前言
自然语言处理(natural language process,简称nlp)是计算机科学与自然语言交互的一门学科,主要目的是使计算机能够理解自然语言处理以便能够完成相应的任务。 目前在nlp领域内通常都是通过语言模型来解决相应的问题,而语言模型是对人类语言的内在规律进行建模,从而能够准确的预测未来(或缺失)或词元(token)的概率。根据所采用技术方法的不同,目前语言模型相关的研究工作可以分为以下四个不同的发展阶段。
统计语言阶段
统计语言模型(statistical language model, slm)兴起于20世纪90年代,这一类模型是基于统计学习方法发展而来的。具体来说,slm使用马尔科夫假设(markov assumption)来建立语言序列的预测模型,通常是根据若干个连续的上下文来预测下一个词出现的概率,这种基于固定上下文长度的统计语言模型通常被称为n元语言模型(n-gram),通常使用得比较多的是二元或者三元语言模型,随着阶数n的增加,需要估计的转移概率项数将会出现指数级增长,从而导致出现“维度灾难”的问题,因此,slm通常被广泛应用在信息检索和nlp领域的早期研究工作。同时为了缓解数据稀疏的问题,通常需要设计专门的语言模型平滑策略,然而平滑方法对于高阶上下文的刻画能力仍然比较有限,无法精确的建立复杂的高阶语义之间的关系。
深度学习阶段
在深度学习阶段主要采用的是神经语言模型(neural language model, nlm)。nlm使用神经网络模拟文本序列的生成,通常使用的循环神经网络(recurrent neural network, rnn)。早期是通过引入分布式词表示(distributed word representation)这一概念,并构建基于聚合上下文特征(即分布式词向量)的目标词预测函数。分布式词表示使用低维稠密向量来表示词汇的寓意,与基于词典空间的稀疏词向量表示(one-hot representation)有着本质的不同,能够刻画更加丰富的隐含语义特征。同时,稠密向量的非零表征对于复杂语言模型的搭建非常友好,能够有效克服统计语言模型中的数据稀疏问题。分布式词向量又称为“词嵌入”(word embedding)。这种基于隐含语义特征的语言建模方法为自然语言处理任务提供了一种较为通用的解决途径。在这一系列工作中,比较具有代表性的学习模型是word2vec,它构建了一个简化的浅层神经网络来学习分布式词表示,所学习到的词嵌入可以用于后续任务的语义特征提取器,在自然语言处理任务中得到了广泛使用,取得了显著的性能提升。这些创新性的研究工作将语言模型用于文本表示学习,在自然语言处理领域产生了重要的影响。
预训练模型阶段
预训练语言模型与早期的词嵌入模型相比,在训练架构和训练数据两个方面进行了改进和创新。如早期的预训练模型elmo提出使用大量无标注的数据训练双向lstm网络,预训练完成后得到的bilstm可以用来学习上下文感知的单词表示,这与word2vec学习固定的词表示有着显著不同。进一步,elmo可以根据下游任务数量对bilstm网络进行微调,从而实现面向特定任务的模型优化。而传统序列神经网络的长文本建模能力较弱,并且不容易并行训练,这些缺点限制了早期预训练模型的性能。2017年google提出了基于自注意力机制的transformer模型,通过自注意力机制建模长序列关系。
transformer网络模型的架构图如下所示:
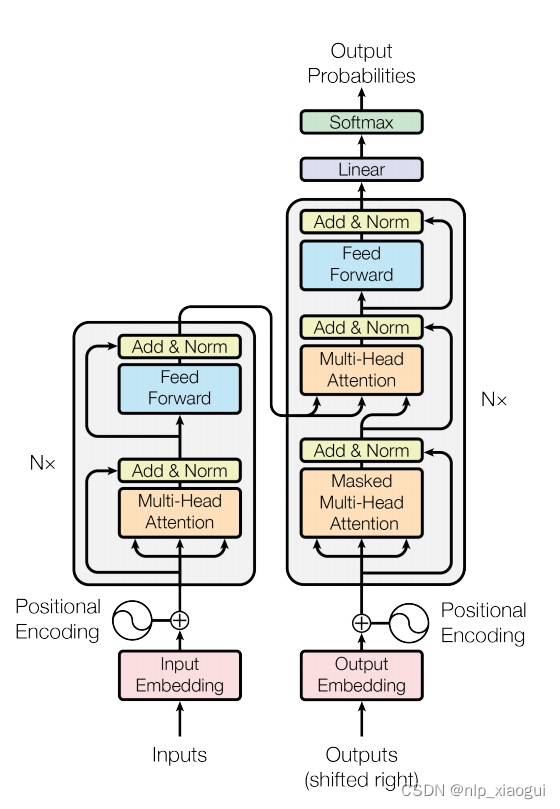
transformer的一个主要优势是其模型设计对于硬件非常友好,可以为研发大语言模型提供可并行化的神经网络架构。基于transformer架构,google进一步提出了预训练模型bert,该模型仅使用了transformer架构的encoder部分,并通过在大规模无标注数据上使用专门设计的预训练任务来学习双向语言模型。同时openai也基于transformer的架构提出了gpt-1,gpt-1仅采用了transformer的decoder模块,以及基于下一个词元预测的预训练任务进行模型的训练。elmo、bert和gpt模型的对比架构图如下所示:
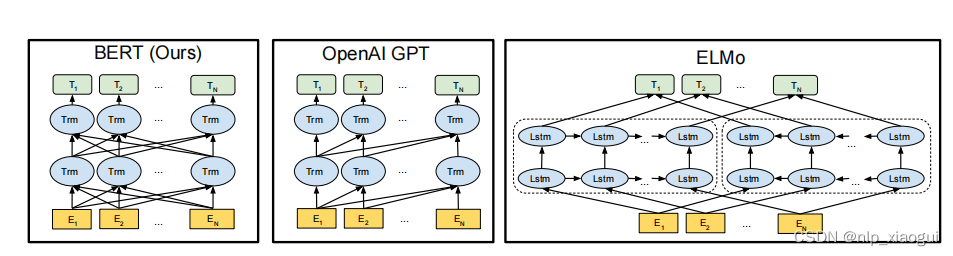
一般来说,编码器架构被认为更适合去解决自然语言理解任务(如完形填空等),而解码器架构更适合解决自然语言生成任务(如文本摘要等)。预训练阶段旨在通过大规模无标注文本简历模型的基础能力,而微调阶段则使用有标注数据对于模型进行特地你任务的适配,从而更好地解决下游的自然语言处理任务。
大语言模型阶段
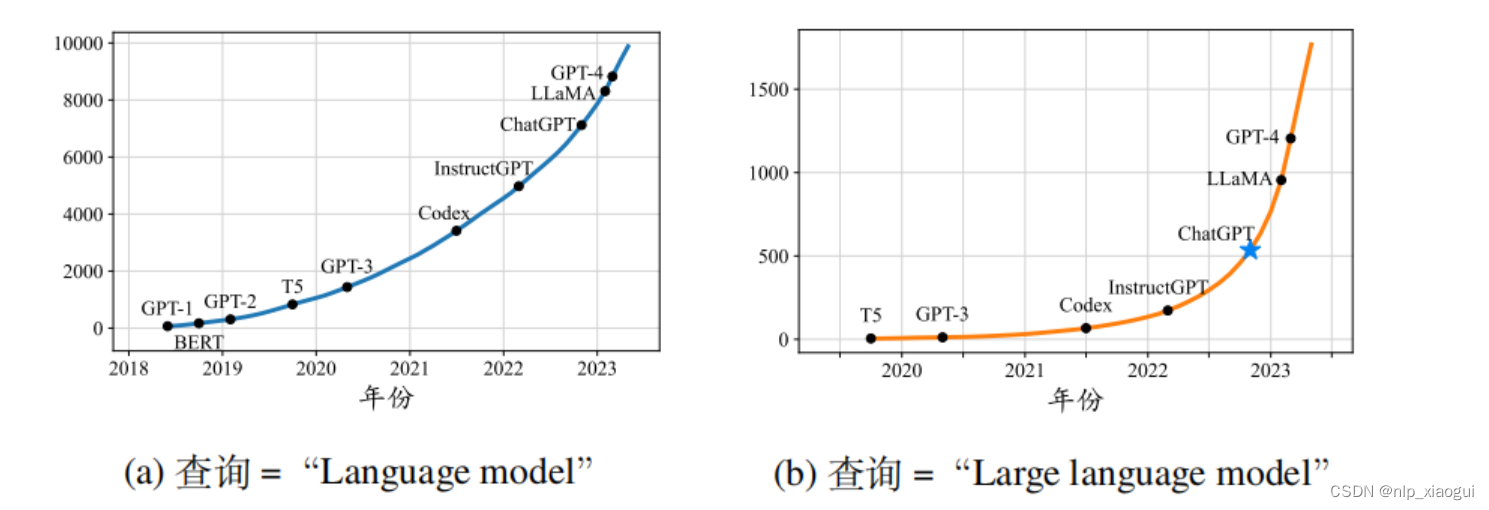
随着模型规模的扩展(如增加模型参数规模或数据规模)通常会带来下游任务的模型性能提升,这种现象通常被称为“扩展法则”(scaling law)。一些研究工作尝试训练更大的预训练语言模型来探索扩展语言模型所带来的性能极限。这些大规模的预训练语言模型在解决复杂任务时表现出了与小型预训练语言模型不同的行为。这种大模型具有但小模型不具有的能力通常被称为“涌现能力”。为了区分这一能力上的差异,学术界将这些大型预训练语言模型命名为“大语言模型”。作为大语言模型的一个代表性应用,chatgpt将gpt系列大语言训练模型适配到对话任务中,展现出令人震撼的人际对话能力,已经上线就取得了社会的广泛关注,chatgpt发布后,与大语言模型相关的arxiv论文数量迅速增长(如下图所示),这一研究方向收到了学术界的高度关注。
reference
赵鑫、李俊毅、周坤、唐天一、文继荣. 大语言模型, 2024




发表评论