文章目录
hadoop 之文件读取
hadoop 文件读取
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iyti55aw-1630285652604)(/users/craft/pictures/typora_images/e2ad600f-da37-45e3-9221-baacd87c588f-0285619.jpg)]
具体的步骤如下:
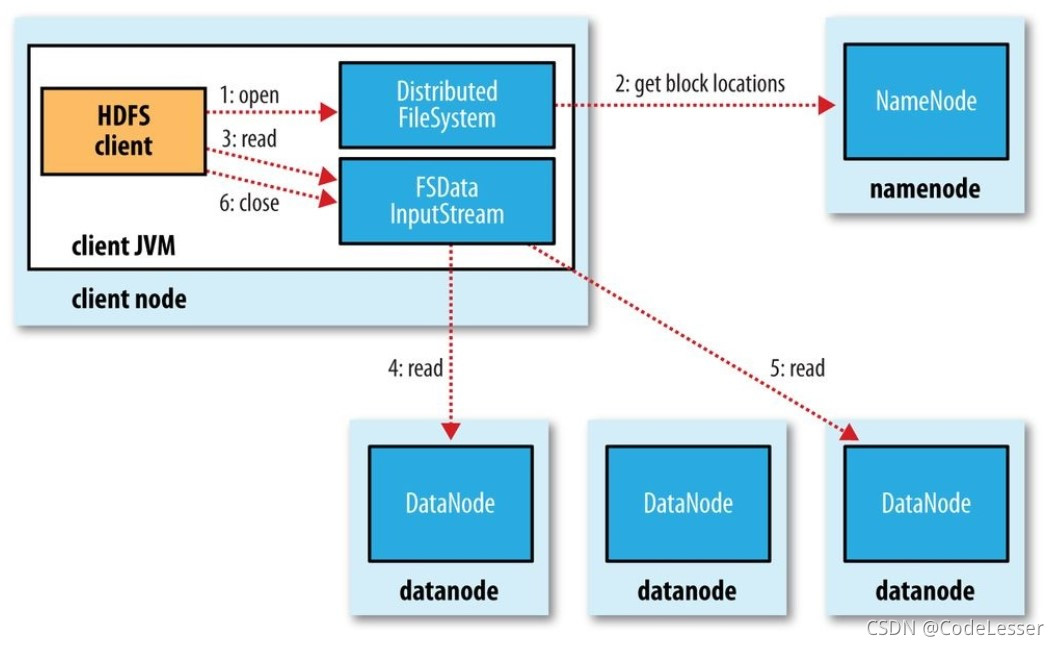
1.客户端调用 filesystem 对象的 open() 方法来打开待读取的文件(对于 hdfs 来说,就是 distributedfilesystem)
2.distributedfilesystem 通过 rpc 来调用 namenode,确定文件起始块的位置,对于每个块,namenode 返回存有该块副本的 datanode 地址。这些 datanode 根据它们与客户端的距离来排序
distributedfilesystem 类返回一个 fsdatainputstream 对象给客户端以便读取数据(该类封装了 dfsinputstream,管理 datanode 和 namenode 的 i/o)
3.客户端对 fsdatainputstream 调用 read() 方法,dfsinputstream 从它所存储的起始几个块的 datanode 中,选择最近的第一个块所在的 datanode 建立连接
4.通过对数据流反复调用 read() 方法,将数据从 datanode 传输到客户端
5.到达块的末端时,dfsinputstream 关闭与该 datanode 的链接,寻找下一个块的最佳 datanode
6.客户端从流中读取数据时,块是按照打开 dfsinputstream 与 datanode 新建连接的顺序读取的。也会根据需要询问 namenode 来检索下一批数据块的 datanode 的位置。当客户端完成读取,就会对 fsdatainputstream 调用 close() 方法
网络拓扑
- 同一节点上的进程
- 同一机架上的不同节点
- 同一数据中心中不同机架上的节点
- 不同数据中心中的节点
假设有数据中心 d1 机架 r1 中的节点 n1,该节点可以表示为 /d1/r1/n2。利用这种标记,给出四中距离的描述
- distance(/d1/r1/n1, /d1/r1/n1) = 0
- distance(/d1/r1/n1, /d1/r1/n2) = 0
- distance(/d1/r1/n1, /d1/r2/n3) = 0
- distance(/d1/r1/n1, /d2/r3/n4) = 0

发表评论