

🌈个人主页: 鑫宝code
🔥热门专栏: | 炫酷html | javascript基础
💫个人格言: "如无必要,勿增实体"

文章目录
独立成分分析(ica):解锁信号的隐秘面纱
引言
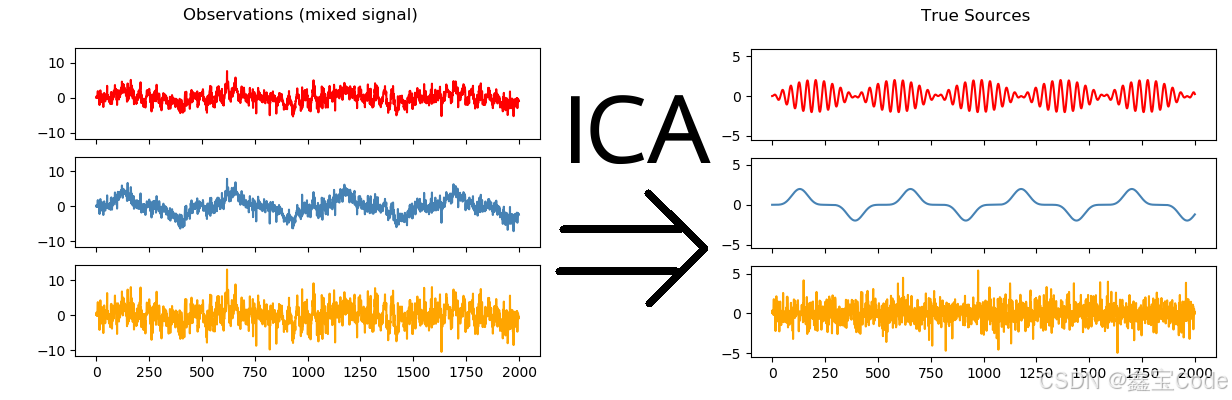
在当今数据驱动的世界中,信号处理和数据分析面临着前所未有的挑战。特别是在处理混合信号时,如何从复杂的混合体中分离出纯净的源信号,成为了研究的热点。独立成分分析(independent component analysis,ica)作为一种先进的信号处理技术,以其独特的理论基础和广泛的适用性,逐渐成为了信号分离和盲源分离领域的一颗璀璨明珠。本文旨在深入探讨ica的原理、算法、应用及其与主成分分析(pca)的区别,为读者提供一个全面的ica视角。
ica的基本概念
独立成分分析是一种统计和计算方法,用于估计和分离一组随机变量(或信号)的线性组合,即观测信号,以恢复其原本的、相互独立的源信号。ica假设源信号是相互独立的,并且在统计上是非高斯的。这种假设使得ica能够解决许多pca无法解决的问题,尤其是在信号分离和盲源分离领域。
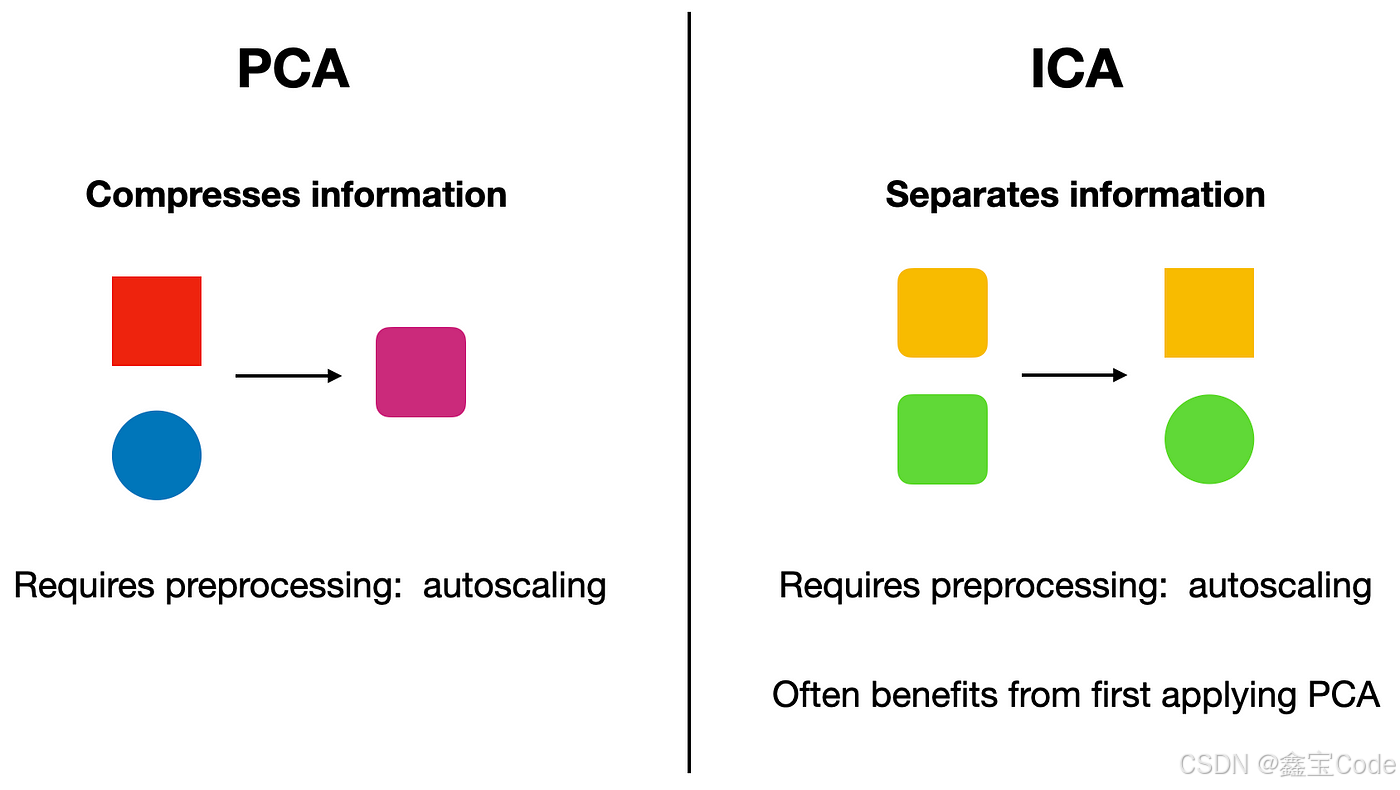
ica与pca的区别
- 目标不同:pca的目标是找到数据的主成分,即数据的正交基,其中第一个主成分具有最大的方差;而ica的目标是找到源信号的独立成分,即使得输出信号的统计独立性最大化。
- 数据假设不同:pca假设数据服从高斯分布,而ica则假设源信号是非高斯的,这是ica能够成功分离信号的关键。
- 应用领域不同:pca广泛应用于数据降维和特征提取,而ica主要用于信号分离和盲源分离,如音频信号分离、生物医学信号处理等。
ica的原理
ica的基本思想是找到一个线性变换矩阵(\mathbf{w}),使得(\mathbf{w}\mathbf{x})中的信号分量尽可能独立。这里,(\mathbf{x})是观测信号矩阵,(\mathbf{w})是ica要估计的变换矩阵。ica通过最大化输出信号的非高斯性或统计独立性来实现这一目标。
ica的算法步骤
数据预处理
在ica的算法流程中,数据预处理是至关重要的第一步,主要包括中心化和白化两个步骤。
中心化
中心化是为了消除数据的均值影响,确保数据的均值为零。设 x \mathbf{x} x为 n n n维观测信号向量,其均值为 e [ x ] = μ \mathbb{e}[\mathbf{x}] = \mathbf{\mu} e[x]=μ,则中心化后的信号为:
x c = x − μ \mathbf{x_c} = \mathbf{x} - \mathbf{\mu} xc=x−μ
白化
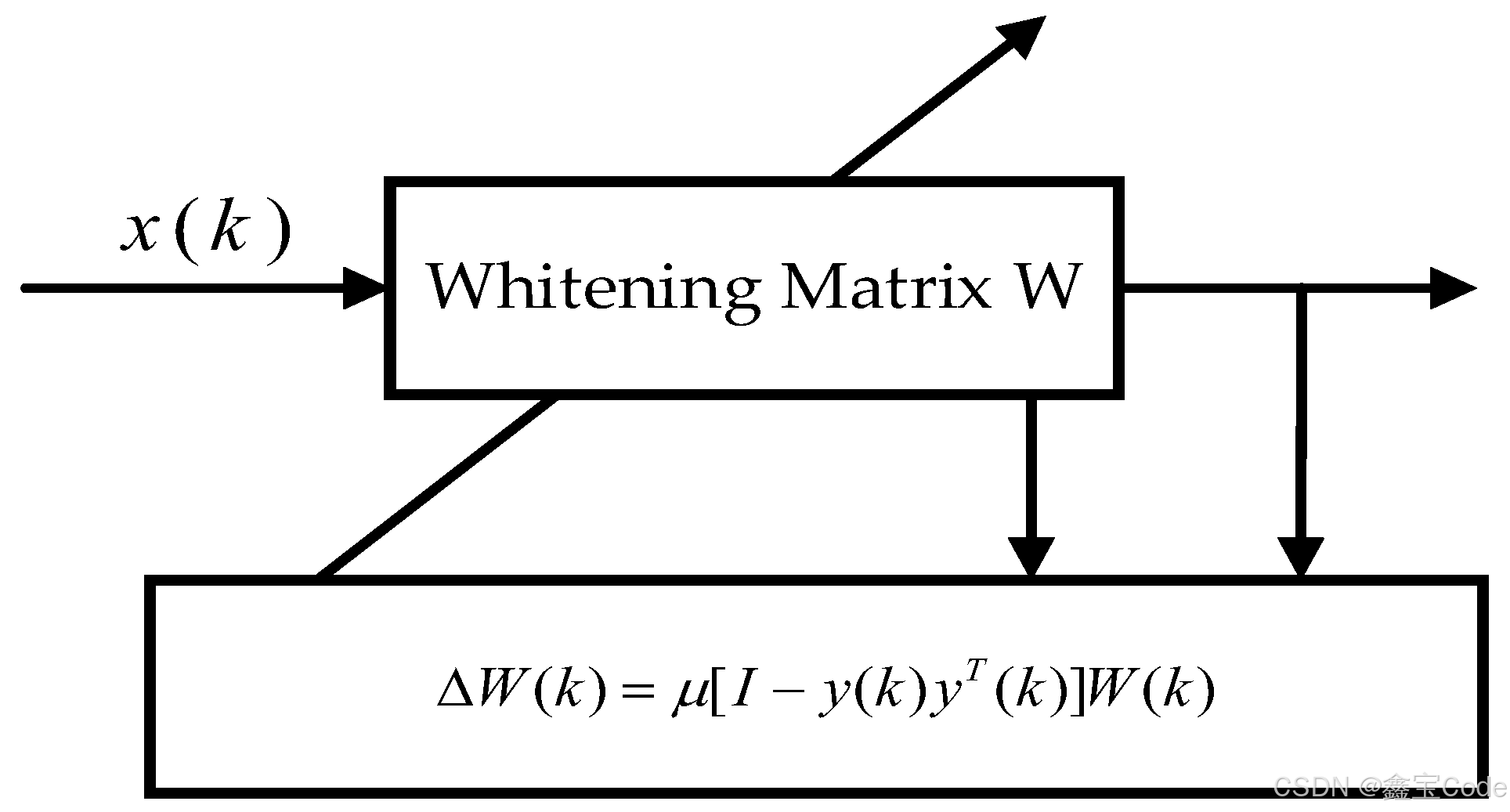
白化处理的目的是去除数据间的相关性,使得数据的协方差矩阵变为单位矩阵。设 c x = e [ x c x c t ] \mathbf{c_x} = \mathbb{e}[\mathbf{x_c}\mathbf{x_c}^t] cx=e[xcxct]为观测信号的协方差矩阵,白化变换可通过以下步骤完成:
- 计算 c x \mathbf{c_x} cx的特征值分解:其中 u \mathbf{u} u是特征向量矩阵, λ \mathbf{\lambda} λ是特征值对角矩阵。 c x = u λ u t \mathbf{c_x} = \mathbf{u}\mathbf{\lambda}\mathbf{u}^t cx=uλut
- 构造白化矩阵
w w h i t e n = u λ − 1 2 u t \mathbf{w_{whiten}} = \mathbf{u}\mathbf{\lambda}^{-\frac{1}{2}}\mathbf{u}^t wwhiten=uλ−21ut - 应用白化矩阵,得到白化后的数据 x w = w w h i t e n x c \mathbf{x_w} = \mathbf{w_{whiten}}\mathbf{x_c} xw=wwhitenxc
独立性度量
ica的核心在于寻找一个变换矩阵 w \mathbf{w} w,使得输出信号 s = w x w \mathbf{s} = \mathbf{w}\mathbf{x_w} s=wxw的分量尽可能独立。为了度量信号的独立性,ica采用非高斯性作为独立性的近似指标,因为独立的随机变量往往具有非高斯分布。常见的非高斯性度量包括负熵和kurtosis。
负熵
负熵 h \mathcal{h} h是衡量随机变量非高斯性的指标之一,定义为:
h [ s ] = − ∫ p ( s ) log p ( s ) d s + const. \mathcal{h}[s] = -\int p(s) \log p(s) ds + \text{const.} h[s]=−∫p(s)logp(s)ds+const.
其中, p ( s ) p(s) p(s)是随机变量(s)的概率密度函数。最大化输出信号的负熵,即寻找矩阵 w \mathbf{w} w使得 h [ s ] \mathcal{h}[\mathbf{s}] h[s]最大。
kurtosis(峰度)
峰度是另一个常用的非高斯性度量,反映了数据分布的尖峭程度。对于随机变量(s),其峰度定义为:
kurt [ s ] = e [ ( s − e [ s ] ) 4 ] ( e [ ( s − e [ s ] ) 2 ] ) 2 − 3 \text{kurt}[s] = \frac{\mathbb{e}[(s-\mathbb{e}[s])^4]}{(\mathbb{e}[(s-\mathbb{e}[s])^2])^2} - 3 kurt[s]=(e[(s−e[s])2])2e[(s−e[s])4]−3
在ica中,我们通常最大化绝对值的四阶矩,即:
ica objective = max w ∑ i e [ ∣ s i ∣ 4 ] \text{ica objective} = \max_w \sum_i \mathbb{e}[|s_i|^4] ica objective=wmaxi∑e[∣si∣4]
ica算法实现
ica的算法实现通常涉及迭代优化,以最大化独立性度量。一种流行的ica算法是fastica,其核心是固定点迭代法,通过更新变换矩阵 w \mathbf{w} w,逐步逼近最优解。
fastica算法

-
初始化:随机初始化 w \mathbf{w} w。
-
更新规则:对于当前的 w \mathbf{w} w,更新规则为:
w n e w = x w g ( w t x w ) − β w x w \mathbf{w}_{new} = \mathbf{x_w}g(\mathbf{w}^t\mathbf{x_w}) - \beta\mathbf{w}\mathbf{x_w} wnew=xwg(wtxw)−βwxw
其中, g g g是非线性函数, β \beta β是步长,通常设置为 e [ g ( w t x w ) 2 ] \mathbb{e}[g(\mathbf{w}^t\mathbf{x_w})^2] e[g(wtxw)2]
-
正则化:为了保持 w n e w \mathbf{w}_{new} wnew的单位范数,需进行正则化处理:
w n e w = w n e w ∣ ∣ w n e w ∣ ∣ \mathbf{w}_{new} = \frac{\mathbf{w}_{new}}{||\mathbf{w}_{new}||} wnew=∣∣wnew∣∣wnew
-
迭代:重复步骤2和3,直至 w \mathbf{w} w收敛。
通过上述算法,我们最终能够获得一个变换矩阵 w \mathbf{w} w,使得输出信号 s = w x w \mathbf{s} = \mathbf{w}\mathbf{x_w} s=wxw的分量尽可能独立,从而实现了ica的目标。
ica的应用
音频信号分离
ica在音频信号分离中有着广泛的应用,例如,它可以用来分离混在一起的多个音乐乐器的声音,或者在嘈杂环境中分离出清晰的人声。
生物医学信号处理
在脑电图(eeg)、心电图(ecg)等生物医学信号处理中,ica能够有效分离出大脑活动的独立成分,帮助研究人员更深入地理解大脑功能和疾病机理。
图像处理
ica在图像处理中也有所应用,比如在图像去噪、纹理分析和颜色校正等方面,通过分离出图像的不同成分,可以提高图像的质量和分析精度。
结论
独立成分分析作为一种强大的信号处理工具,以其独特的能力在信号分离和盲源分离领域展现出了巨大的潜力。通过假设源信号的独立性和非高斯性,ica能够有效地从复杂的混合信号中恢复出纯净的源信号,为信号处理和数据分析提供了新的视角和解决方案。在未来,随着算法的不断优化和计算能力的提升,ica将在更多的领域发挥其独特的作用,为人类理解和利用复杂信号开辟新的道路。




发表评论