前言
本文过分割解决办法,主要针对一些目标物在图像中较为分散或比较单一的情况有效。例如血管的过分割,一些杂质颗粒的过分割,较为分散矿石的过分割。如果目标物较为密集也可参考本文,自行改进聚类算法实现过分割的修复。
以下例子为杂质颗粒的过分割修复
1. 过分割分析
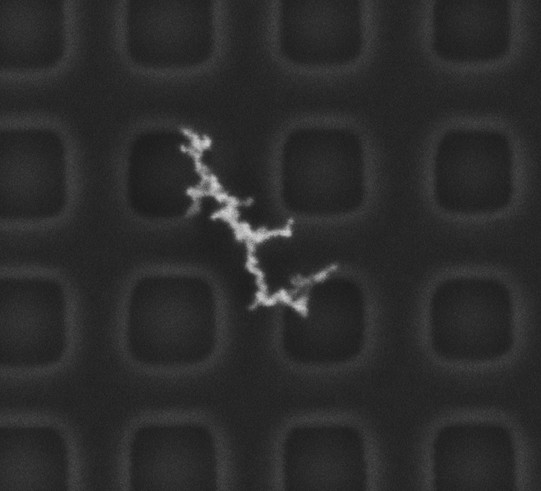 原图 原图
|
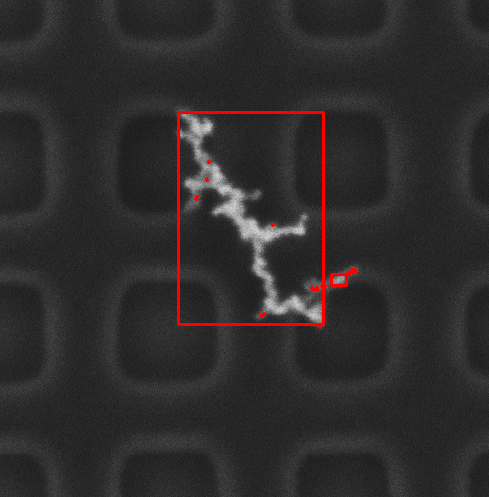 对原图二值化后提取轮廓 对原图二值化后提取轮廓
|
 开运算膨胀后提取轮廓 开运算膨胀后提取轮廓
|
 原图 原图
|
 对原图二值化后提取轮廓 对原图二值化后提取轮廓
|
 开运算膨胀后提取轮廓 开运算膨胀后提取轮廓
|
图中可以看出通过开运算、膨胀后内部一些杂点被消除,但是一些灰度值较低的连接处仍然无法连接在一起,图3中开运算及膨胀采用kernel大小,如下所示:
# 开运算
kernel1 = cv2.getstructuringelement(cv2.morph_ellipse, (3, 3))
# 膨胀
kernel2 = cv2.getstructuringelement(cv2.morph_ellipse, (5, 5))
如果膨胀采用15 x 15的核,效果如下:
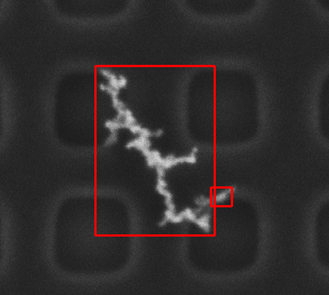
|

|

|
|
2. 聚类算法
思想:遍历所有轮廓,根据每个轮廓重心点的距离减两个轮廓最小外接圆的半径,小于阈值的归为一类
聚类算法过程示意图:
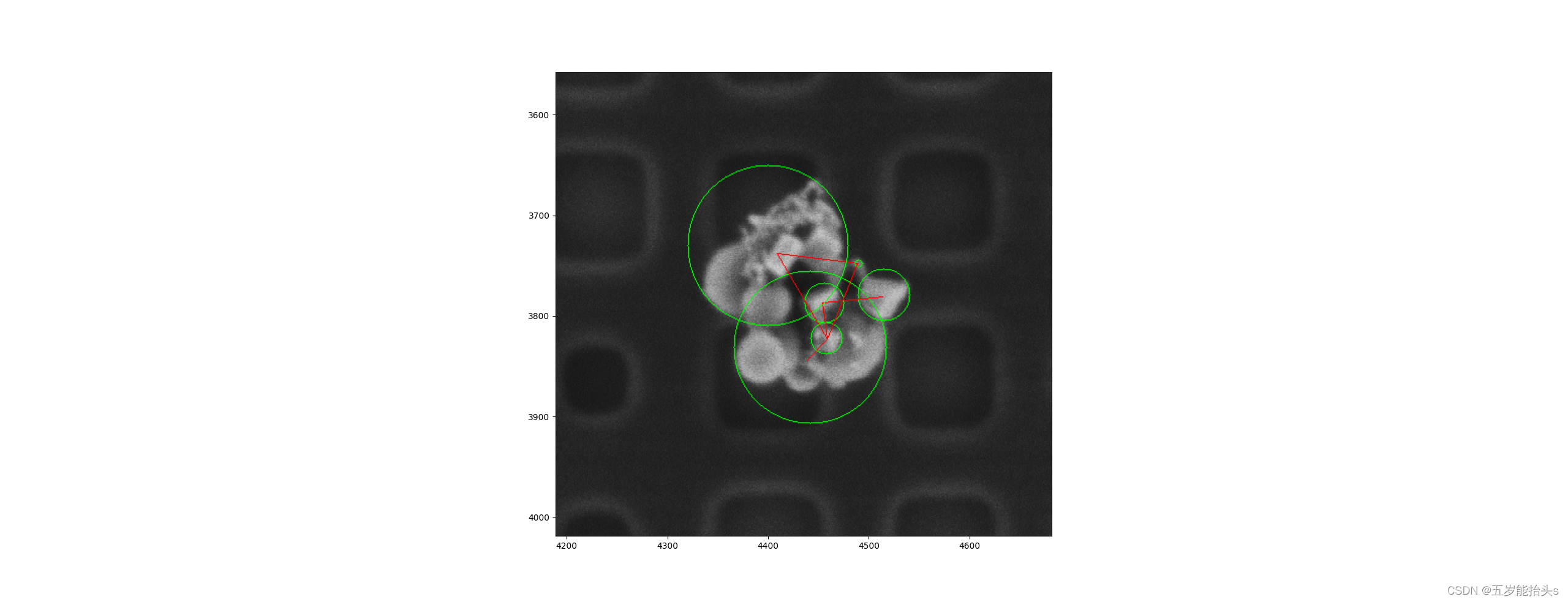
核心代码
# 开运算膨胀,消除二值化图像中小亮点
kernel1 = cv.getstructuringelement(cv.morph_ellipse, (5, 5))
kernel2 = cv.getstructuringelement(cv.morph_ellipse, (3, 3))
image_open = cv.morphologyex(image_thre, cv.morph_open, kernel2, iterations=1)
image_dil = cv.dilate(image_open,kernel1)
_ , contours, hierarchy = cv.findcontours(image_dil, cv.retr_external, cv.chain_approx_simple)
if len(contours) != 0 :
# 距离相近的轮廓聚类,输出轮廓index
cnt_idxs = [[idx] for idx in range(len(contours))] # 轮廓index
pre_len = len(cnt_idxs)
while len(cnt_idxs) > 1:
tmp_cnt_idxs = []
flags = [false] * len(cnt_idxs)
for first in range(len(cnt_idxs)):
for second in range(len(cnt_idxs)):
if first == second or flags[first] or flags[second]:
continue
is_find = false
for fidx in cnt_idxs[first]:
cnt = contours[fidx]
_, radius1 = cv.minenclosingcircle(cnt)
# 获取轮空间矩、中心矩、归一化矩
m = cv.moments(cnt)
# 获取目标重心坐标
cx = int(m["m10"] / m["m00"])
cy = int(m["m01"] / m["m00"])
for sidx in cnt_idxs[second]:
new_cnt = contours[sidx]
m2 = cv.moments(new_cnt)
# 获取目标重心坐标
cx2 = int(m2["m10"] / m2["m00"])
cy2 = int(m2["m01"] / m2["m00"])
_, radius2 = cv.minenclosingcircle(new_cnt)
sq1 = (cx2 - cx) * (cx2 - cx)
sq2 = (cy2 - cy) * (cy2 - cy)
# 两轮廓中心点距离
dist = math.sqrt(sq1 + sq2)
# print("dist:{0:.2f}".format(dist))
if dist - radius2 - radius1 < 30:
is_find = true
tmp_cnt_idxs.append(cnt_idxs[first] + cnt_idxs[second])
flags[first] = flags[second] = true
break
if is_find:
break
for idx, flag in enumerate(flags):
if not flag:
tmp_cnt_idxs.append(cnt_idxs[idx])
cnt_idxs = tmp_cnt_idxs
if pre_len == len(cnt_idxs):
break
else:
pre_len = len(cnt_idxs)
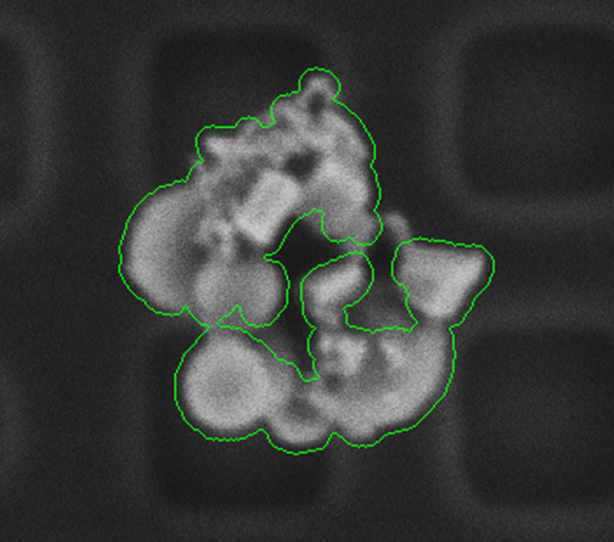
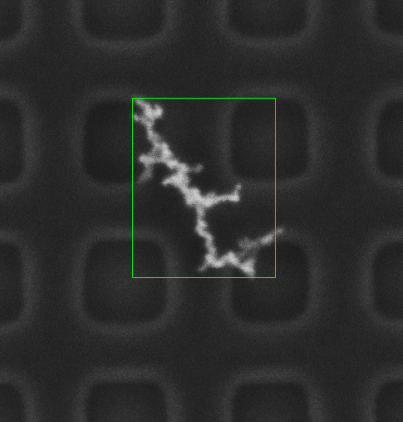
膨胀和本文聚类算法对比
采用膨胀的方法造成轮廓选取偏差较大,影响精准计算
|
|
|
|
|

|

发表评论