一.开发环境及第三方库
python=3.7以上
第三方库torch torchvision
from pil import image
import numpy as np
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim二.加载mnist数据集
# 加载mnist数据集
transform = transforms.compose([transforms.totensor(), transforms.normalize((0.5,), (0.5,))])
trainset = torchvision.datasets.mnist(root='./data', train=true, download=true, transform=transform)
trainloader = torch.utils.data.dataloader(trainset, batch_size=4, shuffle=true)这段代码是一个是一个基于mnist数据集的神经网络模型,将数据转换为张量并且对数据进行归一化处理,使用torchvision.databases.mnist函数进行数据下载存储。第三行代码创建一个训练数据加载器,设置每个批次大小为4,并且对数据进行随机打乱。
三.构建神经网络模型
class net(nn.module):
def __init__(self):
super(net, self).__init__()
self.fc1 = nn.linear(28*28, 128)
self.fc2 = nn.linear(128, 64)
self.fc3 = nn.linear(64, 10)
def forward(self, x):
x = x.view(-1, 28*28)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
net = net()创建net类继承pytorch中的nn.module,在初始化方法中,定义三个全连接层fc1,fc2,fc3,fc1的输入为28*28,输出为128,fc2的输入为128,输出为64,fc3的输入为64,输出为10。
在forward方法中,首先对输入的x进行reshape操作,将其变换为二维张量,大小为(-1, 28*28),其中-1表示该维度的大小由数据自动推断得出。接着,将经过第一个全连接层fc1的计算结果通过relu激活函数处理,得到激活后的输出。然后,将这个输出再经过第二个全连接层fc2和relu激活函数处理,得到新的输出。最后,将这个输出通过最后一个全连接层fc3,得到最终的输出结果。
四.定义损失函数和优化器
criterion = nn.crossentropyloss()
optimizer = optim.sgd(net.parameters(), lr=0.001, momentum=0.9)
损失函数在机器学习和深度学习中用于衡量模型预测结果与真实标签之间的差异或错误程度。通过最小化损失函数的值,可以使模型的预测结果更接近真实标签,从而提高模型的准确性和性能。定义优化器,优化器的作用是帮助模型更快地收敛到最优解,提高模型的训练速度和性能。
五.训练网络模型
for epoch in range(6): # 5个epoch
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('finished training')遍历5个epoch,将初始的损失函数的值设为零,将优化器的梯度也归零。对于每个batch,获取输入数据和标签,将输入数据输入到神经网络中,得到输出的模型。
计算模型输出与标签之间的损失值,根据损失值计算梯度进行反向传播,根据此代码来说,进行五次便利,每组值处理两千个数据时就计算并且输出平均损失值。
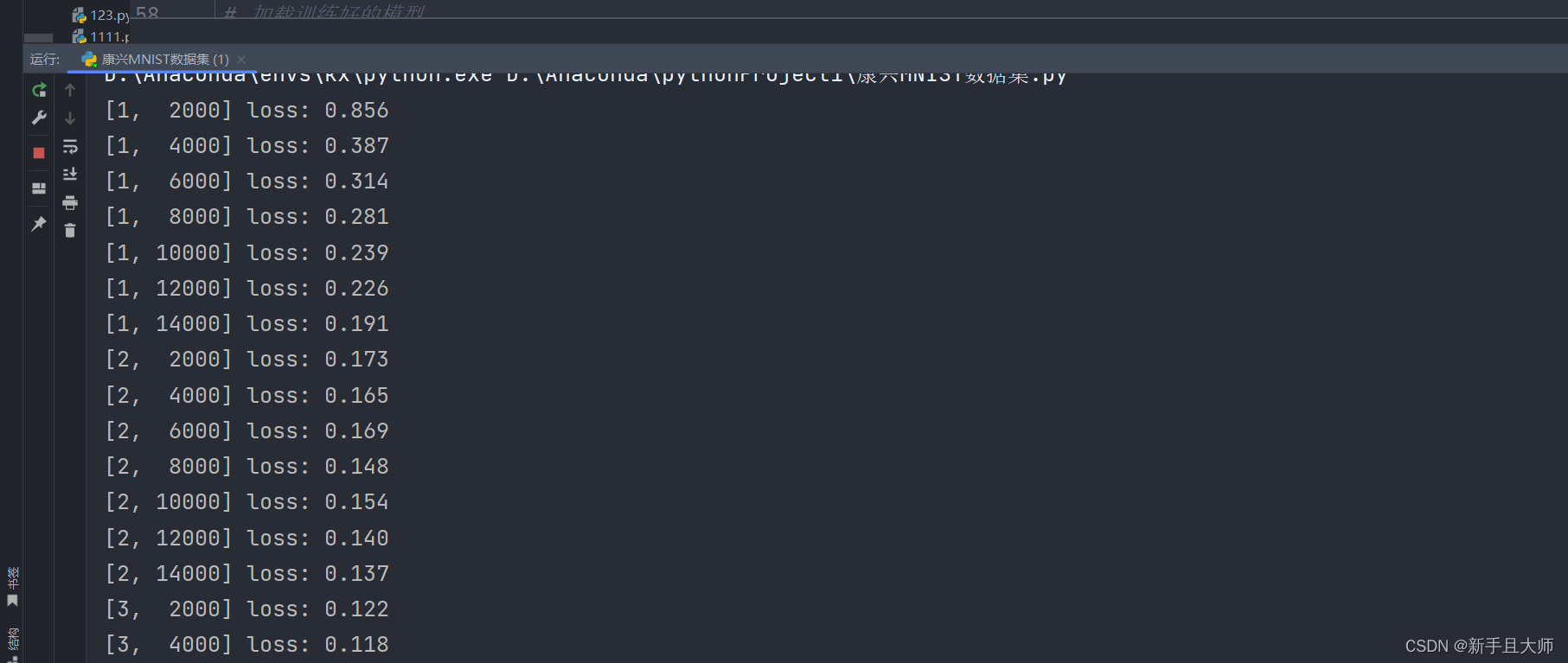
在此运行结构可以看出损失值平均值不断在下降,说明模型拟合成功,每个epoch运行14000次,运行六次,每次继承上一次的结果,不断优化模型,损失率由0.856降为0.08。
六.处理手写数字图片并进行预测
def preprocess_image(image_path):
image = image.open(image_path).convert('l') # 转为灰度图
transform = transforms.compose([transforms.resize((28, 28)),
transforms.totensor(),
transforms.normalize((0.5,), (0.5,))])
image = transform(image)
image = image.unsqueeze(0) # 添加一个维度作为batch
return image
image_path = '屏幕截图 2024-03-25 200951.png'
input_image = preprocess_image(image_path)
output = model(input_image)
predicted_class = np.argmax(output.detach().numpy())1.预处理图像
打开图片,将图片转换为灰度图像,并且将图片大小调整为28*28像素,与我们上面所构建的神经网络模型相匹配,并且将图像转换为张量格式,对图像进行标准化处理,将像素值缩放到范围【-1,1】
2.进行预测
将预处理后的图像输入神经网络模型model进行推理,得到输出结果output。np.argmax()找到数组中最大的索引,为模型预测类别。
七.完整代码
from pil import image
import numpy as np
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
# 加载mnist数据集
transform = transforms.compose([transforms.totensor(), transforms.normalize((0.5,), (0.5,))])
trainset = torchvision.datasets.mnist(root='./data', train=true, download=true, transform=transform)
trainloader = torch.utils.data.dataloader(trainset, batch_size=4, shuffle=true)
# 构建神经网络模型
class net(nn.module):
def __init__(self):
super(net, self).__init__()
self.fc1 = nn.linear(28*28, 128)
self.fc2 = nn.linear(128, 64)
self.fc3 = nn.linear(64, 10)
def forward(self, x):
x = x.view(-1, 28*28)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
net = net()
# 定义损失函数和优化器
criterion = nn.crossentropyloss()
optimizer = optim.sgd(net.parameters(), lr=0.001, momentum=0.9)
# 训练网络
for epoch in range(5): # 5个epoch
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()#优化器梯度归零
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()#计算梯度值,利用优化算法更新模型参数
optimizer.step()
running_loss += loss.item()#损失值累加
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('finished training')
# 保存模型
path = './mnist_net.pth'
torch.save(net.state_dict(), path)
# 加载训练好的模型
model = net()
model.load_state_dict(torch.load(path))
model.eval()
# 处理输入的手写数字图片
def preprocess_image(image_path):
image = image.open(image_path).convert('l') # 转为灰度图
transform = transforms.compose([transforms.resize((28, 28)),
transforms.totensor(),
transforms.normalize((0.5,), (0.5,))])
image = transform(image)
image = image.unsqueeze(0) # 添加一个维度作为batch
return image
# 在编译器中输入手写数字图片的路径
image_path = '屏幕截图 2024-03-25 200951.png'
# 使用模型进行预测
input_image = preprocess_image(image_path)
output = model(input_image)
predicted_class = np.argmax(output.detach().numpy())
# 显示预测结果
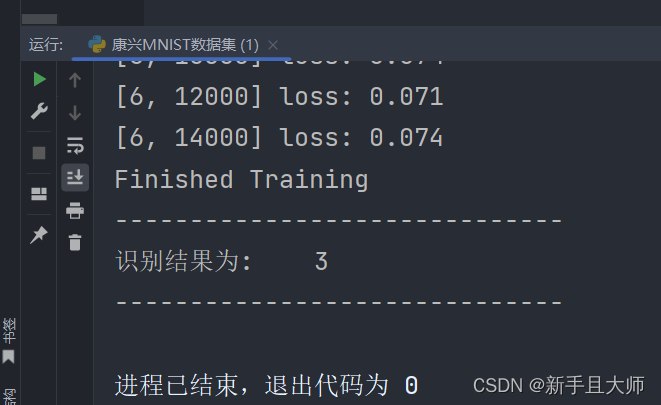
print("识别结果为:", predicted_class)
八.总结
这段代码实现了加载mnist数据集、构建神经网络模型、训练模型、保存模型、加载模型以及对输入的手写数字图片进行预测的功能。在实测之后能正确的识别图片上的数字。

发表评论