elk是什么(what)?
elk组件介绍
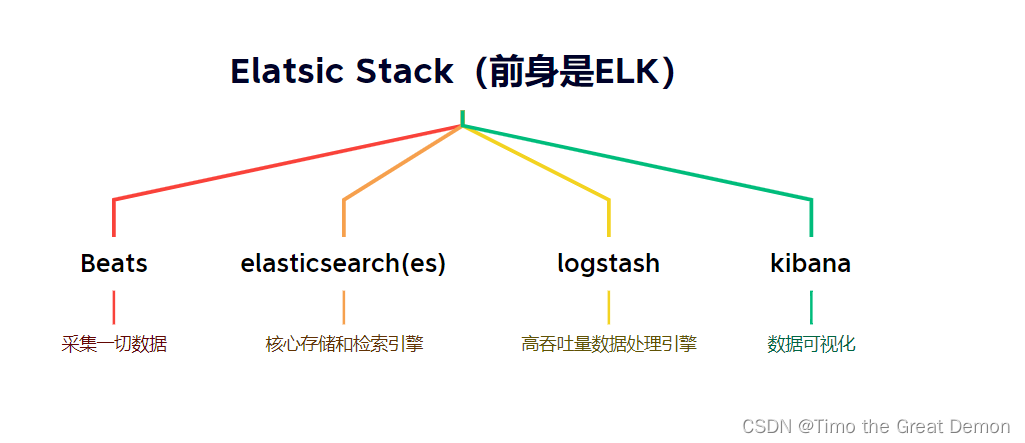
elk 是elasticsearch开源生态中提供的一套完整日志收集、分析以及展示的解决方案,是三个产品的首字母缩写,分别是elasticsearch、logstash 和 kibana。除此之外,filebeat也是目前使用较多的日志收集软件,相对于logstash更加轻量级占用资源更少。
elasticsearch ,它是一个近实时(nrt)的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析。它是一个建立在全文搜索引擎 apache lucene 基础上的搜索引擎,使用 java 语言编写。
logstash ,它是一个具有近实时(nrt)传输能力的数据收集、过滤、分析引擎,用来进行数据收集、解析、过滤,并最终将数据发送给es。
kibana ,它是一个为 elasticsearch 提供分析和展示的可视化 web 平台。它可以在 elasticsearch 的索引中查找,交互数据,并生成各种维度表格、图形以及仪表盘。
为什么学习elk?
虚拟机还要一个个去看日志,而elk可以直接看多个虚拟机的日志
学习elk(elasticsearch, logstash, kibana)的原因还有几个重要的方面:
-
日志管理和分析:elk被广泛用于日志管理和分析领域。它能够收集、存储和分析大量的日志数据,帮助用户理解系统和应用程序的运行情况。
-
实时数据处理:elk能够处理实时数据,支持快速搜索、分析和可视化,帮助用户及时发现和解决问题。
-
可扩展性和灵活性:elasticsearch作为核心组件,具有强大的横向扩展能力和灵活的搜索和分析功能,适用于多种数据处理需求。
-
开源和活跃的社区支持:elk是开源的,有庞大而活跃的社区支持,用户可以从社区中获得各种问题的解答、新功能的探索和技术支持。
-
适用于多种场景:不论是运维监控、安全分析、业务分析还是用户行为分析,elk都可以根据需要进行配置和定制,满足不同场景下的数据处理需求。
总之,学习elk可以帮助你掌握先进的日志管理和实时数据分析技术,提高系统监控和故障排查的效率,以及在业务分析和决策支持方面发挥重要作用。
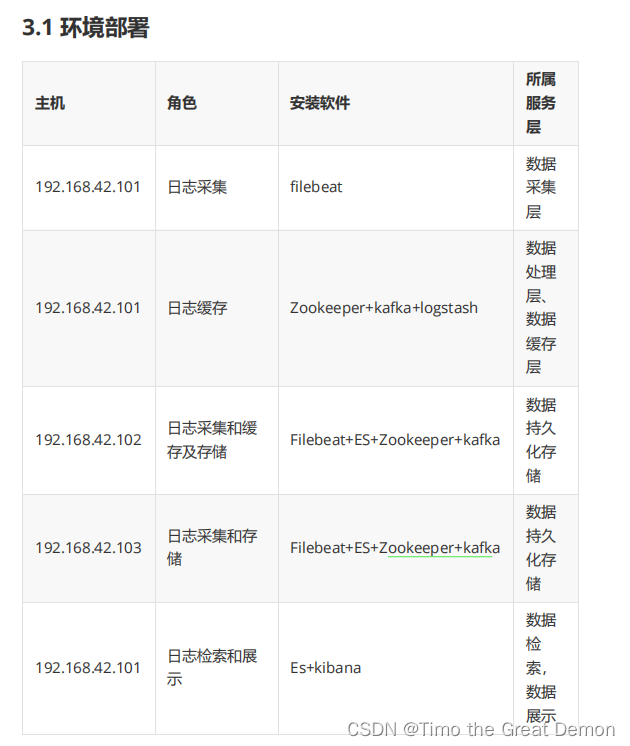
构架
kafka介绍
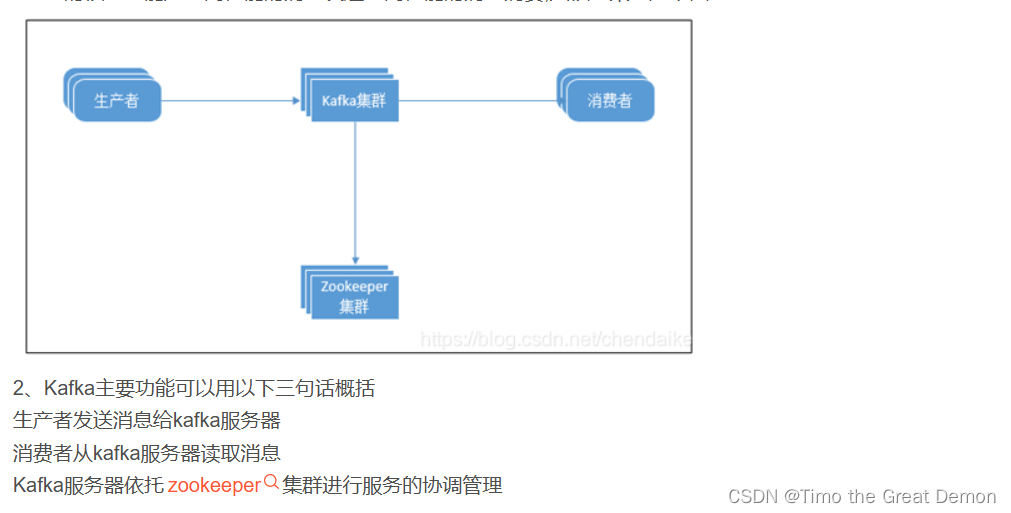
kafka简介
kafka是linkedin于2010年12月份创建的开源消息系统,它主要用于处理活跃的流式数据。活跃的流式数据在web网站应用中非常常见,这些活动数据包括页面访问量(page view)、被查看内容方面的信息以及搜索情况等内容。 这些数据通常以日志的形式记录下来,然后每隔一段时间进行一次统计分析。
传统的日志分析系统是一种离线处理日志信息的方式,但若要进行实时处理,通常会有较大延迟。而现有的消息队列系统能够很好的处理实时或者近似实时的应用,但未处理的数据通常不会写到磁盘上,这对于hadoop之类,间隔时间较长的离线应用而言,在数据安全上会出现问题。kafka正是为了解决以上问题而设计的,它能够很好地进行离线和在线应用。


优点


为什么你要使用这么强大的分布式消息中间件——kafka
1、实时性
2、有些数据,存储数据库浪费,直接存储硬盘效率又低
3、高性能的消息发送与高性能的消息消费

zookeeper介绍

优点


kafka集群搭建
ip server broker.id
192.168.199.132 kafka+zookeeper 1
192.168.199.133 kafka+zookeeper 2
192.168.199.135 kafka+zookeeper 3

132配置如下
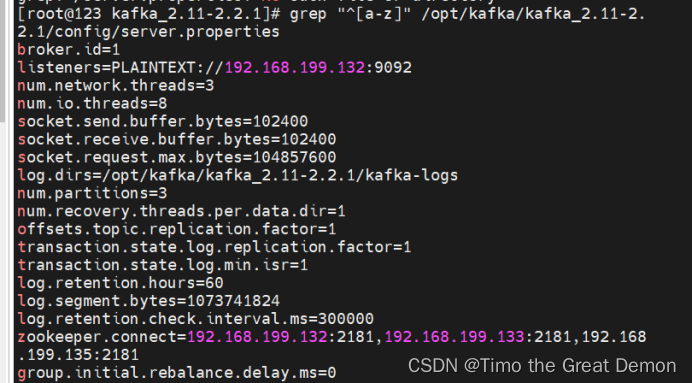
133配置 第一行broker.id=2 第二行改成自己ip
135配置 第一行broker.id=3 第二行改成自己ip
启动服务

查看日志

验证操作

如下图

在zookeeper中查看

132运行生产者,输入消息到服务器

133运行消费者,消费消息

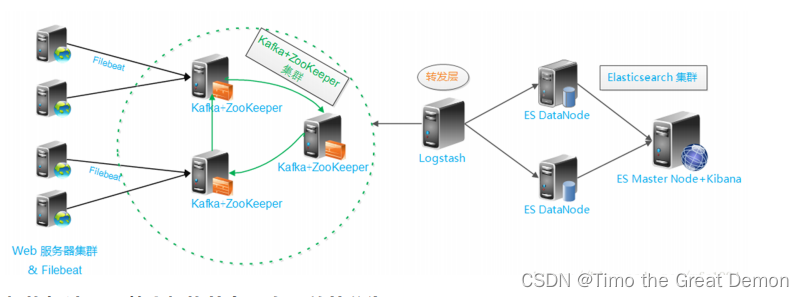
elk+filebeat+kafka+zookeeper构建海量日志分析平台
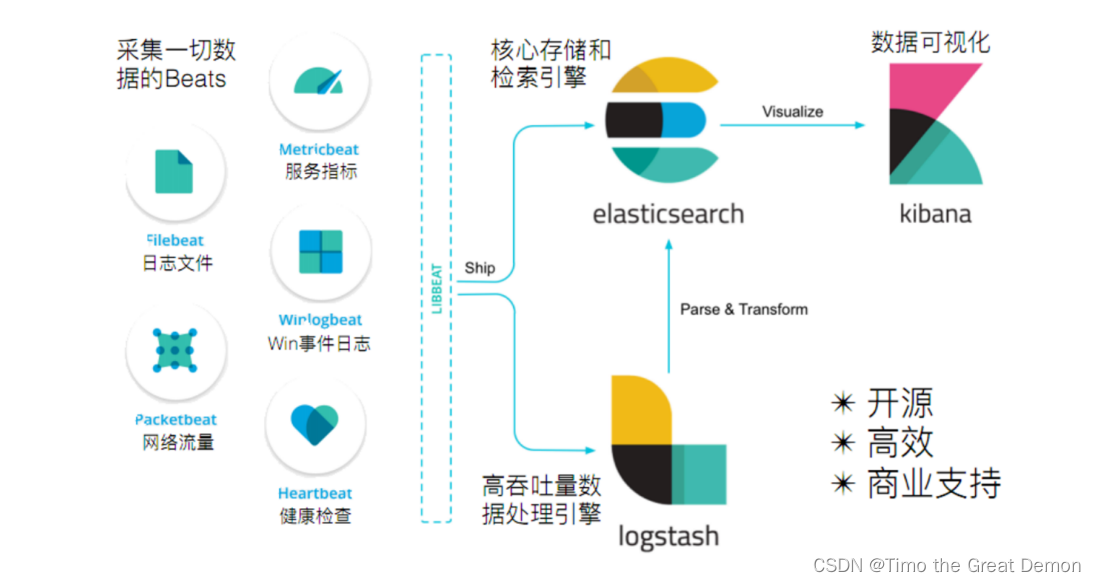
在实际应用场景中,为了满足大数据实时检索的需求,您可以使用filebeat采集日志数据,并输出到kafka中。kafka实时接收filebeat采集的数据,并输出到logstash中。输出到logstash中的数据在格式或内容上可能不能满足您的需求,此时可以通过logstash的filter插件过滤数据。最后将满足需求的数据输出到elasticsearch中进行分布式检索,并通过kibana进行数据分析与展示。简单流程如下。


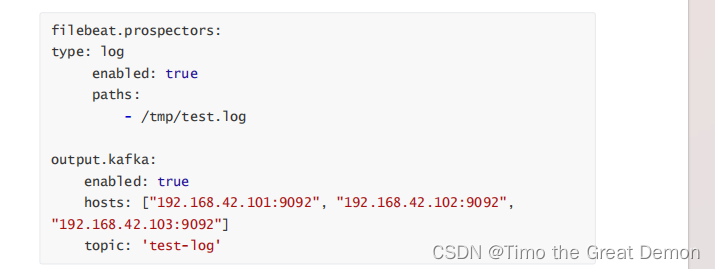
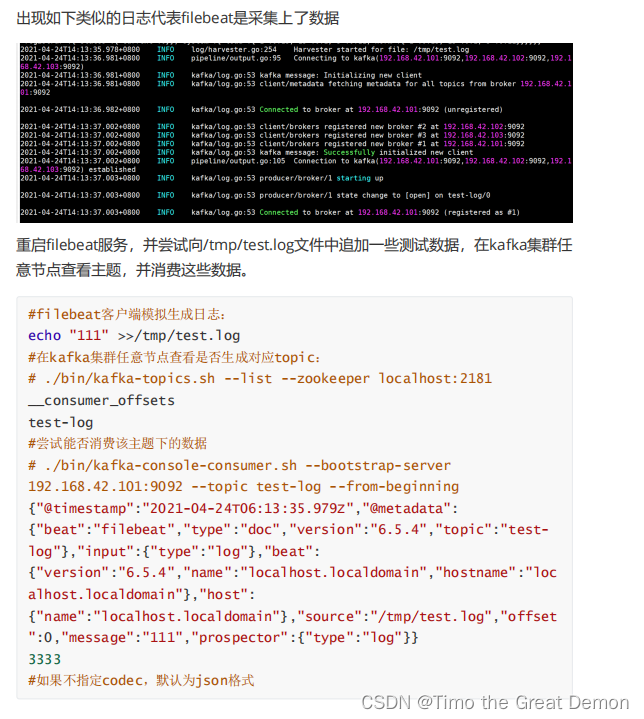
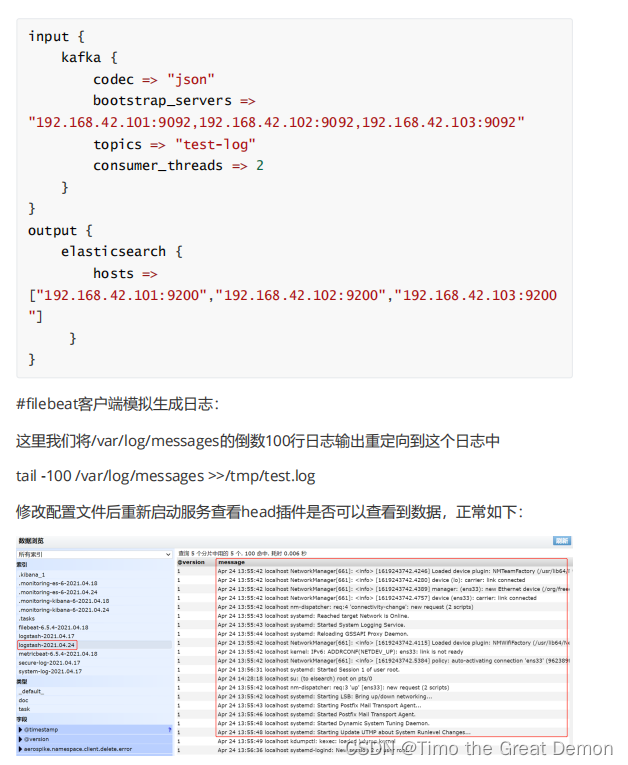
1、配置filebeat输出到kafka集群
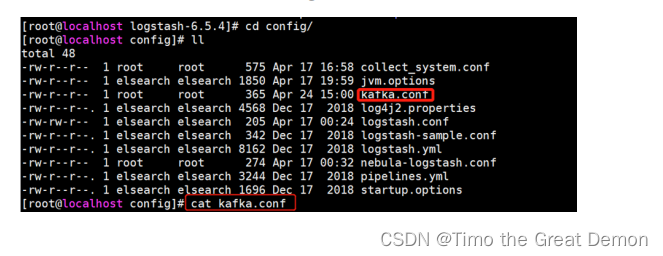
2、logstsh从kafka读取数据,并输出到es

![]()
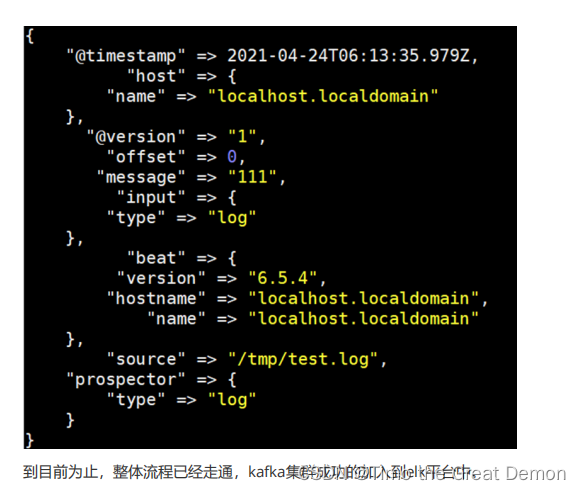
3、将filebeat采集的日志通过logstash输出到es和kibana
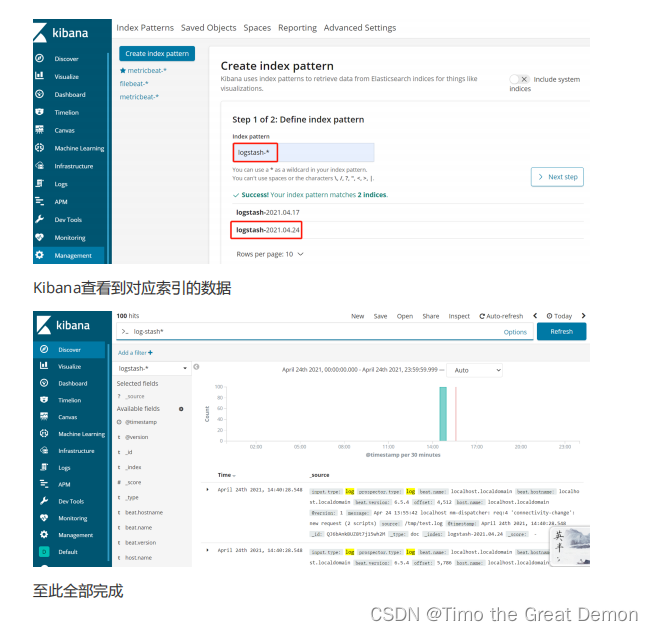
4、kibana操作

![[ 云计算 | AWS 实践 ] Java 如何重命名 Amazon S3 中的文件和文件夹](https://images.3wcode.com/3wcode/20240802/s_0_202408020028483641.png)
发表评论