rbf
在前边,已经介绍了hdfs federation,也提到了解决federation但带来问题的viewfs和3.x新带来的viewfs overload schema特性。但之前应用更广泛的是router-based federation,一种基于服务端的实现解决方案。
此方案增加了额外的一层设计,能够实现用户透明的访问子集群。它能够管理并维护集群namespace的状态,将请求转发到正确的子集群,并且支持跨子集群的数据均衡。同时,它也实现可扩展、高可用和容错机制。
架构
rbf主要由两层组成,router及state store。router主要有两个角色:
-
federated interface:与namenode有相同的接口,所以可以直接接受客户端的请求并将请求转发到正确的集群。
-
namenode heartbeats:这个意思在于router会监控namenode的状态和心跳信息并将信息存储到state store(主要包括ha state及负载情况)
而state store主要就负责:
-
存储mount table,是的,和viewfs的基本一样。存储文件夹与子集群的映射关系。
-
存储membership table。这个表存储的就是上面router监控的namenode信息
-
存储router本身的心跳。
看到这里,整个请求流程大概就清晰了:
-
客户端发出读写请求到router
-
router从state store中的mount table中找出包含实际文件路径的集群
-
router同时会通过state store中的membership table,确认正确的namenode,同时会检查该集群中目标namenode的状态。
-
这些都完成之后,会将请求转发到对应的namenode。
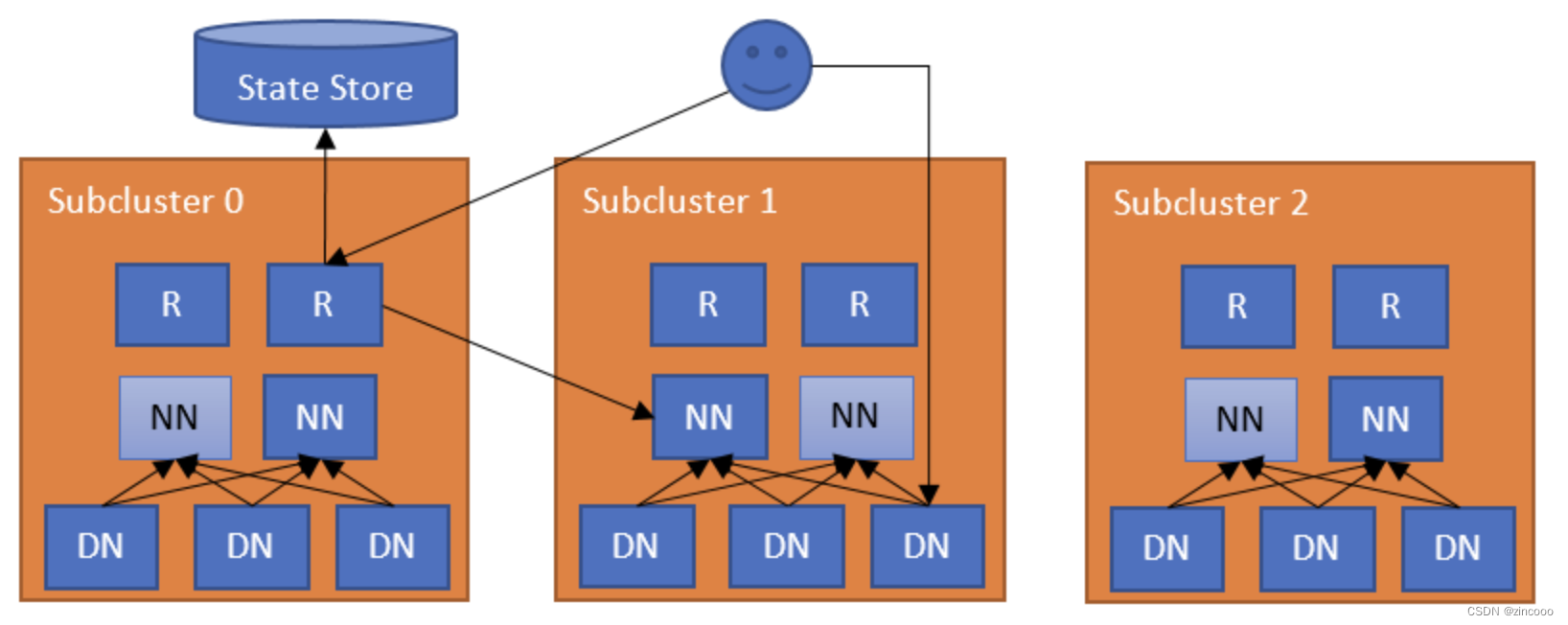
这里将mount table存储到了state store(默认是使用zookeeper),也就是服务端,避免了重客户端的操作。下面讨论一下这个请求链路的容错及高可用性。
-
客户端配置了所有router的endpoints,单个router失败,客户端也可以请求其他router。另外router本身异常,也会自动进入安全模式而不提供服务。
-
最简单的实现是在每个namenode的机器上部署router,但是为了高可用及灵活性,会使用多个router监控同一个namenode(state store中冲突的信息由quorum解决),这样即使router失败也不会导致有问题。
-
而state store一般会使用zookeeper,所以也不用担心有单点问题。
这样两层都有了高可用及容错。
对于监控的namenode,如果router联系不到了active的namenode,它会首先尝试访问standby namenode,再去访问联系不上的namenode。如果在这个过程中都失败,才会抛出异常。
同样如果在多个心跳周期内收不到namenode的心跳,router会将其状态更新为死亡,直到收到心跳信息才会更新状态。
interface
为了与用户和管理员交互,router暴露了多个接口。
-
rpc:实现了hdfs的大部分接口。比如 snapshot,encryption and tiered storage。
-
admin:这个接口可以让用户通过命令行查询和修改信息。
-
web ui:类似namenode ui一样的可视化界面。展示了mount 和 membership table信息,比如每个子集群、router的状态。
-
webhdfs:提供了hdfs的webhdfs接口。
-
jmx:提供ui提供了一些metric指标。
所有不允许的操作都将会抛出异常。
mount table管理
一个好的建议是将federated namespaces的名字与destination namespaces相同。
可以通过router暴露的admin接口来管理mount table:
[hdfs]$ $hadoop_home/bin/hdfs dfsrouteradmin -add /tmp ns1 /tmp
[hdfs]$ $hadoop_home/bin/hdfs dfsrouteradmin -add /data/app1 ns2 /data/app1
[hdfs]$ $hadoop_home/bin/hdfs dfsrouteradmin -add /data/app2 ns3 /data/app2
[hdfs]$ $hadoop_home/bin/hdfs dfsrouteradmin -ls
也支持设置挂载点只读
[hdfs]$ $hadoop_home/bin/hdfs dfsrouteradmin -add /readonly ns1 / -readonly
如果挂载点没有设置,router默认匹配默认的namespace(dfs.federation.router.default.nameserviceid)
mount table 也有类似linux的权限设置。写权限用户增删改。读权限允许查。默认是755
[hdfs]$ $hadoop_home/bin/hdfs dfsrouteradmin -add /tmp ns1 /tmp -owner root -group supergroup -mode 0755
多个子集群
multiple subclusters:
上面挂载点都是一对一,这里允许单个挂载映射到多个子集群。例如:
[hdfs]$ $hadoop_home/bin/hdfs dfsrouteradmin -add /data ns1,ns2 /data -order space
这样设置,当list该目录时,会展示两个子集群的文件夹及文件。而写入呢?可以看到-order参数,是由它指定的。有以下几个策略:
-
local:尝试写数据到本地子集群
-
random:会在所有子集群中创建文件夹,多个子集群随机写入
-
space:会在所有子集群中创建文件夹,尝试在有更多可用空间的子集群上写数据
-
hash:只对第一层目录采用hash
-
hash_all:会在所有子集群中创建文件夹,对所有层采用hash。这种方法试图均衡各个子集群之间的读和写操作。
举个例子,理解其中的区别:
假设我们有一个/data/hash的hash挂载点,那么/data/hash/folder0下的文件和文件夹都将在同一个子集群中。而对于/data/hash_all的hash_all挂载点将把/data/hash_all/folder0下的文件分散到该挂载点的所有子集群(将为所有子集群创建子文件夹)。
如果要确认文件属于哪个子集群:
[hdfs]$ $hadoop_home/bin/hdfs dfsrouteradmin -getdestination /user/user1/file.txt
router不能保证跨子集群的数据一致性。默认如果一个router失败,在当前子集群的写入可能会失败。
客户端配置
client configuration:
在hdfs-site.xml中。假如集群有四个namespaces,这里还需要增加一个federated namespace(fs.defaultfs)指向router。
<configuration>
<property>
<name>dfs.nameservices</name>
<value>ns0,ns1,ns2,ns3,ns-fed</value>
</property>
<property>
<name>dfs.ha.namenodes.ns-fed</name>
<value>r1,r2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns-fed.r1</name>
<value>router1:rpc-port</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns-fed.r2</name>
<value>router2:rpc-port</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns-fed</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.configuredfailoverproxyprovider</value>
</property>
<property>
<name>dfs.client.failover.random.order</name>
<value>true</value>
</property>
</configuration>
其他关于rbf的配置,配置在hdfs-rbf-default.xml。官网文档列出的很详细。
rbf可支持多个独立的集群、联邦集群或两者混合的集群。同时rbf还支持了quota和security,相对于viewfs功能更强大并且也解决其存在的问题,是一种很好的管理多集群的方式。

发表评论