1 大数据集群
1.1 大数据集群介绍
spark集群是一种分布式计算框架,它基于内存计算,提供了高效的数据抽象和并行计算能力,能够处理大规模数据集的批处理和实时处理任务。spark采用内存存储中间计算结果,可减少迭代运算的磁盘i/o,并通过并行计算有向无环图的优化,使其运行速度比mapreduce快100倍;spark可以使用hadoop yarn和apache mesos作为其资源管理和调度器,可以从多种数据源读取数据,如hdfs、hbase、mysql等。
pyspark则是spark的python api,允许python开发者利用spark的强大功能进行数据处理和分析。本案例采用pyspark大数据集群做数据分析与挖掘,使用hdfs作为文件存储系统。pyspark由多个组件构成,包括spark sql、spark streaming、mllib(机器学习库)和graphx(图计算库)等。
本案例部署了3个节点的完全分布式集群,具体的开发环境如下:
| 节点/组件/安装包 | 版本 | 备注 |
|---|---|---|
| 名称节点 | 192.168.126.10 | master |
| 数据节点 | 192.168.126.10 | slave1 |
| 数据节点 | 192.168.126.10 | slave2 |
| jdk | jdk-8u281 | java运行环境,spark的运行需要jdk的支持 |
| hadoop | hadoop-3.1.4 | 提供hdfs、hive运行环境支持。hdfs系统访问端口为:hdfs://192.168.126.10:9000 |
| pyspark | spark-3.4.3-bin-hadoop3.tgz | spark集群的master节点的地址和端口为:spark://192.168.126.10:7077 |
| mysql | 5.7.18 | 存储数据分析结果,端口:3306,用户名:root,密码:123456 |
| python | python-3.9.0.tgz | 3.9.0版本的python |
| mysql connector | mysql-connector-java-5.1.32-bin.jar | spark 连接mysql的驱动 |
| intellij idea | ultimate 2020.3 | 编程工具idea |
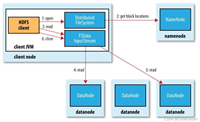
大数据集群运行时,spark的管理页面如下图所示:
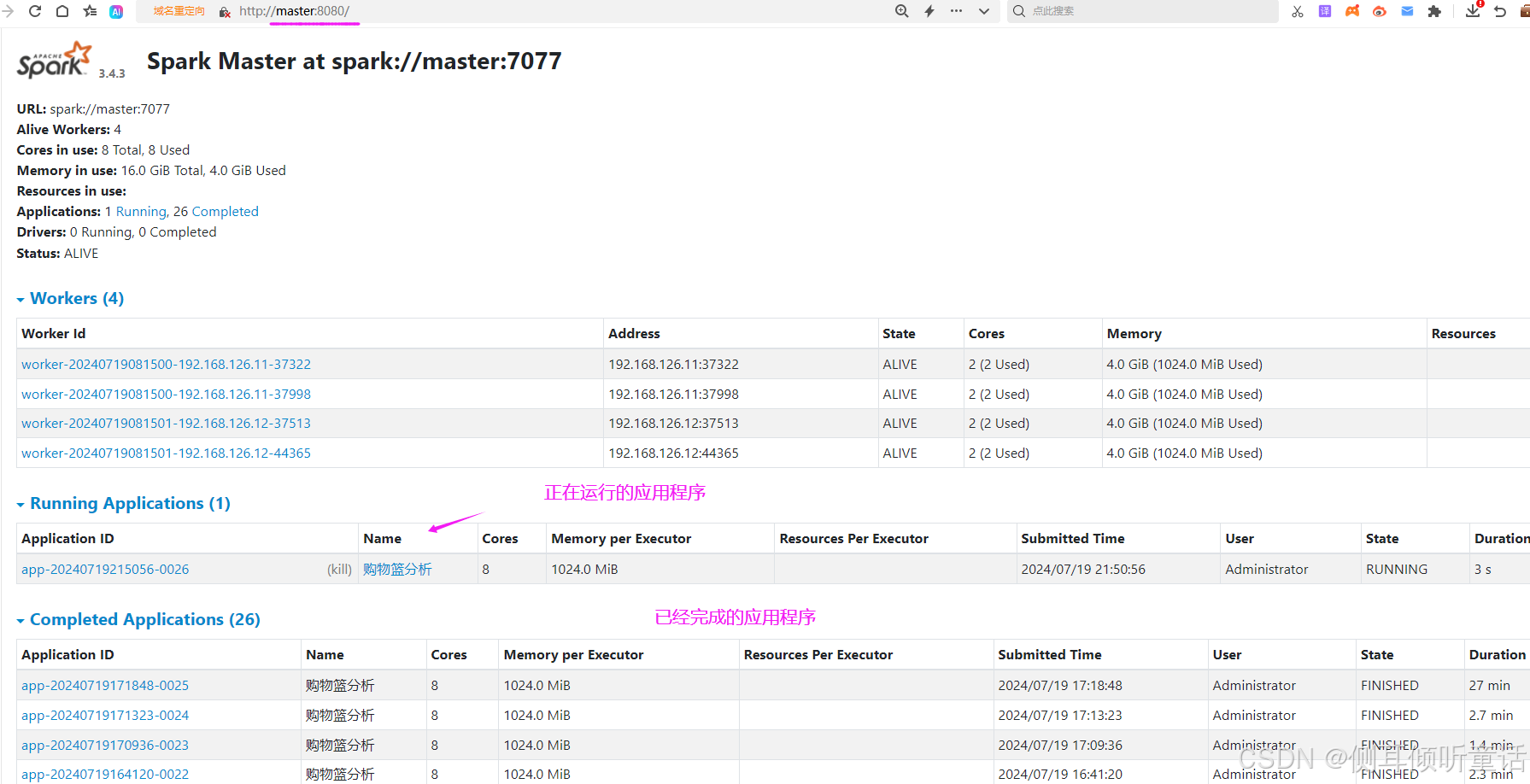
1.2 大数据集群部署、相关组件(软件)的配置(略,后续更新)
2 购物篮数据分析与挖掘
2.1 数据集介绍
“assignment-1_data”数据集,包含与消费者购物行为相关的数据,用于市场购物篮分析(mba)和关联规则挖掘(association rule mining),目的是通过分析消费者在购买过程中的商品组合,揭示商品之间的关联性和购买行为模式。
数据集下载地址: 购物篮数据集
2.1.1 数据集包含的内容
数据集的字段如下图所示:
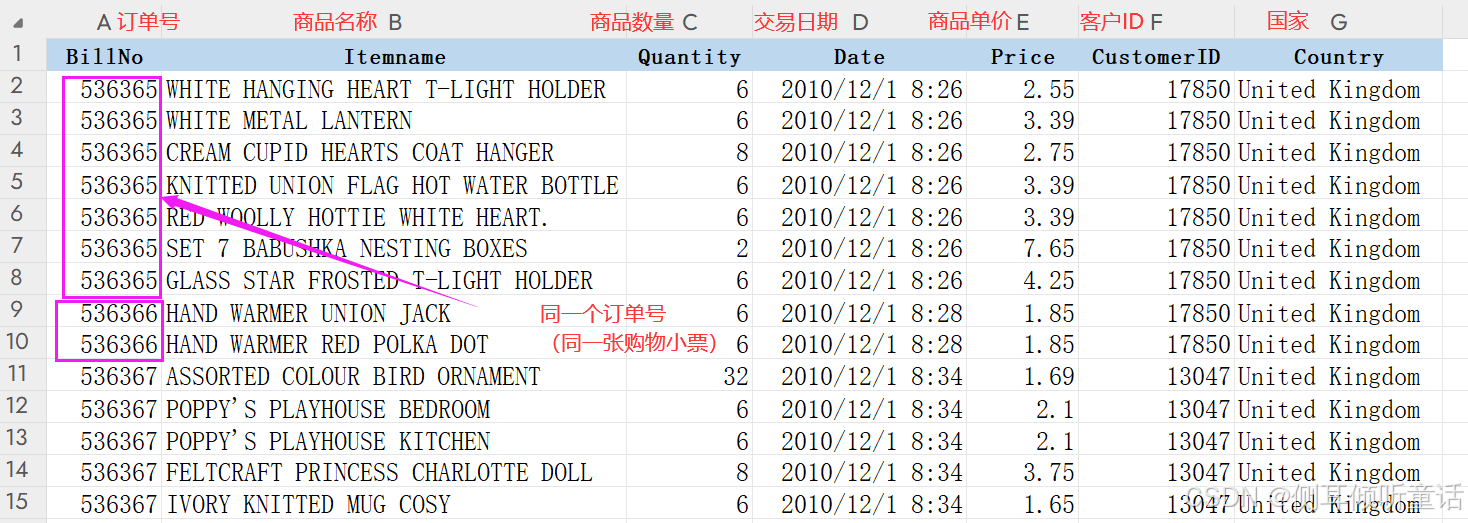
| 字段 | 说明 | 备注 |
|---|---|---|
| 订单号(billno) | 用于唯一标识每一笔交易或订单。 | 订单信息 |
| 购买日期(date) | 记录订单发生的日期 | 订单信息 |
| 客户id(customerid) | 用于标识购买该订单的客户,可用于进一步分析客户的购买习惯和偏好。 | 订单信息 |
| 商品名称(itemname) | 列出订单中包含的商品名称。 | 商品信息 |
| 数量(quantity) | 每种商品在订单中的购买数量。 | 商品信息 |
| 单价(price) | 每种商品的单价 | 商品信息 |
| 国家(country) | 交易地点 | 订单信息 |
数据集有7个字段,522,064条记录,共38.7mb。
2.1.2 购物篮分析(mba)与关联规则挖掘(association rule mining)的应用
(1)识别频繁项集:
支持度(support):衡量某个商品组合在所有订单中出现的频率。高支持度意味着该商品组合在销售中较为常见。例如,如果“可乐+薯片”组合的支持度为10%,则意味着在所有订单中,有10%的订单同时包含了这两种商品。
(2)提取关联规则:
置信度(confidence):衡量在购买了商品a的条件下,同时购买商品b的概率。高置信度表示商品之间的关联性强。
提升度(lift):衡量商品a的购买对商品b购买的影响程度。提升度大于1表示商品a的购买对商品b的购买有正向影响。例如,如果购买可乐的顾客中有40%也购买了薯片,而薯片在所有订单中的支持度为10%,则“可乐→薯片”的置信度为40%,提升度为4(因为40%/10%=4),表示购买可乐对购买薯片有很强的正向影响。
(3)应用分析结果:
交叉销售和捆绑销售:根据分析出的关联规则,商家可以设计交叉销售策略,将经常一起购买的商品放在相邻的货架上,或进行捆绑销售以提高销售额。
库存管理和促销策略:了解哪些商品组合更受欢迎,有助于商家优化库存管理和制定更有效的促销策略。
个性化推荐:在电子商务平台上,可以根据用户的购买历史和行为,利用关联规则为其推荐可能感兴趣的商品。
2.1.3 数据集上传
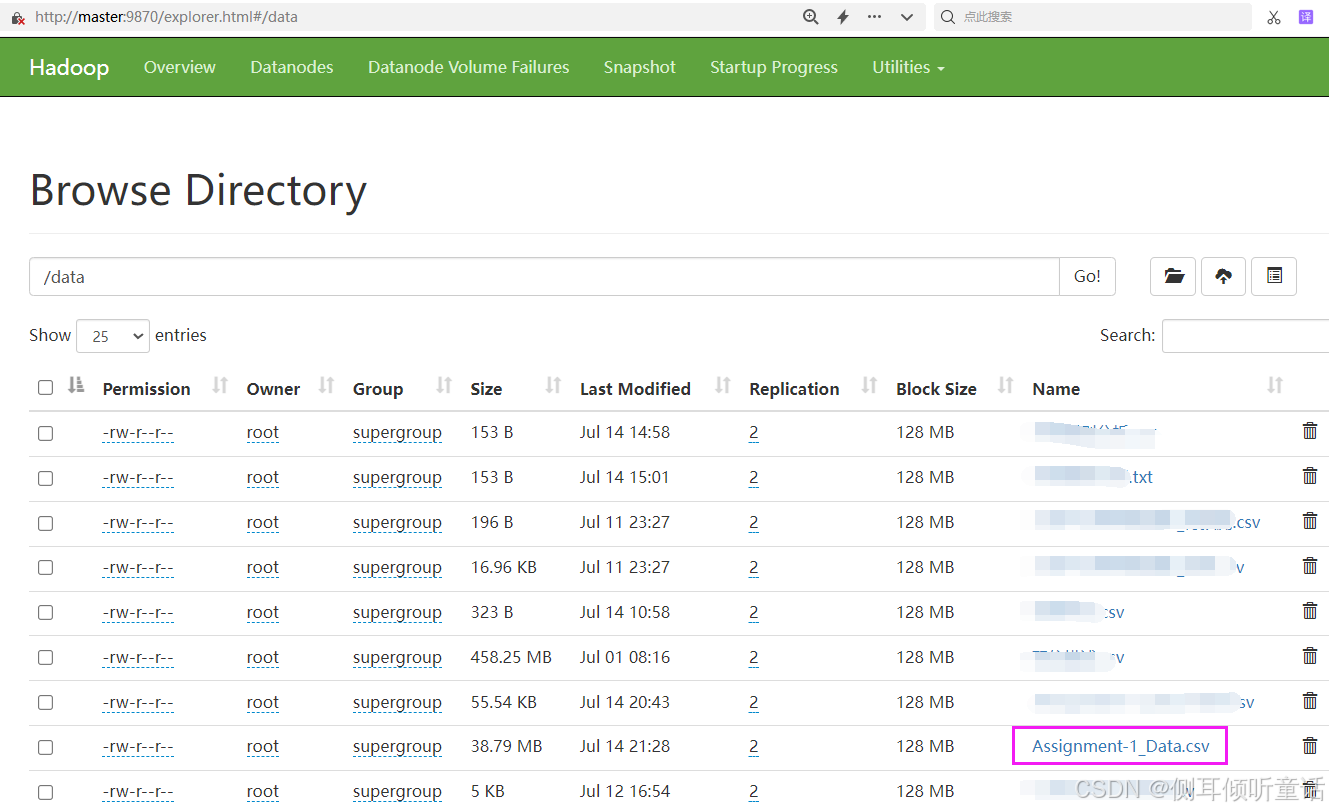
先启动hadoop集群和spark集群,再将数据集assignment-1_data.csv上传到hadoop分布式存储系统hdfs的目录/data/下,如下图所示:
2.2 数据导入,数据预处理
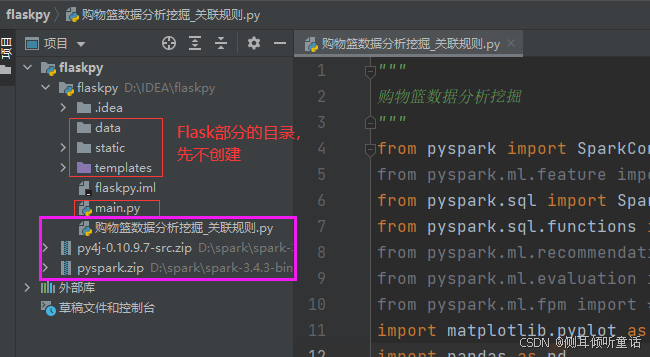
打开intellij idea,新建项目flaskpy,再新建python文件:购物篮数据分析挖掘_关联规则.py,以及其他文件夹(flask部分再详细说明),项目结构如图所示。
打开python文件:购物篮数据分析挖掘_关联规则.py。
数据导入:先导入数据集,再做数据预处理。
数据预处理:主要是日期(date)列拆分转换为年(year)、月(month)、日(day)、星期(dayofweek)、小时(hour)、分钟(minute)列,为后面更深、更细的数据分析和挖掘做准备;删除负值的记录、填充缺失值并删除那些非商品的记录。
from pyspark import sparkconf
from pyspark.ml.feature import stringindexer
from pyspark.sql import sparksession
from pyspark.sql.functions import *
from pyspark.ml.recommendation import als
from pyspark.ml.evaluation import regressionevaluator
from pyspark.ml.fpm import *
import matplotlib.pyplot as plt
import pandas as pd
from pyspark.sql.types import structfield, integertype
plt.rcparams['font.sans-serif'] = ['simhei'] # 指定默认字体为simhei显示中文
plt.rcparams['axes.unicode_minus'] = false # 解决保存图像时负号'-'显示为方块的问题
# 创建一个spark配置对象,用于设置spark作业的配置项
conf = sparkconf().setappname("购物篮分析") \
.set("spark.sql.legacy.timeparserpolicy", "legacy") \
.setmaster('spark://192.168.126.10:7077') # spark集群的master节点的地址和端口
sc = sparkcontext.getorcreate(conf)
spark = sparksession(sc)
# -------------一、数据导入与数据预处理-----------------------
# ------------(一)数据导入--------------------
filename = "assignment-1_data.csv"
data = spark.read.csv('hdfs://192.168.126.10:9000/data/' + filename, header=true, inferschema=true) #inferschema=true表示自动推断每列的数据类型
data.show(10, false) # 显示数据的前10行,并设置false来避免截断过长的列值
data.printschema() # 打印数据的模式(schema),即各列的名称和数据类型
# ------------(二) 数据预处理--------------
# ----------1 数据转换------------
data = data.withcolumn('timestamp', to_timestamp('date', 'yyyy/mm/dd hh:mm')) # 将'date'列的数据类型从字符串转换为时间戳类型,并添加列timestamp
data.show(5)
print("数据集记录数:", data.count())
# 接下来,基于新创建的'timestamp'列,提取并添加年、月、日、星期几、小时和分钟等字段
data = data.withcolumn('year', year('timestamp')) \
.withcolumn('month', month('timestamp')) \
.withcolumn("day", dayofmonth("timestamp")) \
.withcolumn("dayofweek", dayofweek("timestamp")) \
.withcolumn("hour", hour("timestamp")) \
.withcolumn("minute", minute("timestamp"))
data.show(5)
# -----2 删除负值的记录、填充缺失值并删除那些非商品的记录-------------
data = data.where((data['quantity'] > 0) & (data['price'] > 0)) # 删除商品数量和价格为负数的记录
print(data.count())
data = data.withcolumn("total_price", col("quantity") * col("price")) # 增加一列商品总价total_price
data_null_agg = data.agg(*[sum(when(isnull(c), 1)).alias(c) for c in data.columns]) # 检查并查看每列的空值总数
data_null_agg.show() # 发现 customerid 有十几万个空值
data = data.fillna('99999', 'customerid') # 客户号customerid 空值填充99999
data = data.where(
~(data['itemname'].isin(['postage', 'dotcom postage', 'adjust bad debt', 'manual']))
) # 删除非商品的那些item
data.show(5)
2.3 数据探索
2.3.1 总体销售情况
从订单量(no_of_trans)、成交量(quantity)与成交额(total_price)三个维度,分别从多个角度进行数据分析与可视化。数据可视化不是spark的强项,这里仅用于程序测试,程序最终提交集群运行时,可以将数据可视化部分放在flask部分,使用pyechart将多张图片做成web端可视化大屏,方便用户查看。
编程思路:
(1)总体交易分析(data_ttl_trans):按订单号(billno)分组,计算各组的成交量(quantity)和成交额(total_price)。然后将计算结果存储到mysql,再用pyecharts绘图。同时为了测试需要,将计算结果(pyspark dataframe格式)转换为 pandas dataframe格式,用于测试程序的可视化绘图。
(2)总体商品分析(data_ttl_item):按商品名称(itemname)分组,计算各组的成交量(quantity)和成交额(total_price)。
(3)总体时间分析(按年和月)(data_ttl_time):按年(year)、月(month)分组,计算各组的成交量(quantity)和成交额(total_price)。
(4)总体星期几分析(data_ttl_weekday):按星期(dayofweek)分组,计算各组的成交量(quantity)和成交额(total_price)。
(5)总体国家分析(data_ttl_country):按国家(country)分组,计算各组的成交量(quantity)和成交额(total_price)。
(6)总体国家时间分析(按国家、年和月)(data_ttl_country_time):按国家(country)、年(year)、月(month)分组,计算各组的成交量(quantity)和成交额(total_price)。
最后将6个分组计算后的结果存储到mysql,同时将其转换为pandas的dataframe,但是pandas的dataframe的数据运算只能在driver节点进行,会降低整个spark集群性能,因此只适合处理小型数据集。而pyspark的data frame的数据是分布式集群计算,适合处理中大规模数据集。程序代码如下:
# ----------------二、探索性分析--------------------
# ------(一)总体销售情况-----
# 从订单量(no_of_trans)、成交量(quantity)与成交额(total_price)三个维度,分别从多个角度进行数据可视化与分析
# 1.总体交易分析
data_ttl_trans = data.groupby("billno").agg(
sum("quantity").alias("quantity"),
sum("total_price").alias("total_price"))
data_ttl_trans_copy = data_ttl_trans # 用于存储到mysql
data_ttl_trans = data_ttl_trans.topandas() # 如果需要pandas dataframe,则转换为pandas
print("\n总体交易分析:\n", data_ttl_trans)
# 2.总体商品分析
data_ttl_item = data.groupby("itemname").agg(
sum("quantity").alias("quantity"),
sum("total_price").alias("total_price"))
data_ttl_item_copy = data_ttl_item
data_ttl_item = data_ttl_item.topandas() # 如果需要pandas dataframe,则转换为pandas
print("\n总体商品分析:\n", data_ttl_item)
# 3.总体时间分析(按年和月)
data_ttl_time = data.groupby(["year", "month"]).agg(
sum("quantity").alias("quantity"),
sum("total_price").alias("total_price"))
data_ttl_time_copy = data_ttl_time
data_ttl_time = data_ttl_time.topandas() # 如果需要pandas dataframe,则转换为pandas
print("\n总体时间分析(按年和月):\n", data_ttl_time)
# 4.总体星期几分析
data_ttl_weekday = data.groupby("dayofweek").agg(
sum("quantity").alias("quantity"),
sum("total_price").alias("total_price"))
data_ttl_weekday_copy = data_ttl_weekday
data_ttl_weekday = data_ttl_weekday.topandas() # 如果需要pandas dataframe,则转换为pandas
print("\n总体星期几分析:\n", data_ttl_weekday)
# 5.总体国家分析
data_ttl_country = data.groupby("country").agg(
sum("quantity").alias("quantity"),
sum("total_price").alias("total_price"))
data_ttl_country_copy = data_ttl_country
data_ttl_country = data_ttl_country.topandas() # 如果需要pandas dataframe,则转换为pandas
print("\n总体国家分析:\n", data_ttl_country)
# 6.总体国家时间分析(按国家、年和月)
data_ttl_country_time = data.groupby(["country", "year", "month"]).agg(
sum("quantity").alias("quantity"),
sum("total_price").alias("total_price"))
data_ttl_country_time_copy = data_ttl_country_time
data_ttl_country_time = data_ttl_country_time.topandas() # 如果需要pandas dataframe,则转换为pandas
print("\n总体国家时间分析(按国家、年和月):\n", data_ttl_country_time)
# ----------------将数据存储到linux的mysql中,为可视化大屏做数据准备-----------------------
# 定义mysql数据库的连接参数:数据库为test,用户名root,密码123456,驱动com.mysql.jdbc.driver
url = "jdbc:mysql://192.168.126.10:3306/test"
properties = {
"user": "root",
"password": "123456",
"driver": "com.mysql.jdbc.driver"}
# 写数据到mysql的test数据库的movie表,无需预先在mysql创建表。自动在mysql创建movie表
data_ttl_trans_copy.coalesce(1).write.format('jdbc') \
.option('url', url) \
.option('dbtable', 'data_ttl_trans') \
.option('user', properties['user']) \
.option('password', properties['password']) \
.option('driver', properties['driver']) \
.option('mode', 'overwrite') \
# .save() # 第一次建表时使用.save()。append为追加数据模式,overwrite为覆盖数据模式
print('spark将数据写入mysql完成。')
# ---------封装将pyspark的dataframe写入mysql数据库的函数,方便调用--------------------
from pyspark.sql import dataframe
import pymysql
def write_to_mysql(df: dataframe, url: str, properties: dict, table_name: str):
"""
将pyspark的dataframe写入mysql数据库的指定表。检查表是否存在,存在则先删除表。
参数:
- df: 要写入的dataframe。
- url: mysql数据库的jdbc url。
- properties: 包含数据库连接信息的字典(user, password, driver)。
- table_name: 要写入的mysql表名。
"""
conn = pymysql.connect(host=url.split('/')[2].split(':')[0],
port=int(url.split('/')[2].split(':')[1].split('/')[0]),
user=properties['user'],
password=properties['password'],
database=url.split('/')[-1],
charset='utf8mb4',
cursorclass=pymysql.cursors.dictcursor)
try:
with conn.cursor() as cursor:
# 检查表是否存在
cursor.execute(f"show tables like '{table_name}'")
if cursor.fetchone():
# 如果表存在,则删除它
cursor.execute(f"drop table if exists {table_name}")
conn.commit()
print(f"删除表:{table_name}")
finally:
conn.close()
# 写入数据到mysql
df.coalesce(1).write.format('jdbc') \
.option('url', url) \
.option('dbtable', table_name) \
.option('user', properties['user']) \
.option('password', properties['password']) \
.option('driver', properties['driver']) \
.option('mode', 'append') \
.save()
print(f'spark将数据写入mysql的{table_name}表完成。')
# --------封装函数完成。-------
# 使用示例
url = "jdbc:mysql://192.168.126.10:3306/test" # test为mysql的数据库
properties = {
"user": "root", # mysql用户名
"password": "123456", # mysql密码
"driver": "com.mysql.jdbc.driver" }# mysql驱动
# 将相关的数据分析结果存储到linux的mysql,用于windows端数据可视化。
write_to_mysql(data_ttl_item_copy, url, properties, 'data_ttl_item') # 2.总体商品分析
write_to_mysql(data_ttl_time_copy, url, properties, 'data_ttl_time') # 3.总体时间分析(按年和月)
write_to_mysql(data_ttl_weekday_copy, url, properties, 'data_ttl_weekday') # 4.总体星期几分析
write_to_mysql(data_ttl_country_copy, url, properties, 'data_ttl_country') # 5.总体国家分析
write_to_mysql(data_ttl_country_time_copy, url, properties, 'data_ttl_country_time') # 6.总体国家时间分析(按国家、年和月)
# 后面其他pyspark dataframe数据需要写入mysql的,直接调用函数即可。pandas dataframe数据不能调用该函数。
在idea的调试模式下,可以查看pandas的dataframe数据。
2.3.2 异常值检测与处理
异常值检测与处理:用箱线图对分组后的数据做异常值检测,删除异常值。
使用np.percentile函数计算特定百分位数,箱线图的异常值上界和下界通常定义为q3 + 1.5iqr(上界)和q1 - 1.5iqr(下界),其中q1是第一四分位数(25%分位数),q3是第三四分位数(75%分位数),iqr = q3 - q1是四分位距。
代码如下:
# -------------------------------------(二)异常值检测及处理-------------------------------------------------------------------
# data_ttl_trans["quantity"].plot(kind='boxplot')
plt.boxplot(data_ttl_trans["quantity"]) # 绘制总体交易成交量的箱线图,查看异常值
plt.show()
plt.boxplot(data_ttl_trans["total_price"]) # 绘制总体交易成交额的箱线图,查看异常值
plt.show()
# 销售数据极不平衡,有些单子里的销售额或销售量远远超过正常标准,因此在作分布图时,将箱线图中的离群点去除。
"""
np.percentile函数用于计算特定百分位数,而箱线图的异常值上界和下界通常定义为q3 + 1.5*iqr(上界)和q1 - 1.5*iqr(下界),
其中q1是第一四分位数(25%分位数),q3是第三四分位数(75%分位数),iqr = q3 - q1是四分位距。
"""
# 计算四分位数
q1_quantity = np.percentile(data_ttl_trans["quantity"], 25) # 25%分位数
q3_quantity = np.percentile(data_ttl_trans["quantity"], 75) # 75%分位数
iqr_quantity = q3_quantity - q1_quantity # 四分位距
# 计算箱线图异常值上界(注意:这里只计算了上界,下界可以类似计算)
upper_bound_quantity = q3_quantity + 1.5 * iqr_quantity
print("成交量箱线图上界:", upper_bound_quantity)
# 对total_price做同样的计算
q1_total_price = np.percentile(data_ttl_trans["total_price"], 25)
q3_total_price = np.percentile(data_ttl_trans["total_price"], 75)
iqr_total_price = q3_total_price - q1_total_price
upper_bound_total_price = q3_total_price + 1.5 * iqr_total_price
print("成交额箱线图上界:", upper_bound_total_price)
# 使用histplot绘制分布图
# 注意:这里假设了某个阈值来限制绘图的数据范围,但这通常不是必需的,除非您想要专注于数据的某个子集
plt.hist(data=data_ttl_trans[data_ttl_trans["quantity"] <= upper_bound_quantity], x="quantity")
plt.title("distribution of quantity (limited)")
plt.show()
plt.hist(data=data_ttl_trans[data_ttl_trans["total_price"] <= upper_bound_total_price], x="total_price")
plt.title("distribution of total price (limited)")
plt.show()
# 从分布图上分布看依旧明显右偏趋势,表明了有极少数的订单拥有极大的销售量与销售额,远超正常订单的水平。
# 总体商品成交量异常值检测 及分布图
plt.boxplot(data_ttl_item['quantity']) # 总体商品成交量的箱线图
plt.show()
q1_quantity = np.percentile(data_ttl_item["quantity"], 25) # 25%分位数
q3_quantity = np.percentile(data_ttl_item["quantity"], 75) # 75%分位数
iqr_quantity = q3_quantity - q1_quantity # 四分位距
upper_bound_quantity = q3_quantity + 1.5 * iqr_quantity # 计算箱线图异常值上界
print("成交量箱线图上界:", upper_bound_quantity)
plt.hist(data=data_ttl_item[data_ttl_item["quantity"] <= upper_bound_quantity], x="quantity")
plt.title("总体商品成交量的分布图")
plt.show()
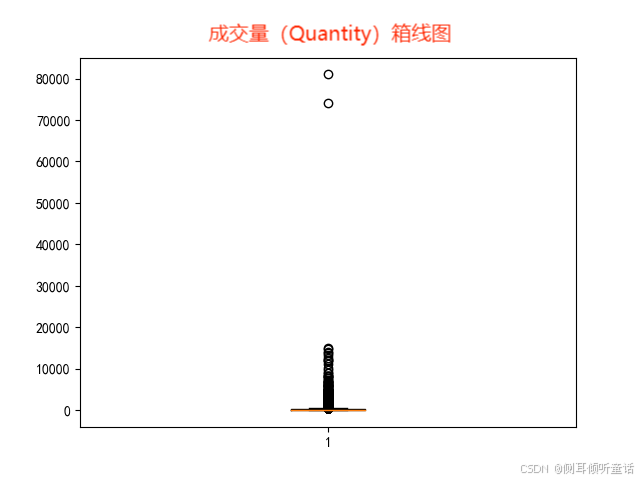
成交量(quantity)箱线图如下:
成交额(total_price)箱线图如下:
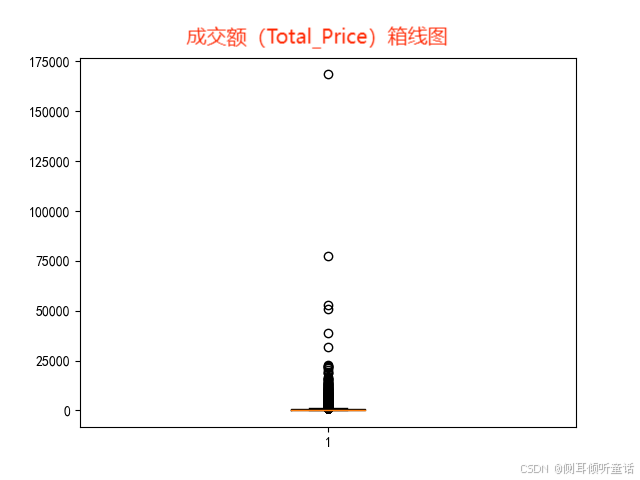
上两图所示,销售数据极不平衡,有些单子里的交易量或交易额远远超过正常标准,因此在作分布图时,将箱线图中的离群点去除。
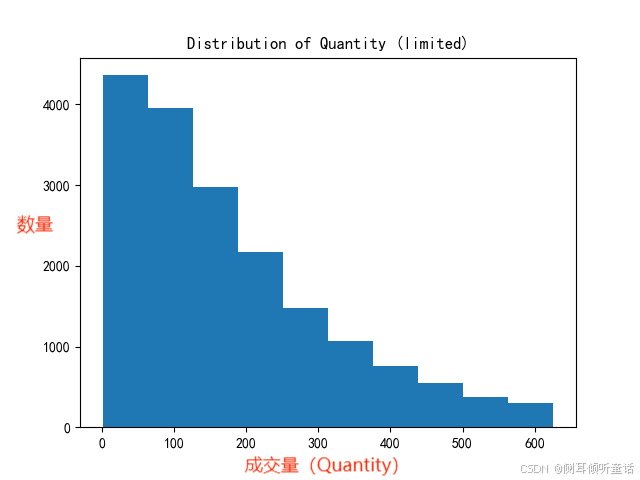
剔除异常值后的成交量(quantity)分布图如下:
剔除异常值后的成交额(total_price)分布图如下:
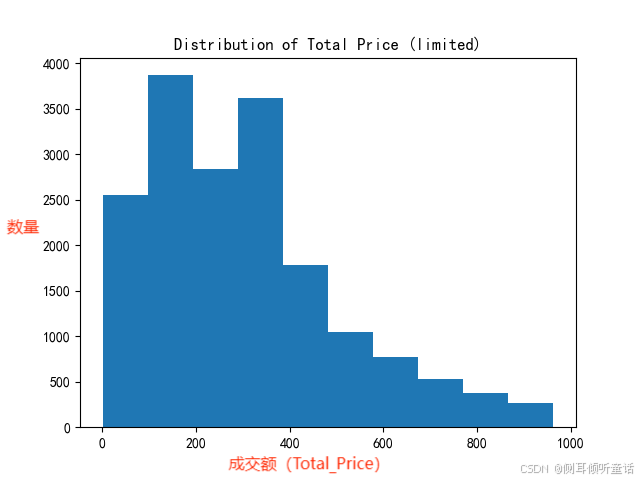
从分布图上看,分布依旧明显右偏趋势,表明了有极少数的订单拥有极大的销售量与销售额,远超正常订单的水平。
此处并没有删除数据的异常值。实际上,异常值检测与处理,应在数据分组前进行,也就是在“2.2 数据导入,数据预处理”部分,对原始数据做异常值检测与处理。后续将对这一点进行改进。
2.3.3 总体销售情况的数据可视化
数据可视化部分可以放在windows端的flask部分,用pyecharts绘图,最后渲染到web页面,做成一个可视化大屏。
总体时间分析(按年和月)(data_ttl_time),可视化绘图如下:
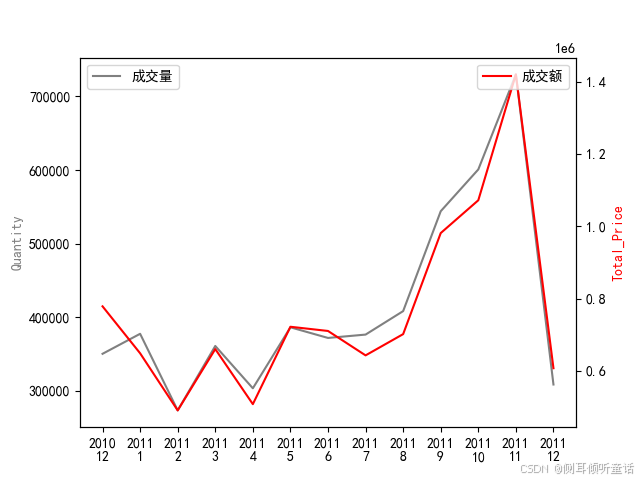
可以看出,2011年12月,成交量和成交额都达到了最大值。
总体星期几分析(data_ttl_weekday),可视化绘图如下:
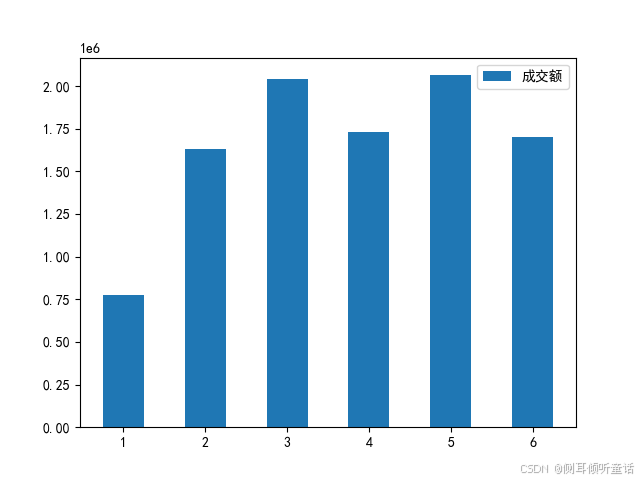
上图可以看出,周一的成交额较少,周二至周六的成交额起伏较为平缓,周日的成交额的数据缺失。
总体国家分析(data_ttl_country),绘制成交额排名前5的国家和剩余国家成交额的饼图如下:
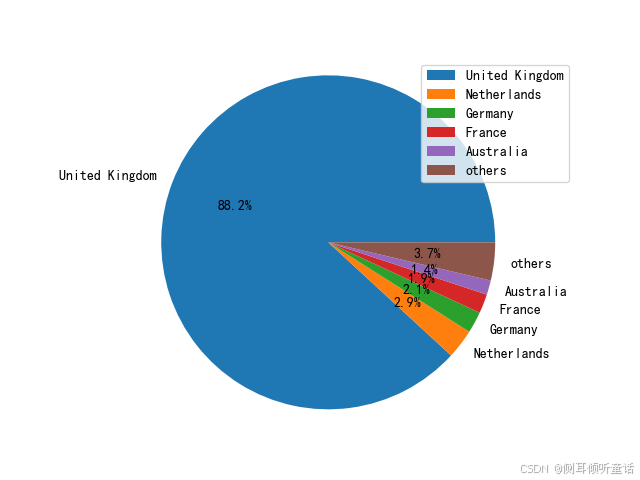
总体上来看,总销售额(成交额)的绝大部分都是来自于英国销售,占比高达88.2%,紧随其后的是新西兰、德国、法国和澳大利亚,占总销售额的比例很小。
总体国家分析(data_ttl_country)中,比较每年每月英国成交额和其他国家成交额总和,绘制的堆叠柱形图如下:
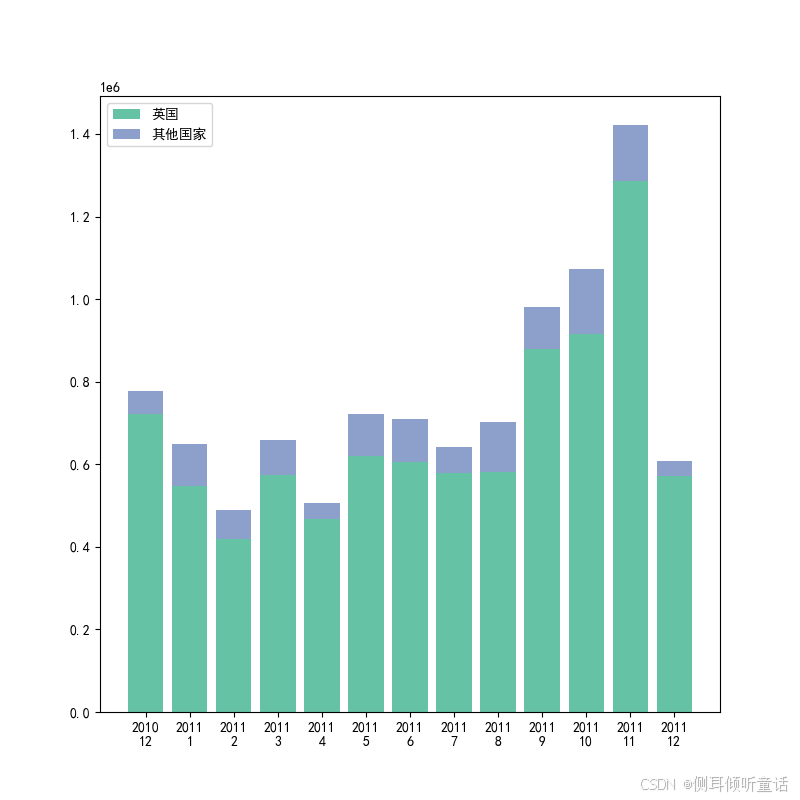
由上图可以看出,从时间线上来看,每个月都是英国销售额占主体。
具体的代码如下:
# ----------------------------------(三)数据可视化(这部分可以放在windows端,用pyecharts绘图)-------------------------
# ------------------1.data_ttl_time总体时间分析(按年和月)可视化-----------------------
data_ttl_time = data_ttl_time.sort_values(['year', 'month']) # 按年和月排序
data_ttl_time.index = [str(i) + "\n" + str(j) for i, j in zip(data_ttl_time["year"], data_ttl_time["month"])] # 重建索引
fig, ax1 = plt.subplots()
ax1.plot(data_ttl_time["quantity"], color='gray', label="成交量")
ax1.set_ylabel("quantity", color="gray")
plt.legend(loc='upper left')
ax2 = ax1.twinx() # 创建第二个y轴
ax2.plot(data_ttl_time["total_price"], color="red", label="成交额")
ax2.set_ylabel("total_price", color="red")
plt.legend(loc='upper right')
plt.show() # 从时间轴上来看,销售额有一个明显的上升趋势,到了11月有一个明显的高峰,而到12月则有所回落。
# --------------------------2.总体星期几分析 可视化-----------------------------
plt.bar(data_ttl_weekday["dayofweek"],
data_ttl_weekday["total_price"],
width=0.5, label="成交额")
plt.legend()
plt.show()
# -----------------------------3.总体国家分析可视化----------------------------
data_ttl_country.set_index("country", inplace=true) # 设置索引为 country 列
top_five = data_ttl_country["total_price"].sort_values(ascending=false)[:5] # 排序 total_price 并取前五个
others = data_ttl_country["total_price"].sort_values(ascending=false)[5:].sum() # 计算其他国家的总和
pie_data = top_five.copy()
pie_data = pie_data.append(pd.series([others], index=["others"])) # 创建一个新的 series 来包含前五个国家和“其他”的总和
# 绘制饼图
plt.pie(pie_data, labels=pie_data.index, autopct='%1.1f%%')
plt.axis('equal') # 确保饼图是圆形
plt.legend(loc="upper right")
plt.show()
# -----------------4.data_ttl_country_time总体国家时间分析(按国家、年和月)可视化-------------
data_ttl_country_time["isunitedkingdom"] = ["uk" if i == "united kingdom" else "not uk" for i in
data_ttl_country_time["country"]] # 创建isunitedkingdom列
data_ttl_country_time_isuk = data_ttl_country_time.groupby(["isunitedkingdom", "year", "month"])[
"total_price"].sum().reset_index() # 分组并计算成交额
data_ttl_country_time_isuk.index = [str(i) + "\n" + str(j) for i, j in
zip(data_ttl_country_time_isuk["year"],
data_ttl_country_time_isuk["month"])] # 重建索引
uk = data_ttl_country_time_isuk[data_ttl_country_time_isuk["isunitedkingdom"] == "uk"] # 英国uk的每年每月成交额
nuk = data_ttl_country_time_isuk[data_ttl_country_time_isuk["isunitedkingdom"] == "not uk"] # 非英国uk的每年每月成交额
plt.figure(figsize=(8, 8))
plt.bar(uk.index, uk["total_price"], color="#66c2a5", label="英国")
plt.bar(nuk.index, nuk["total_price"], bottom=uk["total_price"], color="#8da0cb", label="其他国家")
plt.legend()
plt.show() # 总体上来看,总销售额的绝大部分都是来自于英国销售,而从时间线上来看,每个月都是英国销售额占主体。
2.3.4 英国是否存在季节性商品(按季度分组)
将2011年4个季度的交易量、成交量以及成交额分别汇总并排序,看看有没有哪个商品在各个季度的排名有明显的差距。也就是分别在交易量、成交量以及成交额找出季节性波动最大的一个商品(即:有的月份量大,有的月份量小),据此可以判断是不是季节性商品。
“no_of_trans”(不同购物小票的数量)、“quantity”(成交量)和 “total_price”(成交额)。
尽量避免在pandas和spark之间频繁转换,因为pandas dataframe的操作通常不适合大规模数据集。尽量在spark环境中完成所有的数据分析与处理。
编程思路如下:
1.选取英国2011年的数据,将1-12月转换为1-4季度。
2.确定每季度每件商品的交易订单量、成交量、成交额排名,给每件商品标注排名并添加新列。
3.选取四季度交易量、成交量、成交额3个维度排名的商品,四季度的前10商品名去重后按照维度放在一起。此时,存放的每个维度的商品数量(集合)有可能大于10件。
4.是否是季节性商品,也就是分析四季度排名前10的商品集合,分别在1、2、3、4季度的排名,然后计算四季度排名差,保存最大排名差。
如某商品paper chain kit vintage christmas (复古圣诞纸链套装)的交易量no_of_trans在第1、2、3、4季度的排名分别为1669、1734、110、4,值(交易量)分别为:11、9、143、509,因此该商品的排名差为:1734-4=1730。排名差越大,说明是季节性商品的可能性越大。
5.对交易订单量、销售量、销售额3个维度的商品排名差进行降序排序,选取排名差最大的3个商品。
6.分别绘制交易订单量、销售量、销售额3个维度排名差最大的3个商品四个季度的对应值的饼图。
代码如下:
# -------------------(四)英国是否存在季节性商品(按季度)-------------------------------
"""
将2011年的4个季度的成交量、销售量以及销售额分别汇总并排序,看看有没有哪个商品在各个季度的排名有明显的差距。
也就是分别在成交量、销售量以及销售额找出季节性波动最大的一个商品(有的月份量大,有的月份量小),据此可以判断它们是季节性商品。
"no_of_trans"(不同账单号的数量)、"quantity"(每件商品的销售量)和 "total_price"(每件商品的销售额)。
尽量避免在pandas和spark之间频繁转换,因为pandas dataframe的操作通常不适合大规模数据集。如果可能,尽量在spark环境中完成所有处理。
编程思路如下:
1.选取英国2011年的数据,将1-12月转换为1-4季度。
2.确定每季度每件商品的交易订单量、销售量、销售额排名,并添加列给每件商品标注排名。
3.选取四季度交易订单量、销售量、销售额3个维度排名的商品,四季度前10商品名去重后按照维度一起存放。此时,存放的每个维度的商品数量(集合)有可能大于10件。
4.是否存在季节性商品,也就是分析四季度排名前10的商品集合,分别在1、2、3、4季度的排名,然后计算四季度排名差,保存最大排名差。
如某商品paper chain kit vintage christmas (复古圣诞纸链套装)的交易量no_of_trans在第1、2、3、4季度的排名分别为1669、1734、110、4,
值(交易量)分别为:11、9、143、509,因此该商品的排名差为:1734-4=1730。排名差越大,说明是季节性商品的可能性越大。
5.对交易订单量、销售量、销售额3个维度的商品排名差进行降序排序,选取排名差最大的3个商品。
6.分别绘制交易订单量、销售量、销售额3个维度排名差最大的3个商品四个季度的对应值的饼图。
"""
# 1.选取英国2011年的数据,将1-12月转换为1-4季度。
df_uk = data.filter((col("country") == "united kingdom") & (col("year") == 2011)) # 只选取uk英国2011年的全年数据
df_uk = df_uk.withcolumn("season", floor((col("month") - 1) / 3) + 1) # 将1-12月转换为相应的1-4季度,新增一列:季度
# 分组与聚合:按季度、商品名称分组,统计季度的成交量、销售量、销售额
df_uk_seasonal = df_uk.groupby(["season", "itemname"]).agg(
countdistinct("billno").alias("no_of_trans"), # 成交量
sum("quantity").alias("quantity"), # 销售量
sum("total_price").alias("total_price") # 销售额
)
print("\n按季度、商品名称分组,统计季度的成交量、销售量、销售额:\n")
df_uk_seasonal.orderby('itemname').show(20, false)
print('df_uk_seasonal的行数:', df_uk_seasonal.count())
df_uk_seasonal = df_uk_seasonal.topandas()
# 排序
# 2.确定每季度每件商品的交易订单量、销售量、销售额排名,并添加列给每件商品标注排名。
def rank_seasonal(df, season="all"):
groupby_cols = ["itemname"]
if season != "all":
groupby_cols.append("season")
df = df[df["season"] == int(season)] # 提取某一个季节的数据
df = df.groupby(groupby_cols).sum(
["no_of_trans", "quantity", "total_price"]) # 按商品名分组,再按季节,计算no_of_trans,quantity,total_price的总和
for col in ["no_of_trans", "quantity", "total_price"]:
df[col + "_rank"] = df[col].rank(ascending=false) # 确定每件商品的交易数,销售量,销售额的排名,并添加相应的排名列
return df
df_uk_all = rank_seasonal(df_uk_seasonal)
df_uk_first = rank_seasonal(df_uk_seasonal, "1")
df_uk_second = rank_seasonal(df_uk_seasonal, "2")
df_uk_third = rank_seasonal(df_uk_seasonal, "3")
df_uk_fourth = rank_seasonal(df_uk_seasonal, "4")
print(df_uk_all)
print(df_uk_fourth)
"""
在apache spark的pyspark模块中,window函数是一个非常强大的工具,它允许你在保持数据集为分布式的同时,执行复杂的分组聚合操作,
这些操作类似于sql中的窗口函数(window functions)或分析函数(analytic functions)。window函数不是直接对数据集进行分区,
而是定义了一个“窗口”或“框架”,在这个窗口内可以对数据进行聚合或排序等操作,而不需要将数据实际地分组到一起。
partitionby:分组,
"""
# 全年交易量、销售量、销售额排名
# 3.选取四季度交易订单量、销售量、销售额3个维度排名的商品,四季度前10商品名去重后按照维度一起存放。此时,存放的每个维度的商品数量(集合)有可能大于10件。
dfs = [df_uk_all, df_uk_first, df_uk_second, df_uk_third, df_uk_fourth]
item_set_no_of_trans = set() # 如果 dataframe 中的有关列 包含重复值,并且这些值在排名前十的列表中,则它们在集合中只会出现一次。这是集合(set)的特性,它不允许重复元素。
item_set_quantity = set()
item_set_total_price = set()
for df in dfs: # 遍历全年及四个季度的交易量、销售量、销售额排行榜,提取排行前十的商品名字
df = df.copy().reset_index()
itemname_top_trans = df[df["no_of_trans_rank"] <= 10]["itemname"] # 交易量排名前十的商品名字
itemname_top_qty = df[df["quantity_rank"] <= 10]["itemname"] # 销售量排名前十的商品名字
itemname_top_ttl_price = df[df["total_price_rank"] <= 10]["itemname"] # 销售额排名前十的商品名字
for i in itemname_top_trans:
item_set_no_of_trans.add(i)
for i in itemname_top_qty:
item_set_quantity.add(i)
for i in itemname_top_ttl_price:
item_set_total_price.add(i)
print("全年及四个季度排名前10的商品的集合(商品不重复):\n")
pd.set_option('display.max_columns', none) # 显示所有列
print(item_set_no_of_trans) # 全年及四季度交易订单量排行前十的商品的集合
print(item_set_quantity) # 全年及四季度销售量排行前十的商品的集合
print(item_set_total_price) # 全年及四季度销售额排行前十的商品的集合
## 每个季度的是否有所不同?
"""
4.是否存在季节性商品,也就是分析四季度排名前10的商品集合,分别在1、2、3、4季度的排名,然后计算四季度排名差,保存最大排名差。
如某商品paper chain kit vintage christmas (复古圣诞纸链套装)的交易量no_of_trans在第1、2、3、4季度的排名分别为1669、1734、110、4,
值(交易量)分别为:11、9、143、509,因此该商品的排名差为:1734-4=1730。排名差越大,说明是季节性商品的可能性越大。
"""
rank_df = {"dimension": [], "item": [], "rank": [], "value": [], "season": [],
"range": []} # pd.dataframe(columns=["dimension","item","rank","value"])
for dim, itemset in [("no_of_trans", item_set_no_of_trans),
("quantity", item_set_quantity),
("total_price", item_set_total_price)]: # 3个维度dim:no_of_trans,quantity,total_price
for i in list(itemset): # 遍历 全年及四季度排名前十的商品名,逐一取出商品名给i
min_rank = 9999
max_rank = -1
for j, df in enumerate(dfs): # 遍历全年及四季度交易订单量,销售量,销售额的排名数据,j是dfs的索引。
df = df.reset_index() # 重置索引,索引号为原来的自然编号
if j == 0: # j=0,表示取出的是全年订单量,销售量,销售额的排名数据
rank_df["season"].append("all")
else:
rank_df["season"].append(df["season"].values[0])
sub_df = df[df["itemname"] == i] # 比对排名前十商品名,抽取该商品数据信息(包含3项排名信息)
if sub_df.shape[0] == 0:
curr_rank = 9999
curr_value = 0
else:
curr_rank = df[df["itemname"] == i][dim + "_rank"].values[0] # 该商品在该季度对应维度的排名
curr_value = df[df["itemname"] == i][dim].values[0] # 提取该商品对应维度的数据,如该商品交易量是多少。
min_rank = __builtins__.min(curr_rank,
min_rank) # 商品的当前排名curr_rank和最小排名min_rank比较,更新min_rank。使用python内置的min函数,而不是pyspark。
max_rank = __builtins__.max(curr_rank, max_rank) if curr_rank < 9999 else max_rank
rank_df["dimension"].append(dim) # 用字典为该商品创建相关信息,包括维度,商品名,排名,该商品在该维度的数量
rank_df["item"].append(i)
rank_df["rank"].append(curr_rank)
rank_df["value"].append(curr_value)
rank_df["range"] += [max_rank - min_rank] * 5 # 将该排名差放在该商品的全年及四季度的range列里面。每件商品出现5次,对应全年及四季度的数据
rank_df = pd.dataframe(rank_df) # 将字典转成pandas的dataframe
print(rank_df)
# “每个季度的量相差很多”的,但是本身很多的
"""
5.对交易订单量、销售量、销售额3个维度的商品排名差进行降序排序,选取排名差最大的3个商品。
6.分别绘制交易订单量、销售量、销售额3个维度排名差最大的3个商品四个季度的对应值的饼图。
"""
plt.figure(figsize=(20, 20))
dims = ["no_of_trans", "quantity", "total_price"]
for i, dim in enumerate(dims): # 遍历列表,取索引号和元素
tmp_df = rank_df[(rank_df["dimension"] == dim) & (rank_df["season"] != 'all')] # 取出对应维度的四季度数据,剔除全年(all)数据。
tmp_df["range_rank"] = tmp_df["range"].rank(ascending=false) # 对排名差 进行降序排序,并添加一列数据range_rank
tmp_df = tmp_df.sort_values("range_rank").reset_index(drop=true) # 重置索引,且不在新的dataframe中保留旧的索引作为一列
for j in range(3): # 提取每个维度的前j=3个商品,绘制每个季度对应维度(如no_of_trans交易量)数据的饼图。
tmp_df_rank = tmp_df.loc[4 * j:4 * (j + 1) - 1, :] # 分别提取前3个商品的4行数据(四季度)
this_item = list(set(tmp_df_rank["item"]))[0] # 从tmp_df_rank的"item"列中选取一个唯一的(不重复的)元素,集合set自动过滤重复值
plt.subplot(3, 3, i * 3 + j + 1)
plt.pie(tmp_df_rank["value"], labels=tmp_df_rank["season"]) # 绘制四季度相应维度的数据
plt.title(f"{dim}:{this_item}")
plt.show()
"""
#上图中的商品,是在全年的销售中名销售额/销售了/成交量列前茅的前3个商品,但是从饼图上来看,这些商品明显是会集中在某一个季度中畅销。
把颗粒度缩小到按月份来看,计算每月销售额占总销售额的比重(季节指数);并以此排序看看哪些商品的季节指数极差最大。
"""
选取排名差最大的前3个商品,计算交易量、成交量和成交额在四季度中所占的比例。绘制的饼图如下:
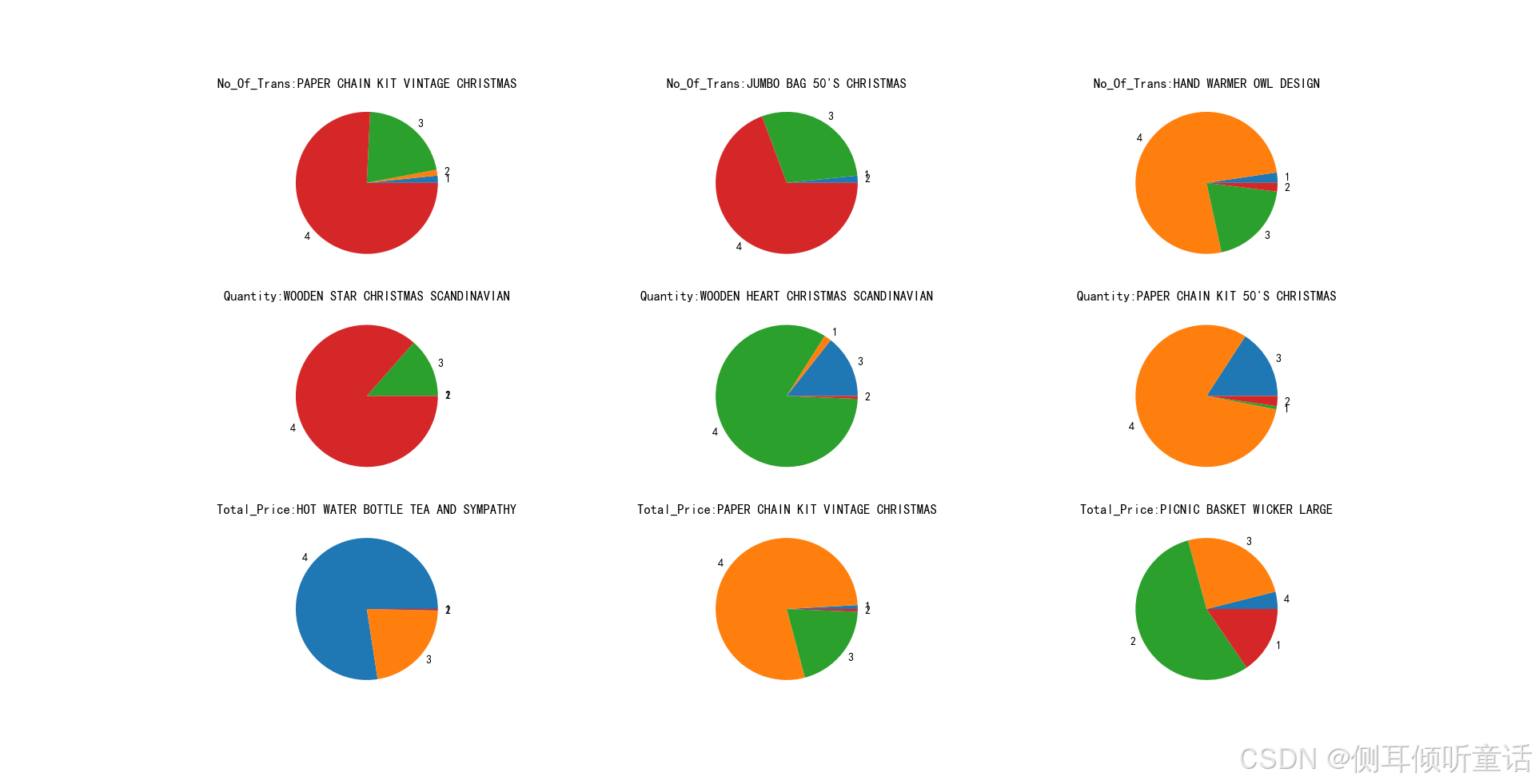
上图中,
第一行3个饼图,表示四个季度中成交量排名相差最大的前3个商品,在四个季度中的交易量占比。如商品“paper chain kit vintage christmas(复古圣诞纸链套装)”是季节性商品,在第4季度的交易量占比最大。
第二行的3个饼图,表示四个季度中成交量排名相差最大的前3个商品,在四个季度中的成交量占比。
第三行的3个饼图,表示四个季度中成交额排名相差最大的前3个商品,在四个季度中的成交额占比。
2.3.5 哪些商品的季节指数极差最大(按月判断)
上图中的商品,是按季度划分,交易量、成交量、成交额名列前茅的前3个商品,从饼图上来看,这些商品明显集中在某一个季度中畅销。如果按月分组,哪些商品季节指数极差最大?把数据分析颗粒度缩小到按月份分组,计算每月交易量、成交量、成交额/全年月平均交易量、成交量、成交额,即:季节指数,并以此排序看看哪些商品的季节指数极差最大。
代码如下:
# ------------(五)哪些商品的季节指数极差最大(按月判断)---------------------
# 把颗粒度缩小到按月份来看,计算每月交易量/全年月平均交易量的(季节指数);并以此排序看看哪些商品的季节指数极差最大。以此类推,再计算成交量、成交额的季节指数
from pyspark.sql import functions as f
df_uk_monthly = df_uk.groupby(["month", "itemname"]).agg(f.countdistinct(f.col("billno")).alias("no_of_trans"),
f.sum(f.col("quantity")).alias("quantity")
, f.sum(f.col("total_price")).alias(
"total_price")).topandas().reset_index(drop=true) # 每月每件商品的交易量、成交量、成交额总数
df_uk_fullyear = df_uk_monthly.groupby(["itemname"]).mean(
["no_of_trans", "quantity", "total_price"]).reset_index() # 每件商品交易量、成交量、成交额的全年月均值
df_uk_fullyear.rename(
columns={"no_of_trans": "fy_no_of_trans", "quantity": "fy_quantity", "total_price": "fy_total_price"}, inplace=true)
df_uk_monthly_season = pd.merge(df_uk_monthly, df_uk_fullyear, on=["itemname"], how='left')
df_uk_monthly_season["seasonal_index_no_of_trans"] = df_uk_monthly_season["no_of_trans"] / df_uk_monthly_season[
"fy_no_of_trans"]
df_uk_monthly_season["seasonal_index_quantity"] = df_uk_monthly_season["quantity"] / df_uk_monthly_season["fy_quantity"]
df_uk_monthly_season["seasonal_index_total_price"] = df_uk_monthly_season["total_price"] / df_uk_monthly_season[
"fy_total_price"] # 每月成交额/全年月平均成交额
# 算极差
# 每月交易量/全年月平均交易量(季节指数),看看哪些商品的季节指数极差最大。以此类推,再计算成交量、成交额的季节指数和极差
df_uk_season_max = df_uk_monthly_season.groupby("itemname").max(
["seasonal_index_no_of_trans", "seasonal_index_quantity", "seasonal_index_total_price"]).reset_index().rename(
columns={"seasonal_index_no_of_trans": "seasonal_index_no_of_trans_max",
"seasonal_index_quantity": "seasonal_index_quantity_max",
"seasonal_index_total_price": "seasonal_index_total_price_max"}) # 计算每样商品的交易量、成交量、成交额季节指数最大值。
df_uk_season_min = df_uk_monthly_season.groupby("itemname").min(
["seasonal_index_no_of_trans", "seasonal_index_quantity", "seasonal_index_total_price"]).reset_index().rename(
columns={"seasonal_index_no_of_trans": "seasonal_index_no_of_trans_min",
"seasonal_index_quantity": "seasonal_index_quantity_min",
"seasonal_index_total_price": "seasonal_index_total_price_min"}) # 每样商品的交易量、成交量、成交额,那个月的季节指数最小。
df_uk_season_ranges = pd.merge(df_uk_season_min, df_uk_season_max, on=["itemname"])
seasonal_index_cols = ["seasonal_index_no_of_trans", "seasonal_index_quantity", "seasonal_index_total_price"]
for col in seasonal_index_cols:
df_uk_season_ranges[col] = df_uk_season_ranges[col + "_max"] - df_uk_season_ranges[col + "_min"]
df_uk_season_ranges[col + "_rank"] = df_uk_season_ranges[col].rank(ascending=false)
df_uk_season_ranges = df_uk_season_ranges[
["itemname"] + [i for i in df_uk_season_ranges if "seasonal_index" in i]] # 选取itemname列和含seasonal_index的列。
# -------------月度极差可视化(每个维度排名前3的商品)-------------
# 提取月度极差排名前3的商品,绘制其1-12月相应维度数据的折线图
plt.figure(figsize=(15, 15))
for i, col in enumerate(["seasonal_index_no_of_trans", "seasonal_index_quantity", "seasonal_index_total_price"]):
seasonal_items = df_uk_season_ranges.sort_values(col + "_rank").reset_index().loc[:2,
"itemname"].tolist() # 选择相应维度的极差指数的前3名 商品
for j, item in enumerate(seasonal_items):
plt.subplot(3, 3, i * 3 + j + 1)
idxs = [k for k in df_uk_monthly.index if df_uk_monthly.loc[k, "itemname"] == item] # df_uk_monthly查找相应物品的索引
tmp_df = df_uk_monthly.loc[idxs, ["itemname", "month", col.replace("seasonal_index_","")]]
# 根据这些索引,从df_uk_monthly中选取对应的商品名称、月份和相应的交易量/销售量/销售额
tmp_df = tmp_df.pivot(index="month", columns="itemname",
values=col.replace("seasonal_index_", ""))
# 将tmp_df数据透视,以月份为行索引,商品名称为列索引,交易量/销售量/销售额为数据
plt.plot(tmp_df, marker='o')
plt.ylabel(col.replace("seasonal_index_", ""))
plt.title(item)
plt.subplots_adjust(wspace=0.2, hspace=0.2) # 调整子图间距。wspace=0.2,水平间距为 整图的20%,hspace=0.2,垂直方向
plt.show()
"""
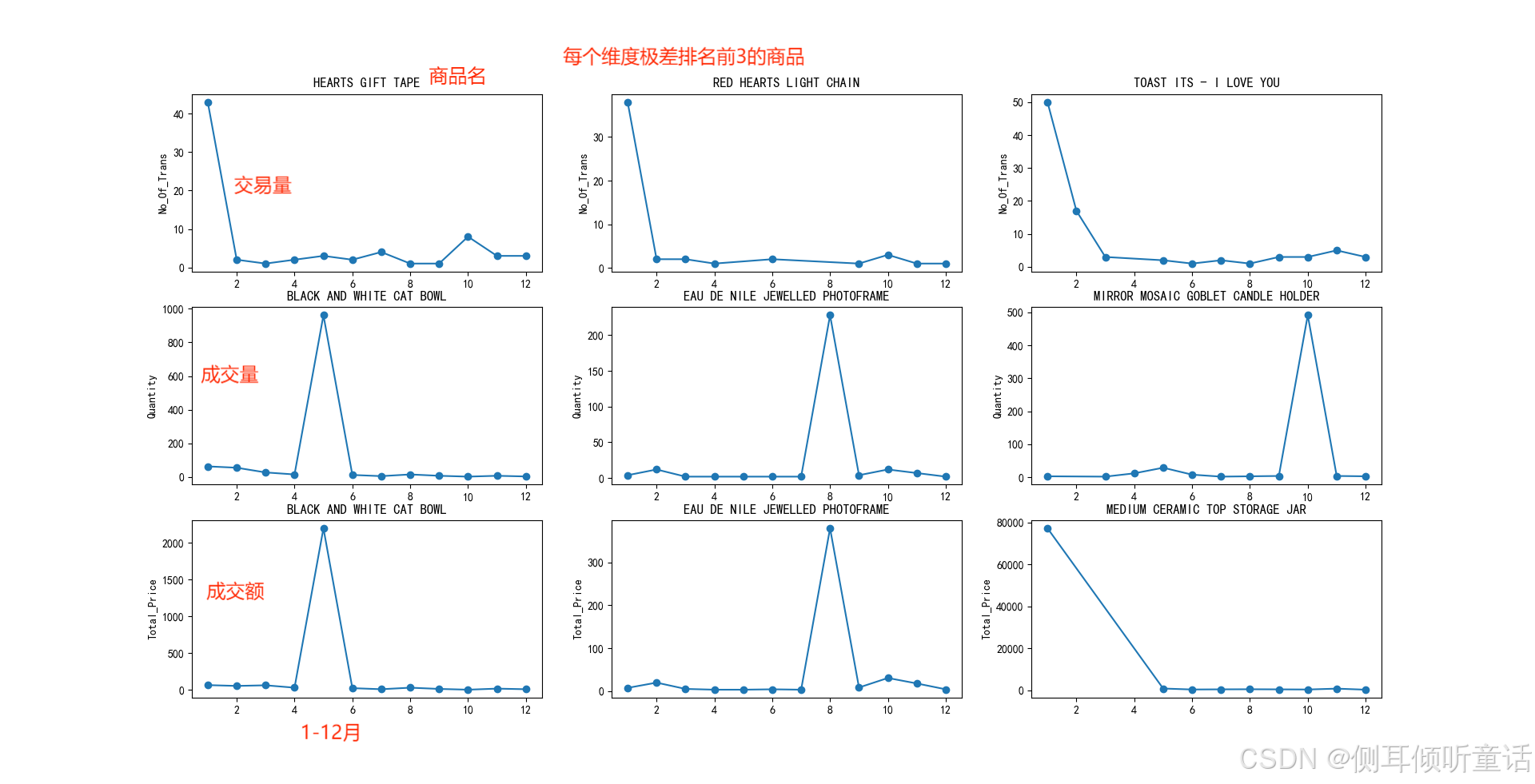
此处分别从交易量、成交量、成交额3个维度构造了季节指数,并将极差排名前3的商品作了折线统计图。
从图中来看,这些商品全都是“集中在某一个月份十分畅销,但是在其他月份相对无人问津”。
"""
# -----------将全年及每个季度排名top10的商品的交易量、成交量、成交额作水平柱形图,图中商品旁边标出了它对应交易量/成交量/成交额的极差排名--------
# 对rank_df按dimension分组,并取每个小组的第一个非空行,然后再选择"dimension", "item", "range"三列数据。
ranges = rank_df.groupby(["dimension", "item"]).first().reset_index()[["dimension", "item", "range"]]
## no_of_trans交易量排名前十商品,及商品相应的极差
plt.figure(figsize=(20, 20))
range_df = ranges[ranges["dimension"] == "no_of_trans"]
titles = ["all", "season one", "season two", "season three", "season four"]
for n in range(5):
plt.subplot(5, 1, n + 1)
df = dfs[n].copy().reset_index() # 选取全年或1、2、3、4季度的数据
# [i for i in df.index if df.loc[i, "itemname"] in item_set_no_of_trans] 选取在排名前10商品表item_set_no_of_trans
# 中的df的行索引,再选取df的["itemname", "no_of_trans"]两列。
df = df.loc[[i for i in df.index if df.loc[i, "itemname"] in item_set_no_of_trans], ["itemname", "no_of_trans"]]
df = df.sort_values("no_of_trans", ascending=false)
df = df.iloc[:10, :] # 选取 交易量前10 商品。
df = pd.merge(df, range_df, left_on="itemname", right_on="item", how="left") # 两表左合并,使整表的商品名itemname和range列。
# df["itemname"] + " " + df["range"].astype("str")条形图的标签,df["no_of_trans"]条形图长度
plt.barh(df["itemname"] + " " + df["range"].astype("str"), df["no_of_trans"])
plt.title("no_of_trans " + titles[n])
plt.subplots_adjust(hspace=0.4) # 调整子图间距。wspace=0.2,水平间距为 整图的20%,
plt.show()
# quantity成交量排名前十商品,及商品相应的极差
plt.figure(figsize=(20, 20))
range_df = ranges[ranges["dimension"] == "quantity"]
titles = ["all", "season one", "season two", "season three", "season four"]
for n in range(5):
plt.subplot(5, 1, n + 1)
df = dfs[n].copy().reset_index()
df = df.loc[[i for i in df.index if df.loc[i, "itemname"] in item_set_quantity], ["itemname", "quantity"]]
df = df.sort_values("quantity", ascending=false)
df = df.iloc[:10, :]
df = pd.merge(df, range_df, left_on="itemname", right_on="item", how="left")
plt.barh(df["itemname"] + " " + df["range"].astype("str"), df["quantity"])
plt.title("quantity " + titles[n])
plt.subplots_adjust(hspace=0.4) # 调整子图间距。wspace=0.2,水平间距为 整图的20%,
plt.show()
# total_price成交额排名前十商品,及商品相应的极差
plt.figure(figsize=(20, 20))
range_df = ranges[ranges["dimension"] == "total_price"]
titles = ["all", "season one", "season two", "season three", "season four"]
for n in range(5):
plt.subplot(5, 1, n + 1)
df = dfs[n].copy().reset_index()
df = df.loc[[i for i in df.index if df.loc[i, "itemname"] in item_set_total_price], ["itemname", "total_price"]]
df = df.sort_values("total_price", ascending=false)
df = df.iloc[:10, :]
df = pd.merge(df, range_df, left_on="itemname", right_on="item", how="left")
plt.barh(df["itemname"] + " " + df["range"].astype("str"), df["total_price"])
plt.title("total_price " + titles[n])
plt.subplots_adjust(hspace=0.4) # 调整子图间距。wspace=0.2,水平间距为 整图的20%,
plt.show()
月度极差排名前3的商品,绘制其1-12月相应维度数据的折线图,如下图所示。
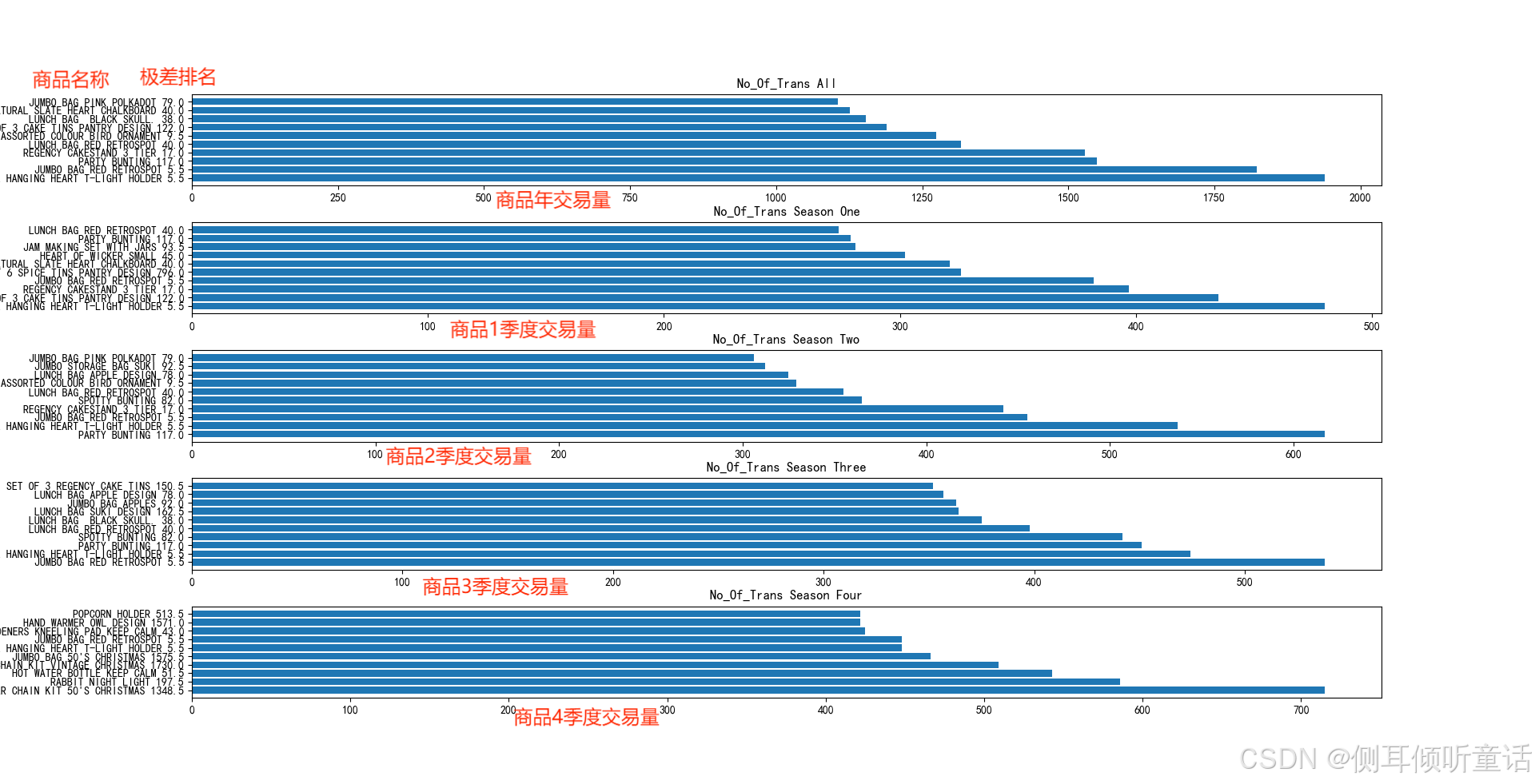
全年及每个季度交易量、成交量、成交额排名top10的商品的,图中商品旁边标出了它对应交易量、成交量、成交额的极差排名。交易量的水平柱形图如下所示。
成交量的柱形图如下所示:
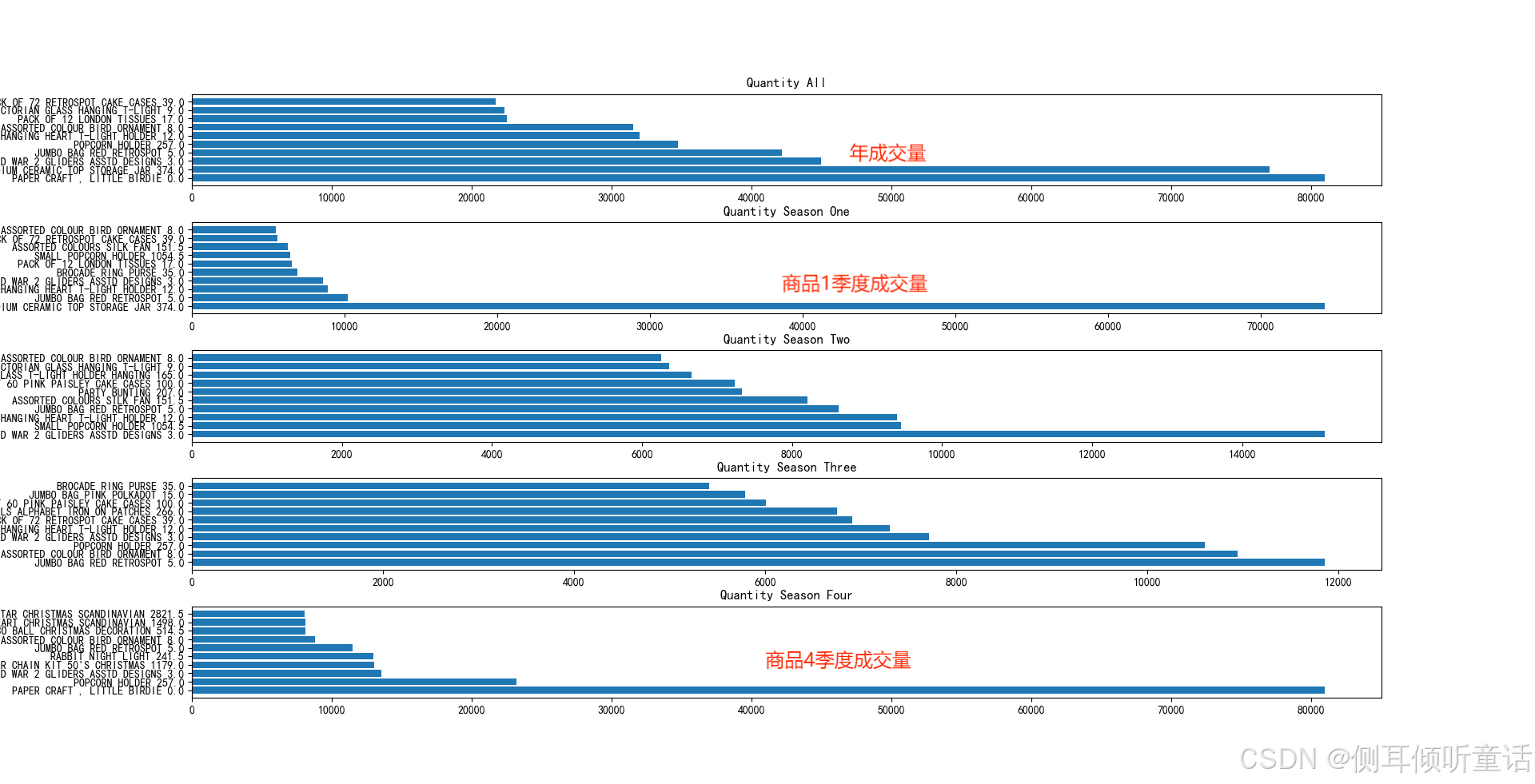
成交额的柱形图如下所示:
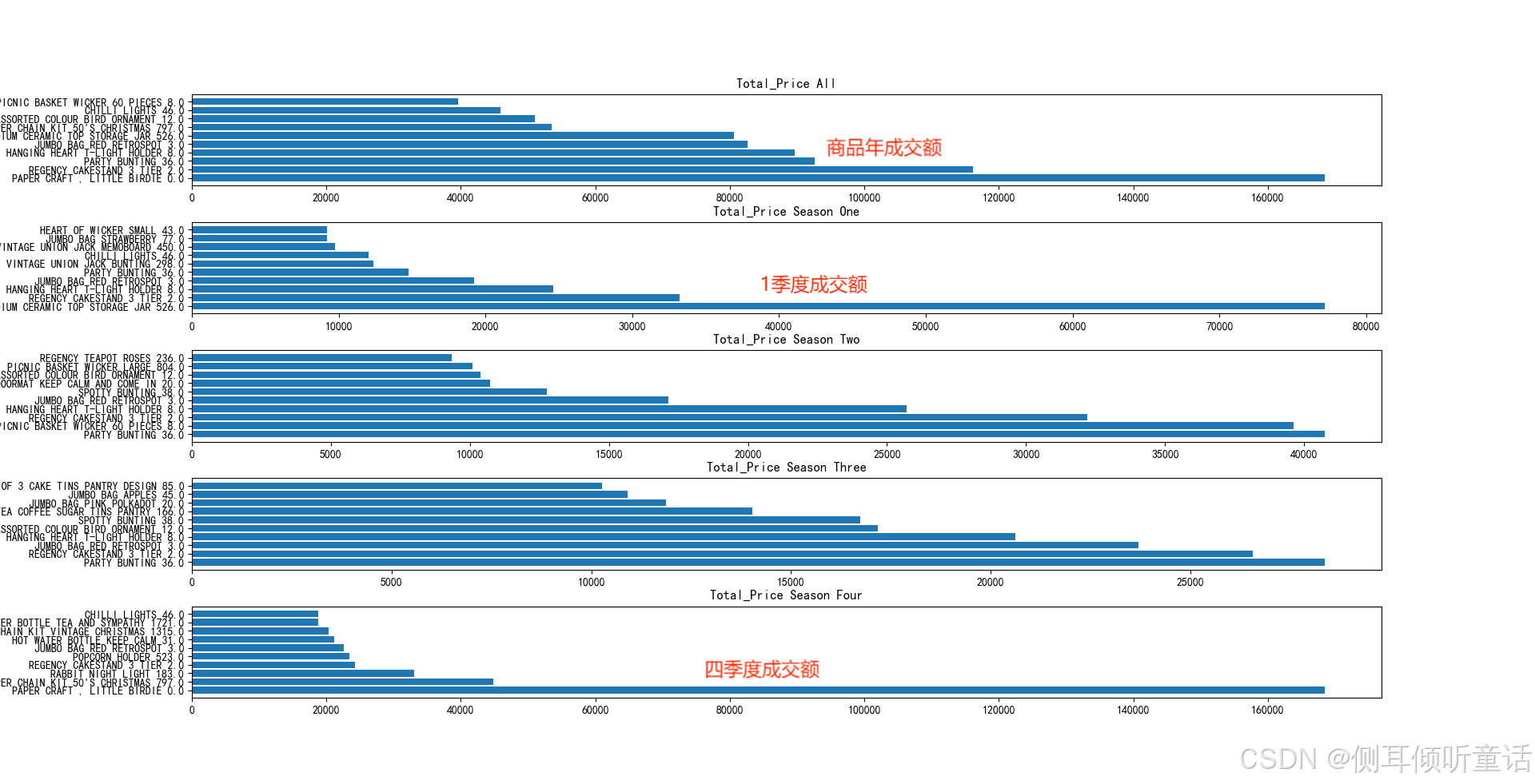
可以看到,虽然大多数在全年销售中获得的top10排名极差都较小(总共有3000+个商品), 但是在总成交额的全年top10中,依然有一个明显存在季节性效应的商品(paper chain kit 50’s chrismas)。
2.3.6 同一个商品在不同维度上全年排名之间的排名差
计算每件商品在交易量、成交量、成交额的排名,并将这3个维度排名之差最大的5个商品列出。
代码如下:
# --------(六)同一个商品在不同维度上的全年排名是否排名差距较大---------
"""
计算了每件商品在交易量、成交量、成交额的全年排名,并将这3个维度排名之差最大的5个商品列出了。
"""
df_uk_all = df_uk_monthly.groupby(["itemname"]).sum(["no_of_trans", "quantity", "total_price"]).reset_index()
df_uk_all["no_of_trans_rank"] = df_uk_all["no_of_trans"].rank(ascending=false) # 给交易量标注排名(降序),并添加排名列
df_uk_all["quantity_rank"] = df_uk_all["quantity"].rank(ascending=false)
df_uk_all["total_price_rank"] = df_uk_all["total_price"].rank(ascending=false)
# df_uk_all.shape[0])表示行数。遍历df_uk_all所有行,取出交易量、成交量、成交额的排名,计算这3个数的最大最小值。
# 再计算最大最小值之差rank_gaps,即同一商品的排名差。
rank_gaps = [
__builtins__.max(df_uk_all.loc[i, "no_of_trans_rank"], df_uk_all.loc[i, "quantity_rank"],
df_uk_all.loc[i, "total_price_rank"]) \
- __builtins__.min(df_uk_all.loc[i, "no_of_trans_rank"], df_uk_all.loc[i, "quantity_rank"],
df_uk_all.loc[i, "total_price_rank"]) \
for i in range(df_uk_all.shape[0])]
df_uk_all["rank_gaps"] = rank_gaps #
df_ranked_all = df_uk_all.sort_values("rank_gaps", ascending=false).reset_index(drop=true) # 最大最小值之差 降序排序
# --------------------------可视化:在交易量、成交量、成交额全年排名相差最大的5个商品----------------------
plt.figure(figsize=(20, 20))
for i in range(5): # 取5个商品
plt.subplot(5, 1, i + 1)
sub = df_ranked_all.iloc[i, :] # 逐一取出5行数据(5个商品的数据)
item_name = sub["itemname"]
sub = dict(sub) # 将pandas的dataframe做成字典。方便sub["no_of_trans_rank"]等取值。。
sub_df = pd.dataframe({"index": ["no_of_trans_rank", "quantity_rank", "total_price_rank"],
"value": [sub["no_of_trans_rank"], sub["quantity_rank"], sub["total_price_rank"]]})
plt.barh(sub_df["index"], sub_df["value"])
plt.title(item_name)
plt.subplots_adjust(hspace=0.4) # 调整子图间距。wspace=0.2,水平间距为 整图的20%,
plt.show()
本商品全年交易量、成交量、成交额排名之差最大的前5个商品,如下图所示。
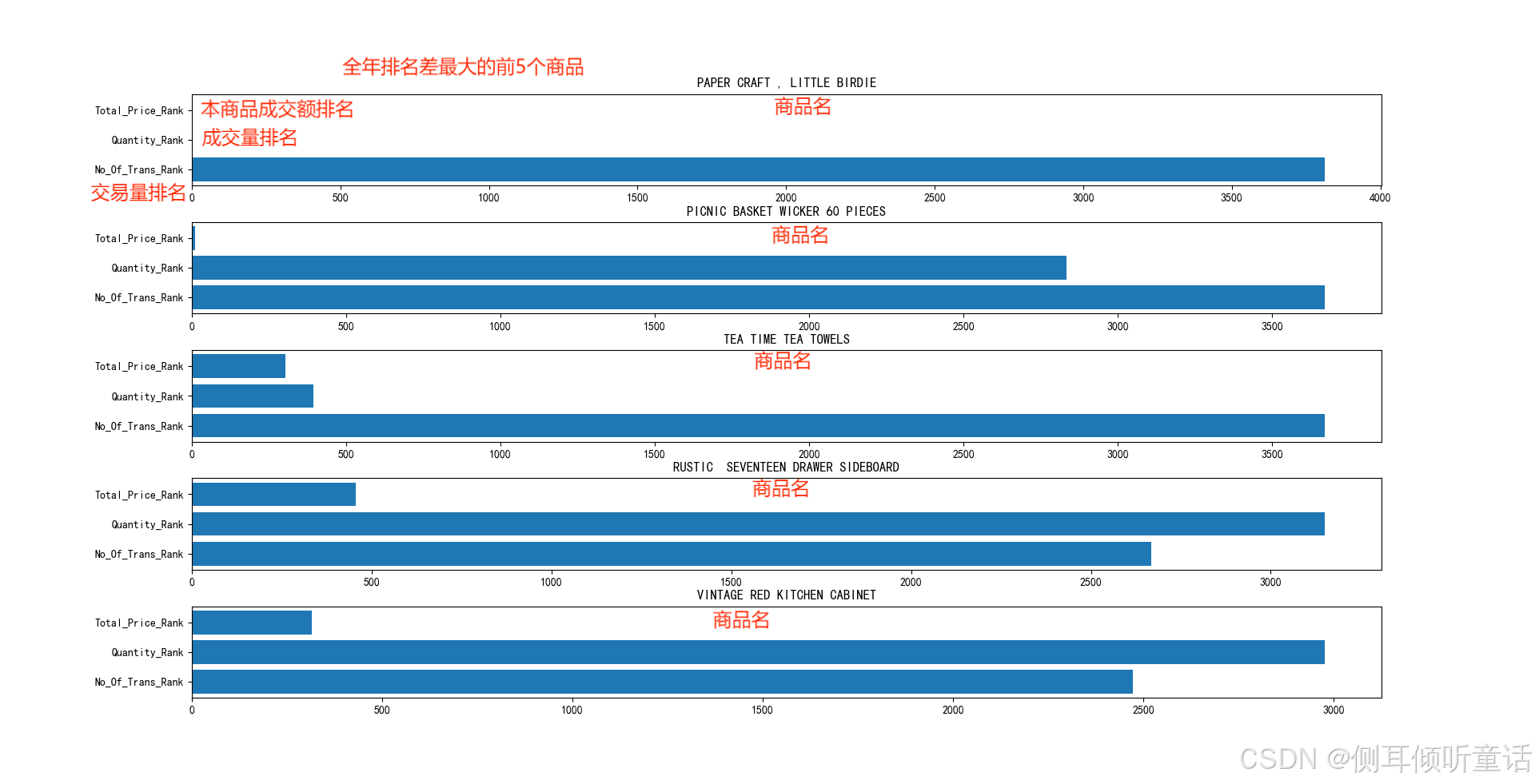
可以发现上图中的商品,有些虽然成交额与成交量名列前茅,但是成交量却排名靠后。特别是第一名(paper craft, little bride),实际看表格数据时会发现它只有1个单子,但是那1个单子却订了8万多个这个商品。
2.3.7 探索客单价、客单量与平均售价
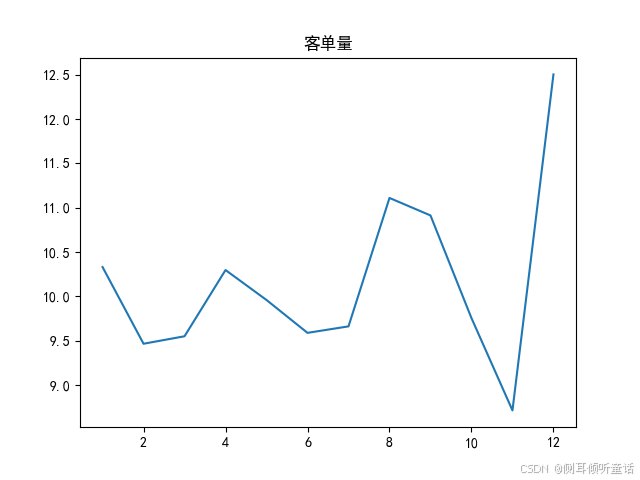
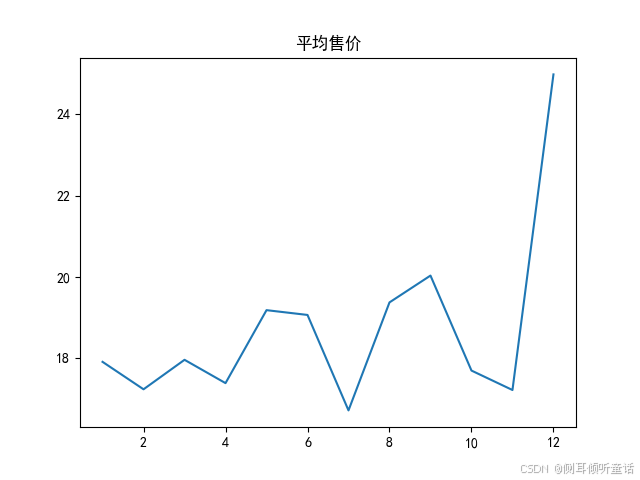
构造以下3个kpi(每月):
客单量(upt, units per transaction)= 成交量(quantity)/交易量(no_of_trans), 客单量是指平均每笔交易所包含的商品数量。
平均售价(asp, average selling price)= 成交额(total_price)/ 成交量(quantity),平均售价是指售出商品的平均价格。
客单价(atv, average transaction value)= 成交额(total_price)/ 成交量(no_of_trans),客单价是指平均每笔交易的总金额。
客单量,平均每笔交易所包含的商品数量,如下图所示。
平均售价,售出商品的平均价格,如下图所示。
客单价,平均每笔交易的总金额,如下图所示。
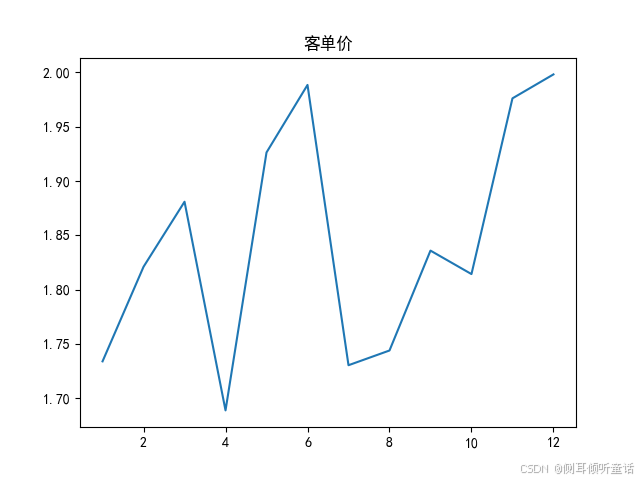
每月交易量,如下图所示。
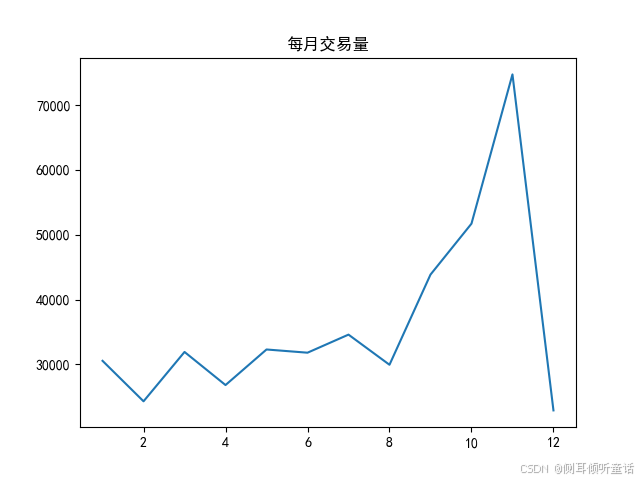
11月的高成交额实际上是由于11月的高交易量。尽管12月份的成交额再次下降,但12月份的订单大多都是大单子。
3 数据挖掘—关联规则分析
关联规则分析为的就是发现商品与商品之间的关联。通过计算商品之间的支持度、置信度与提升度,分析哪些商品有正向关系,顾客愿意同时购买它们。
此处使用了pyspark自带的fpgrowth算法。它和apriori算法一样都是计算两两商品之间支持度置信度与提升度的算法,虽然算法流程不同,但是计算结果是一样的。
关联规则算法只需要每个订单商品名称,不需要其他数据。因此,每个订单的商品名称放在一个列表里,整理后的 数据集如下图所示。
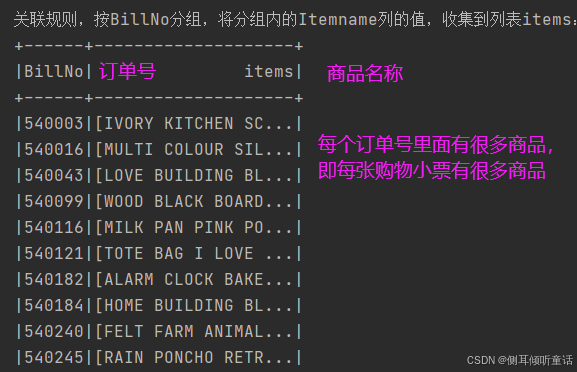
利用pyspark机器学习库的关联规则模型,对上述数据集进行关联分析,代码如下:
from pyspark.ml.fpm import fpgrowth, fpgrowthmodel
"""
df_uk_concatenated = df_uk\
.groupby(["billno", "itemname"])\
.agg(f.sum("quantity").alias("quantity"))\
.groupby("billno")\
.agg(f.collect_list(f.col("itemname")).alias("items"))
"""
# 将同一个订单号的商品集合到一个列表。
df_uk_concatenated = df_uk \
.groupby(["billno", "itemname"]) \
.agg(f.sum("quantity").alias("quantity")) # 按"billno", "itemname"分组,计算quantity的总数(分组后必须要有一个运算式子)
print("关联规则,按billno, itemname分组:")
df_uk_concatenated.show(10, false)
df_uk_concatenated = df_uk_concatenated \
.groupby("billno") \
.agg(f.collect_list(f.col("itemname")).alias("items"))
print("关联规则,按billno分组,将分组内的itemname列的值,收集到列表items:")
df_uk_concatenated.show(10)
model = fpgrowth(minsupport=0.03, minconfidence=0.3)
model = model.fit(df_uk_concatenated.select("items"))
res = model.associationrules.topandas()
# -----------------------关联规则可视化-----------------------
combs = [('confidence', 'lift', 'support'), ('lift', 'support', 'confidence'), ('support', 'confidence', 'lift')]
for i, (x, y, c) in enumerate(combs):
plt.subplot(3, 1, i + 1)
sc = plt.scatter(res[x], res[y], c=res[c], cmap='viridis')
plt.xlabel(x)
plt.ylabel(y)
plt.colorbar(sc, label=c)
plt.show()
# 支持度(support)前三的商品组合(每2条实际上是同一组商品)。
print(res.sort_values("support", ascending=false).head(6))
# 置信度(confidence)前5的商品组合,置信度指的是当商品a被购买时,商品b也被购买的概率。
print(res.sort_values("confidence", ascending=false).head(5))
# 提升度(lift)前三的商品组合(每2条实际上是同一组商品)。 提升度可以看做是2件商品之间是否存在正向/反向的关系。
print(res.sort_values("lift", ascending=false).head(6))
(1) antecedent(前件)
定义:在关联规则中,if部分称为前提(antecedent),表示某些物品的组合。它是规则中用于推断或预测的条件部分。
示例:在规则“购买牛奶 → 购买面包”中,“购买牛奶”是前件。
(2) consequent(后件)
定义:在关联规则中,then部分称为结果(consequent),表示其他物品的组合。它是在前件满足时可能发生的结果。
示例:在规则“购买牛奶 → 购买面包”中,“购买面包”是后件。
(3) confidence(置信度)
定义:置信度是关联规则的可信程度,表示在包含前件的事务中,同时也包含后件的事务所占的比例。
示例:如果购买牛奶的顾客中有70%也购买了面包,则规则“购买牛奶 → 购买面包”的置信度为70%。
(4) lift(提升度)
定义:提升度表示在包含前件的事务中同时包含后件的比例,与仅包含后件的事务的比例之间的比值。它反映了前件对后件出现的提升作用。
示例:如果购买牛奶的顾客中购买面包的比例是70%,而所有顾客中购买面包的比例是50%,则规则“购买牛奶 → 购买面包”的提升度为1.4(70% / 50%)。
(5) support(支持度)
定义:支持度是项集在数据集中出现的频率或概率,表示同时包含前件和后件的事务占所有事务的比例。
示例:如果100个购物交易中,有30个交易同时包含了牛奶和面包,则规则“购买牛奶 → 购买面包”的支持度为30%。
按支持度(support)降序排序的商品组合(每2条实际上是同一组商品)。
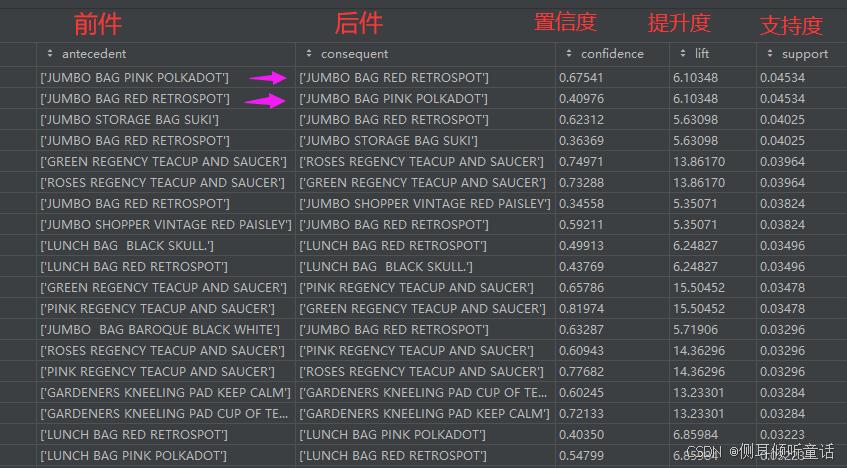
第一条关联规则:[‘jumbo bag pink polkadot’]----->[‘jumbo bag red retrospot’],
置信度confidence为0.67541,表示购买了jumbo bag pink polkadot商品的顾客,有67.541%的概率会购买商品jumbo bag red retrospot。
提升度lift为6.10348,如果该值大于1,则说明该关联规则有效,值越大,有效性越强。
支持度support为0.04534,表示有4.5%的交易包含了商品jumbo bag pink polkadot和商品jumbo bag red retrospot,即这两样商品在所有交易中出现的频率。
置信度(confidence)降序排名的商品组合,置信度指的是当商品a被购买时,商品b也被购买的概率。
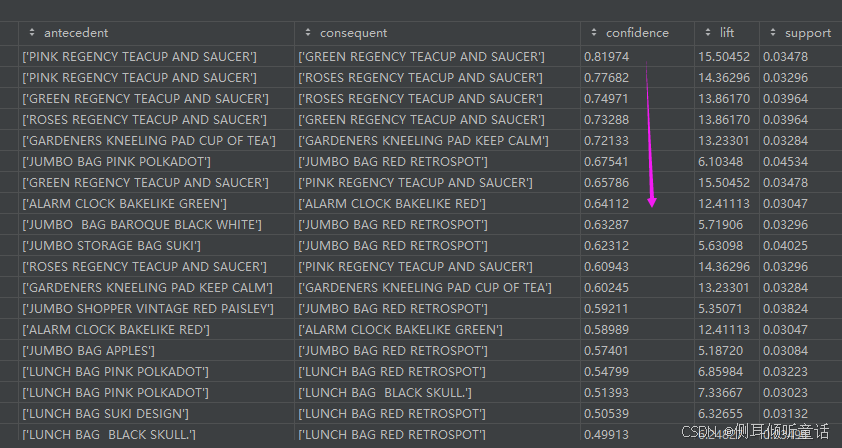
关联规则:[‘pink regency teacup and saucer’]---->[‘green regency teacup and saucer’]的置信度confidence为0.81974,提升度lift为15.50452,支持度support为0.03478。
提升度(lift)降序排名的商品组合(每2条实际上是同一组商品)。 提升度可以看做是2件商品之间是否存在正向/反向的关系。
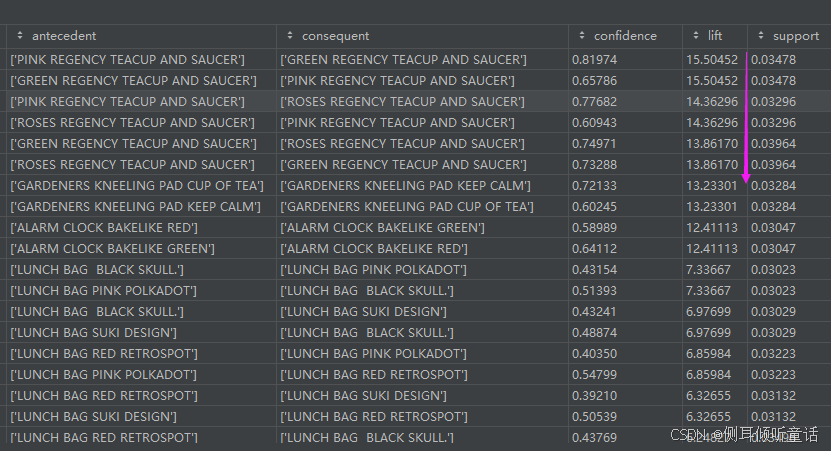
[‘pink regency teacup and saucer’]—>[‘green regency teacup and saucer’]的置信度confidence为0.81974,提升度lift为15.50452,支持度support为0.03478。
可将关联规则模型推荐的结果存储在mysql数据库,再通过flask在可视化大屏展示。
4 数据可视化大屏的设计
这部分内容可参考作者写的另外一篇文章,flask+pyecharts+大数据集群:数据可视化大屏的实现:链接: ,“六、flask+pyecharts+大数据集群(linux):绘制数据可视化大屏。”
前期准备:安装pyechats,flask等组件。
flask:是一个轻量级、灵活、可扩展的web应用框架,使用python编写,适合用于构建中小型web应用程序。它提供了基本的路由、模板引擎、url构建、错误处理等功能,并支持插件和扩展来增强其功能。
flask提供了一个路由系统,可以将不同的url路径映射到相应的处理函数上。当用户访问特定的url时,flask会调用相应的处理函数,并返回响应。
flask内置了一个基于jinja2的模板引擎,开发者可以使用模板来渲染html页面。通过将动态数据传递给模板,并使用模板语言来定义页面的结构和样式,开发者可以轻松地创建和管理web页面的外观和布局。
pyecharts:是一款基于python的开源数据可视化库,它整合了echarts与python的优势,使得在python环境中能够轻松创建出美观且交互性强的图表。pyecharts支持多达数十种图表类型,包括折线图、柱状图、散点图、饼图等常见图表,以及地图、热力图、关系图等特色图表。这些丰富的图表类型能够满足不同场景下的数据可视化需求。
pyecharts的基本教程可以参考本文作者的另外一篇文章:pyecharts快速入门及高清图片保存:链接:
在idea项目上创建3个目录:data,static,templates,和1个python文件:main.py。data用来存储本地数据,static用来存放echarts的图表和组件模板文件,templates用来存放html文件,项目的目录结构如下图所示。
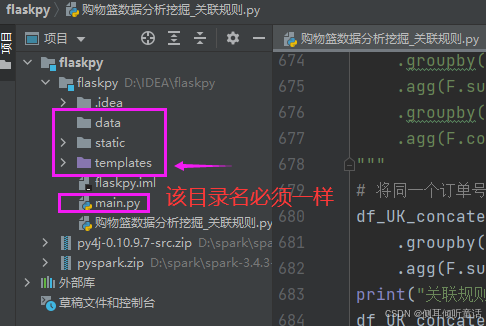
在templates文件上单击鼠标右键,将该目录标记为模板文件夹,flask默认渲染该文件下的html文件。
到echarts官网下载模板和组件json文件:链接: https://echarts.apache.org/zh/download.html
将下载的echats.js文件复制到static目录。
在templates目录下新建html文件,用于展示可视化图形,选择html 5文件格式,命名为show_pyecharts_05。
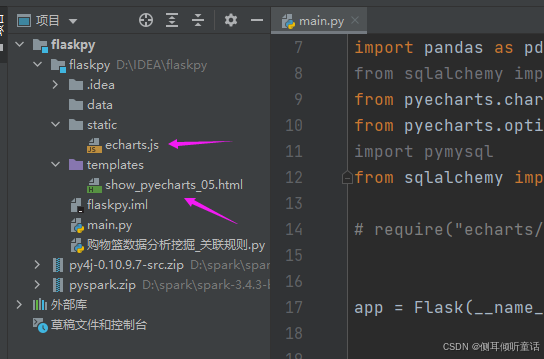
打开main.py文件,清空里面的内容,输入以下代码:
import json
import pyecharts.charts
from flask import flask, render_template
from pyecharts.options import *
from markupsafe import markup # 导入 markup,用于在 flask 模板中安全地渲染 html
from pyecharts import charts
import pandas as pd
from sqlalchemy import create_engine
from pyecharts.charts import pie, bar, line
from pyecharts.options import labelopts, titleopts, legendopts
import pymysql
from sqlalchemy import create_engine
app = flask(__name__) # 创建一个 flask 应用实例
# ---------------4.读取集群的mysql数据,绘制可视化大屏------------------------
# 自定义函数,读master节点的mysql数据
def connfun_linux(sql_query):
engine = create_engine("mysql+pymysql://root:123456@192.168.126.10:3306/test")
try:
data = pd.read_sql(sql_query, engine)
return data
except exception as e:
print(f"an error occurred: {e}")
raise # 可选:重新抛出异常以便在外部捕获 '''
# 读取master节点(linux系统)中的mysql数据,自定义绘图函数
def get_pie_linux():
sql = '''select * from data_ttl_country'''
data = connfun_linux(sql) # 确保这个函数返回的是dataframe
# data.set_index("country", inplace=true)
top_five = data.sort_values("quantity", ascending=false)[:5]
others_quantity = data.sort_values("quantity", ascending=false)[5:]['quantity'].sum() # 其余国家的销售量和销售额总和
others_total_price = data.sort_values("quantity", ascending=false)[5:]['total_price'].sum() # 其余国家的销售量和销售额总和
top_five2 = top_five.copy()
others_df = pd.dataframe(
{"country": ["others"], "quantity": [others_quantity], "total_price": [others_total_price]})
pie_data = pd.concat([top_five2, others_df], ignore_index=true)
country = list(pie_data["country"])
quantity = list(pie_data['quantity'])
data_list = [list(z) for z in zip(country, quantity)]
c = (
pie()
.add("", data_list, radius=["40%", "75%"])
.set_global_opts(title_opts=titleopts(title="成交量"),
legend_opts=legendopts(orient="vertical", pos_top="15%", pos_left="2%"))
.set_series_opts(label_opts=labelopts(formatter="{b}: {c}"))
)
return c
def get_bar_linux():
sql = '''select * from data_ttl_weekday '''
data = connfun_linux(sql)
data = data.sort_values('dayofweek', ascending=true)
# x = list(data["dayofweek"])
x = ['星期一', '星期二', '星期三', '星期四', '星期五', '星期六', '星期日']
y1 = list(data['quantity'])
c = (
pyecharts.charts.bar()
.add_xaxis(x)
.add_yaxis("成交量(quantity)", y1)
.set_global_opts(title_opts=titleopts(title="周一到周日成交量", subtitle="bar"),
xaxis_opts=axisopts(axislabel_opts=labelopts(rotate=45)), )
)
return c
def get_line_linux():
sql = '''select * from data_ttl_time '''
data = connfun_linux(sql)
data = data.sort_values(['year', 'month'])
x = [str(i) + "\n" + str(j) for i, j in zip(data["year"], data["month"])] # x轴刻度标签
y2 = list(data["quantity"])
y1 = list(data['total_price'].round(0)) # 保留2位小数
c = (
line()
.add_xaxis(x)
.add_yaxis("成交额", y1,
markline_opts=marklineopts(data=[marklineitem(type_="average")]),
label_opts=labelopts(is_show=false), ) # 不显示数据点标签
.add_yaxis("成交量", y2,
markline_opts=marklineopts(data=[marklineitem(type_="average")]),
label_opts=labelopts(is_show=false),
markpoint_opts=markpointopts(data=[markpointitem(coord=[11, y2[11]], value=y2[11])]), )
.set_global_opts(title_opts=titleopts(title="成交量和成交额折线图"))
)
return c
def get_barstack_linux():
sql = '''select * from data_ttl_country_time '''
data_ttl_country_time = connfun_linux(sql)
data_ttl_country_time["isunitedkingdom"] = ["uk" if i == "united kingdom" else "not uk" for i in
data_ttl_country_time["country"]] # 创建isunitedkingdom列
data_ttl_country_time_isuk = data_ttl_country_time.groupby(["isunitedkingdom", "year", "month"])[
"total_price"].sum().reset_index() # 分组并计算成交额
data_ttl_country_time_isuk.index = [str(i) + "\n" + str(j) for i, j in
zip(data_ttl_country_time_isuk["year"],
data_ttl_country_time_isuk["month"])] # 重建索引
uk = data_ttl_country_time_isuk[data_ttl_country_time_isuk["isunitedkingdom"] == "uk"] # 英国uk的每年每月成交额
nuk = data_ttl_country_time_isuk[data_ttl_country_time_isuk["isunitedkingdom"] == "not uk"] # 非英国uk的每年每月成交额
x = list(uk.index)
y1 = list(uk['total_price'])
y2 = list(nuk['total_price'])
c = (
bar()
.add_xaxis(x)
.add_yaxis("英国", y1, stack="stack1")
.add_yaxis("其他国家", y2, stack="stack1")
.set_series_opts(label_opts=labelopts(is_show=false))
.set_global_opts(title_opts=titleopts(title="成交额"), toolbox_opts=toolboxopts(is_show=true), )
)
return c
@app.route('/show_pyecharts_05')
def show_pyecharts_05():
pie = get_pie_linux()
bar = get_bar_linux()
line = get_line_linux()
barstack = get_barstack_linux()
return render_template("show_pyecharts_05.html",
pie_options=pie.dump_options(),
bar_options=bar.dump_options(),
line_options=line.dump_options(),
barstack_options=barstack.dump_options(), )
if __name__ == "__main__":
app.run(host='127.0.0.1', port=5000, debug=true)
上面的程序,将通过pandas访问mysql,读取pyspark存放的数据,读取mysql数据库的代码如下图所示:
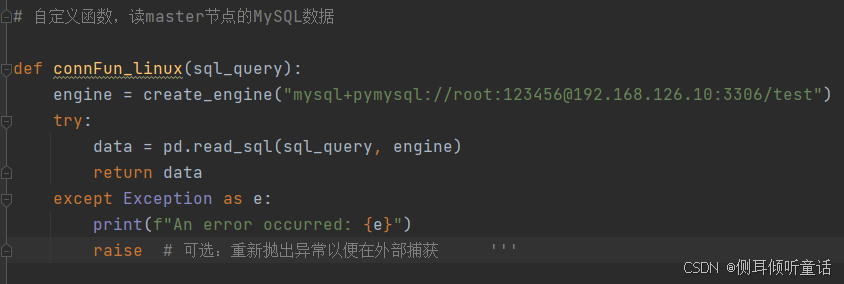
图中,192.168.126.10为大数据集群主节点master的ip地址,3306为mysql的访问端口,test为mysql数据库的名字。root为mysql用户名,123456为密码。
这部分的编程流程是:先用pandas读取mysql数据,pyecharts绘制图表,flask再将pyechart绘制的图表渲染到show_pyecharts_05.html页面。
打开show_pyecharts_05.html,清空里面的内容,粘贴以下代码:
<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<title>echarts</title>
<style >
/* css 样式将放在这里 */
.chart-container{
display:flex;
flex-direction:column; /* 默认为column,表示垂直布局 */
justify-content:center; /* 水平居中 */
align-items:center; /* 垂直居中(如果需要的话) */
height:150vh; /* 根据需要设置容器高度 */
width:100%; /* 占据全屏宽度 */
}
.chart-row{
display: flex; /* 每一行都是一个flex容器 */
justify-content:space-between; /* 列之间均匀分布 */
margin-bottom:20px; /* 行与行之间的间距 */
}
.chart-item{
flex: 1; /* 每个flex item占据相等的空间 */
margin: 0 10px; /* 图表之间的间距 */
}
</style>
<!-- 引入刚刚下载的 echarts 文件 -->
<script src="/static/echarts.js"></script>
</head>
<body>
<!-- 为 echarts 准备一个定义了宽高的 dom -->
<div class="chart-container">
<div class="chart-row">
<div class="chart-item" id="pie" style="width: 800px;height:400px;"></div>
<div class="chart-item" id="bar" style="width: 800px;height:400px;"></div>
</div>
<div class="chart-row">
<div class="chart-item" id="line" style="width: 800px;height:400px;"></div>
<div class="chart-item" id="barstack" style="width: 800px;height:400px;"></div>
</div>
</div>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var piechart = echarts.init(document.getelementbyid('pie'));
var barchart = echarts.init(document.getelementbyid('bar'));
var linechart = echarts.init(document.getelementbyid('line'));
var barstackchart = echarts.init(document.getelementbyid('barstack'))
// 使用刚指定的配置项和数据显示图表。
piechart.setoption({{ pie_options | safe }});
barchart.setoption({{ bar_options | safe }});
linechart.setoption({{ line_options | safe }});
barstackchart.setoption({{ barstack_options | safe }});
</script>
</body>
</html>
以下面的数据为例,pyspark已经将这些数据存储在linux系统的mysql的test数据库,先读取这些数据,然后pyecharts绘制图表,flaskk将图表渲染到页面,制作成可视化大屏,可视化大屏的布局为2行2列。
总体国家分析(data_ttl_country):按国家(country)分组,计算各组的成交量(quantity)和成交额(total_price)。
总体星期几分析(data_ttl_weekday):按星期(dayofweek)分组,计算各组的成交量(quantity)和成交额(total_price)。
总体时间分析(按年和月)(data_ttl_time):按年(year)、月(month)分组,计算各组的成交量(quantity)和成交额(total_price)。
总体国家时间分析(按国家、年和月)(data_ttl_country_time):按国家(country)、年(year)、月(month)分组,计算各组的成交量(quantity)和成交额(total_price)。
flask渲染的可视化大屏如下图所示。
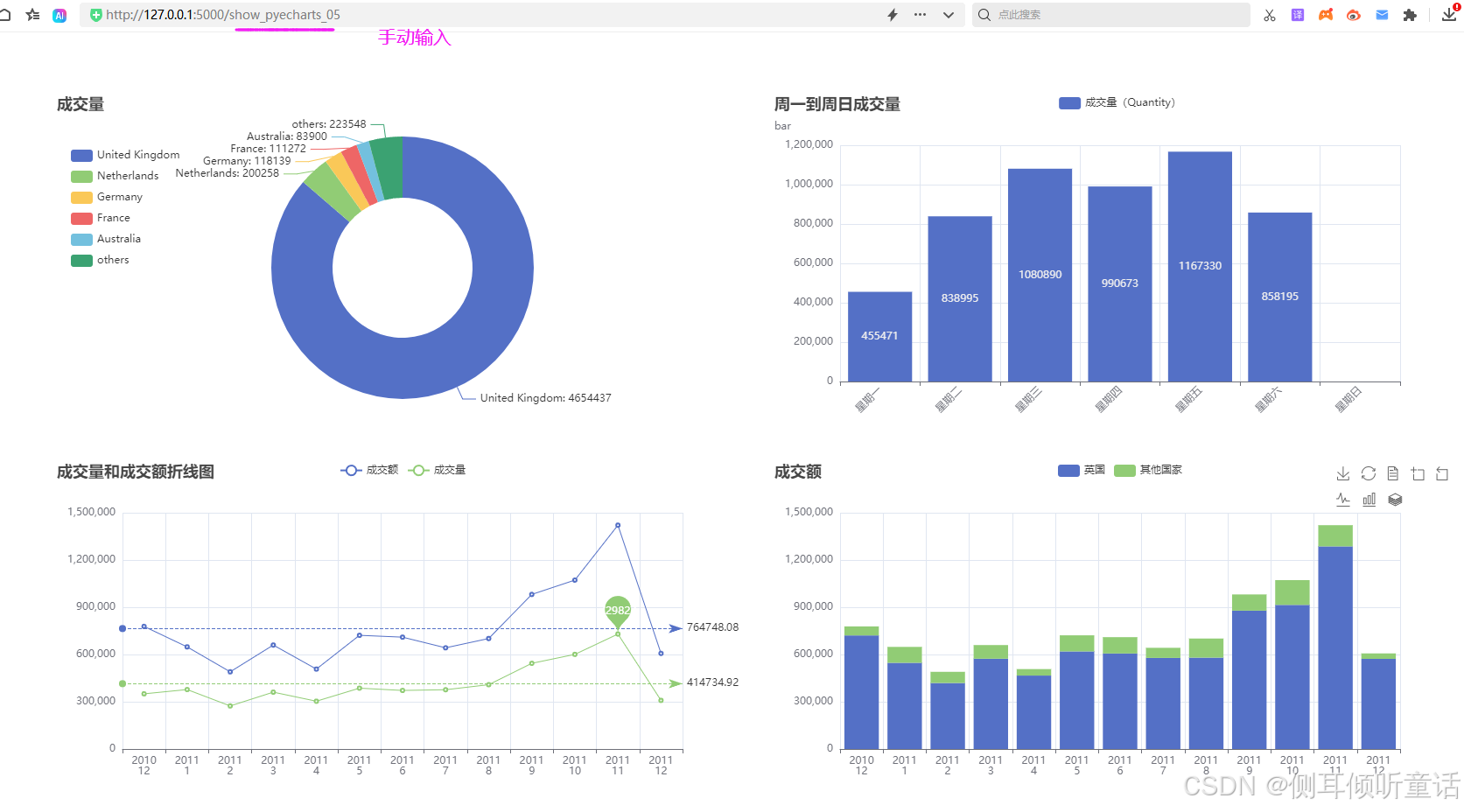
pyecharts绘制的图表更精致美观,图形也更丰富。本案例有很多图形,可以将它们渲染到可视化大屏,如果一个页面放不下,可以渲染到几个页面。
5 总结
(1)季节性销售波动分析:数据明确显示,英国市场在2011年11月出现了显著的销售量激增,这一趋势很可能与年度购物季(如黑色星期五、圣诞节前购物潮)相吻合,随后在12月虽略有回落,但仍维持较高水平,反映出节日促销活动的持续影响。
(2)交易量与单笔交易价值分析:11月的高销售量主要得益于交易次数的增加,表明消费者在该月更加活跃;而12月虽然销售量稍减,但可能由于节日期间高端礼品或大宗商品的购买增加,导致单笔交易金额显著上升,体现了市场消费结构的变化。
(3)季节性产品策略:进一步确认了产品销量受季节性因素影响显著,即便是年度畅销产品如“paper chain kit 50’s christmas”也表现出强烈的季节特征。这要求商家需提前规划库存,优化供应链管理,以应对季节性需求波动。
(4)小众产品高销量现象:注意到像“paper craft, little birdie”这样的产品,尽管交易次数极少,但单笔交易的高销量使其位居前列。这提示商家应重视小众市场,可能通过限量发售、定制服务等方式提升产品附加值,吸引特定消费群体。
(5)商品组合与购买习惯:通过关联规则分析,发现消费者倾向于购买同一产品的不同颜色版本,如杯子和碟子的组合购买,这反映了消费者对产品多样性和协调性的需求。商家可据此优化产品组合策略,推出更多配套产品或套餐优惠,提升购买转化率。
下一步工作:
(1)增强市场细分与个性化营销:基于用户购买历史、偏好及行为数据,进行更细致的市场细分,实施个性化营销策略。例如,针对高频购买者提供会员特权或积分奖励,对偏好特定类型产品的消费者推送定制化促销信息。
(2)优化库存管理与预测模型:利用历史销售数据结合季节性因素、市场趋势预测模型,提高库存管理的精确度和灵活性,减少库存积压和缺货风险,同时优化资金占用。
(3)跨品类关联营销:除了同一产品的不同颜色或款式外,探索跨品类的商品组合推荐,如基于用户购买习惯分析,推荐与已购商品相辅相成的其他产品,增加购物篮平均价值。
参考资料:
1.从0开始学习pyspark–spark dataframe数据的选取与访问[第5节]:https://blog.csdn.net/weixin_43817712/article/details/140127703
2.大数据–关联规则挖掘案例:https://blog.csdn.net/qq_51641196/article/details/128478588
3.pyspark+关联规则 kaggle购物篮分析案例:https://blog.csdn.net/thorn_r/article/details/138351087
4.spark 关联规则挖掘:https://blog.csdn.net/weixin_39709476/article/details/109223271
5.pandas vs spark:获取指定列的n种方式:https://blog.csdn.net/weixin_43841688/article/details/115222979
6.spark官网:https://spark.apache.org/docs/latest/api/python/reference/index.html


发表评论