文章目录
udf 是什么?
hive 中的 udf 其实就是用户自定义函数,允许用户注册使用自定义的逻辑对数据进行处理,丰富了hive 对数据处理的能力。
udf 负责完成对数据一进一出处理的操作,和 hive 中存在的函数 year、month、day 等相同。
reflect
在 hive 中,可以使用 reflect() 方法通过 java 反射机制调用 java 类的方法。
通俗来说,它可以调用 hive 中不存在,但是 jdk 中拥有的方法。
语法
reflect()函数的语法为:reflect(class,method[,arg1[,arg2..]])。
静态方法调用
假设当前在 java 中存在类如下:
package com.example;
public class mathutils {
public static int addnumbers(int a, int b) {
return a + b;
}
}
那么使用 reflect() 方法调用时,如下所示:
select reflect("com.example.mathutils", "addnumbers", 3, 5) as result;
注意! 这里的类 "com.example.mathutils" 并不是在 jdk 中真实存在的,只是我作为说明的一个案例, reflect() 方法只能调用 jdk 中(原生内置)存在的方法。
所以当你需要使用 reflect() 方法时,需要先去查找调用的目标方法全类名、方法名以及是否需要传递参数。
实例方法调用
当我们需要调用 java 中的实例方法时,先创建 java 对象,然后再调用其方法。
例如:将乱码的字符串进行解析。
select reflect('java.net.urldecoder', 'decode', "mozilla/5.0%20(compatible;%20mj12bot/v1.4.7;%20http://www.majestic12.co.uk/bot.php?+)
" ,'utf-8') as result;
结果输出如下:

自定义 udf(genericudf)
hive 支持两种 udf 函数自定义操作,分别是:
-
genericudf(通用udf):用于实现那些可以处理任意数据类型的函数。它们的输入和输出类型可以是任意的,但需要在函数内部处理类型转换和逻辑,可以实现更复杂的逻辑处理。
-
udf:用于实现那些只能处理特定数据类型的函数。每个 udf 都明确指定了输入参数的类型和返回值类型,使用更为简单。
本文采用的是通用 udf —— genericudf 实现方法
这里通过一个在 hive 中实现两数相加的自定义 udf 案例来进行说明,看完你就会啦,轻松拿捏。
1.创建项目
在 idea 中创建一个 maven 项目,引入 hive 依赖,如下所示:
<?xml version="1.0" encoding="utf-8"?>
<project xmlns="http://maven.apache.org/pom/4.0.0"
xmlns:xsi="http://www.w3.org/2001/xmlschema-instance"
xsi:schemalocation="http://maven.apache.org/pom/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelversion>4.0.0</modelversion>
<groupid>org.jsu</groupid>
<artifactid>myudf</artifactid>
<version>1.0-snapshot</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<!-- hive-exec依赖无需打到jar包,故scope使用provided-->
<dependency>
<groupid>org.apache.hive</groupid>
<artifactid>hive-exec</artifactid>
<version>3.1.3</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupid>org.apache.maven.plugins</groupid>
<artifactid>maven-assembly-plugin</artifactid>
<version>3.0.0</version>
<configuration>
<!--将依赖编译到jar包中-->
<descriptorrefs>
<descriptorref>jar-with-dependencies</descriptorref>
</descriptorrefs>
</configuration>
<executions>
<!--配置执行器-->
<execution>
<id>make-assembly</id>
<!--绑定到package执行周期上-->
<phase>package</phase>
<goals>
<!--只运行一次-->
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
注意,引入的 hive 依赖版本请保持和你集群中使用的版本一致。
2.创建类继承 udf
创建一个类,我这里取名为 addtest,继承 hive udf 父类 genericudf,需要重写三个方法,如下所示:
import org.apache.hadoop.hive.ql.exec.udfargumentexception;
import org.apache.hadoop.hive.ql.metadata.hiveexception;
import org.apache.hadoop.hive.ql.udf.generic.genericudf;
import org.apache.hadoop.hive.serde2.objectinspector.objectinspector;
public class addtest extends genericudf {
@override
public objectinspector initialize(objectinspector[] objectinspectors) throws udfargumentexception {
return null;
}
@override
public object evaluate(deferredobject[] deferredobjects) throws hiveexception {
return null;
}
@override
public string getdisplaystring(string[] strings) {
return null;
}
}
-
initialize(objectinspector[] objectinspectors)方法
这个方法是在 udf 初始化时调用的。它用于执行一些初始化操作,并且可以用来验证 udf 的输入参数类型是否正确。参数objectinspectors是一个包含输入参数的objectinspector数组,它描述了每个输入参数的类型和结构。
一般在这个方法中检查输入参数的数量和类型是否满足你的函数的要求。如果输入参数不符合预期,你可以抛出udfargumentexception异常。如果一切正常,你需要返回一个合适的objectinspector对象,它描述了你的函数返回值的类型。 -
evaluate(deferredobject[] deferredobjects)方法
在这个方法中定义真正执行 udf 逻辑的地方,获取输入的参数,并且根据输入参数执行相应的计算或操作。参数deferredobjects是一个包含输入参数的 deferredobject 数组,你可以通过它来获取实际的输入值。 -
getdisplaystring(string[] strings)方法
这个方法用于描述 udf 的信息,用于生成可读的查询执行计划(explain),以便用户了解查询的结构和执行过程。
3.数据类型判断
实现 udf 的第一步操作就是在 initialize 方法中,判断用户输入的参数是否合法,出现错误时,进行反馈。
在这里主要分为三个步骤:
-
检验参数个数
-
检查参数类型
-
定义函数返回值类型
一般情况下,可以使用下面的模板:
@override
public objectinspector initialize(objectinspector[] objectinspectors) throws udfargumentexception {
// 1.校验参数个数
if (objectinspectors.length != 2) {
throw new udfargumentexception("参数个数有误!");
}
// 2.检查第1个参数是否是int类型
// 判断第1个参数的基本类型
objectinspector num1 = objectinspectors[0];
if (num1.getcategory() != objectinspector.category.primitive) {
throw new udfargumentexception("第1个参数不是基本数据类型");
}
// 第1个参数类型判断
primitiveobjectinspector temp = (primitiveobjectinspector) num1;
if (primitiveobjectinspector.primitivecategory.int != temp.getprimitivecategory()) {
throw new udfargumentexception("第1个参数应为int类型");
}
// 2.检查第2个参数是否是int类型
// 判断第2个参数的基本类型
objectinspector num2 = objectinspectors[1];
if (num2.getcategory() != objectinspector.category.primitive) {
throw new udfargumentexception("第2个参数不是基本数据类型");
}
// 第2个参数类型判断
primitiveobjectinspector temp2 = (primitiveobjectinspector) num2;
if (primitiveobjectinspector.primitivecategory.int != temp2.getprimitivecategory()) {
throw new udfargumentexception("第2个参数应为int类型");
}
// 3.设置函数返回值类型(返回一个整型数据)
return primitiveobjectinspectorfactory.javaintobjectinspector;
}
4.编写业务逻辑
在 evaluate 方法中定义业务逻辑,这里比较简单,就是实现两数相加。
@override
public object evaluate(deferredobject[] deferredobjects) throws hiveexception {
// 完成两数相加的逻辑计算
int num1 = integer.parseint(deferredobjects[0].get().tostring());
int num2 = integer.parseint(deferredobjects[1].get().tostring());
return num1 + num2;
}
5.定义函数描述信息
在 getdisplaystring 方法中定义函数在 explain 中的描述信息,一般都是固定写法,如下所示:
@override
public string getdisplaystring(string[] strings) {
return getstandarddisplaystring("addtest", strings);
}
把对应的函数名称进行替换即可。
6.打包与上传
对编写的项目进行打包,并上传到 hdfs 上。
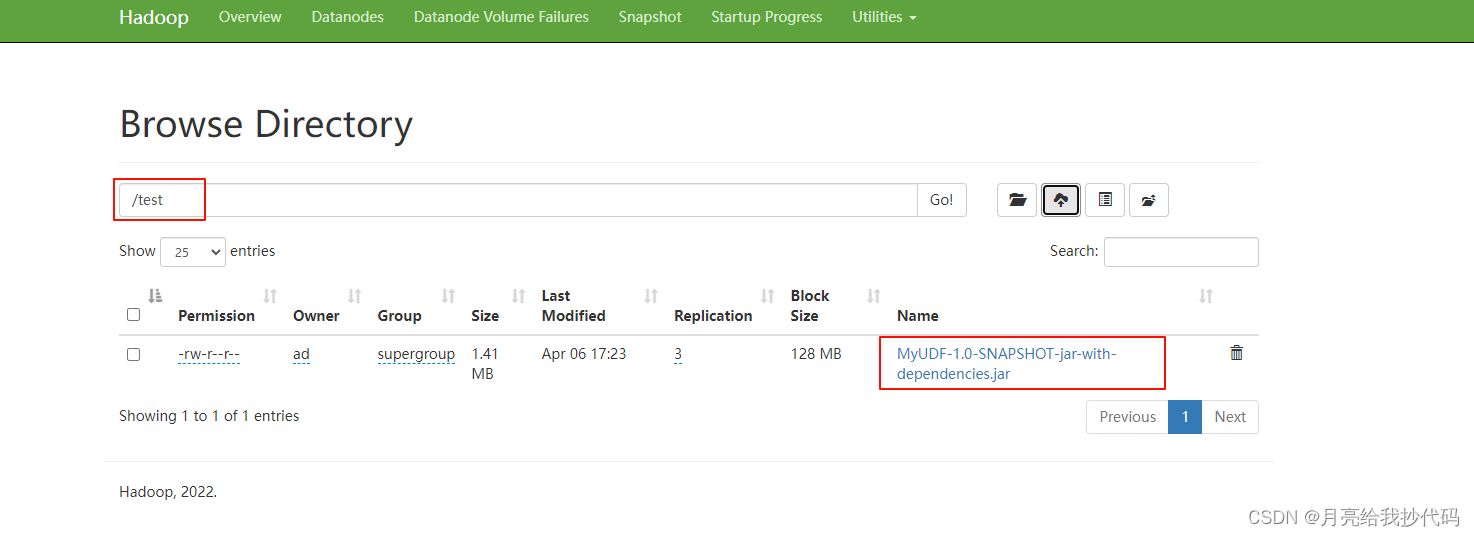
本案例的完整代码如下所示:
import org.apache.hadoop.hive.ql.exec.udfargumentexception;
import org.apache.hadoop.hive.ql.metadata.hiveexception;
import org.apache.hadoop.hive.ql.udf.generic.genericudf;
import org.apache.hadoop.hive.serde2.objectinspector.objectinspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitiveobjectinspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.primitiveobjectinspectorfactory;
public class addtest extends genericudf {
@override
public objectinspector initialize(objectinspector[] objectinspectors) throws udfargumentexception {
// 1.校验参数个数
if (objectinspectors.length != 2) {
throw new udfargumentexception("参数个数有误!");
}
// 2.检查第1个参数是否是int类型
// 判断第1个参数的基本类型
objectinspector num1 = objectinspectors[0];
if (num1.getcategory() != objectinspector.category.primitive) {
throw new udfargumentexception("第1个参数不是基本数据类型");
}
// 第1个参数类型判断
primitiveobjectinspector temp = (primitiveobjectinspector) num1;
if (primitiveobjectinspector.primitivecategory.int != temp.getprimitivecategory()) {
throw new udfargumentexception("第1个参数应为int类型");
}
// 2.检查第2个参数是否是int类型
// 判断第2个参数的基本类型
objectinspector num2 = objectinspectors[1];
if (num2.getcategory() != objectinspector.category.primitive) {
throw new udfargumentexception("第2个参数不是基本数据类型");
}
// 第2个参数类型判断
primitiveobjectinspector temp2 = (primitiveobjectinspector) num2;
if (primitiveobjectinspector.primitivecategory.int != temp2.getprimitivecategory()) {
throw new udfargumentexception("第2个参数应为int类型");
}
// 3.设置函数返回值类型(返回一个整型数据)
return primitiveobjectinspectorfactory.javaintobjectinspector;
}
@override
public object evaluate(deferredobject[] deferredobjects) throws hiveexception {
// 完成两数相加的逻辑计算
int num1 = integer.parseint(deferredobjects[0].get().tostring());
int num2 = integer.parseint(deferredobjects[1].get().tostring());
return num1 + num2;
}
@override
public string getdisplaystring(string[] strings) {
return getstandarddisplaystring("addtest", strings);
}
}
7.注册 udf 函数并测试
进入 hive 中对创建的 udf 函数进行注册。
如果你期间修改了 jar 包并重新上传,则需要重启与 hive 的连接,建立新的会话才会生效。
-- 永久注册
create function testadd as 'addtest' using jar 'hdfs://hadoop201:8020/test/myudf-1.0-snapshot-jar-with-dependencies.jar';
-- 删除注册的函数
drop function if exists testadd;
-
testadd:注册的 udf 函数名称。 -
as 'addtest':编写的 udf 函数全类名。 -
using jar:指定 jar 包的全路径。
注册成功后,如下所示:

测试
select testadd(1,2);

如果输入错误的数据类型,会进行报错提示:

返回复杂的数据类型
在更多的场景下,我们可能有多个返回值,那么该如何定义与配置呢?
这里还是通过上面的两数相加的案例来进行说明,套下面的模板使用:
import org.apache.hadoop.hive.ql.exec.udfargumentexception;
import org.apache.hadoop.hive.ql.metadata.hiveexception;
import org.apache.hadoop.hive.ql.udf.generic.genericudf;
import org.apache.hadoop.hive.serde2.objectinspector.objectinspector;
import org.apache.hadoop.hive.serde2.objectinspector.objectinspectorfactory;
import org.apache.hadoop.hive.serde2.objectinspector.primitiveobjectinspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.primitiveobjectinspectorfactory;
import java.util.arraylist;
public class addtestreturnlist extends genericudf {
@override
public objectinspector initialize(objectinspector[] objectinspectors) throws udfargumentexception {
// 1.校验参数个数
if (objectinspectors.length != 2) {
throw new udfargumentexception("参数个数有误!");
}
// 2.检查第1个参数是否是int类型
// 判断第1个参数的基本类型
objectinspector num1 = objectinspectors[0];
if (num1.getcategory() != objectinspector.category.primitive) {
throw new udfargumentexception("第1个参数不是基本数据类型");
}
// 第1个参数类型判断
primitiveobjectinspector temp = (primitiveobjectinspector) num1;
if (primitiveobjectinspector.primitivecategory.int != temp.getprimitivecategory()) {
throw new udfargumentexception("第1个参数应为int类型");
}
// 2.检查第2个参数是否是int类型
// 判断第2个参数的基本类型
objectinspector num2 = objectinspectors[1];
if (num2.getcategory() != objectinspector.category.primitive) {
throw new udfargumentexception("第2个参数不是基本数据类型");
}
// 第2个参数类型判断
primitiveobjectinspector temp2 = (primitiveobjectinspector) num2;
if (primitiveobjectinspector.primitivecategory.int != temp2.getprimitivecategory()) {
throw new udfargumentexception("第2个参数应为int类型");
}
// 3.设置函数返回值类型(返回一个键值对数据)
arraylist<string> structfieldnames = new arraylist<>();
arraylist<objectinspector> structfieldobjectinspectors = new arraylist<>();
structfieldnames.add("result");
structfieldobjectinspectors.add(primitiveobjectinspectorfactory.javastringobjectinspector);
return objectinspectorfactory.getstandardstructobjectinspector(structfieldnames, structfieldobjectinspectors);
}
@override
public object evaluate(deferredobject[] deferredobjects) throws hiveexception {
// 完成两数相加的逻辑计算
arraylist<integer> arraylist = new arraylist<>();
int num1 = integer.parseint(deferredobjects[0].get().tostring());
int num2 = integer.parseint(deferredobjects[1].get().tostring());
arraylist.add(num1 + num2);
return arraylist;
}
@override
public string getdisplaystring(string[] strings) {
return getstandarddisplaystring("addtestreturnlist", strings);
}
}
(退出当前与 hive 的连接,建立新的连接,刷新缓存)
同样的,打包上传到 hdfs 上进行注册:
create function addtestreturnlist as 'addtestreturnlist' using jar 'hdfs://hadoop201:8020/test/myudf-1.0-snapshot-jar-with-dependencies.jar';
此时,可能会发生报错,这是由于我们之前已经加载过该 jar 包了,再次加载时 hive 会抛出异常,我们可以通过下面的语句进行调整:
-- 关闭向量化查询
set hive.vectorized.execution.enabled=false;
重新注册即可。
进行测试:
select addtestreturnlist(1,2);
计算结果如下:

是不是轻松拿捏了~


发表评论