springcloud gateway 防止xss漏洞
一.xss(跨站脚本)漏洞详解
1.xss的原理和分类
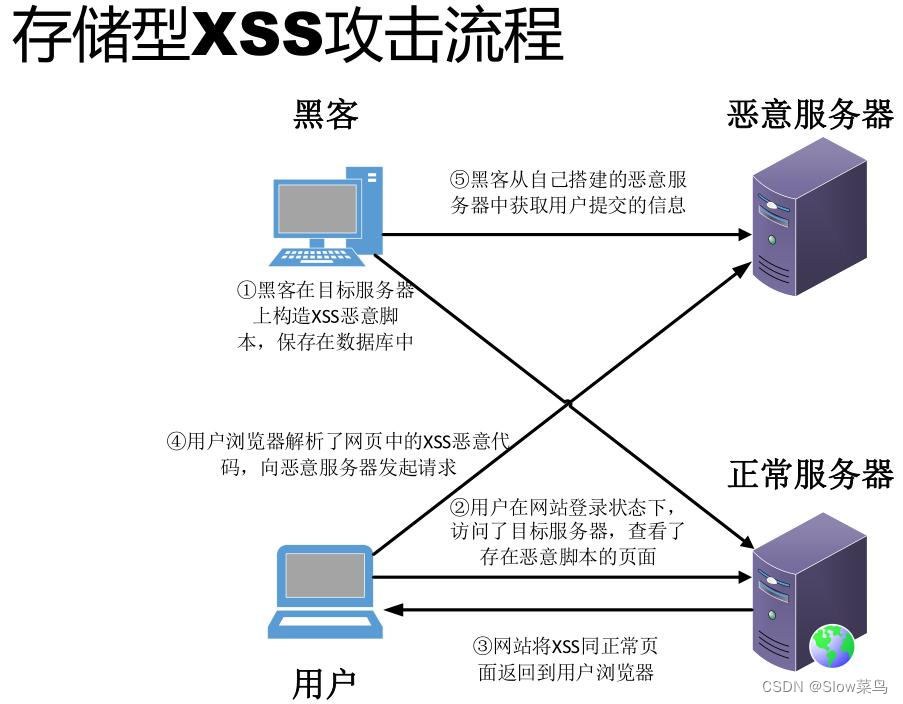
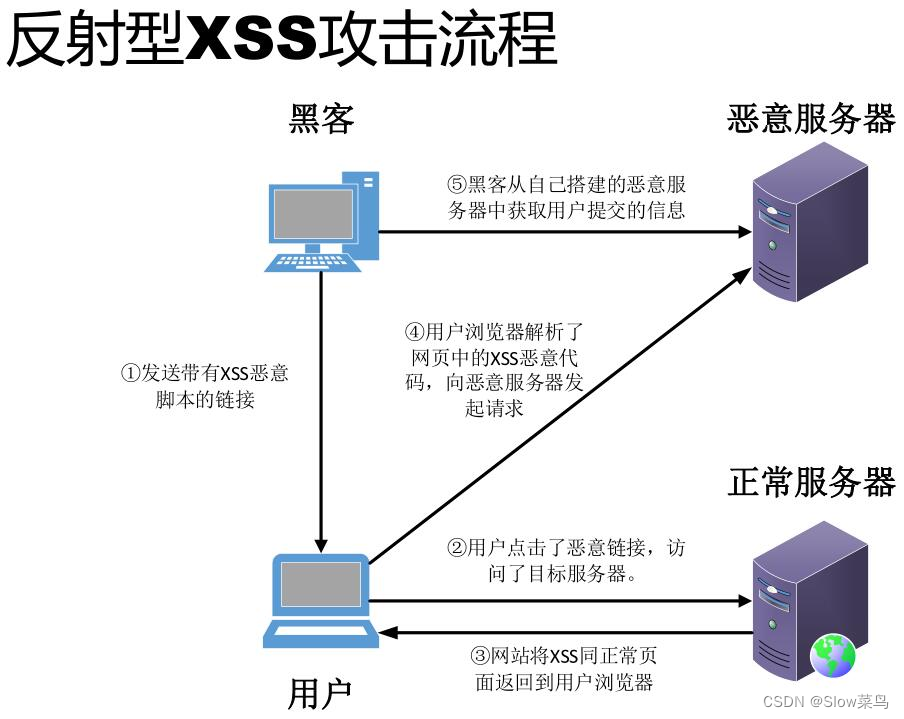
xss分为:存储型 、反射型 、dom型xss
-
存储型xss:存储型xss,持久化,代码是存储在服务器中的,如在个人信息或发表文章等地方,插入代码,如果没有过滤或过滤不严,那么这些代码将储存到服务器中,用户访问该页面的时候触发代码执行。这种xss比较危险,容易造成蠕虫,盗窃cookie
-
反射型xss:非持久化,需要欺骗用户自己去点击链接才能触发xss代码(服务器中没有这样的页面和内容),一般容易出现在搜索页面
-
dom型xss:不经过后端,dom-xss漏洞是基于文档对象模型(document objeet model,dom)的一种漏洞,dom-xss是通过url传入参数去控制触发的,其实也属于反射型xss。
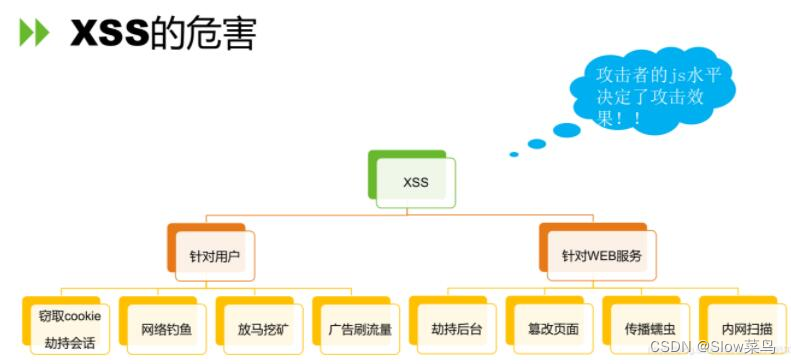
2.xss漏洞的危害
从以上我们可以知道,存储型的xss危害最大。因为他存储在服务器端,所以不需要我们和被攻击者有任何接触,只要被攻击者访问了该页面就会遭受攻击。而反射型和dom型的xss则需要我们去诱使用户点击我们构造的恶意的url,需要我们和用户有直接或者间接的接触,比如利用社会工程学或者利用在其他网页挂马的方式。
3.xss的防御
xss防御的总体思路是:对用户的输入(和url参数)进行过滤,对输出进行html编码。也就是对用户提交的所有内容进行过滤,对url中的参数进行过滤,过滤掉会导致脚本执行的相关内容;然后对动态输出到页面的内容进行html编码,使脚本无法在浏览器中执行。
对输入的内容进行过滤,可以分为黑名单过滤和白名单过滤。黑名单过滤虽然可以拦截大部分的xss攻击,但是还是存在被绕过的风险。白名单过滤虽然可以基本杜绝xss攻击,但是真实环境中一般是不能进行如此严格的白名单过滤的。
对输出进行html编码,就是通过函数,将用户的输入的数据进行html编码,使其不能作为脚本运行。
如下,是使用php中的htmlspecialchars函数对用户输入的name参数进行html编码,将其转换为html实体
#使用htmlspecialchars函数对用户输入的name参数进行html编码,将其转换为html实体
$name = htmlspecialchars( $_get[ 'name' ] );
二.java开发中防范xss跨站脚本攻击的思路
-
- 防堵跨站漏洞
阻止攻击者利用在被攻击网站上发布跨站攻击语句不可以信任用户提交的任何内容,首先代码里对用户输入的地方和变量都需要仔细检查长度和对”<”,”>”,”;”,”’”等字符做过滤;其次任何内容写到页面之前都必须加以encode,避免不小心把html tag 弄出来。这一个层面做好,至少可以堵住超过一半的xss 攻击。
- 防堵跨站漏洞
-
- cookie 防盗
首先避免直接在cookie 中泄露用户隐私,例如email、密码等等。其次通过使cookie 和系统ip 绑定来降低cookie 泄露后的危险。这样攻击者得到的cookie 没有实际价值,不可能拿来重放。
- cookie 防盗
-
- 尽量采用post 而非get 提交表单
post 操作不可能绕开javascript 的使用,这会给攻击者增加难度,减少可利用的跨站漏洞。
- 尽量采用post 而非get 提交表单
-
- 严格检查refer
检查http refer 是否来自预料中的url。这可以阻止第2 类攻击手法发起的http 请求,也能防止大部分第1 类攻击手法,除非正好在特权操作的引用页上种了跨站访问。
- 严格检查refer
-
- 将单步流程改为多步,在多步流程中引入效验码
多步流程中每一步都产生一个验证码作为hidden 表单元素嵌在中间页面,下一步操作时这个验证码被提交到服务器,服务器检查这个验证码是否匹配。
首先这为第1 类攻击者大大增加了麻烦。其次攻击者必须在多步流程中拿到上一步产生的效验码才有可能发起下一步请求,这在第2 类攻击中是几乎无法做到的。
- 将单步流程改为多步,在多步流程中引入效验码
-
- 引入用户交互
简单的一个看图识数可以堵住几乎所有的非预期特权操作。
- 引入用户交互
-
- 只在允许anonymous 访问的地方使用动态的javascript。
-
- 对于用户提交信息的中的img 等link,检查是否有重定向回本站、不是真的图片等可疑操作。
-
- 内部管理网站的问题
很多时候,内部管理网站往往疏于关注安全问题,只是简单的限制访问来源。这种网站往往对xss 攻击毫无抵抗力,需要多加注意。安全问题需要长期的关注,从来不是一锤子买卖。xss 攻击相对其他攻击手段更加隐蔽和多变,和业务流程、代码实现都有关系,不存在什么一劳永逸的解决方案。此外,面对xss,往往要牺牲产品的便利性才能保证完全的安全,如何在安全和便利之间平衡也是一件需要考虑的事情。
web应用开发者注意事项:
- 1.对于开发者,首先应该把精力放到对所有用户提交内容进行可靠的输入验证上。这些提交内容包括url、查询关键字、http头、post数据等。只接受在你所规定长度范围内、采用适当格式、你所希望的字符。阻塞、过滤或者忽略其它的任何东西。
- 2.保护所有敏感的功能,以防被bots自动化或者被第三方网站所执行。实现session标记(session tokens)、captcha系统或者http引用头检查。
- 3.如果你的web应用必须支持用户提供的html,那么应用的安全性将受到灾难性的下滑。但是你还是可以做一些事来保护web站点:确认你接收的html内容被妥善地格式化,仅包含最小化的、安全的tag(绝对没有javascript),去掉任何对远程内容的引用(尤其是样式表和javascript)。为了更多的安全,请使用httponly的cookie。
三.相关代码(适用于spring cloud gateway)
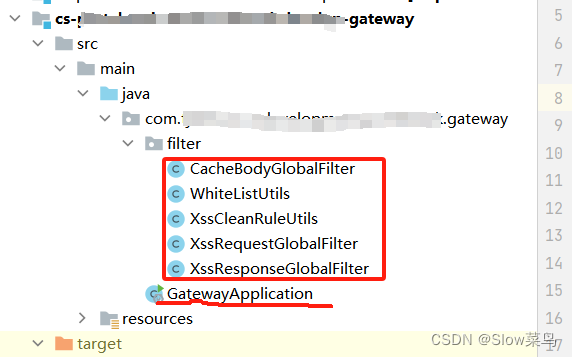
代码执行顺序
cachebodyglobalfilter—>xssrequestglobalfilter—>xssresponseglobalfilter
1.cachebodyglobalfilter.java
这个过滤器解决body不能重复读的问题(在低版本的spring-cloud不需要这个过滤器),为后续的xssrequestglobalfilter重写请求body做准备
package com.xxx.gateway.filter;
import org.springframework.cloud.gateway.filter.gatewayfilterchain;
import org.springframework.cloud.gateway.filter.globalfilter;
import org.springframework.core.ordered;
import org.springframework.core.io.buffer.databuffer;
import org.springframework.core.io.buffer.databufferutils;
import org.springframework.http.httpheaders;
import org.springframework.http.httpmethod;
import org.springframework.http.mediatype;
import org.springframework.http.server.reactive.serverhttprequest;
import org.springframework.http.server.reactive.serverhttprequestdecorator;
import org.springframework.stereotype.component;
import org.springframework.web.server.serverwebexchange;
import reactor.core.publisher.flux;
import reactor.core.publisher.mono;
/**
* @author:
* @description: 这个过滤器解决body不能重复读的问题,为后续的xssrequestglobalfilter重写post|put请求的body做准备
* @date:
* <p>
* 没把body的内容放到attribute中去,因为从attribute取出body内容还是需要强转成 flux<databuffer>,然后转换成string,和直接读取body没有什么区别
*/
@component
public class cachebodyglobalfilter implements ordered, globalfilter {
@override
public mono<void> filter(serverwebexchange exchange, gatewayfilterchain chain) {
httpmethod method = exchange.getrequest().getmethod();
string contenttype = exchange.getrequest().getheaders().getfirst(httpheaders.content_type);
if (method == httpmethod.post || method == httpmethod.put) {
if (mediatype.application_form_urlencoded_value.equalsignorecase(contenttype)
|| mediatype.application_json_value.equalsignorecase(contenttype)
|| mediatype.application_json_utf8_value.equals(contenttype)) {
return databufferutils.join(exchange.getrequest().getbody())
.flatmap(databuffer -> {
databufferutils.retain(databuffer);
flux<databuffer> cachedflux = flux
.defer(() -> flux.just(databuffer.slice(0, databuffer.readablebytecount())));
serverhttprequest mutatedrequest = new serverhttprequestdecorator(
exchange.getrequest()) {
@override
public flux<databuffer> getbody() {
return cachedflux;
}
};
return chain.filter(exchange.mutate().request(mutatedrequest).build());
});
}
}
return chain.filter(exchange);
}
@override
public int getorder() {
return ordered.highest_precedence;
}
}
2.xssrequestglobalfilter.java
自定义防xss攻击网关全局过滤器。
package com.xxx.gateway.filter;
import io.netty.buffer.bytebufallocator;
import org.apache.commons.lang.stringutils;
import org.slf4j.logger;
import org.slf4j.loggerfactory;
import org.springframework.cloud.gateway.filter.gatewayfilterchain;
import org.springframework.cloud.gateway.filter.globalfilter;
import org.springframework.core.ordered;
import org.springframework.core.io.buffer.databuffer;
import org.springframework.core.io.buffer.databufferutils;
import org.springframework.core.io.buffer.nettydatabufferfactory;
import org.springframework.http.httpheaders;
import org.springframework.http.httpmethod;
import org.springframework.http.httpstatus;
import org.springframework.http.mediatype;
import org.springframework.http.server.reactive.serverhttprequest;
import org.springframework.http.server.reactive.serverhttprequestdecorator;
import org.springframework.http.server.reactive.serverhttpresponse;
import org.springframework.stereotype.component;
import org.springframework.web.server.serverwebexchange;
import org.springframework.web.util.uricomponentsbuilder;
import reactor.core.publisher.flux;
import reactor.core.publisher.mono;
import java.net.uri;
import java.nio.charbuffer;
import java.nio.charset.standardcharsets;
import java.util.concurrent.atomic.atomicreference;
/**
* @author:
* @description: 自定义防xss攻击网关全局过滤器
* @date:
*/
@component
public class xssrequestglobalfilter implements globalfilter, ordered {
private logger logger = loggerfactory.getlogger(xssrequestglobalfilter.class);
/**
*
* @param exchange
* @param chain
* @return
*
* get请求参考spring cloud gateway自带过滤器:
* @see org.springframework.cloud.gateway.filter.factory.addrequestparametergatewayfilterfactory
*
* post请求参考spring cloud gateway自带过滤器:
* @see org.springframework.cloud.gateway.filter.factory.rewrite.modifyrequestbodygatewayfilterfactory
*/
@override
public mono<void> filter(serverwebexchange exchange, gatewayfilterchain chain){
// grab configuration from config object
logger.info("----自定义防xss攻击网关全局过滤器生效----");
string path = exchange.getrequest().getpath().tostring();
serverhttprequest serverhttprequest = exchange.getrequest();
httpmethod method = serverhttprequest.getmethod();
string contenttype = serverhttprequest.getheaders().getfirst(httpheaders.content_type);
boolean postflag = (method == httpmethod.post || method == httpmethod.put) &&
(mediatype.application_form_urlencoded_value.equalsignorecase(contenttype) || mediatype.application_json_value.equals(contenttype) || mediatype.application_json_utf8_value.equals(contenttype));
// get 请求, 参考的是 org.springframework.cloud.gateway.filter.factory.addrequestparametergatewayfilterfactory
if (method == httpmethod.get) {
uri uri = exchange.getrequest().geturi();
string rawquery = uri.getrawquery();
if (stringutils.isblank(rawquery)){
return chain.filter(exchange);
}
rawquery = xsscleanruleutils.xssclean(rawquery);
try {
uri newuri = uricomponentsbuilder.fromuri(uri)
.replacequery(rawquery)
.build(true)
.touri();
serverhttprequest request = exchange.getrequest().mutate()
.uri(newuri).build();
return chain.filter(exchange.mutate().request(request).build());
} catch (exception e) {
logger.error("get请求清理xss攻击异常", e);
throw new illegalstateexception("invalid uri query: \"" + rawquery + "\"");
}
}
//post请求时,如果是文件上传之类的请求,不修改请求消息体
else if (postflag){
// 参考的是 org.springframework.cloud.gateway.filter.factory.addrequestparametergatewayfilterfactory
//从请求里获取post请求体
string bodystr = resolvebodyfromrequest(serverhttprequest);
// 这种处理方式,必须保证post请求时,原始post表单必须有数据过来,不然会报错
if (stringutils.isblank(bodystr)) {
logger.error("请求异常:{} post请求必须传递参数", serverhttprequest.geturi().getrawpath());
serverhttpresponse response = exchange.getresponse();
response.setstatuscode(httpstatus.bad_request);
byte[] bytes = "{\"code\":400,\"msg\":\"post data error\"}".getbytes(standardcharsets.utf_8);
databuffer buffer = response.bufferfactory().wrap(bytes);
return response.writewith(mono.just(buffer));
}
//白名单处理(看业务需求)
boolean containstarget = whitelistutils.richtexturls.stream().anymatch(s -> path.contains(s));
if (containstarget) {
//bodystr = xsscleanruleutils.xssrichtextclean(bodystr);
bodystr = xsscleanruleutils.xssclean2(bodystr);
} else {
bodystr = xsscleanruleutils.xssclean(bodystr);
}
uri uri = serverhttprequest.geturi();
uri newuri = uricomponentsbuilder.fromuri(uri).build(true).touri();
serverhttprequest request = exchange.getrequest().mutate().uri(newuri).build();
databuffer bodydatabuffer = stringbuffer(bodystr);
flux<databuffer> bodyflux = flux.just(bodydatabuffer);
// 定义新的消息头
httpheaders headers = new httpheaders();
headers.putall(exchange.getrequest().getheaders());
// 由于修改了传递参数,需要重新设置content_length,长度是字节长度,不是字符串长度
int length = bodystr.getbytes().length;
headers.remove(httpheaders.content_length);
headers.setcontentlength(length);
// 设置content_type
if (stringutils.isnotblank(contenttype)) {
headers.set(httpheaders.content_type, contenttype);
}
// 由于post的body只能订阅一次,由于上面代码中已经订阅过一次body。所以要再次封装请求到request才行,不然会报错请求已经订阅过
request = new serverhttprequestdecorator(request) {
@override
public httpheaders getheaders() {
long contentlength = headers.getcontentlength();
httpheaders httpheaders = new httpheaders();
httpheaders.putall(super.getheaders());
if (contentlength > 0) {
httpheaders.setcontentlength(contentlength);
} else {
// this causes a 'http/1.1 411 length required' on httpbin.org
httpheaders.set(httpheaders.transfer_encoding, "chunked");
}
return httpheaders;
}
@override
public flux<databuffer> getbody() {
return bodyflux;
}
};
//封装request,传给下一级
request.mutate().header(httpheaders.content_length, integer.tostring(bodystr.length()));
return chain.filter(exchange.mutate().request(request).build());
} else {
return chain.filter(exchange);
}
}
@override
public int getorder() {
return -90;
}
/**
* 从flux<databuffer>中获取字符串的方法
* @return 请求体
*/
private string resolvebodyfromrequest(serverhttprequest serverhttprequest) {
//获取请求体
flux<databuffer> body = serverhttprequest.getbody();
atomicreference<string> bodyref = new atomicreference<>();
body.subscribe(buffer -> {
charbuffer charbuffer = standardcharsets.utf_8.decode(buffer.asbytebuffer());
databufferutils.release(buffer);
bodyref.set(charbuffer.tostring());
});
//获取request body
return bodyref.get();
}
/**
* 字符串转databuffer
* @param value
* @return
*/
private databuffer stringbuffer(string value) {
byte[] bytes = value.getbytes(standardcharsets.utf_8);
nettydatabufferfactory nettydatabufferfactory = new nettydatabufferfactory(bytebufallocator.default);
databuffer buffer = nettydatabufferfactory.allocatebuffer(bytes.length);
buffer.write(bytes);
return buffer;
}
}
3.xssresponseglobalfilter.java
重写response,防止xss攻击。
package com.xxx.gateway.filter;
import org.reactivestreams.publisher;
import org.slf4j.logger;
import org.slf4j.loggerfactory;
import org.springframework.cloud.gateway.filter.gatewayfilterchain;
import org.springframework.cloud.gateway.filter.globalfilter;
import org.springframework.core.ordered;
import org.springframework.core.io.buffer.databuffer;
import org.springframework.core.io.buffer.databufferfactory;
import org.springframework.core.io.buffer.databufferutils;
import org.springframework.core.io.buffer.defaultdatabufferfactory;
import org.springframework.http.httpheaders;
import org.springframework.http.mediatype;
import org.springframework.http.server.reactive.serverhttpresponse;
import org.springframework.http.server.reactive.serverhttpresponsedecorator;
import org.springframework.stereotype.component;
import org.springframework.web.server.serverwebexchange;
import reactor.core.publisher.flux;
import reactor.core.publisher.mono;
import java.nio.charset.charset;
/**
* @author:
* @description: 重写response,防止xss攻击
* @date:
*/
@component
public class xssresponseglobalfilter implements ordered, globalfilter {
private logger logger = loggerfactory.getlogger(xssresponseglobalfilter.class);
@override
public mono<void> filter(serverwebexchange exchange, gatewayfilterchain chain) {
//获取请求url
string path = exchange.getrequest().getpath().tostring();
serverhttpresponse originalresponse = exchange.getresponse();
databufferfactory bufferfactory = originalresponse.bufferfactory();
serverhttpresponsedecorator decoratedresponse = new serverhttpresponsedecorator(originalresponse) {
@override
public mono<void> writewith(publisher<? extends databuffer> body) {
string contenttype = getdelegate().getheaders().getfirst(httpheaders.content_type);
boolean flag = mediatype.application_json_value.equals(contenttype) || mediatype.application_json_utf8_value.equals(contenttype);
if (body instanceof flux && flag) {
flux<? extends databuffer> fluxbody = (flux<? extends databuffer>) body;
return super.writewith(fluxbody.buffer().map(databuffer -> {
//如果响应过大,会进行截断,出现乱码,
//然后看api defaultdatabufferfactory有个join方法可以合并所有的流,乱码的问题解决
databufferfactory databufferfactory = new defaultdatabufferfactory();
databuffer join = null;
try {
join = databufferfactory.join(databuffer);
byte[] content = new byte[join.readablebytecount()];
join.read(content);
//释放掉内存
databufferutils.release(join);
string result = new string(content, charset.forname("utf-8"));
//logger.info("result:"+result);
//若为带有富文本的接口,走富文本xss过滤
boolean containstarget = whitelistutils.richtexturls.stream().anymatch(s -> path.contains(s));
if (containstarget) {
//result = xsscleanruleutils.xssrichtextclean(result);
result = xsscleanruleutils.xssclean2(result);
} else {
//result就是response的值,对result进行去xss
result = xsscleanruleutils.xssclean(result);
}
byte[] uppedcontent = new string(result.getbytes(), charset.forname("utf-8")).getbytes();
return bufferfactory.wrap(uppedcontent);
} catch (exception e) {
// 处理异常,记录日志等
throw e;
} finally {
if (join != null) {
//释放掉内存
databufferutils.release(join);
}
}
}));
}
// if body is not a flux. never got there.
return super.writewith(body);
}
};
// replace response with decorator
return chain.filter(exchange.mutate().response(decoratedresponse).build());
}
@override
public int getorder() {
return -50;
}
}
4.xsscleanruleutils.java (工具类)
上面几个过滤器使用的工具类
后续我自己这边没有用jsoup了(感觉有坑,就放弃了)
package com.xxx.gateway.filter;
import com.alibaba.fastjson.json;
import com.alibaba.fastjson.jsonarray;
import com.alibaba.fastjson.jsonobject;
import org.jsoup.jsoup;
import org.jsoup.nodes.document;
import org.jsoup.safety.whitelist;
import org.springframework.core.io.classpathresource;
import java.io.ioexception;
import java.io.inputstream;
import java.util.iterator;
import java.util.regex.pattern;
/**
* @author:
* @description: xss过滤工具
* @date:
*/
public class xsscleanruleutils {
//xss过滤规则(对于script、src及加载事件和弹窗事件的代码块)
private final static pattern[] scriptpatterns = {
pattern.compile("<script>(.*?)</script>", pattern.case_insensitive),
pattern.compile("src[\r\n]*=[\r\n]*\\\'(.*?)\\\'", pattern.case_insensitive | pattern.multiline | pattern.dotall),
pattern.compile("</script>", pattern.case_insensitive),
pattern.compile("<script(.*?)>", pattern.case_insensitive | pattern.multiline | pattern.dotall),
pattern.compile("eval\\((.*?)\\)", pattern.case_insensitive | pattern.multiline | pattern.dotall),
pattern.compile("expression\\((.*?)\\)", pattern.case_insensitive | pattern.multiline | pattern.dotall),
pattern.compile("javascript:", pattern.case_insensitive),
pattern.compile("vbscript:", pattern.case_insensitive),
pattern.compile("onload(.*?)=", pattern.case_insensitive | pattern.multiline | pattern.dotall)
};
//非富文本的
public static string xssclean(string value) {
if (value != null) {
value = value.replaceall("\0|\n|\r", "");
for (pattern pattern : scriptpatterns) {
value = pattern.matcher(value).replaceall("");
}
value = value.replaceall("<", "<").replaceall(">", ">");
}
return value;
}
//富文本的
public static string xssclean2(string value) {
if (value != null) {
value = value.replaceall("\0|\n|\r", "");
for (pattern pattern : scriptpatterns) {
value = pattern.matcher(value).replaceall("");
}
}
return value;
}
//自定义的json白名单
private static final classpathresource jsoupwhitelistpathres = new classpathresource("/json/xsswhitelist.json");
//配置过滤化参数, 不对代码进行格式化
private static final document.outputsettings outputsettings = new document.outputsettings().prettyprint(false);
//富文本的(使用了jsoup)
public static string xssrichtextclean(string value) {
// 创建一个自定义的白名单,基于jsoup的默认白名单
whitelist customwhitelist = whitelist.basic();
inputstream whiteconfig = null;
try {
whiteconfig = jsoupwhitelistpathres.getinputstream();
} catch (ioexception e) {
e.printstacktrace();
}
if (whiteconfig == null) {
throw new runtimeexception("读取jsoup xss 白名单文件失败");
} else {
try {
jsonobject whitelistjson = json.parseobject(whiteconfig, jsonobject.class);
//添加标签 addtags
jsonarray addtagsjsonarr = whitelistjson.getjsonarray("addtags");
string[] addtagsarr = addtagsjsonarr.toarray(new string[0]);
customwhitelist.addtags(addtagsarr);
//添加属性 addattributes
jsonarray addattrjsonarr = whitelistjson.getjsonarray("addattributes");
iterator<object> iter = addattrjsonarr.iterator();
while (iter.hasnext()) {
jsonobject attrjsonobj = (jsonobject) iter.next();
string tag = attrjsonobj.getstring("tag");
jsonarray attrjsonarr = attrjsonobj.getjsonarray("attributes");
string[] attrarr = attrjsonarr.toarray(new string[0]);
customwhitelist.addattributes(tag, attrarr);
}
//添加 addprotocols
jsonarray addprotojsonarr = whitelistjson.getjsonarray("addprotocols");
iter = addprotojsonarr.iterator();
while (iter.hasnext()) {
jsonobject attrjsonobj = (jsonobject) iter.next();
string tag = attrjsonobj.getstring("tag");
string attribute = attrjsonobj.getstring("attribute");
jsonarray protojsonarr = attrjsonobj.getjsonarray("protocols");
string[] protocolarr = protojsonarr.toarray(new string[0]);
customwhitelist.addprotocols(tag, attribute, protocolarr);
}
} catch (ioexception e) {
e.printstacktrace();
}
}
value =jsoup.clean(value, "", customwhitelist, outputsettings);
return value;
}
}
5.whitelistutils(白名单)
package com.xxx.gateway.filter;
import java.util.arrays;
import java.util.list;
//白名单
public class whitelistutils {
//白名单接口
public static final list<string> richtexturls = arrays.aslist(
"/xxx/information/findbyunid",
"/xxx/getnoticeannouncementdetail");
}
6.xsswhitelist.json (自定义的jsoup白名单)
转载:
{
"addtags": [
"p",
"strong",
"em",
"u",
"s",
"blockquote",
"pre",
"h1",
"h2",
"h3",
"h4",
"h5",
"h6",
"br",
"ol",
"li",
"ul",
"sub",
"sup",
"span",
"iframe",
"a",
"img"
],
"addattributes": [
{
"tag": ":all",
"attributes": [
"class",
"id",
"src",
"style"
]
},
{
"tag": "pre",
"attributes": [
"spellcheck"
]
},
{
"tag": "iframe",
"attributes": [
"frameborder",
"allowfullscreen",
"src"
]
},
{
"tag": "a",
"attributes": [
"rel",
"target"
]
},
{
"tag": "img",
"attributes": [
"align",
"alt",
"height",
"src",
"title",
"width"
]
}
],
"addprotocols": [
{
"tag": "xx",
"attribute": "src",
"protocols": [
"src",
"http",
"https",
"data"
]
}
]
}
7.注意启动类不要忘记加@componentscan
四.jsoup
转载:https://www.jianshu.com/p/32abc12a175a
-
项目依赖
-
jsoup-1.9.2
<dependency>
<groupid>org.jsoup</groupid>
<artifactid>jsoup</artifactid>
<version>1.9.2</version>
</dependency>
jsoup 默认给我们提供了 5 个白名单对象
| 白名单对象 | 标签 | 说明 |
|---|---|---|
| none | 无 | 只保留标签内文本内容 |
| simpletext | b,em,i,strong,u | 简单的文本标签 |
| basic | a,b,blockquote,br,cite,code,dd,dl,dt,em,i,li,ol, p,pre,q,small,span,strike,strong,sub,sup,u,ul | 基本使用的标签 |
| basicwithimages | basic 的基础上添加了 img 标签 及 img 标签的 src,align,alt,height,width,title 属性 | 基本使用的加上 img 标签 |
| relaxed | a,b,blockquote,br,caption,cite,code,col,colgroup,dd, div,dl,dt,em,h1,h2,h3,h4,h5,h6,i,img,li,ol,p,pre,q,small, span,strike,strong,sub,sup,table,tbody,td,tfoot,th,thead,tr,u,ul | 在 basicwithimages 的基础上又增加了一部分部分标签 |
如果没有图片上传的需求, 使用 basic, 否则使用 basicwithimages
- 其他事项
在刚才测试的时候, 会发现 jsoup.clean() 方法返回的代码已经被进行格式化, 在标签及标签内容之间添加了 \n 回车符, 如果不需要的话, 可以使用jsoup.clean(testhtml, "", whitelist, new document.outputsettings().prettyprint(false));进行过滤
** 以下为实际项目中所使用的工具类 **
import org.jsoup.jsoup;
import org.jsoup.nodes.document;
import org.jsoup.safety.whitelist;
/**
* 描述: 过滤 html 标签中 xss 代码
*/
public class jsouputil {
/**
* 使用自带的 basicwithimages 白名单
* 允许的便签有 a,b,blockquote,br,cite,code,dd,dl,dt,em,i,li,ol,p,pre,q,small,span,strike,strong,sub,sup,u,ul,img
* 以及 a 标签的 href,img 标签的 src,align,alt,height,width,title 属性
*/
private static final whitelist whitelist = whitelist.basicwithimages();
/** 配置过滤化参数, 不对代码进行格式化 */
private static final document.outputsettings outputsettings = new document.outputsettings().prettyprint(false);
static {
// 富文本编辑时一些样式是使用 style 来进行实现的
// 比如红色字体 style="color:red;"
// 所以需要给所有标签添加 style 属性
whitelist.addattributes(":all", "style");
}
public static string clean(string content) {
return jsoup.clean(content, "", whitelist, outputsettings);
}
}
五.参考文章
【1】spring cloud gateway 过滤器防止跨站脚本攻击(存储xss、反射xss)
https://blog.csdn.net/qq_26801767/article/details/106235359?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_baidulandingword~default-4-106235359-blog-128300551.235v40pc_relevant_3m_sort_dl_base1&spm=1001.2101.3001.4242.3&utm_relevant_index=7
【2】xss(跨站脚本)漏洞详解之xss跨站脚本攻击漏洞的解决
http://www.uml.org.cn/safe/202203034.asp
【3】springcloud微服务实战——搭建企业级开发框架(五十一):微服务安全加固—自定义gateway拦截器实现防止sql注入/xss攻击
https://blog.csdn.net/wmz1932/article/details/129449794
【4】spring cloud gateway 实现xss、sql注入拦截
https://www.jianshu.com/p/17613323463d
【5】springboot针对富文本和非富文本添加xss过滤
https://blog.csdn.net/cholg/article/details/119949942
【6】详解xss 及springboot 防范xss攻击(附全部代码)
https://www.cnblogs.com/blbl-blog/p/17188558.html
![[ 云计算 | AWS 实践 ] Java 如何重命名 Amazon S3 中的文件和文件夹](https://images.3wcode.com/3wcode/20240802/s_0_202408020028483641.png)


发表评论