前言
决策树(decision trees)
决策树是一种基于树形结构的分类(或回归)模型,它通过对数据集中的特征进行递归地分割,以构建一个树形结构,从而实现对数据的分类或预测。
决策树的一般步骤
- 特征选择:根据某种准则(如信息增益、基尼不纯度等),选择最佳的特征来进行数据集的划分
- 节点分裂:将数据集根据选定的特征进行分割,生成新的节点。
- 递归处理:对每个新生成的节点重复上述过程,直到达到停止条件,如节点达到最大深度、样本数低于阈值等。
- 叶节点标记:当达到停止条件时,将叶节点标记为最终的类别(或回归值)。
决策树的优点包括易于理解和解释、能够处理数值型和类别型数据、对缺失值不敏感等。然而,单独的决策树容易过拟合,泛化能力较弱,为了解决这个问题,可以使用集成学习方法,如随机森林。

基本公式
决策树的基本公式用于计算特征选择的准则,例如信息增益(information gain)或基尼不纯度(gini impurity)。以信息增益为例,其计算公式为:
i
g
(
d
,
f
)
=
i
(
d
)
−
∑
v
=
1
v
∣
d
v
∣
∣
d
∣
i
(
d
v
)
ig(d, f) = i(d) - \sum_{v=1}^{v} \frac{|d_v|}{|d|} i(d_v)
ig(d,f)=i(d)−v=1∑v∣d∣∣dv∣i(dv)
其中:
- ig(d, f) 是特征f的信息增益;
- i(d) 是数据集 d 的初始信息熵;
- v 是特征 f 的可能取值个数;
- d_v 是数据集 d 中特征 f 取值为 v 的子集;
- |d| 和 |d_v| 分别是数据集 d 和子集 d_v 的样本数量;
- i(d) 和 i(d_v) 分别是数据集 d 和子集 d_v 的信息熵,计算方式为 i ( d ) = − ∑ i = 1 c p i log 2 ( p i ) i(d) = -\sum_{i=1}^{c} p_i \log_2(p_i) i(d)=−i=1∑cpilog2(pi),其中 p_i 是数据集中类别 i 的样本比例。
代码实现
以下是使用python和scikit-learn库构建决策树模型的示例代码:
from sklearn.datasets import load_iris
from sklearn.tree import decisiontreeclassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
x = iris.data
y = iris.target
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
# 创建决策树分类器
dt_classifier = decisiontreeclassifier()
# 训练模型
dt_classifier.fit(x_train, y_train)
# 预测并计算准确率
y_pred = dt_classifier.predict(x_test)
accuracy = accuracy_score(y_test, y_pred)
print("决策树模型的准确率:", accuracy)
随机森林(random forests)
随机森林是一种集成学习方法,通过同时训练多个决策树来提高分类(或回归)性能。随机森林的基本思想是:通过随机选择特征子集和样本子集,构建多个决策树,并通过投票(分类任务)或平均(回归任务)来得到最终的预测结果。
随机森林的主要步骤
- 随机选择特征子集:对于每棵决策树的训练过程中,随机选择特征子集,以保证每棵树的差异性。
- 随机选择样本子集:对于每棵决策树的训练过程中,随机选择样本子集,以保证每棵树的差异性。
- 独立训练:利用选定的特征子集和样本子集独立地训练每棵决策树。
- 投票(或平均):对于分类任务,通过投票来确定最终的类别;对于回归任务,通过平均来确定最终的预测值。
随机森林相对于单个决策树具有更好的泛化能力和抗过拟合能力,因为它通过集成多个模型来减少方差。此外,由于随机森林的并行性,它的训练过程可以很好地进行并行化处理,适用于大规模数据集。
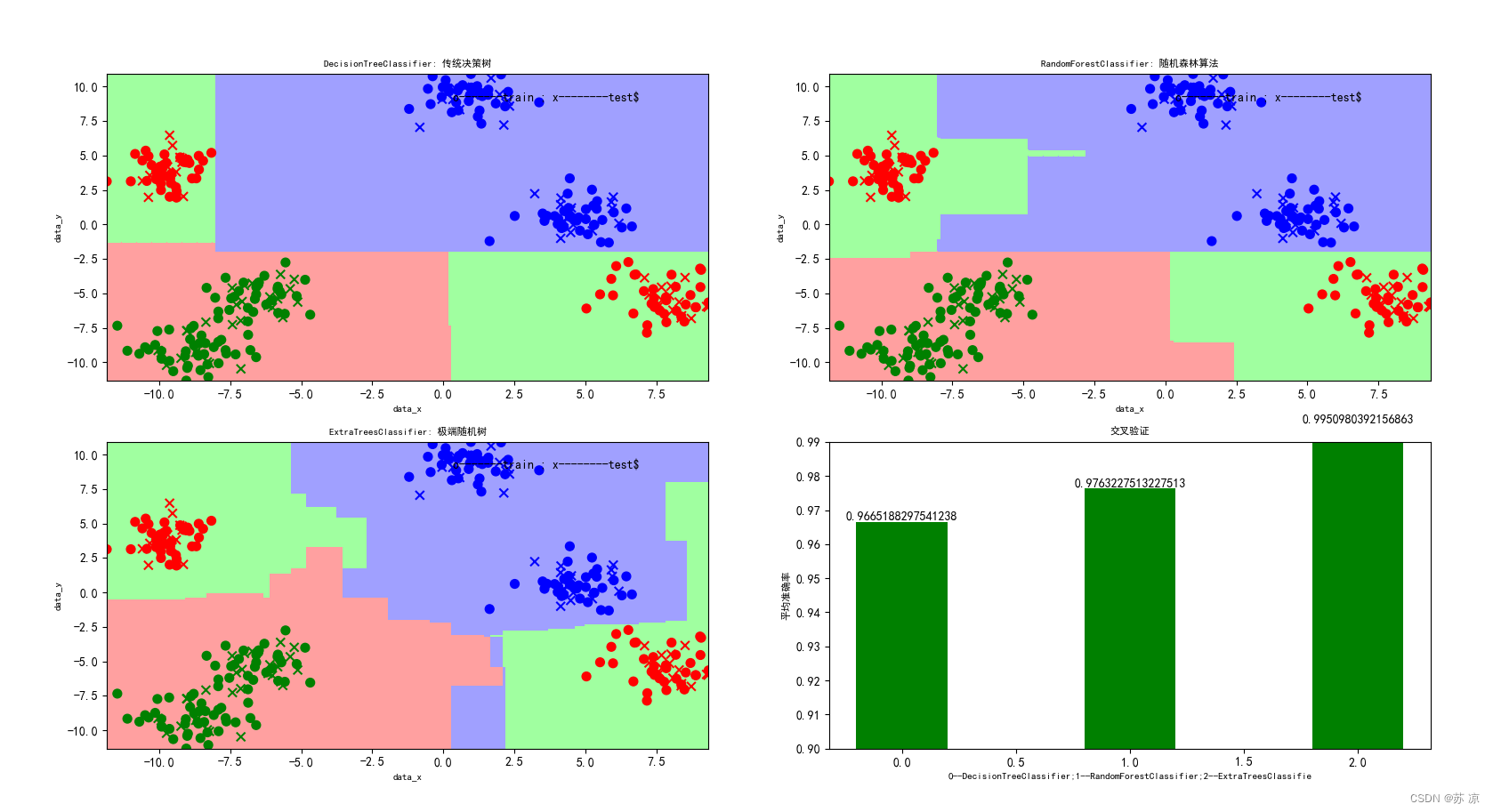
基本公式
随机森林的核心思想是集成多个决策树,通过投票(分类任务)或平均(回归任务)来得到最终的预测结果。对于分类任务,假设我们有
t 棵树,每棵树的预测结果为
y
^
i
\hat{y}_i
y^i,则随机森林的预测结果为:
y ^ rf = argmax c ∑ i = 1 t i ( y ^ i = c ) \hat{y}_{\text{rf}} = \text{argmax}_c \sum_{i=1}^{t} i(\hat{y}_i = c) y^rf=argmaxci=1∑ti(y^i=c)
其中:
-
y ^ rf \hat{y}_{\text{rf}} y^rf 是随机森林的预测结果;
-
y ^ i \hat{y}_i y^i 是第 i 棵树的预测结果;
-
t 是随机森林中树的数量;
-
c 是类别标签;
-
i( ) 是指示函数,表示当 y ^ i \hat{y}_i y^i 等于类别 c 时返回1,否则返回0。
代码实现
以下是使用python和scikit-learn库构建随机森林模型的示例代码:
from sklearn.ensemble import randomforestclassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 创建随机森林分类器
rf_classifier = randomforestclassifier(n_estimators=100, random_state=42)
# 训练模型
rf_classifier.fit(x_train, y_train)
# 预测并计算准确率
y_pred_rf = rf_classifier.predict(x_test)
accuracy_rf = accuracy_score(y_test, y_pred_rf)
print("随机森林模型的准确率:", accuracy_rf)
结语
决策树和随机森林作为机器学习中的经典算法,在计算机视觉领域发挥着重要作用。它们能够从图像数据中学习模式和特征,并用于图像分类、目标检测、特征提取等任务。决策树通过递归地进行特征选择和节点分裂,构建起对图像数据的分类模型;而随机森林则通过集成多个决策树,利用投票或平均的方式获得更加稳健和准确的分类结果。这些算法的应用使得计算机能够更加智能地处理和理解图像数据,为图像识别、智能监控、自动驾驶等领域的发展提供了强大支持。在未来,随着计算机视觉技术的不断发展和深入,决策树和随机森林这样的经典算法将继续发挥着重要作用,为实现更智能、更高效的图像分析和处理提供技术支持。




发表评论