博主在之前也写过较多的预测模型的文章,主要是基于lstm,见下:
使用 conv1d-lstm 进行时间序列预测:预测多个未来时间步【优化】
使用 conv1d-lstm 进行时间序列预测:预测多个未来时间步
lstm-理解 part-1(rnn:循环神经网络)
python lstm时序数据的预测(一些数据处理的方法)
机器学习 pytorch实现案例 lstm案例(航班人数预测)
接下来主要是依据回归模型对销售进行预测,见下:
导入库
import pandas as pd
import numpy as np
from sklearn.linear_model import bayesianridge, elasticnet
from sklearn.svm import svr
from xgboost import xgbregressor
from sklearn.ensemble import gradientboostingregressor
from sklearn.preprocessing import standardscaler
from sklearn.metrics import explained_variance_score, mean_absolute_error, \
mean_squared_error, r2_score
import matplotlib.pyplot as plt
from sklearn.model_selection import gridsearchcv
这段代码是python中常见的用于机器学习和数据分析的库的导入。机器学习的库有(bayesianridge和elasticnet线性回归模型类,svr支持向量回归模型,xgbregressor类,gradientboostingregressor类),具体解释如下:
import pandas as pd: 导入pandas库并用别名pd表示,pandas是一个用于数据分析的python库,提供了数据结构和数据分析工具。import numpy as np: 导入numpy库并用别名np表示,numpy是一个python科学计算库,提供了用于数组处理、线性代数、傅里叶变换等方面的函数和工具。from sklearn.linear_model import bayesianridge, elasticnet: 从scikit-learn库中导入bayesianridge和elasticnet线性回归模型类,scikit-learn是一个python机器学习库,提供了各种监督学习和非监督学习算法的实现。from sklearn.svm import svr: 从scikit-learn库中导入svr支持向量回归模型类,支持向量机是一种常见的分类和回归算法。from xgboost import xgbregressor: 从xgboost库中导入xgbregressor类,xgboost是一个流行的梯度提升框架,用于解决分类和回归问题。from sklearn.ensemble import gradientboostingregressor: 从scikit-learn库中导入gradientboostingregressor类,梯度提升回归是一种常见的集成学习算法。from sklearn.preprocessing import standardscaler: 从scikit-learn库中导入standardscaler类,standardscaler是一种数据标准化方法。from sklearn.metrics import explained_variance_score, mean_absolute_error, mean_squared_error, r2_score: 从scikit-learn库中导入解释方差得分、平均绝对误差、均方误差和r平方得分四种回归模型评估指标。import matplotlib.pyplot as plt: 导入matplotlib库并用别名plt表示,matplotlib是一个用于绘图的python库。from sklearn.model_selection import gridsearchcv: 从scikit-learn库中导入gridsearchcv类,用于进行网格搜索,以找到最优的模型超参数组合。
读取数据
这里的数据可私信给作者获取。
raw_data = pd.read_csv('./data/regression.txt', delimiter=' ', header=none) # 读取数据文件
raw_data.head()
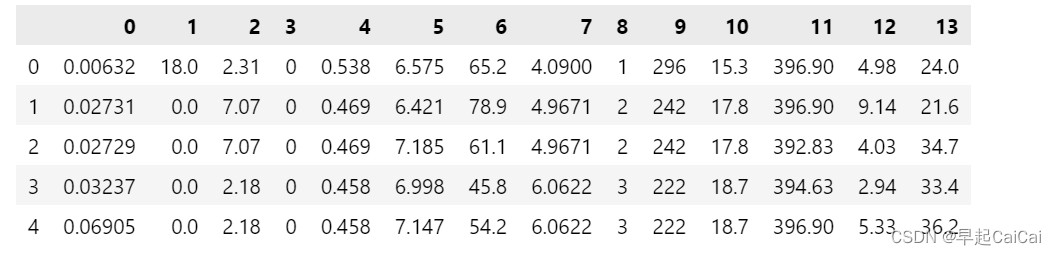
特征工程
# 拆分因变量
x_raw,y = raw_data.iloc[:, :-1],raw_data.iloc[:, -1] # 分割自变量,因变量
# 数据标准化
model_ss = standardscaler()
x = model_ss.fit_transform(x_raw)
x = pd.dataframe(x, columns=raw_data.columns[:-1])
这段代码主要是进行数据预处理,包括拆分因变量和数据标准化两部分,具体解释如下:
x_raw,y = raw_data.iloc[:, :-1],raw_data.iloc[:, -1]: 通过iloc函数从原始数据raw_data中分割出自变量x_raw和因变量y。:, :-1表示选取所有行和除了最后一列之外的所有列作为自变量,[:, -1]表示选取所有行和最后一列作为因变量。这里假设数据的最后一列是因变量列。model_ss = standardscaler(): 创建一个standardscaler对象model_ss,用于进行数据标准化。x = model_ss.fit_transform(x_raw): 使用fit_transform()方法对自变量x_raw进行数据标准化,即对每个特征进行均值为0,方差为1的标准化处理。x = pd.dataframe(x, columns=raw_data.columns[:-1]): 将标准化后的自变量x转换为dataframe对象,并将列名设置为原始数据中除了因变量列之外的列名,即raw_data.columns[:-1]。这里的目的是保持自变量的列名不变,以便于后续的数据分析和建模。
# 样本拆分
num = int(x.shape[0]*0.7)
x_train,x_test = x.iloc[:num,:],x.iloc[num:,:] # 拆分训练集和测试集
y_train,y_test = y[:num],y[num:] # 拆分训练集和测试集
训练集是70%;测试集是30%
数据建模
模型构建
# 初选回归模型
model_names = ['bayesianridge', 'xgbr', 'elasticnet', 'svr', 'gbr'] # 不同模型的名称列表
model_br = bayesianridge() # 贝叶斯岭回归
model_xgbr = xgbregressor(random_state=0) # xgbr
model_etc = elasticnet(random_state=0) # 弹性网络回归
model_svr = svr(gamma='scale') # 支持向量机回归
model_gbr = gradientboostingregressor(random_state=0) # 梯度增强回归
model_list = [model_br, model_xgbr, model_etc,model_svr, model_gbr]
pre_y_list = [model.fit(x_train, y_train).predict(x_test) for model in model_list] # 各个回归模型预测的y值列表
这段代码主要是对几个常用的回归模型进行初步筛选,包括:
model_names = ['bayesianridge', 'xgbr', 'elasticnet', 'svr', 'gbr']: 定义一个列表,包含不同模型的名称。model_br = bayesianridge(): 创建一个贝叶斯岭回归对象model_br。model_xgbr = xgbregressor(random_state=0): 创建一个xgboost回归对象model_xgbr,并指定随机数种子random_state为0。model_etc = elasticnet(random_state=0): 创建一个弹性网络回归对象model_etc,并指定随机数种子random_state为0。model_svr = svr(gamma='scale'): 创建一个支持向量机回归对象model_svr,并指定gamma='scale'表示使用默认的gamma参数。model_gbr = gradientboostingregressor(random_state=0): 创建一个梯度增强回归对象model_gbr,并指定随机数种子random_state为0。model_list = [model_br, model_xgbr, model_etc,model_svr, model_gbr]: 将上述5个回归模型对象存放到列表model_list中。pre_y_list = [model.fit(x_train, y_train).predict(x_test) for model in model_list]: 针对每个回归模型对象,利用fit()方法对训练集进行拟合,然后使用predict()方法对测试集进行预测,最终将预测结果存储在列表pre_y_list中。这里假设已经将原始数据集分成了训练集和测试集,分别为x_train、x_test、y_train、y_test。
模型评估
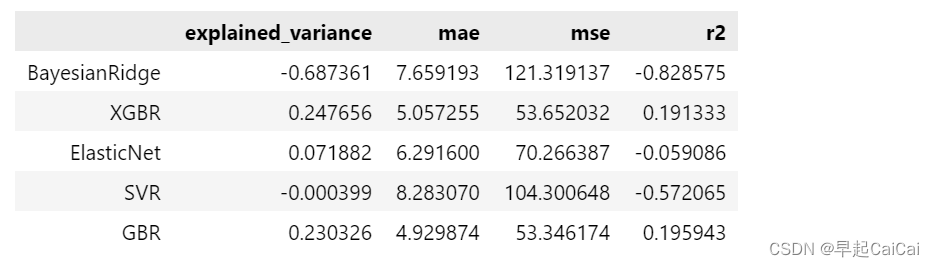
# 模型效果评估
n_samples, n_features = x.shape # 总样本量,总特征数
model_metrics_functions = [explained_variance_score, mean_absolute_error, mean_squared_error,r2_score] # 回归评估指标对象集
model_metrics_list = [[m(y_test, pre_y_list[i]) for m in model_metrics_functions] for i in range(len(model_list))] # 回归评估指标列表
regresstion_score = pd.dataframe(model_metrics_list, index=model_names,
columns=['explained_variance', 'mae', 'mse', 'r2']) # 建立回归指标的数据框
print('all samples: %d \t features: %d' % (n_samples, n_features),'\n','-'*60) # 打印输出样本量和特征数量
regresstion_score # 模型回归指标
结果可视化
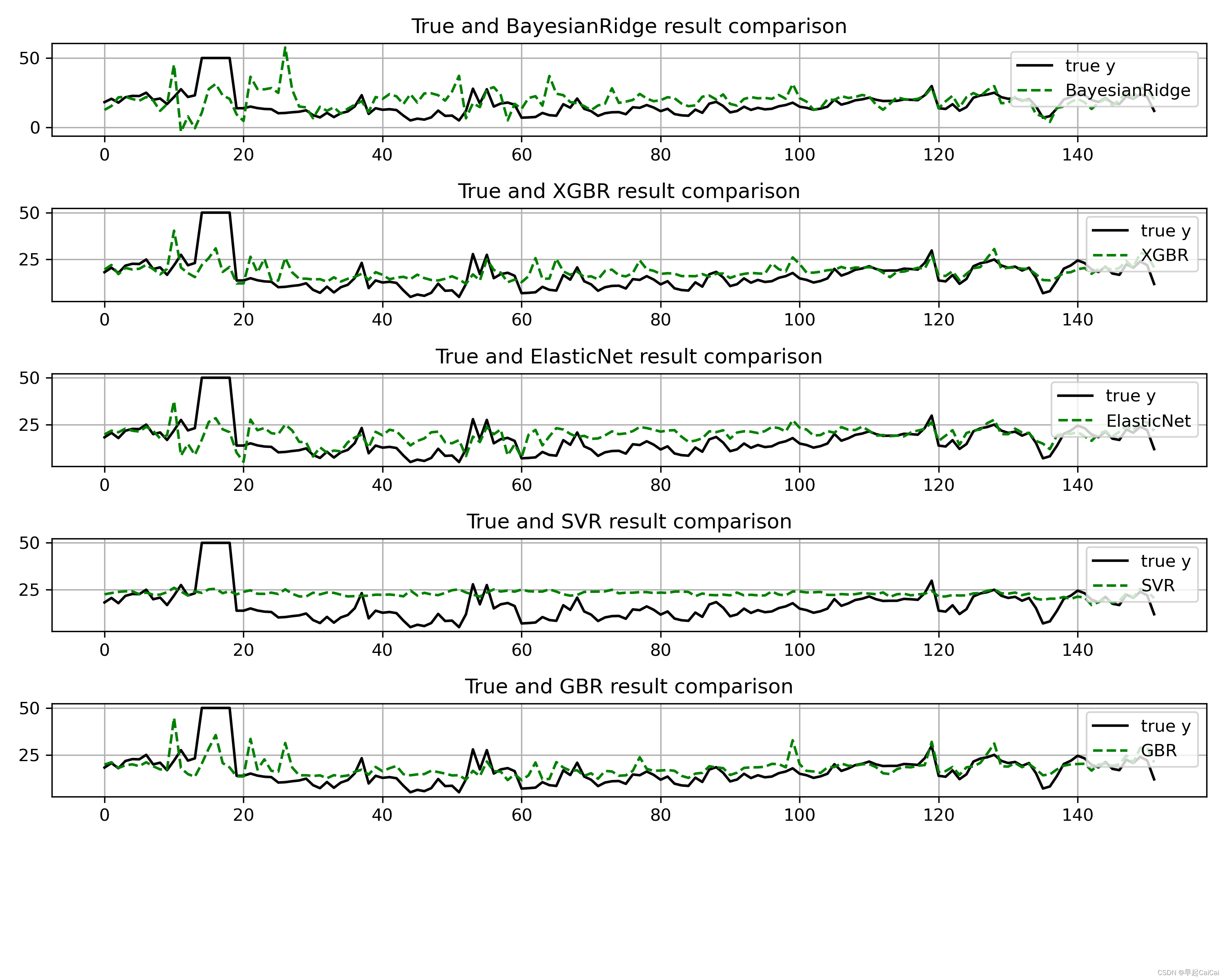
# 模型效果可视化
plt.figure(figsize=(10, 10))
for i, pre_y in enumerate(pre_y_list):
plt.subplot(len(pre_y_list)+1,1,i+1) # 子图6行*1列
plt.plot(np.arange(len(y_test)), y_test, color='k', label='true y')
plt.plot(np.arange(len(y_test)), pre_y_list[i], 'g--', label=model_names[i])
plt.title('true and {} result comparison'.format(model_names[i]))
plt.legend(loc='upper right')
plt.grid()
plt.tight_layout() # 自动调整子图间隔
plt.savefig(fname="./demo_1.png", dpi=300)
plt.show()
模型优化
上述初始模型xgbr与gbr表现较优。这里以xgbr为例进行网格搜索+交叉验证
clf = xgbregressor(random_state=0) # 建立gradientboostingregressor回归对象,该模型较好处理特征量纲与共线性问题
parameters = {
'n_estimators': [10, 50, 100, 500],
'learning_rate': [0.05, 0.1, 0.3, 0.5],
'max_depth': [5, 6, 7, 10]} # 定义要优化的参数信息
model_gs = gridsearchcv(estimator=clf,
param_grid=parameters, cv=5, scoring='r2', n_jobs=-1) # 建立交叉检验模型对象
model_gs.fit(x_train, y_train) # 训练交叉检验模型
print('best score is:', model_gs.best_score_) # 获得交叉检验模型得出的最优得分
print('best parameter is:', model_gs.best_params_) # 获得交叉检验模型得出的最优参数

用最佳训练模型预测数据
model_xgbr = model_gs.best_estimator_ # 获得交叉检验模型得出的最优模型对象
pre_y = model_xgbr.predict(x_test)
评估模型效果,结果是优于上次的
model_metrics_list = [[m(y_test, pre_y) for m in model_metrics_functions]] # 回归评估指标列表
regresstion_score = pd.dataframe(model_metrics_list, index=['model_xgbr'],
columns=['explained_variance', 'mae', 'mse', 'r2']) # 建立回归指标的数据框
regresstion_score # 模型回归指标

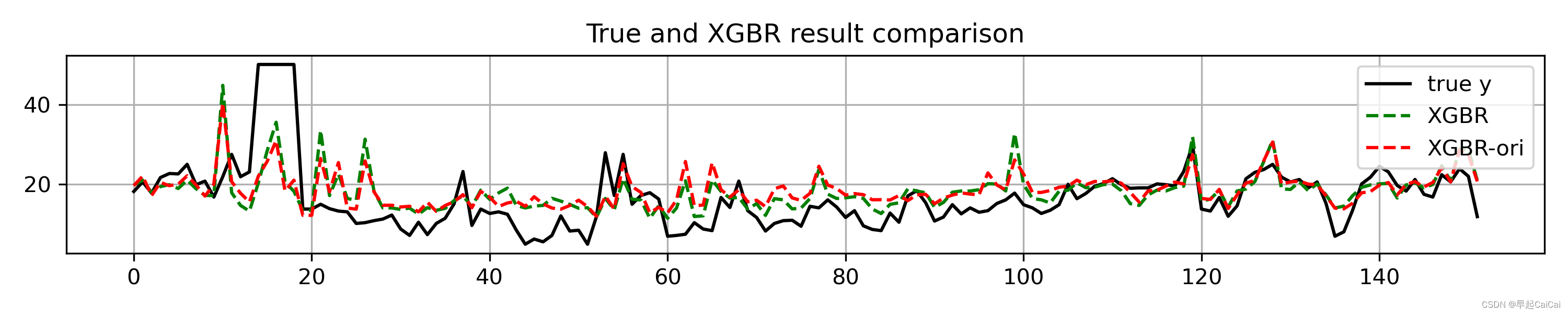
模型结果可视化:
plt.figure(figsize=(10, 2)) # 创建画布
plt.plot(np.arange(len(y_test)), y_test, color='k', label='true y') # 画出原始值的曲线
plt.plot(np.arange(len(y_test)), pre_y, 'g--', label='xgbr') # 画出每条预测结果线
plt.title('true and {} result comparison'.format('xgbr')) # 标题
plt.legend(loc='upper right') # 图例位置
plt.tight_layout() # 自动调整子图间隔
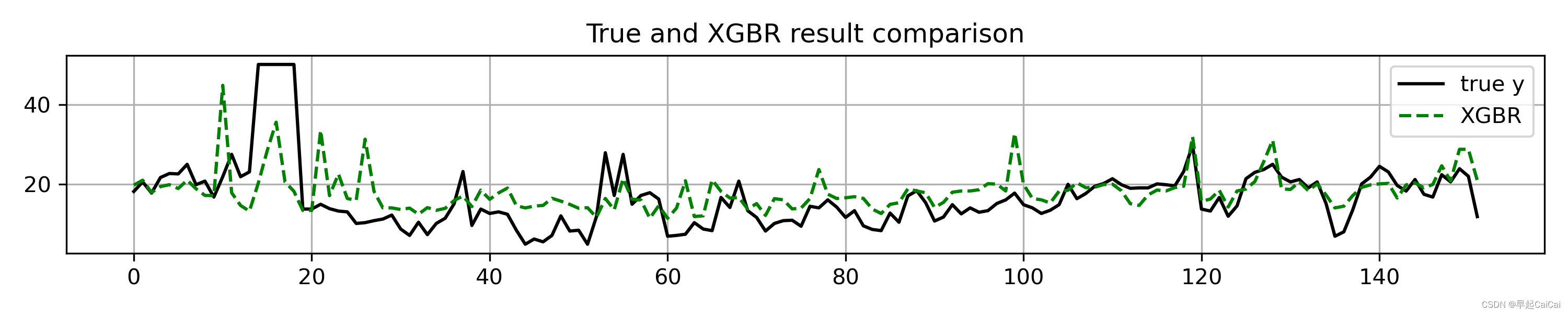
pass:一些可视化的优化,第二张图可添加未改良之前的线。见下:

发表评论