1.背景介绍
数据挖掘和机器学习是两种处理大量数据以发现隐藏模式、规律和知识的技术。它们在现实生活中的应用非常广泛,包括商业分析、金融风险控制、医疗诊断、人工智能等领域。然而,这两种技术在理论和实践上存在一定的区别和联系,本文将从以下几个方面进行探讨:
- 背景介绍
- 核心概念与联系
- 核心算法原理和具体操作步骤以及数学模型公式详细讲解
- 具体代码实例和详细解释说明
- 未来发展趋势与挑战
- 附录常见问题与解答
1.1 数据挖掘的背景
数据挖掘是指从大量数据中发现有价值的信息和知识的过程。它的主要目标是从数据中发现新的规律、模式和关系,以便为企业和组织提供有价值的决策支持。数据挖掘的应用范围广泛,包括市场分析、金融风险控制、医疗诊断、人工智能等领域。
数据挖掘的核心技术包括数据清洗、数据集成、数据挖掘算法等。数据清洗是指从数据中去除噪声、缺失值、重复值等不良数据,以便进行有效的数据挖掘。数据集成是指将来自不同来源的数据集成为一个整体,以便进行更全面的数据挖掘。数据挖掘算法是指用于从数据中发现规律和模式的算法,如决策树、聚类分析、关联规则等。
1.2 机器学习的背景
机器学习是指使计算机程序在不被明确编程的情况下自动学习和改进其表现的过程。它的主要目标是让计算机程序能够从数据中自主地学习出规律、模式和关系,以便进行更智能的决策和操作。机器学习的应用范围也广泛,包括语音识别、图像识别、自然语言处理、人工智能等领域。
机器学习的核心技术包括机器学习算法、机器学习模型、机器学习评估等。机器学习算法是指用于从数据中学习出规律和模式的算法,如支持向量机、回归分析、逻辑回归等。机器学习模型是指用于表示计算机程序所学习出的规律和模式的结构,如决策树、神经网络、随机森林等。机器学习评估是指用于评估计算机程序所学习出的规律和模式的准确性和效果的方法,如交叉验证、精度、召回等。
2.核心概念与联系
2.1 数据挖掘与机器学习的区别
数据挖掘和机器学习是两种处理大量数据以发现隐藏模式、规律和知识的技术,但它们在理论和实践上存在一定的区别。主要区别如下:
数据挖掘的目标是从数据中发现新的规律、模式和关系,以便为企业和组织提供有价值的决策支持。机器学习的目标是让计算机程序能够从数据中自主地学习出规律、模式和关系,以便进行更智能的决策和操作。
数据挖掘主要关注的是数据的质量和完整性,包括数据清洗、数据集成等。机器学习主要关注的是算法的效果和性能,包括机器学习算法、机器学习模型、机器学习评估等。
数据挖掘通常关注的是结构化数据,如关系型数据库、数据仓库等。机器学习通常关注的是非结构化数据,如文本、图像、音频等。
数据挖掘通常需要人工参与,如规则的解释、模式的验证等。机器学习通常是自动进行的,无需人工参与。
2.2 数据挖掘与机器学习的联系
尽管数据挖掘和机器学习在理论和实践上存在一定的区别,但它们在实际应用中存在一定的联系。主要联系如下:
数据挖掘和机器学习都需要大量的数据进行支持。数据挖掘需要大量的结构化数据进行挖掘,而机器学习需要大量的非结构化数据进行训练。
数据挖掘和机器学习都需要算法进行支持。数据挖掘需要数据挖掘算法进行挖掘,而机器学习需要机器学习算法进行学习。
数据挖掘和机器学习都需要模型进行支持。数据挖掘需要数据挖掘模型进行表示,而机器学习需要机器学习模型进行表示。
数据挖掘和机器学习都需要评估进行支持。数据挖掘需要数据挖掘评估进行评估,而机器学习需要机器学习评估进行评估。
3.核心算法原理和具体操作步骤以及数学模型公式详细讲解
3.1 数据挖掘算法
3.1.1 决策树
决策树是一种用于解决分类和回归问题的算法,它将问题空间划分为多个子空间,每个子空间对应一个决策节点,最终导致一个预测结果。决策树的构建过程包括以下步骤:
- 选择一个特征作为根节点。
- 根据该特征将数据集划分为多个子集。
- 对于每个子集,重复步骤1和步骤2,直到满足停止条件。
- 返回最终的决策树。
决策树的数学模型公式为:
$$ f(x) = argmaxc \sum{i=1}^n i(y_i = c)p(c|x) $$
其中,$f(x)$ 表示预测结果,$c$ 表示类别,$n$ 表示数据集大小,$i(yi = c)$ 表示如果 $yi$ 等于 $c$ 则为1,否则为0,$p(c|x)$ 表示给定 $x$ 时,类别 $c$ 的概率。
3.1.2 聚类分析
聚类分析是一种用于解决无监督学习问题的算法,它将数据集划分为多个簇,使得同一簇内的数据点相似度高,不同簇内的数据点相似度低。聚类分析的构建过程包括以下步骤:
- 选择一个初始的聚类中心。
- 根据距离度量计算每个数据点与聚类中心的距离。
- 将每个数据点分配给最近的聚类中心。
- 更新聚类中心。
- 重复步骤2和步骤3,直到满足停止条件。
- 返回最终的聚类结果。
聚类分析的数学模型公式为:
$$ c = argmaxc \sum{i=1}^n \max{ci \in c} sim(xi, ci) $$
其中,$c$ 表示簇,$ci$ 表示数据点 $xi$ 所属的簇,$sim(xi, ci)$ 表示数据点 $xi$ 和簇 $ci$ 的相似度。
3.1.3 关联规则
关联规则是一种用于发现数据集中隐藏的关联关系的算法,它可以发现两个或多个项目之间的关联关系。关联规则的构建过程包括以下步骤:
- 计算项目的频率。
- 计算支持度。
- 计算信息增益。
- 选择频率最高的项目。
- 计算条件频率。
- 更新项目集。
- 重复步骤4和步骤5,直到满足停止条件。
- 返回最终的关联规则。
关联规则的数学模型公式为:
$$ p(a \rightarrow b) = p(a \cup b) - p(a)p(b) $$
其中,$p(a \rightarrow b)$ 表示条件概率,$p(a \cup b)$ 表示$a$和$b$的联合概率,$p(a)$ 表示$a$的概率,$p(b)$ 表示$b$的概率。
3.2 机器学习算法
3.2.1 支持向量机
支持向量机是一种用于解决分类和回归问题的算法,它通过在特征空间中找到最大间隔来将数据分类。支持向量机的构建过程包括以下步骤:
- 计算类别间的间隔。
- 计算支持向量。
- 计算决策函数。
- 返回最终的支持向量机模型。
支持向量机的数学模型公式为:
$$ f(x) = sign(\sum{i=1}^n \alphai yi k(xi, x) + b) $$
其中,$f(x)$ 表示预测结果,$yi$ 表示类别,$k(xi, x)$ 表示核函数,$b$ 表示偏置项。
3.2.2 回归分析
回归分析是一种用于解决回归问题的算法,它通过拟合数据点的关系来预测目标变量的值。回归分析的构建过程包括以下步骤:
- 计算平均值。
- 计算协方差。
- 计算相关系数。
- 计算回归方程。
- 返回最终的回归分析模型。
回归分析的数学模型公式为:
$$ y = \beta0 + \beta1 x1 + \beta2 x2 + \cdots + \betan x_n + \epsilon $$
其中,$y$ 表示目标变量的值,$xi$ 表示特征变量,$\betai$ 表示权重,$\epsilon$ 表示误差项。
3.2.3 逻辑回归
逻辑回归是一种用于解决分类问题的算法,它通过拟合数据点的关系来预测目标变量的值。逻辑回归的构建过程包括以下步骤:
- 计算平均值。
- 计算协方差。
- 计算相关系数。
- 计算逻辑回归方程。
- 返回最终的逻辑回归模型。
逻辑回归的数学模型公式为:
$$ p(y=1|x) = \frac{1}{1 + e^{-(\beta0 + \beta1 x1 + \beta2 x2 + \cdots + \betan x_n)}} $$
其中,$p(y=1|x)$ 表示给定特征向量$x$时,目标变量$y$为1的概率,$e$ 表示基数。
4.具体代码实例和详细解释说明
4.1 决策树
```python from sklearn.tree import decisiontreeclassifier
训练数据
xtrain = [[1, 2], [3, 4], [5, 6], [7, 8]] ytrain = [0, 1, 0, 1]
测试数据
xtest = [[2, 3], [4, 5], [6, 7], [8, 9]] ytest = [0, 1, 0, 1]
创建决策树模型
clf = decisiontreeclassifier()
训练决策树模型
clf.fit(xtrain, ytrain)
预测测试数据
ypred = clf.predict(xtest)
评估准确率
accuracy = sum(ypred == ytest) / len(y_test) print("准确率:", accuracy) ```
4.2 聚类分析
```python from sklearn.cluster import kmeans
训练数据
x_train = [[1, 2], [3, 4], [5, 6], [7, 8]]
指定聚类数
k = 2
创建kmeans模型
kmeans = kmeans(n_clusters=k)
训练kmeans模型
kmeans.fit(x_train)
预测聚类中心
clustercenters = kmeans.clustercenters_
预测聚类标签
clusterlabels = kmeans.labels
打印聚类结果
print("聚类中心:", clustercenters) print("聚类标签:", clusterlabels) ```
4.3 关联规则
```python from mlxtend.frequentpatterns import associationrules from mlxtend.frequent_patterns import apriori
训练数据
data = [[1, 0], [1, 1], [0, 1], [0, 0]]
创建频繁项集模型
frequentitemsets = apriori(data, minsupport=0.5, use_colnames=true)
创建关联规则模型
rules = associationrules(frequentitemsets, metric="confidence", min_threshold=0.5)
打印关联规则
print(rules) ```
4.4 支持向量机
```python from sklearn.svm import svc
训练数据
xtrain = [[1, 2], [3, 4], [5, 6], [7, 8]] ytrain = [0, 1, 0, 1]
测试数据
xtest = [[2, 3], [4, 5], [6, 7], [8, 9]] ytest = [0, 1, 0, 1]
创建支持向量机模型
svm = svc(kernel='linear')
训练支持向量机模型
svm.fit(xtrain, ytrain)
预测测试数据
ypred = svm.predict(xtest)
评估准确率
accuracy = sum(ypred == ytest) / len(y_test) print("准确率:", accuracy) ```
4.5 回归分析
```python from sklearn.linear_model import linearregression
训练数据
xtrain = [[1, 2], [3, 4], [5, 6], [7, 8]] ytrain = [2, 4, 6, 8]
测试数据
xtest = [[2, 3], [4, 5], [6, 7], [8, 9]] ytest = [3, 5, 7, 9]
创建回归分析模型
lr = linearregression()
训练回归分析模型
lr.fit(xtrain, ytrain)
预测测试数据
ypred = lr.predict(xtest)
打印预测结果
print("预测结果:", y_pred) ```
4.6 逻辑回归
```python from sklearn.linear_model import logisticregression
训练数据
xtrain = [[1, 2], [3, 4], [5, 6], [7, 8]] ytrain = [0, 1, 0, 1]
测试数据
xtest = [[2, 3], [4, 5], [6, 7], [8, 9]] ytest = [0, 1, 0, 1]
创建逻辑回归模型
logistic_regression = logisticregression()
训练逻辑回归模型
logisticregression.fit(xtrain, y_train)
预测测试数据
ypred = logisticregression.predict(x_test)
评估准确率
accuracy = sum(ypred == ytest) / len(y_test) print("准确率:", accuracy) ```
5.未来发展
数据挖掘和机器学习是两个快速发展的领域,未来的发展方向包括以下几个方面:
大数据处理:随着数据量的增加,数据挖掘和机器学习算法需要更高效地处理大数据。
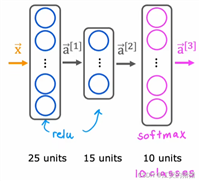
深度学习:深度学习是机器学习的一个子领域,它通过多层神经网络来解决复杂问题。未来,深度学习将在数据挖掘和机器学习中发挥越来越重要的作用。
自动机器学习:自动机器学习是一种通过自动化机器学习过程来减少人工参与的方法。未来,自动机器学习将在数据挖掘和机器学习中发挥越来越重要的作用。
解释性机器学习:解释性机器学习是一种通过提供可解释的模型来解释机器学习模型的决策过程的方法。未来,解释性机器学习将在数据挖掘和机器学习中发挥越来越重要的作用。
跨学科合作:数据挖掘和机器学习将与其他学科领域进行更紧密的合作,如生物信息学、金融市场、医疗保健等,为各个领域提供更多的价值。
6.附加问题及答案
附加问题1:什么是数据挖掘?
数据挖掘是一种通过从大量数据中发现隐藏的模式、规律和知识的过程,以便为组织和个人提供有价值的信息。数据挖掘涉及到数据清洗、数据集成、数据转换、数据挖掘算法和数据挖掘应用等多个环节。
附加问题2:什么是机器学习?
机器学习是一种通过从数据中学习规律并自动改进的方法,使计算机能够自主地进行决策和预测。机器学习涉及到机器学习算法、机器学习模型、机器学习评估等多个环节。
附加问题3:数据挖掘与机器学习的区别是什么?
数据挖掘和机器学习的主要区别在于数据挖掘关注于发现隐藏的模式和规律,而机器学习关注于通过学习这些模式和规律来自动进行决策和预测。数据挖掘可以看作是机器学习的一种特殊情况,它将数据转化为有价值的信息,为机器学习提供了更好的数据。
附加问题4:数据挖掘与数据科学的区别是什么?
数据挖掘是数据科学的一个子领域,它关注于从大量数据中发现隐藏的模式和规律。数据科学则是一种跨学科的领域,它涉及到数据挖掘、统计学、机器学习、人工智能等多个领域的知识和技术。数据科学的目标是通过数据驱动的方法来解决实际问题。
附加问题5:机器学习与人工智能的区别是什么?
机器学习是人工智能的一个子领域,它关注于通过学习从数据中自主地进行决策和预测。人工智能则是一种通过模拟人类智能来创建智能机器的学科。人工智能涉及到知识表示、推理、学习、语言理解等多个环节。机器学习是人工智能的一个重要组成部分,但它们之间的范围和目标有所不同。
参考文献
[1] han, j., kamber, m., pei, j., & steinbach, m. (2012). data mining: concepts and techniques. morgan kaufmann.
[2] mitchell, t. m. (1997). machine learning. mcgraw-hill.
[3] bishop, c. m. (2006). pattern recognition and machine learning. springer.
[4] tan, b., steinbach, m., & kumar, v. (2006). introduction to data mining. prentice hall.
[5] dumm, r. (2016). data mining for the business analyst. wiley.
[6] hastie, t., tibshirani, r., & friedman, j. (2009). the elements of statistical learning: data mining, inference, and prediction. springer.
[7] james, g., witten, d., hastie, t., & tibshirani, r. (2013). an introduction to statistical learning with applications in r. springer.
[8] russell, s., & norvig, p. (2016). artificial intelligence: a modern approach. prentice hall.
[9] goodfellow, i., bengio, y., & courville, a. (2016). deep learning. mit press.
[10] kelleher, k., & kelleher, c. (2015). data mining: practical machine learning tools and techniques. elsevier.
[11] shalev-shwartz, s., & ben-david, y. (2014). understanding machine learning: from theory to algorithms. cambridge university press.
[12] murphy, k. p. (2012). machine learning: a probabilistic perspective. mit press.
[13] nielsen, l. (2015). neural networks and deep learning. coursera.
[14] caruana, r. (2006). towards a theory of machine learning. journal of machine learning research, 7, 1599-1635.
[15] breiman, l. (2001). random forests. machine learning, 45(1), 5-32.
[16] friedman, j., hastie, t., & tibshirani, r. (2000). stochastic gradient lazy kernel approximation for support vector machines. journal of machine learning research, 1, 199-228.
[17] vapnik, v. n. (1998). the nature of statistical learning theory. springer.
[18] duda, r. o., hart, p. e., & stork, d. g. (2001). pattern classification. wiley.
[19] bishop, c. m. (2006). pattern recognition and machine learning. springer.
[20] hastie, t., tibshirani, r., & friedman, j. (2009). the elements of statistical learning: data mining, inference, and prediction. springer.
[21] james, g., witten, d., hastie, t., & tibshirani, r. (2013). an introduction to statistical learning with applications in r. springer.
[22] goodfellow, i., bengio, y., & courville, a. (2016). deep learning. mit press.
[23] kelleher, k., & kelleher, c. (2015). data mining: practical machine learning tools and techniques. elsevier.
[24] shalev-shwartz, s., & ben-david, y. (2014). understanding machine learning: from theory to algorithms. cambridge university press.
[25] murphy, k. p. (2012). machine learning: a probabilistic perspective. mit press.
[26] nielsen, l. (2015). neural networks and deep learning. coursera.
[27] caruana, r. (2006). towards a theory of machine learning. journal of machine learning research, 7, 1599-1635.
[28] breiman, l. (2001). random forests. machine learning, 45(1), 5-32.
[29] friedman, j., hastie, t., & tibshirani, r. (2000). stochastic gradient lazy kernel approximation for support vector machines. journal of machine learning research, 1, 199-228.
[30] vapnik, v. n. (1998). the nature of statistical learning theory. springer.
[31] duda, r. o., hart, p. e., & stork, d. g. (2001). pattern classification. wiley.
[32] bishop, c. m. (2006). pattern recognition and machine learning. springer.
[33] hastie, t., tibshirani, r., & friedman, j. (2009). the elements of statistical learning: data mining, inference, and prediction. springer.
[34] james, g., witten, d., hastie, t., & tibshirani, r. (2013). an introduction to statistical learning with applications in r. springer.
[35] goodfellow, i., bengio, y., & courville, a. (2016). deep learning. mit press.
[36] kelleher, k., & kelleher, c. (2015). data mining: practical machine learning tools and techniques. elsevier.
[37] shalev-shwartz, s., & ben-david, y. (2014). understanding machine learning: from theory to algorithms. cambridge university press.
[38] murphy, k. p. (2012). machine learning: a probabilistic perspective. mit press.
[39] nielsen, l. (2015). neural networks and deep learning. coursera.
[40] caruana, r. (2006). towards a theory of machine learning. journal of machine learning research, 7, 1599-1635.
[41] breiman, l. (2001). random forests. machine learning, 45(1), 5-32.
[42] friedman, j., hastie, t., & tibshirani, r. (2000). stochastic gradient lazy kernel approximation for support vector machines. journal of machine learning research, 1, 199-228.
[43] vapnik, v. n. (1998). the nature of statistical learning theory. springer.
[44] duda, r. o., hart, p. e., & stork, d. g. (2001). pattern classification. wiley.
[45] bishop, c. m. (2006). pattern recognition and machine learning. springer.
[46] hastie, t., tibshirani, r., & friedman, j. (2009). the elements of statistical learning: data mining, inference, and prediction. springer.
[47] james, g., witten, d., hastie, t.,


发表评论