【科学文献计量】利用pybibx分析Scopus文献数据集(EDA,N-Grams,Cluster,Network analysis,NLP)
文章介绍了利用pybibx库对scopus文献数据,进行探索式分析EDA,N-Grams语言模型构建及可视化,文献聚类和映射,网络分析(社区网络分析、个人网络分析,合作组织网络分析)、NLP(词嵌入模型、BERT模型、chatGPT大语言模型下的主题建模和摘要提取)
手动反爬虫: https://blog.csdn.net/lys_828/article/details/133754558
知识梳理不易,请尊重劳动成果,文章仅发布在csdn网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
欢迎交流
作者邮箱:xianl828@163.com
微信:lys_828
1 运行前准备
1.1 数据集
scopus数据格式需要为bib格式,文件放置在assets文件夹下的bibs数据文件夹中
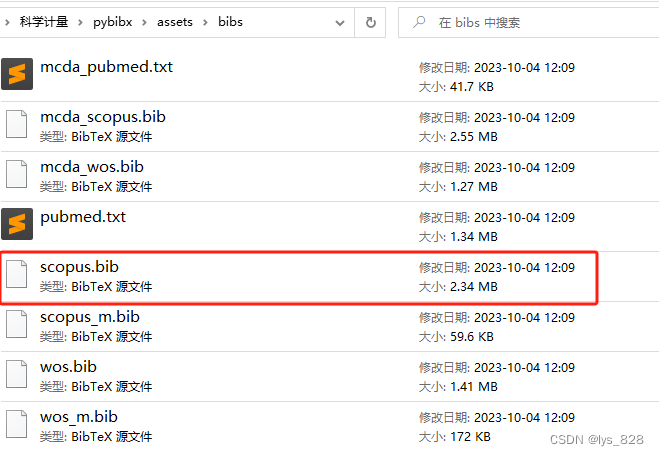
1.2 前置库
numpy的版本需要小于1.25
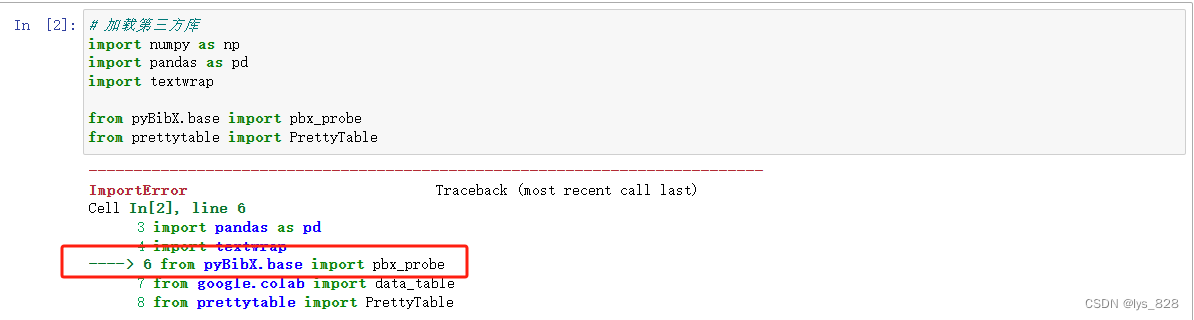
具体的报错信息如下
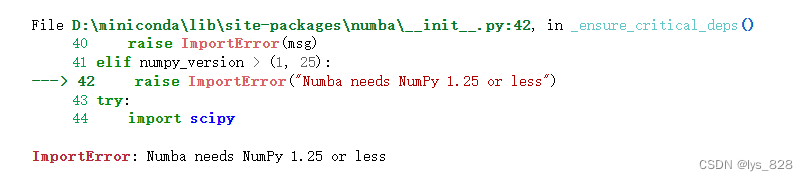
可以在命令行中安装
相关文章:
-
-
-
-
-

自动驾驶:技术创新与安全挑战
1.背景介绍自动驾驶技术是近年来以快速发展的人工智能领域中的一个重要应用。自动驾驶旨在通过集成传感器、计算机视觉、机器学习、深度学习、人工智能、路径规划和控制等...
[阅读全文]
-
版权声明:本文内容由互联网用户贡献,该文观点仅代表作者本人。本站仅提供信息存储服务,不拥有所有权,不承担相关法律责任。
如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 2386932994@qq.com 举报,一经查实将立刻删除。



发表评论