

引言:chatgpt等语言模型没有视觉处理能力,大家认为实现强大的视觉模型可能还需要一段时间。然而,2023年3月份发布的gpt-4彻底改变了这一预期。gpt-4刷新了多个视觉榜单记录,并且展现出很强的图片理解能力。此外,相比chatgpt,关于gpt-4的资料相对更少,使其更显神秘。
2022年11月,openai发布了chatgpt 3.5,一经推出便引起了轰动。紧接着在2023年3月,openai发布了支持多模态输入的gpt-4,并展示了其强大的图像理解能力。这一突破立即在学术界引发了热烈反响,vision-language models (vlms) 的相关研究工作迅速增长。正如下图所示,无论是开源还是闭源的模型,都层出不穷,更新速度令人目不暇接。
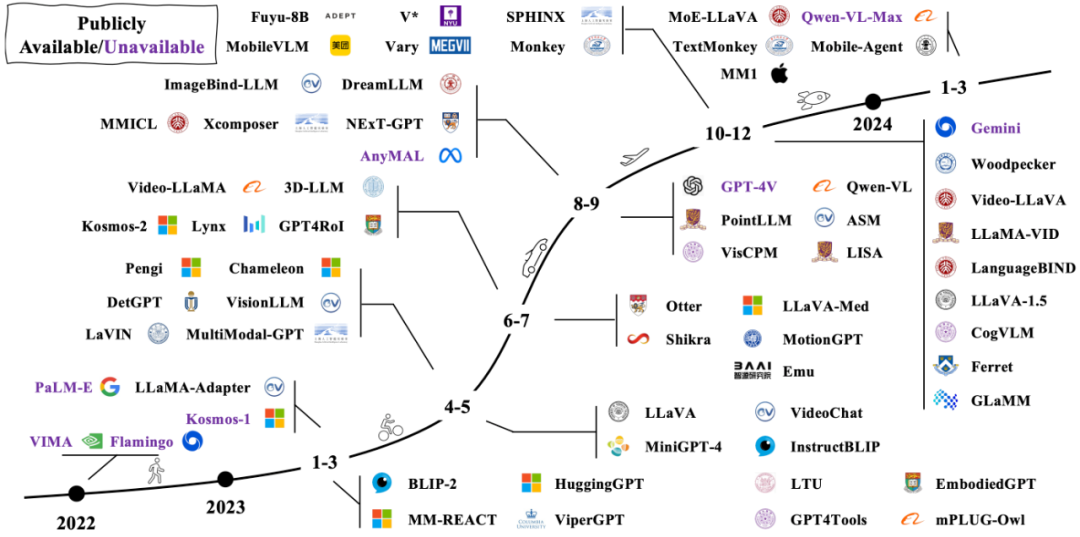
-
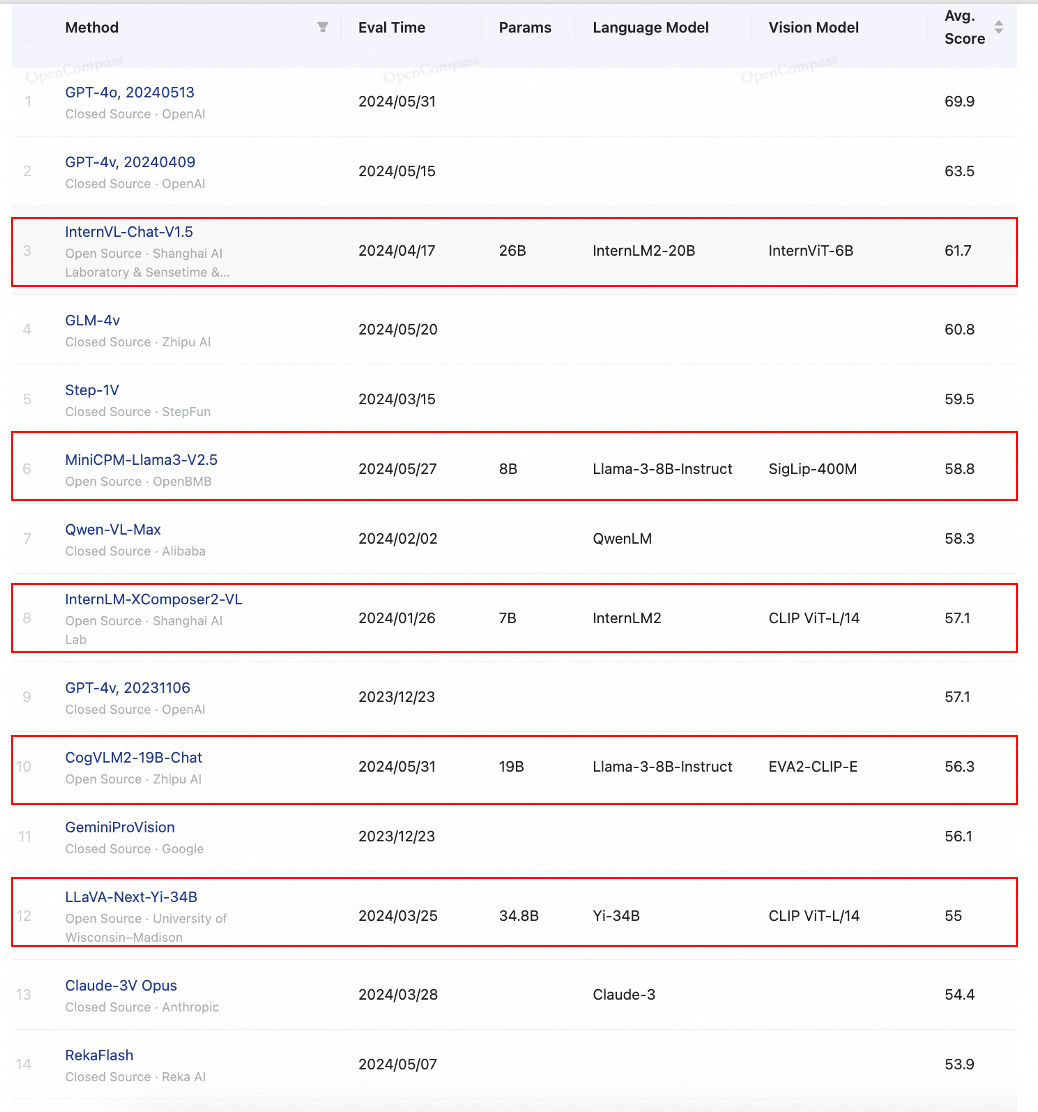
gpt-4毫无争议地排名第一,尤其是最近发布的gpt-4o版本表现尤为突出 -
其他相关模型也在快速追赶,并在榜单上超过了gpt-4v 20231106版本 -
虽然国内模型相对openai的产品还有一定差距,但与其他国外厂商如谷歌的geminivision相比,仍处于同一梯队 -
令人欣喜的是,许多开源模型在榜单上也名列前茅,甚至超过了一些闭源模型

但需要注意的是:
大模型的评估本身也是一件复杂的任务,评估方法和指标还在不断完善中。因此,上述opencompass榜单上的指标只能作为参考,实际应用中哪个大模型表现更好还需要在具体业务场景中进行实测。
模型输出中仍然存在幻觉、输出不稳定和泛化性问题,特别是对于一些较小的模型,这些问题更加明显。
当前的视觉大模型在处理速度上依然存在较大限制,因此在现阶段许多实时性要求较高的业务应用中,使用小模型仍然是更可行的选择。
小结:开源vlms从最初的demo级别,迅速发展到现在许多业务中都已具备实际使用的能力,近一年进展可谓飞速。接下来,我们将探讨一下vlms在过去一年中取得的进步,以及哪些方面仍需持续改进。

代表性工作 — llava
引言:回顾一下代表性工作llava,可以帮助我们更好地理解vlms的基本范式,并分析其存在的问题以及近一年来的相关改进。
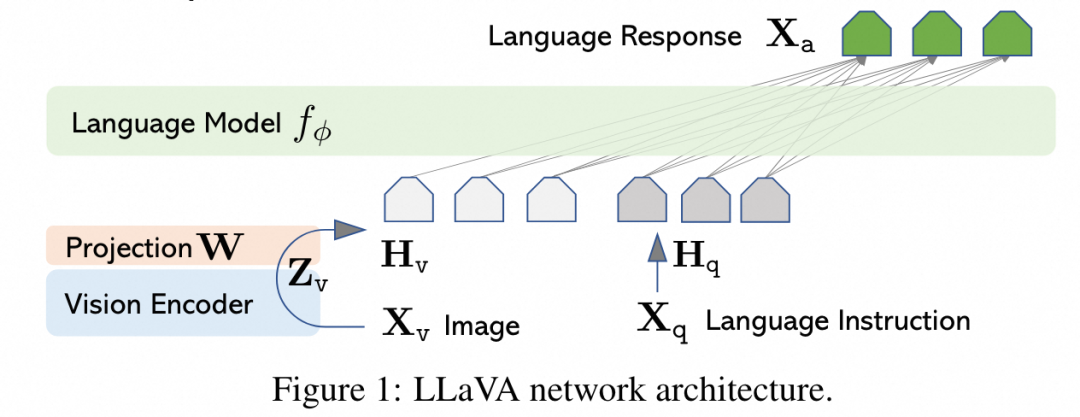
llava在模型结构上十分简洁,将视觉图像视作一种“外语”,利用vision-encoder和projection将“图像翻译成文本信号”,并微调llm适应图像任务。
vision-encoder: vit-l/14
projection:单个线性层,后续改为两层mlp
llm:vicuna-7b
训练数据包括:
预训练数据:过滤cc3m后得到的595k image-text caption pairs数据
sft数据:
通过gpt-4生成的问答数据:158k instruction-following data
science qa问答数据集:21k多模态选择问答题
整个训练包含二个阶段,一阶段利用caption数据只训练projection,二阶段sft数据训练projection和llm。整个训练阶段冻结vision encoder。
初版本llava的效果在很多业务问题上只能说是demo级别,还有很多问题需要解决:
llava只支持224,实际场景中224分辨率根本不够用,怎么处理高分辨率?
vision-encoder用vit合适吗?projection使用简单的mlp对吗?视觉token和文本token这样简单连接在一起对吗?
这么点训练数据够吗?视觉encoder不需要训练吗?
没法做精细化图像感知任务,没法输出检测框和分割框,ocr能力弱
接入视觉信号,vicuna本身文本的能力怎么样,变强了还是变弱了?
...
让我们带着这些问题来看近一年的工作,有些问题已经解答的比较好,有些问题还在持续探索中。
小结:现在看llava初版效果一般,但在当时几个小时训练好,代码数据开源,诚意满满,让很多小成本玩家也能玩得起多模态。

高分辨率问题
引言:llava默认的224分辨率远远不够,尤其对于文档任务来说至少需要896以上的分辨率;而直接扩大图像尺寸,会让图像token数据快速增加,不希望训练代价太大。
-
方式一:引入高分辨率分支,相关论文有 vary(2312) 引入一个高分辨率分支,该分支加量不加价(输入大尺度图像1024*1024,但在网络设计上保证高分辨分支和低分辨率分支图像token数保持一致) -
方式二:滑动切块,相关论文有 ureader(2310)、 monkey(2311)、 llava-uhd(2403)、 internlm-xcomposer2-4khd(2404)、 internvl-1.5(2404) 等
方式一有个问题,如果要求分辨率比1024还大怎么办,并且高分辨率分支还需要额外训练。解决分辨率更恰当的方案可能还是滑窗切块。大致的思路是将高分辨率图像切分成n个子图,每个子图resize到224或448,用同一个vit提取n个子图的特征,然后将子图特征又聚合在一起。上述论文处理高分辨率都是采用这个逻辑,但在切块和聚合的细节上略有不同。
其他细节问题
切图是否会正好把文字切成两半影响性能呢?textmonkey(2403)借鉴swin transformer添加shift滑窗机制。
有些任务需要大分辨率,有些其实小分辨率就够了,怎么自动决定用多大分辨率呢(上述动态切块都是自适应宽高比,不能自适应分辨率)?相关论文dualfocus(2402)让vlms自己学会放大镜功能。
其实上述之所以要手动滑窗切块是因为vit使用固定位置编码,无法像卷积一样任意扩大分辨率,如果使用swin transformer这类backbone是否可以实现任意分辨率而不用手动切块,或者将vit修改为相对位置编码。
小结:个人认为分辨率问题在近期的vlms研究中得到了相对较好的解决,尤其是在需要高分辨率支持的任务(如文档问答)方面,进展尤为显著。

数据
引言:llava使用的训练数据相对较少,所以在业务上会发现泛化性不足,难以应用实际的业务;相比文本数据,视觉数据形式更多样,存储和采集更困难,我们该怎么构建好数据呢?
毫无疑问,数据才是训练一个好的vlms的重中之重。
为了让vlm充分理解物理世界,我们要构造什么样的视觉数据呢?大致可以想到这些:
基础的认知数据(caption):知道什么是什么
感知定位数据(检测、分割):有精确的定位能力
文档ocr相关数据:现实生活中非常重要的一类数据
复杂一点的思维链数据:需要用来激活vlm逻辑能力
3d数据/视频数据:这类数据才是真实的物理世界
其他行业图像:如医学图像、x光图像、雷达图等
...
这里每一项数据由于图像特性又可以分全局描述和局部描述,使得表现形式极为丰富;另一个问题是当前vlms受限于只能输出文本,必须有image-text pairs,目前还没有做到像llm一样"无监督预训练"(llm预训练数据是人类产生的,其实也算是有监督,但是label很容易获取)。【如何充分挖掘利用好互联网上图文数据omnicorpus(2406)?或者就直接用图像自回归训练?】
所以训练数据的收集和构造对于vlms来说是一个大难题,学术界对于这个问题也没有形成定论,大致是分成两类数据,一是预训练对齐数据,二是sft数据。预训练数据会更偏向于感知,看上去更简单一点;sft数据会要求更强的逻辑推理,看上去会更难一些。【具体哪部分数据放在预训练好?哪部分放在sft好呢?哪部分数据又是真的有效呢?dataset selection(2405)】
在训练数据的构造问题上建议直接查看开源论文的工作 internvl-1.5(2404)和 deepseek-vl(2403),论文中收集的数据比较全,并且描述比较细。如下图所示为internvl-1.5训练数据:
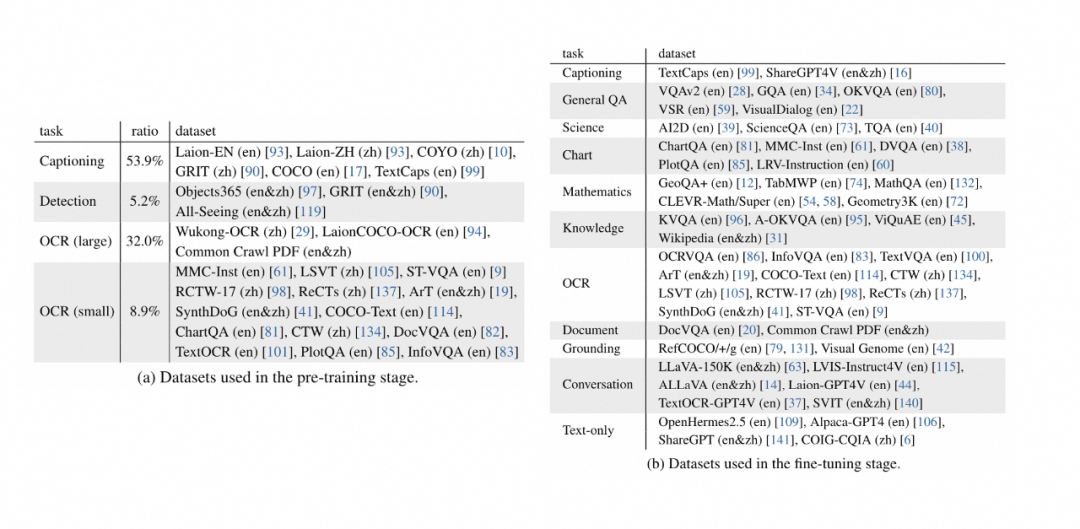
这么多数据集,光下载就费劲,真是让人头大。一是期待有人能构建处理好的数据供直接下载;二是这么多数据大部分人其实没有资源去训练尝试。所以对大部分人更有意义的是如何构造业务上高质量的sft数据。这里可以查看 awesome-multimodal-large-language-models 持续跟踪最新的数据集相关的工作。
具体到笔者熟悉的文档领域,可以参考
mplug-docowl 1.5(2403), textsquare(2404), fox(2405) 等相关论文的工作。
其他细节问题:当前vlms对于检测框的bbox要么直接用归一化的数字(0~1000)表示,要么用特殊标记符(bbox_0~bbox_1000),合理吗?检测框还能用四个值表示,分割呢? psalm(2403),pixelllm(2312)
小结:数据这一块还没有收敛,也是各大公司的核心机密。无论是在学术研究还是商业应用中,数据始终是第一优先级,做好数据准备工作至关重要。对于大部分人员来说,如何获取和构建高质量的业务sft数据尤为重要。

引言:llava模型结构比较简洁,是否需要设计更复杂的模型结构呢?
近一年,也有许多论文对模型结构进行尝试和改进。
vision_encoder
gvt(2305)中讨论将vit换成deit, clip, mae, dino等其他自监督视觉backbone,deepseek-vl(2403)等工作使用了两种vison encoder联合编码图像特征(sam+siglip),fuyu(2310)更激进的提出不用vision encoder,直接原图输入。
projection
除了mlp外,qformer(2301)、 resampler(2204)等也可以作为特征转换层。尽管还有一些论文提出新的抽取层c-abstractor(2312),但使用最广泛的还是mlp。即使minicpm-v(2402)、textmonkey(2403)等采用非mlp方式也更多的是为了效率而不是效果考虑。
llm
通常都是直接复用开源llm模型。有一个值得探究的点是文本token和图像token在llm中是否应该区别处理,如internlm-xcomposer2(2401)会在在lora微调llm时区别对待图像token和文本token,或者beit3(2208)在模型结构上就针对不同领域token设计专家模型。但目前最普遍的还是直接复用开源llm。
小结:从上述论文的结果来看,除了moe能明确用来训练更大模型外,其他网络结构的改动性能上变动并不显著;在数据没饱和的情况下,除非是大的模型结构创新,否则更值得做的事情是挖掘高质量数据。

理解和生成一体化
引言:当前提到图像生成,大家默认会想到diffusion,其实vlm也可以做图像生成。上文提到过当前vlms训练时其实忽略了分割数据(文本不适合表示分割),如果vlms能直接输出图像,是不是也能很好的利用分割数据;agi必然会针对不同的需求,选择最高效的方式输出,而不仅仅是局限在文本输出上。
llava目前只能处理图像理解任务,输出文本描述,而无法生成图像。
如果我们希望vlms能够输出图像,该如何实现呢?最直观的办法是让vlms先生成图像的文本描述,然后利用扩散模型(diffusion model)将这些描述转化为图像。然而,如果vlms与扩散模型之间没有经过联合训练,生成效果可能会受到很大限制。
近一年也有不少相关工作,将理解和生成一体化。基于输出图像的形式,大致可以分为两类。
方式一:连续embedding表示图像
相关工作有emu2(2312), dreamllm(2309), next-gpt (2309), seed-x(2404)
这一类的工作特点在于输出图像的embedding,作为diffusion的控制条件,利用diffusion解码出图像。在优化llm的图像输出embedding时,通常保持diffusion冻结,相当于将diffusion作为图像解码器
注意由于连续embedding需要使用回归loss进行监督,和当前llm的分类loss不一致,所以需要修改llm训练代码支持回归loss
方式二:离散token表示图像
相关工作有lavit(2309), unified-io 2(2312)
这类工作使用vqvae(1711)将图像离散化,输出的是离散图像token,在训练框架上和当前llm保持统一
这一类方法要考虑vqvae图像离散化有效性的问题。通常vqvae的图像词表是4k或者8k,是否能完美表示50176(14*14*256)像素空间呢?这里magvit v2(2310)提出新的编码图像token的方式,可以将图像词表扩充至262k
除了图像输出形式外,也许还需要对输出方式进行改进。llm现在的自回归是为文本设计的,一个一个token蹦出来是符合人类语言特性的。但是人类看图像不是一个patch一个patch看的。而是先看图像整体再看细节。所以var(2404)提出在空间维度进行自回归训练,一次性输出一个scale的图像token,在速度和效果上都能和早期diffusion相提并论。
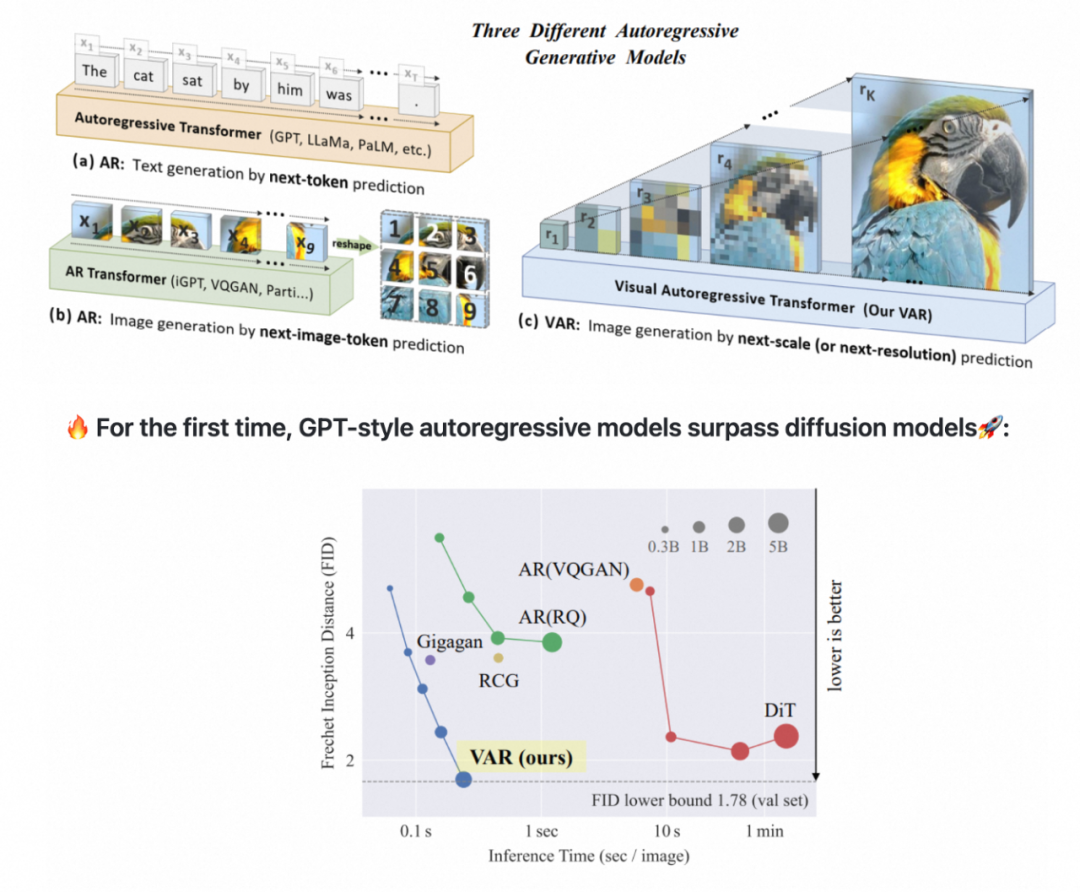
其他:vitron(2404)采用纯文本作为控制信号,并通过设计指令数据来微调大语言模型(llm),从而优化其“调用文本”的输出效果。论文认为这种设计使得后端解码器在更换时变得更加容易和灵活,这为系统的可扩展性和适应性提供了显著优势,并能减轻llm的训练负担。
小结:尽管vlms在图像生成方面尚未如diffusion方法那般广泛应用,但无疑是有潜力的。vlms优越的长上下文理解能力和灵活的输出形式,使其在实际应用中比单独使用diffusion更为便捷。虽然这一路线在技术细节上尚未完全成熟,但也有企业如videopoet、阶跃星辰坚定地在这一领域进行探索。

视觉能让llm更智能吗
引言:之前和非视觉同学讨论说,vlm看上去不就是接了个vit吗,没啥特别的?知乎上也有讨论为什么是语言大模型产生“智能”,而不是视觉大模型产生“智能”——盲人看不见,也有智能,说明产生智能不需要视觉;很多动物也有视觉能力,但是并没有表现出太多的智能。
chatgpt 令人兴奋,是因为它看起来非常聪明,能够生成类似人类的“智能”输出。但目前的vlms更多是为大型语言模型 (llm) 添加一个感官信号,很难说vlms会比llm更加聪明。
无论是nlp还是视觉算法同学,最终的目标无疑是实现通用人工智能(agi)。如果说视觉和智能关系不大,那一定会让视觉同学感到沮丧。然而,当前vlm确实更多是以llm为主体,并且没有明确的研究表明加入视觉信号的vlm在文本的逻辑推理任务上明显优于纯文本的llm。
因此有必要深入探讨视觉与智能之间的关系,以及视觉在实现agi过程中能发挥的作用。
▐ 什么是智能
要想回答视觉是否能让llm更智能,首先要定义什么是智能,以及智能怎么来的。在此简要概述笔者理解的“智能” (不一定对)。
首先将“智能”狭义的定义为“连接关系”。
例如,单独的“人”这个词仅仅是一个指代,只有当我们将“人”这一概念与“手”、“头”、“车”等其他概念连接起来时,它才具有实际的意义。在狭义上,智能可以被定义为将各种事物和概念“连接”在一起的能力。
将智能的产生过程归纳如下:

首先通过观测运动的物理世界,我们会发现一些简单的“连接关系”,比如手和头是连接在一起的,树上有小绿片等。
物理世界中存在着无数种“连接关系”,人类大脑无法事无巨细地全部记住,因此我们需要对这些简单的连接进行抽象处理。例如,树a和树b上都有小绿片,我们不会机械地记住每棵树上的每一片小绿片,而是将这些小绿片统一称为“树叶”。这些抽象概念通过文字得以存储,并永久保留。
通过可存储的文字,我们有条件建立起更长久、更高级的连接,把长时间、大范围内的各种“连接关系”串联起来,进而抽象出更高层次的“连接关系”,例如物理定律。这些高级的连接关系形成了我们理解的高级智能。
当然“智能”肯定不是这么简单就形成的,还涉及社会学、心理学、生物学等多方面因素。
从这个过程中可以看出,人类作为一个物种,其智能的发展经历了从视觉感知到文本信息的压缩抽象,再到更高级的思维连接的过程。然而,就个体发展而言,尤其是在婴儿的成长过程中,除了通过视觉进行自我学习和归纳总结之外,我们也在不断地向他们传授已知的连接关系。如果完全依赖儿童自己通过观察来归纳和总结,以形成智能,那么他们的成长曲线将会非常漫长,类似于人类整体历经数千上万年的发展历程。
当前的大规模语言模型(llm),在一定程度上就类似于婴儿。我们并没有让这个“婴儿”直接从视觉中学习和理解“连接关系”,而是通过文本向其传授人类已知的连接关系,从而加速它们智能形成的过程。然而,这个“婴儿”目前缺乏视觉(泛指其他感官模态)能力,也没有自我迭代和更新“连接关系”的欲望或能力。
▐ 视觉能为llm这个婴儿带来什么
简单思考一下视觉能为llm这个“婴儿”带来什么?
扩展知识边界:视觉数据为“婴儿”带来了全新的连接关系,这些关系可能在文本数据中未曾出现或难以表达。
提高学习效率:与文本相比,视觉信息在某些场景往往更加直观和丰富。这使得智能系统能够更快地从环境中学习,加速其认知能力的发展。
纠正认知偏差:由于文本数据可能包含人类的偏见、歧视或错误信息,视觉数据提供了一种验证和纠正这些偏差的手段。通过直接观察现实世界,智能系统能够构建更加准确和客观的世界模型。
...
▐ 纯视觉大模型可行吗
按照上述智能的分析,直接从视觉信号开始学习,是不是也会产生智能呢?论文lvm(2312)试图通过自回归的方式构建纯视觉大模型(没有文本)。如下图所示,该模型似乎也有最基本的模仿归纳能力。

视觉大模型lvm(2312)能通过prompt做简单的图像逻辑推理
但这种能力更多的像是动物的感知能力,是很短期的简单的“连接关系”,没有迭代到更高级的“连接关系”。
毕竟llm所看到的文本是人类几千年的智慧积累,纯视觉大模型还没有看过几千年的物理世界。那纯视觉大模型会涌现出高级智能呢?个人认为是有可能的,并且这种智能体可能会发展出一种非人类语言的抽象表示。这种抽象表示可能更高效、更直接,更适合机器智能。然而,如果仅仅依赖数据堆积而不在算法设计上进行迭代优化,其消耗的资源将是难以想象的。
现阶段,更现实的做法是依托llm来融合视觉信息,并在适当的时候让vlm自我迭代出超越文本的抽象表示,而不是一开始就抛弃文本,舍近求远。这种渐进式的策略不仅能让我们在已有基础上获得最大的收益,还能确保我们在探索和建设高级智能的道路上更加稳健和高效。
其他:
使用vlm进行纯感知任务的效果可能会更好,因为vlm是在已有“高级连接”的基础上重新建立“低级连接”。这种方法可能比纯感知模型更能区分出镜子中的人
现阶段的llm这个“婴儿”缺乏自我迭代和更新的“欲望”。如何让这个“婴儿”设定一个合理的欲望,使其具备自我迭代的能力,同时又要限制其在自我迭代过程中不危害人类?
小结:目前开源界vlms还是比较初级的阶段,数据、多模态输出等还没有完全准备好,这些模型在现阶段似乎还没有对“智能”作出显著贡献。尽管如此,与一年前相比,vlms 已经取得了显著进步,并在许多业务场景中开始具备实用性。我们有理由相信,未来会有更“智能”的vlms出现,为各类应用带来更多创新和突破。

总结
本文简要回顾了在vision-language models (vlms)领域中具有代表性的工作,如llava,并总结了过去一年中vlms的部分发展。由于能力和篇幅所限,我们仅总结了部分方向的工作,诸如3d、视频、agent、具身智能等多个重要方向尚未得到讨论。最后,我们也对vlms在智能领域的意义进行了思考,尽管这些思考可能带有一定的臆测成分,毕竟llm是否算作真正的智能本身仍有争议。
在总结和反思的过程中,我们希望为读者提供一个综合的视角,理解当前vlms的发展的同时,也思考其未来可能的走向和应用。尽管道路充满挑战,我们依然相信,通过不断的研究和优化,vlms将在实现通用人工智能的过程中扮演重要的角色。欢迎大家交流讨论~

参考资料
[1] opencompass: https://rank.opencompass.org.cn/home
[2] llava(2304): https://arxiv.org/abs/2304.08485
[3] vary(2312): https://arxiv.org/abs/2312.06109
[4] ureader(2310): https://arxiv.org/pdf/2310.05126
[5] monkey(2311): https://arxiv.org/pdf/2311.06607
[6] llava-uhd(2403): https://arxiv.org/pdf/2403.11703
[7] internlm-xcomposer2-4khd(2404): https://arxiv.org/abs/2404.06512
[8] internvl-1.5(2404): https://arxiv.org/pdf/2404.16821
[9] textmonkey(2403): https://arxiv.org/pdf/2403.04473
[10] dualfocus(2402):
https://github.com/internlm/internlm-xcomposer/tree/main/projects/dualfocus
[11] omnicorpus(2406): https://arxiv.org/abs/2406.08418
[12] dataset selection(2405): https://arxiv.org/pdf/2405.11850
[13] deepseek-vl(2403): https://arxiv.org/pdf/2403.05525
[14] awesome multimodal large language models:
https://github.com/bradyfu/awesome-multimodal-large-language-models
[15] mplug-docowl 1.5(2403): https://arxiv.org/abs/2403.12895
[16] textsquare(2404): https://arxiv.org/abs/2404.12803
[17] fox(2405): https://arxiv.org/abs/2405.14295
[18] psalm(2403): https://arxiv.org/abs/2403.14598
[19] pixelllm(2312): https://arxiv.org/pdf/2312.02228
[20] gvt(2305): https://arxiv.org/abs/2305.12223
[21] fuyu(2310): https://www.adept.ai/blog/fuyu-8b/
[22] qformer(2301): https://arxiv.org/pdf/2301.12597
[23] resampler(2204): https://arxiv.org/pdf/2204.14198
[24] c-abstractor(2312): https://arxiv.org/pdf/2312.06742
[25] minicpm-v(2402):
https://github.com/openbmb/minicpm-v/blob/main/readme_zh.md
[26] internlm-xcomposer2(2401): https://arxiv.org/abs/2401.16420
[27] beit3(2208): https://arxiv.org/pdf/2208.10442
[28] emu2(2312): https://arxiv.org/abs/2312.13286
[29] dreamllm(2309): https://arxiv.org/abs/2309.11499
[30] next-gpt(2309): https://arxiv.org/abs/2309.05519
[31] seed-x(2404): https://arxiv.org/pdf/2404.14396
[32] lavit(2309): https://arxiv.org/abs/2309.04669
[33] unified-io 2(2312): https://arxiv.org/pdf/2312.17172
[34] vqvae(1711): https://arxiv.org/abs/1711.00937
[35] magvit v2(2310): https://arxiv.org/pdf/2310.05737
[36] var(2404): https://arxiv.org/abs/2404.02905
[37] vitron(2404): http://haofei.vip/downloads/papers/skywork_vitron_2024.pdf
[38] videopoet: https://hub.baai.ac.cn/view/34241
[39] lvm(2312): https://github.com/ytongbai/lvm

团队介绍
我们是供给智能团队,一个以ai能力为核心驱动的技术团队,基于视觉aigc、多模态大模型、agent等技术,服务于商品图片生成、商品库构建、商家经营辅助等诸多淘系供给侧(商家/商品/行业)业务。






发表评论