取百度翻译的两种办法:
二、requests法
我们引用requests模块,向百度发出post请求,得到回复后,进行解释为json格式数据。代码如下:
import requests #找一个趁手的工具,1. 导入这个工具
url = "https://fanyi.baidu.com/sug" # 2. 确定爬取的网址,存到变量里面url
#3. 伪装爬虫
headers = {"user-agent":"mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/110.0.0.0 safari/537.36",
"cookie":'pstm=1715648276; bidupsid=4faeceb2016218e5337788d59d97e028; baiduid=a4621d4af575eb35000b164a4d71a6c9:fg=1; bdsfrcvid=gddojexrog3m1qjttzbibsp-4cgqd7ctdyleowxpsp3lgjlvyvgdeg0ptexpgltmnhulogkkbeothg4f_2uxojjg8utvjec6eg0ptf8g0m5; h_bdclckid_sf=jn-o_c82jkl3hjommjje5bchmhok--q0kkjylr-8kb7vbpqcyunkbfjbdlod-l3-ajnj0qbokfo2kdbtyt5ol447yajdjjouxkji_jc-qbt8ob53dj7pqt8r2xdok5oibmdqslnnab3voponxpo1bt0zbn5thurb2dko-4bcwj5tml5jdh3mb6ksdhatqj0ofnie_i0kfbjjfbtcmjobq4k0-qj-a4jqa5tbsjooacv5opooy4otj6d0kqonk46jbicbsror-tcmepk4mu5o3mvbkhkjwlrqwbclof3v2fnq_ij9qft20bieemtjbbqujtj7kr7jwhvieq72y-tmqlrx5q79attmfntj-qch0kqpsijm5-dwbt8bjhcjt6k8jbujokvk-no5krqphrrhq4tehh4o5xj9wdtoqj7tthcavqcm5h6d0-d9k2fj5mbi5nv2-pbwbp5cfb5k0jjhyuizynjklfbb3mkjbpbnyujn8-beh47lx-4syprgkxrnwikjkfa-b4ncjrctehom3xi8lnj405otbifo0kjzjcfmmdlwjtk2dtpbkmbeet5kaj5tsjooackwhqooy4owk441dpfdqxtjbnqabnor-tcmhp3hb5jj3m04x-on-pqplrvkahciwmqzsl3gqft20b0kwb3xwn3uadbp2n7jwhvieq72y-tmqlrx5q79attmfntj-qch0kqpsijm5-dwbt8ijhcjt6k8jbujokvt-5rdhjtg5dtjhprmbporwmt-mtrykkoztxjkf-bl-xrd0nodjmbxq40fkanrhlrnb-3iv-oxduvnyxazwjjxkuqxtnrjkxnx3hrm8jrd3fvobupulxo9luvmjgcdot5ybbc8eina5hjkbfjbqttjqn3hfikj2cklk-oj-d8lj5am3j; bd_upn=12314753; h_wise_sids=60360_60600_60728_60749; delper=0; bd_ck_sam=1; baiduid_bfess=a4621d4af575eb35000b164a4d71a6c9:fg=1; bdsfrcvid_bfess=gddojexrog3m1qjttzbibsp-4cgqd7ctdyleowxpsp3lgjlvyvgdeg0ptexpgltmnhulogkkbeothg4f_2uxojjg8utvjec6eg0ptf8g0m5; h_bdclckid_sf_bfess=jn-o_c82jkl3hjommjje5bchmhok--q0kkjylr-8kb7vbpqcyunkbfjbdlod-l3-ajnj0qbokfo2kdbtyt5ol447yajdjjouxkji_jc-qbt8ob53dj7pqt8r2xdok5oibmdqslnnab3voponxpo1bt0zbn5thurb2dko-4bcwj5tml5jdh3mb6ksdhatqj0ofnie_i0kfbjjfbtcmjobq4k0-qj-a4jqa5tbsjooacv5opooy4otj6d0kqonk46jbicbsror-tcmepk4mu5o3mvbkhkjwlrqwbclof3v2fnq_ij9qft20bieemtjbbqujtj7kr7jwhvieq72y-tmqlrx5q79attmfntj-qch0kqpsijm5-dwbt8bjhcjt6k8jbujokvk-no5krqphrrhq4tehh4o5xj9wdtoqj7tthcavqcm5h6d0-d9k2fj5mbi5nv2-pbwbp5cfb5k0jjhyuizynjklfbb3mkjbpbnyujn8-beh47lx-4syprgkxrnwikjkfa-b4ncjrctehom3xi8lnj405otbifo0kjzjcfmmdlwjtk2dtpbkmbeet5kaj5tsjooackwhqooy4owk441dpfdqxtjbnqabnor-tcmhp3hb5jj3m04x-on-pqplrvkahciwmqzsl3gqft20b0kwb3xwn3uadbp2n7jwhvieq72y-tmqlrx5q79attmfntj-qch0kqpsijm5-dwbt8ijhcjt6k8jbujokvt-5rdhjtg5dtjhprmbporwmt-mtrykkoztxjkf-bl-xrd0nodjmbxq40fkanrhlrnb-3iv-oxduvnyxazwjjxkuqxtnrjkxnx3hrm8jrd3fvobupulxo9luvmjgcdot5ybbc8eina5hjkbfjbqttjqn3hfikj2cklk-oj-d8lj5am3j; channel=baidusearch; baikevisitid=356e66e5-f4fb-4dd9-99a8-06bbc9ceb739; __bid_n=18ea75651ea4944bc97197; bd_home=1; h_wise_sids_bfess=60360_60600_60728_60749; b64_bot=1; cookie_session=5687_0_7_7_7_16_0_0_4_6_0_0_715485_0_6_0_1727255911_0_1727255905|9#169_6_1718709886|3; psino=7; bdrcvfr[s4-dauiwmmn]=mk3slvn4hkm; bdrcvfr[k-3xbxswsjs]=mk3slvn4hkm; h_ps_pssid=60600_60794_60826_60844; ba_hector=85808lal0h0g0k8g8h258h8h8nq73q1jfd5bi1v; zfy=ccxtjmci9ht2ml4gezdftbe9uar1jmpufqgd:bgwoiis:c'}
while true:
word = input("请输入单词:")
resp = requests.post(url,headers = headers, data = {"kw":word}) # 发请求
for item in resp.json()['data']:
#想看效果,就打印item
print(item["v"])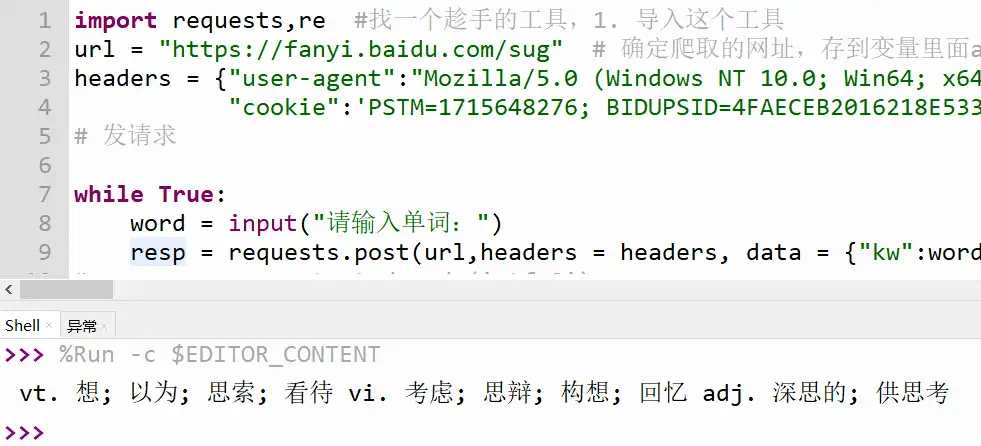
三、urllib法
导入urllib,发出request向url请求,再用urlopen读取并编码为utf-8,最后获取单词的翻译,代码如下:
from urllib import request, parse
import json
def translate_word(string):
url = "https://fanyi.baidu.com/sug" # 请求数据的url链接
data = {'kw': string}
data_url = parse.urlencode(data)
req = request.request(url=url, data=data_url.encode('utf-8'))
response = request.urlopen(req).read()
res = json.loads(response)
if 'data' in res and len(res['data']) > 0:
trans_list = res['data'][0]['v']
if ';' in trans_list:
trans = trans_list.split(';')
else:
trans = trans_list
else:
trans = "翻译失败"
return trans_list
print(translate_word("think"))四、学后反思
对比两种两法,获取的数据内容不尽相同,第二种获取的内容较少,第一种获取的内容更为全面,方法也简单,但是获取的内容有重复。
大家可以根据个人的需求,选择适合自己的代码。
到此这篇关于python获取百度翻译的两种方法的文章就介绍到这了,更多相关python获取百度翻译内容请搜索代码网以前的文章或继续浏览下面的相关文章希望大家以后多多支持代码网!





发表评论